
文章目录
- 前言
- TCP 协议的段格式
- TCP 协议的相关特性
- 什么叫做可靠传输
- TCP 采用了哪些主要机制保证了可靠传输和优化传输效率
- 1. 确认应答
- 2. 超时重传
- 3. 连接管理(三次握手、四次挥手)
- 三次握手(建立连接)
- 四次挥手(断开连接)
- 4. 滑动窗口
- 5. 流量控制
- 6. 拥塞控制
- 7. 延时应答
- 8. 捎带应答
- 9. 面向字节流
- 10. 异常情况的处理
- TCP 和 UDP 的对比
前言
前面我们学习了网络中传输层一个比较重要的协议——UDP 协议,因为 UDP 协议的特点,使得在使用 UDP 协议传输数据的时候虽然保证了速度,但是传输数据的大小和可靠性就降低了。由此就需要传输层的另一个重要协议——TCP 协议,TCP 协议虽然在传播速度上可能比不过 UDP ,但是 TCP 以其传输数据时的可靠性为特点以及传输数据的大小更大的特性,使得它在日常生活中更被广泛使用。这篇文章我将详细为大家分享关于 UDP 协议相关的知识。
TCP 协议的段格式
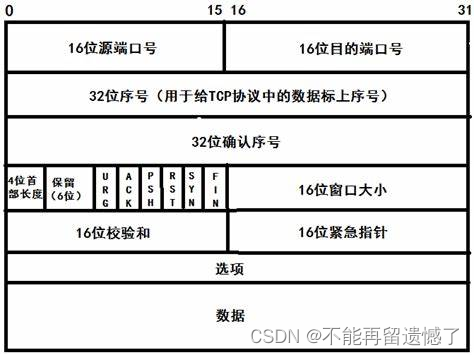
- 源端口/目的端口:表示数据是从哪个进程来,到哪个进程去
- 32位序号/32位确认号:后面为大家详细讲
- 4位首部长度:表示TCP头部信息的长度,单位是4字节(32比特位),所以TCP头部信息长度最长为 15*4=60 字节
- 保留位(6位):因为 UDP 报文长度最大是2个字节的长度,导致 UDP 传输数大小最大为 64kb,而 TCP 协议这里的保留位就增加了可扩展性
- 6个标志位:后面会为大家介绍
- 16位窗口大小/16位紧急指针:后面为大家介绍
- 16位校验和:跟 UDP 中的校验和类似
- 选项:选项表示可选项,也是属于报头部分,选项大小范围是0~40字节
TCP 报头长度最长为 60 字节,最短长度为 20 字节(选项大小为0),当 4 位首部长度表示为 0 时说明报头长度为 20字节,也就是选项的长度为 0,当 4 位首部长度表示为 15 的时候,说明报头长度为 60 字节,也就是选项的长度为 40 字节。
TCP 协议的相关特性
- 有连接:TCP协议在传输数据之前必须先建立连接,并且在数据传输完成后需要释放连接。这是TCP协议的一个重要特点,它使得网络通信更加有序和可靠。
- 可靠传输:TCP协议通过确认应答、超时重传、滑动窗口等机制来保证数据的可靠传输。确认应答机制确保发送的数据段被接收方正确接收;超时重传机制在出现网络延迟或故障时,能够重新发送未被确认的数据段;滑动窗口机制则通过动态调整发送窗口大小,提高数据传输效率。
- 面向字节流:TCP协议将数据看作字节流,以字节为单位进行传输。这意味着在传输过程中,数据不会被分割成固定长度的数据段,而是根据应用程序的需求进行组织和传输。
- 全双工:TCP协议支持全双工通信,即发送方和接收方可以同时进行数据传输。这使得数据传输更加高效,但同时也需要协议在实现中处理好流量控制和拥塞控制等问题。
有连接、面向字节流和全双工,我们在前面的 TCP 流套接字编程中都能体现出来。
Socket clientSocket = serverSocket.accept(); //将建立的连接拿到进行后面的通信
try (InputStream inputStream = clientSocket.getInputStream();
OutputStream outputStream = clientSocket.getOutputStream()) {
}
通信双方都是通过一个 Socket 对象实现通信,体现了 TCP 的全双工。
TCP 协议作为传输层使用最多的协议,很大方面是因为 TCP 协议的可靠传输,TCP 协议的初心也是为了可靠传输,所以这篇文章我将着重为大家分享关于 TCP 可靠传输的知识。
什么叫做可靠传输
在我们日常生活中,因为各种条件的影响,因为网络是通过 光/电 信号传输的,很容易受到其他条件的影响,所以数据的传输很难做到百分百传输到,所以我们就退而求其次。
- 发送发发送消息了之后,能够知道接收方是否收到了这个消息
- 如果接收方没有收到这个数据,会通过一系列的措施来进行补救

TCP 采用了哪些主要机制保证了可靠传输和优化传输效率
- 确认应答
- 超时重传
- 连接管理
1. 确认应答
TCP的确认应答(acknowledgment)机制是TCP协议保证数据可靠传输的重要手段之一。在TCP通信中,当接收方收到发送方发送的数据段后,会向发送方发送一个确认应答信号,以告知发送方数据段已成功接收。
确认应答机制的实现方式如下:
- 接收方在收到数据段后,会将其序号(即数据段的编号)加上确认应答号(acknowledgment number),然后发送给发送方。确认应答号是下一次期望接收的数据段的序号。
- 发送方在收到确认应答后,会将确认应答号所表示的数据段进行重传,以确保这些数据段能够被接收方正确接收。
- 如果发送方在一定时间内未收到确认应答,则会重传数据段。如果重传次数超过一定限制,则可能会触发超时重传机制,重新发送未被确认的数据段。
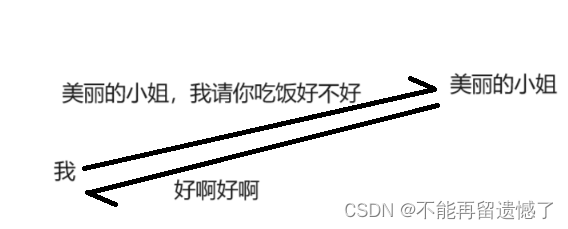
这里是我向美丽的小姐发送了一个请他吃饭的消息,小姐说好啊,但是如果我在没收到小姐的回复之前我又向他发送了一个消息的时候会发生什么呢?
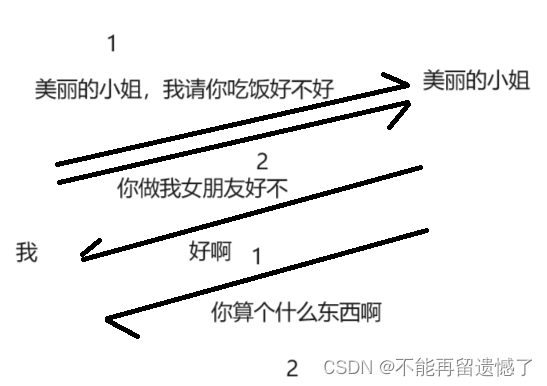
这个是正确的信息,但是如果在这个过程中出现了发送的信息顺序出现了问题呢?
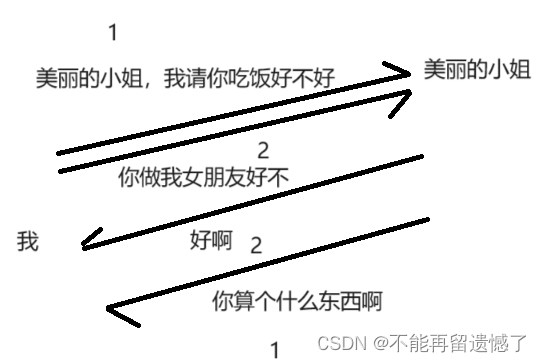
这样美丽的小姐就同意了做我女朋友的请求,但是却拒绝了我请他吃饭的请求,但是这样我也是血赚的。虽然这里我是赚了,但是如果发生在我们的日常生活中的时候就可能会出现很严重的问题,所以这里 TCP 还会做两件事情。
TCP 在此过程中会完成两个工作:
- 确保应答报文和发出去的数据能够对上号,不要出现歧义
- 确保在出现后发先至的情况的时候,能够让应用程序能够按照正确的顺序处理数据
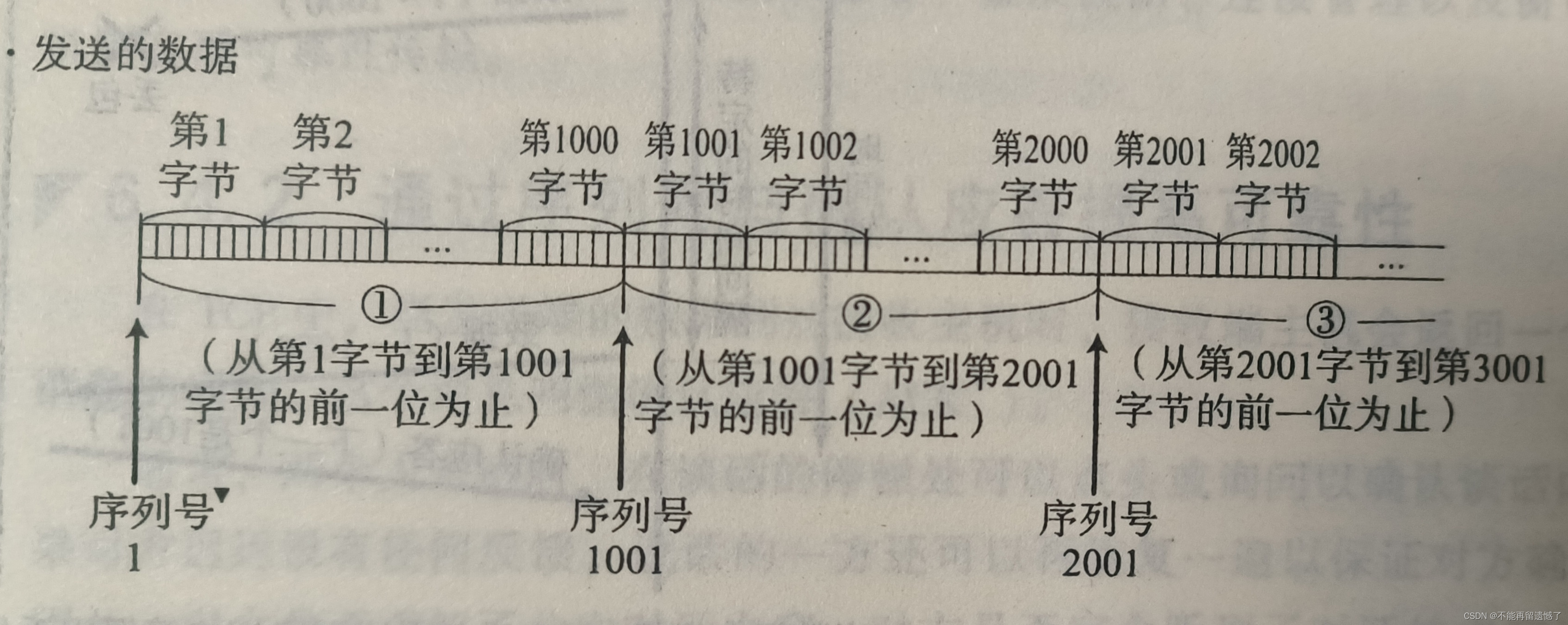
TCP 会将每个字节的数据进行编号,即为序列号。
每一个ACK都带有对应的确认序列号,意思是告诉发送者,我已经收到了哪些数据;下一次你从哪里开始发。
序列号的作用:
- 保证了数据的顺序:TCP将传输的数据分割为TCP段,并为每个段赋予一个序列号。这些序列号使得接收端可以将接收到的数据段重新组合成原始的数据流,保证了数据的顺序。
- 保证了数据的完整性:如果数据在传输过程中出现了丢失或损坏的情况,接收端可以根据序列号来判断哪些数据需要重传,从而保证了数据的完整性。
确认序列号的作用:
- 告知接收端下一次期望接收的数据段的序号:当接收端收到一个TCP段后,会向发送端发送一个确认应答信号,其中的确认序列号表示下一次期望接收的数据段的序号。这有助于避免数据的重复传输。
- 实现可靠的数据传输:只有当发送端接收到接收端发送的确认应答信号后,才会继续发送后续的数据段。如果发送端在一定时间内未收到确认应答,则会重传之前发送的数据段,从而保证了数据的可靠传输。
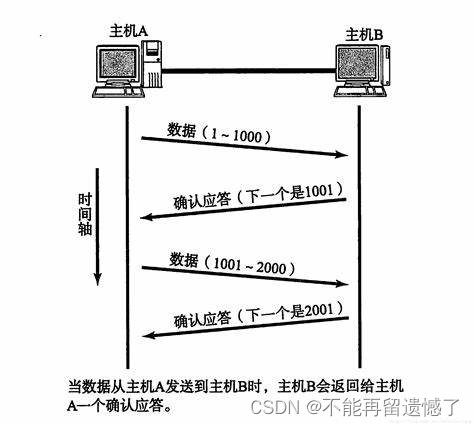
TCP 报头中记录的序号是这次传输的载荷数据中第一个字节的序列号,而剩下其他字节的序列号则需要根据载荷中数据长度依次推出。这里主机 A 向主机 B 发送 1~1000 之间的数据,所以主机 B 会将 1001 返回给主机 B ,下一次主机 A 发送数据的时候就会从 1001 开始发送数据。
通过特殊的 ACK 数据包里面携带的确认序列号就可以告诉发送方,哪些数据我已经确认收到了,这一机制保证了数据的可靠传输。
达成 TCP 可靠传输的最核心的机制就是 确认应答
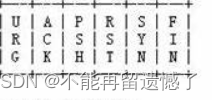
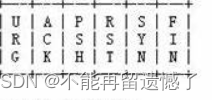
TCP 协议的段格式中6个标志位中的 ACK 就是用来区分该数据包是否为应答数据包 ACK 的,如果该标志位上的数字为 1 则说明该数据包是 ACK 应答数据包,为 0 则不是。
常见面试题:TCP 是如何保证可靠传输的?
答:通过 确认应答 为核心,其他机制辅助最终完成可靠传输。
2. 超时重传
在了解超时重传这个机制之前,我们需要知道什么叫做丢包。
丢包是指在网络传输过程中,数据包因为各种原因没有正确地到达目标地点,而丢失的现象。丢包率是指在数据传输过程中,丢失数据包的数量与发送的数据包总数之比。丢包率越高,说明网络质量越差,数据传输速度越慢。
丢包可能是由多种原因导致的,例如网络拥塞、设备故障、软件缺陷、路由问题等。在网络通信中,丢包可能会导致数据传输中断、延迟或错误,因此是网络性能中最核心的指标之一。
常见点来说就是当短时间内服务器一个设备收到的数据很多的时候,他不会将这些数据阻塞然后一点一点的读取数据,而是会很粗暴的将部分数据给丢弃,这个数据被丢弃之后,那么我们在网络上就找不到这个丢失的数据了,这就是丢包。
确认应答描述的是一个理想的情况,如果在网络传输的过程中发生了“丢包”的时候,该怎么办才能保证 TCP 传输的可靠性呢?
因为丢包是一个随机的事件,所以在上述 TCP 传输数据的时候可能是在发送方发送请求的时候发生了丢包,也有可能是因为在接收方发送 ACK 应答数据的时候出现了丢包。
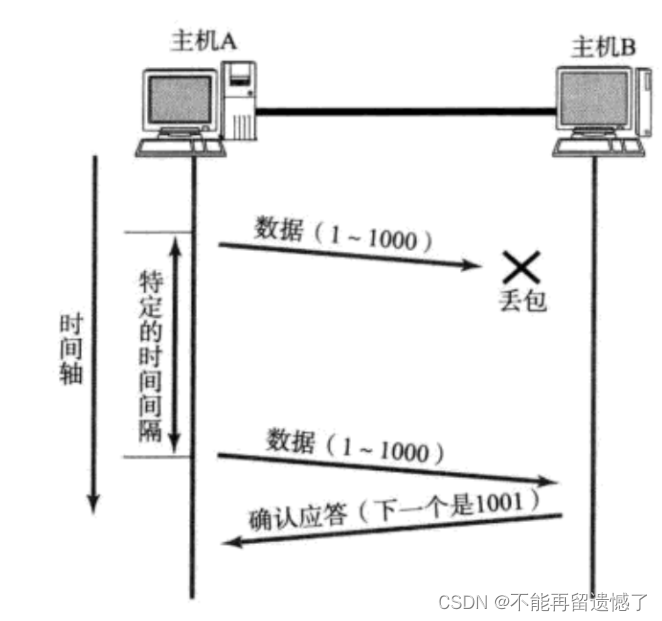
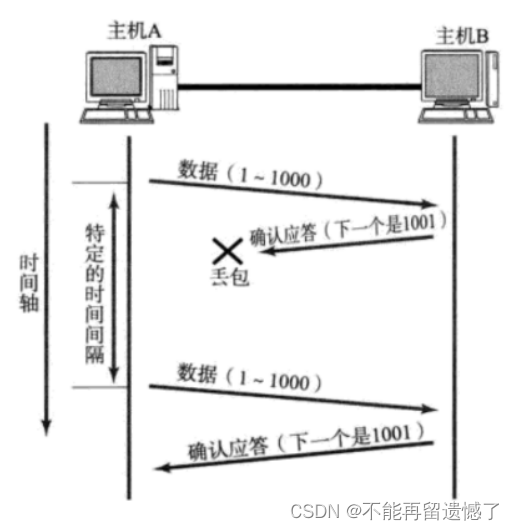
当出现不同情况的丢包的时候,TCP 又会怎么做呢?
因为计算机是非常愚蠢的,它并不知道是在那个过程中发生的丢包,所以这里的应对措施就是无论你哪个阶段发生了丢包,发送方等待一段时间之后如果没有收到应答的话,就会进行重传。
如果重传一次还没有收到应答的话,发送方会再次进行重传并且重传的次数越多,等待的时间机会越长,但也不代表着无限等待重传。当重传几次,时间拉到一定长度之后,就会认为数据再怎么传也是没用了,所以就会放弃这个 TCP 连接,准确点来说就是触发 TCP 的重置连接操作。因为假设网络丢包率为 10%(其实这已经是一个比较大的数字了),当重传两次的时候两次都失败的概率是 1% ,这个概率是非常小的,如果两次重传都失败的话就很可能是网络或者硬件设备出现了问题,你再怎么重传都是没用的。
这里有人可能就会问了?如果是在接收方发送 ACK 应答数据包的时候发生的丢包,然后这里我的发送方等待一段时间没有接收到 ACK 数据包的时候,就会进行超时重传,但是由于第一次发送方发送的数据正常到达了,要是再发一次的话,那么接收方不就是接收到了两份数据(请求)吗?那么这里会不会出现问题呢?答案是肯定的,假如这个是扣款请求呢?但是这里 TCP 对齐做出了相应的措施。
TCP 有一个叫做 接收缓冲区 的概念,上一次接收到的数据,会将这个接收的数据放入接收缓冲区中,当又接收到一个数据的时候,TCP 会先将这个后接受到的数据与接收缓冲区中的数据进行比较,如果发现这个后来的数据和缓冲区当中的数据重复的时候,TCP 会丢弃掉这个后来的重复的数据。
接收缓冲区不仅可以解决收到重复数据的问题,在接收缓冲区当中还可以对数据进行重排序,确保发送的数据和应用程序读取的数据顺序是一样的。
3. 连接管理(三次握手、四次挥手)
三次握手(建立连接)
我们都知道在进行 TCP 通信之前需要保证通信双方建立连接,那么 TCP 的通信双方是如何建立连接的呢?这就需要介绍到面试中的高频考点——三次握手了。
三次握手就相当于通信双方打招呼,告诉对方我要和你建立连接。发送方会先给接收方发送一个 SYN(Synchronize Sequence Numbers)同步报文段,告诉另一方我要和你建立连接,当接收方接收到这个 SYN 同步报文段的时候,接收方会向发送方发送一个 ACK 应答数据包,与此同时,接收方也会向发送方发送一个 SYN,告诉对方我要和你建立连接,当另一方接收到这个 SYN 和 ACK 数据包之后,会返回一个 ACK 数据包。
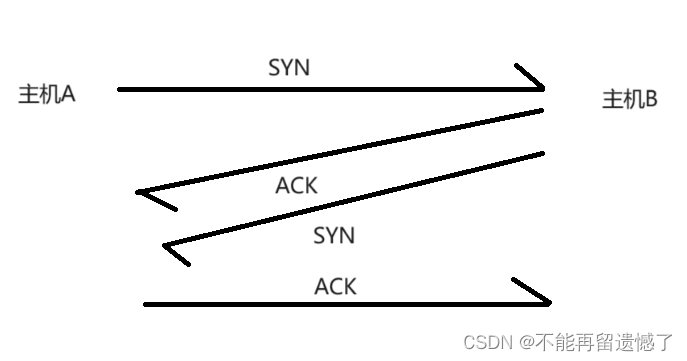
这里又会有人问了,这里不是三次握手吗?为什么会出现发送了四次数据包呢?其实在接收方接收到发送方发送的 SYN 数据包之后,接收方会将 ACK 和 SYN 数据包一起发送给另一方。

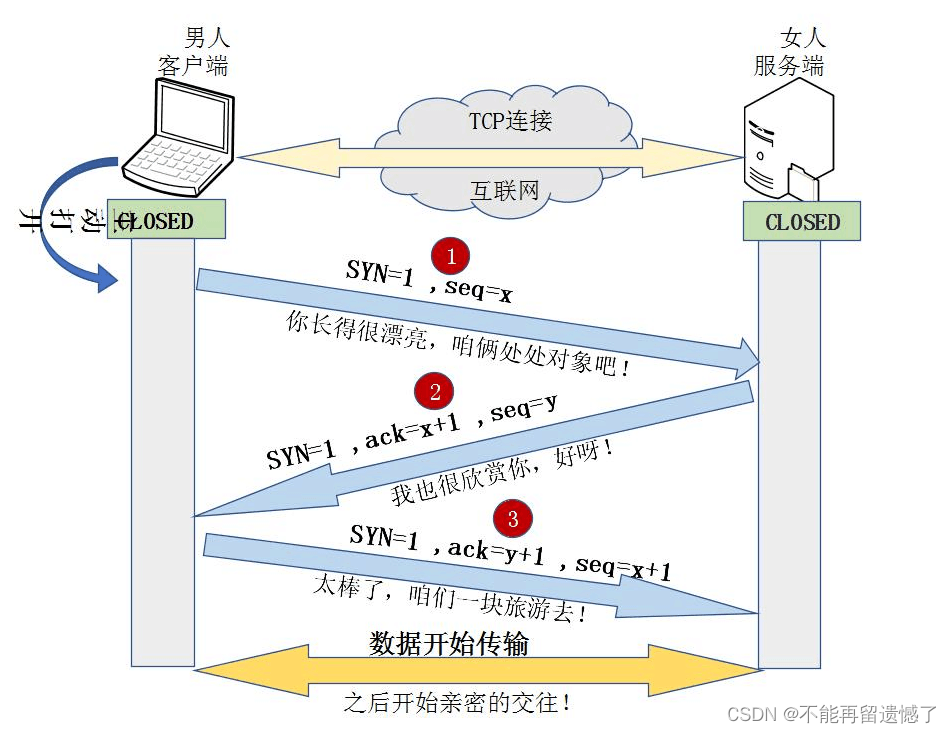
这里如何区别该数据包是 SYN 数据包还是其他的数据包呢?记得前面 TCP 段格式中的 6 个标志位中的 SYN 就是用来记录该数据包是 SYN 数据包还是其他数据包。
三次握手除了能解决通信双方建立连接的问题,它还可以解决什么问题呢?
- 确认当前网络是否通畅
- 让发送方和接收方确认自己的发送和接收能力是正常的
- 针对一些重要的参数进行协商
通信双方进行三次握手建立连接的时候,互相会发送数据包,如果发送的数据包不能到达对方,并且经过几次超时重传之后还是不能到达对方的话,那么就说明此网络不能够正常通信。
当发送方向接收方发送连接请求的时候,接收方接收到请求数据之后,会返回一个 SYN 数据包和 ACK 数据包,那么此时就能证明发送方的发送和接收能力是正常的,接收方的接收能力是正常的;此时发送方又会返回一个 ACK 数据包,当接收方接收到这个 ACK 数据包的时候就可以确定自己的发送能力是正常的。
在通信双方建立连接的时候还会商议好一些参数,例如:“最大消息长度”(MSS:Maximun Segment Size),因为通信双方的硬件设备可能是不同的,所以能允许传输的最大消息长度是不同的,通信双方只能以两方中 MSS 较小的值为标准才能保证数据传输的正常执行。

并且不仅 MSS 需要协商,双方进行通信的时候从哪个序列号开始也是需要商议的,每次协商的时候会选择那个序列号较大的值作为开始序列号。因为在日常生活中,如果网络不太好的话,客户端和服务端之间的连接就会断开,当网络好了的时候,重连之前的数据就会发送过来了,但是这个重连之前的数据是应该被丢弃的,因为它可能会影响现在的业务逻辑。
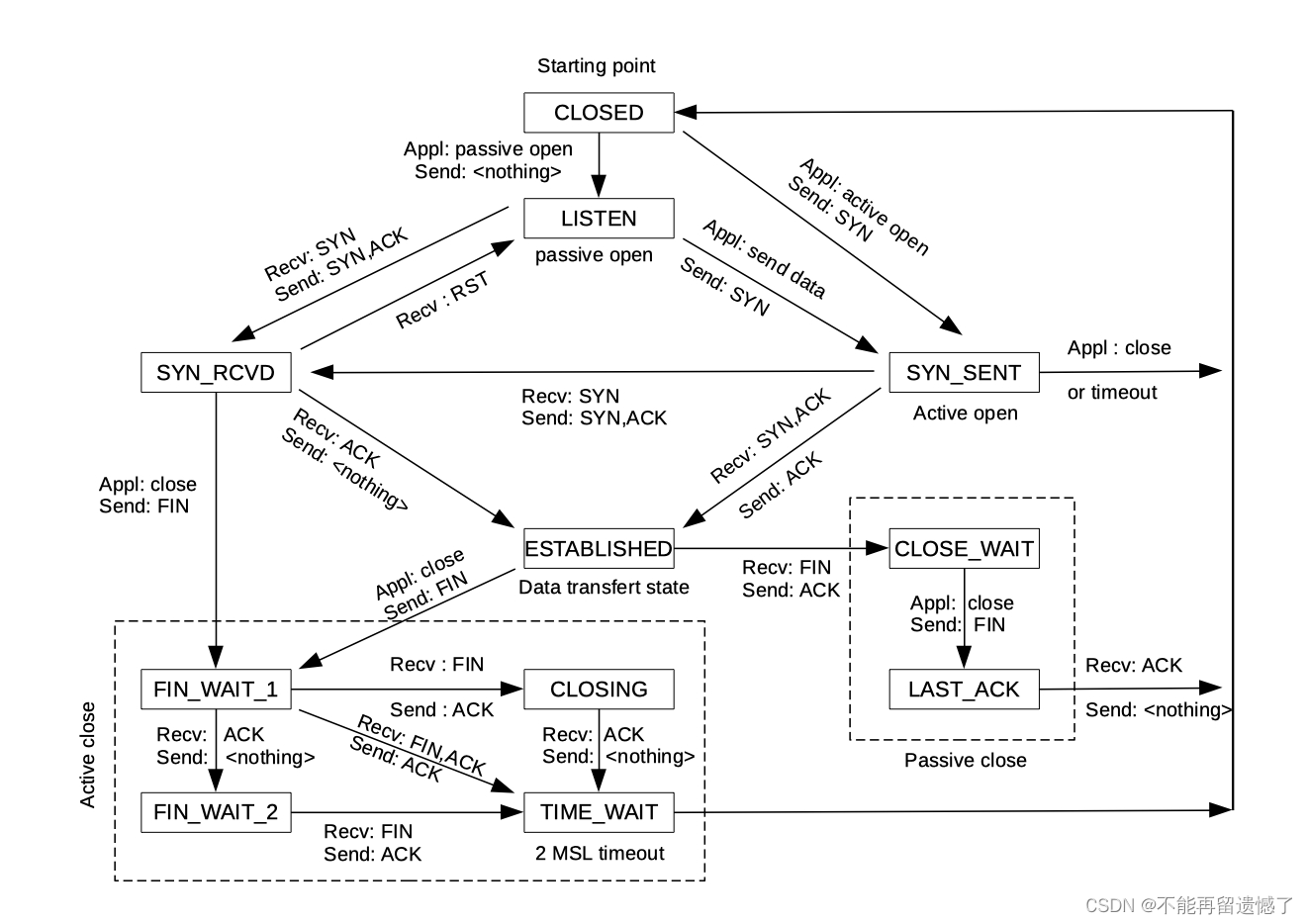
TCP 三次握手的状态转换
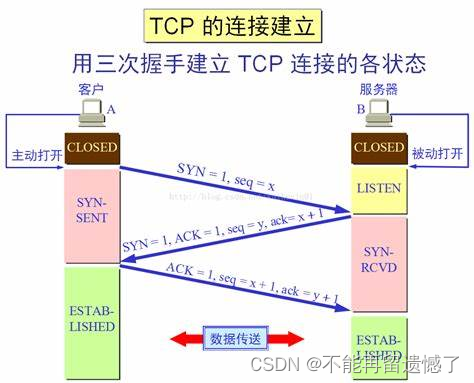
在客户端启动之前,服务端是保证先于客户端开启的,服务端和客户端一开始都处于 CLOSED 状态,当服务端启动之后就处于 LISTEN 状态,等待接收客户端的请求,当客户端启动之后,客户端向服务端发送请求,客户端的状态由 CLOSED -> SYN_SENT ,当服务端接收到客户端传来的请求之后,会向客户端发送一个 ACK + SYN 的数据包,服务端的状态就会由 LISTEN -> SYN_RCVD ,当客户端接收到服务端发送来的相应之后,那么客户端的状态就会转换为 ESTABLISHED 状态,客户端向服务端返回一个 ACK ,客户端接收到这个 ACK 之后,状态就会转换为 ESTABLISHED 状态,当客户端和服务端的状态都由 CLOSED -> ESTABLISHED 就说明双方成功建立了连接。
判断某一个数据包是否为 SYN 数据包或者 ACK 数据包就需要根据 TCP 报头中的 6 个特殊标志位来判断。
四次挥手(断开连接)
当建立了连接的双方需要断开连接的时候,也需要类似三次握手的过程,在这个过程中双方也会发送类似 SYN 和 ACK 这样的具有特殊业务的数据包,只不过当断开连接的时候发送的数据包不是 SYN 而是 FIN 数据包。
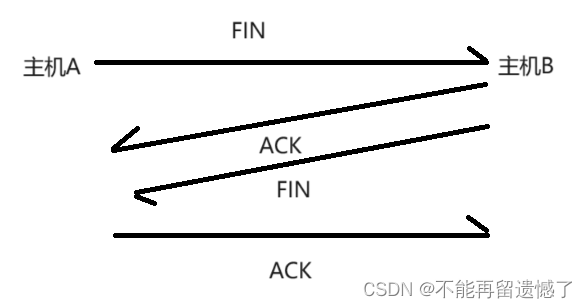
当主机 A 想断掉这次的连接时,就会向主机 B 发送一个 FIN 数据包,当主机 B 接收到这个 FIN 数据包的时候,就会返回一个 ACK 应答数据包,并且还会返回一个 FIN 数据包,当主机 A 接收到 ACK 和 FIN 数据包的时候,就会向主机 B 返回一个 ACK 数据包,当主机 B 接收到这个 ACK 数据包的时候双方的连接就会断开。
那么,这里主机 B 返回的 ACK 和 FIN 数据包是否可以合为一个数据包呢?就跟三次连接时一样呢?答案是不行的。因为 ACK 数据包和 SYN 数据包都是由内核操作发送的,当主机 B 接收到主机 A 发动来的 FIN 时就会立即返回一个 ACK 数据包,而 FIN 数据包则是由用户态操作发送的,而中间需要经历怎样的逻辑代码,我们并不知道,就像我们前面写的 TCP 流套接字一样,在 while 循环和 socket.close() 代码之间可能还会经过很多的代码逻辑才能执行到 close() 方法,所以 ACK 和 FIN 数据包很多情况下都不能合并为一个数据包。
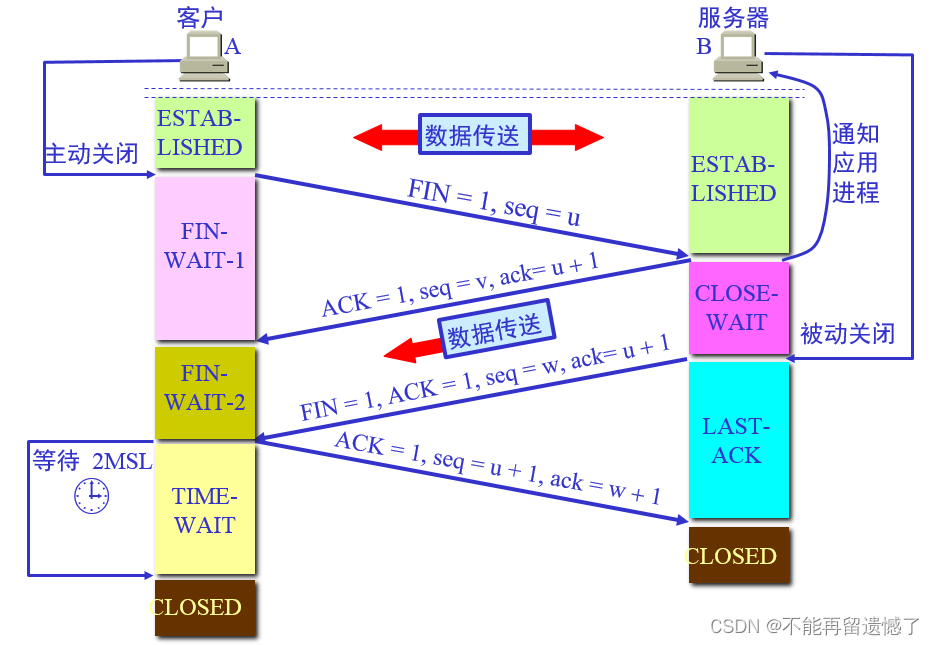
这里四次挥手断开连接和三次握手建立连接还有不同,就是当主机 A 收到主机 B 传来的 ACK 数据包 的时候不是跟建立连接的时候主机 A 发送完 ACK 数据之后就立刻建立起来连接,四次挥手当主机 A 收到 主机 B 传来的 ACK 和 FIN 数据包的时候不会立刻和主机 B 断开连接,而是会等待一段时间,然后再和主机 B 断开连接。
那么,为什么会这样呢?就是如果主机 A 在接收到主机 B 传来的 ACK + FIN 数据包的时候向主机 B 返回 ACK 数据包的时候,主机 A 就会和主机 B 断开连接,但是如果这个 ACK 数据包丢包了的话,那么当主机 B 等待一段时间发现没有接收到这个 ACK 数据包的时候,就会触发超时重传机制,向主机 A 重新发送 ACK + FIN 数据包,但是因为这里主机 A 已经断开了连接,所以这里主机 A 是不能接收到主机 B 重发过来的数据包的,所以就不会返回 ACK 数据包,那么当主机 B 等待一段时间之后又会触发超时重传机制。这样反复几次,当主机 B 确定主机 A 不会有回应的时候,主机 B 就会主动放弃这个连接,换一种说法就是重置这个连接。就会向对端发送一个“复位报文段”,这个“复位报文段”的 RST 标志位为 1 ,如果发送的这个“复位报文段”也没有回应的话,就会自动放弃这个连接。

这个 TIME_WAIT 等待的时间也不是一直等下去的,那么这个等待的时间是多少呢?假设 TCP 报文的最大生存时间是 MSL 那么 TIME_WAIT 等待的时间就是 2MSL 。为什么需要等待 2MSL 时间呢?
IME_WAIT持续存在2MSL能保证在两个传输方向上的尚未被接收或迟到的报文段都已经消失(否则服务器立刻重启,可能会收到来自上一个进程的迟到的数据,但是这种数据很可能是错误的);同时也是在理论上保证最后一个报文可靠到达(假设最后一个ACK丢失,那么服务器会再重发一个FIN。这时虽然客户端的进程不在了,但是TCP连接还在,仍然可以重发LAST_ACK)
通过这个 TIME_WAIT 状态就很好的解决了因返回的 ACK 数据包丢失而造成的另一方需要多次重传数据最终才断开连接的情况。
TCP 状态转移图
4. 滑动窗口
虽然 TCP 的核心是可靠传输,但是也正是因为 TCP 的可靠传输,导致 TCP 的传输效率较低。所以为了解决 TCP 传输效率慢的问题,就又出现了几个机制来优化 TCP 传输效率慢的问题(虽然优化的不多,是亡羊补牢)。
第一个优化就是使用滑动窗口这个机制。什么是滑动窗口机制呢?当 TCP 通信方的一端向另一端发送数据的时候,就需要等待另一端返回 ACK 数据包之后才能继续发送数据,那么在这个等待的过程中这一端基本上干不了什么,就只是等待对端发送 ACK 数据包,那么当要传输的次数很多的话,每次发送数据都需要等待一段时间,那么将这些数据都发送完成就需要很多的时间,所以就出现了滑动窗口。
滑动窗口是值发送方在发送数据的时候会指定一个窗口大小,在这个窗口中的数据可以不用非要等待上一个发送的数据接收到 ACK 数据包之后才继续发送数据,而是当这个数据发送完之后就可以继续发送下一个数据包,当这个窗口中的所有数据包都发送了之后才会进入 TIME_WAIT 状态进入等待,等待另一端的 ACK 数据包,这样就比一个一个等待响应节省很多时间。
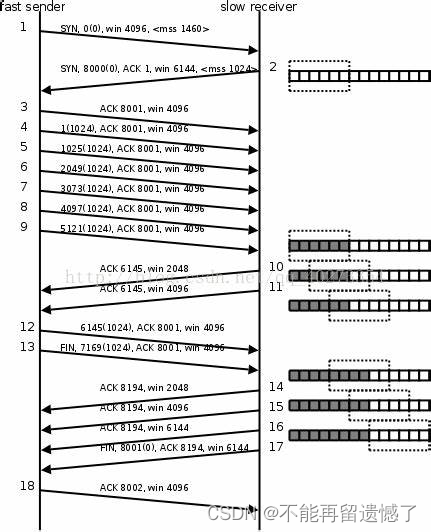
在优化效率的时候,一定要保证 TCP 数据传输的可靠性。在这个滑动窗口的机制下可能会出现丢包的问题,而丢包又分为发送方发送的数据包丢失,接收方返回的 ACK 数据包丢失。
如果是接收方发送的 ACK 包丢失的话,其实影响不大,为什么呢?这里就可以体现出确认序号的强大作用了,返回的确认序号是指在该确认序号之前的所有数据我都已经读取完成了,假设返回的 1001 ACK 数据包丢失的话,但是后面返回了一个 4001 的 ACK 数据包的就表示 4001 之前的所有数据我都已经接收到了,并且通常情况下一个窗口之内总会有一个 ACK 数据包可以成功返回,所以 ACK 数据包丢失的影响不大。
ACK 数据包丢失的影响不大的话,那么发送方发送的数据包丢失的情况下,TCP 又该如何保证可靠传输呢?
假设 1~1000 序列号的数据包丢失了,那么接收方就不会返回带有 1001 确认序号的 ACK 数据包了,当接收方接收到 1001 ~ 2000 序列号之间的数据包的时候,接收方本来应该返回一个带有 2001 确认序号的 ACK 数据包,但是这里不会返回 2001 ,而是会返回一个 1001 ,当下一次接收到 2001 ~ 3000 序列号之间的数据包的时候,接收方还是会返回一个 1001 ACK 数据包,下一次还有数据到来的时候,还是会返回一个 1001 ACK 数据包,当发送方发现收到了三次 1001 确认序号的时候就可以意识到在 1001 序列号之前的一个数据包可能丢失了,那么发送方就会重发这个丢失的数据包。这种重传叫做快速重传,是超时重传的一个变种。
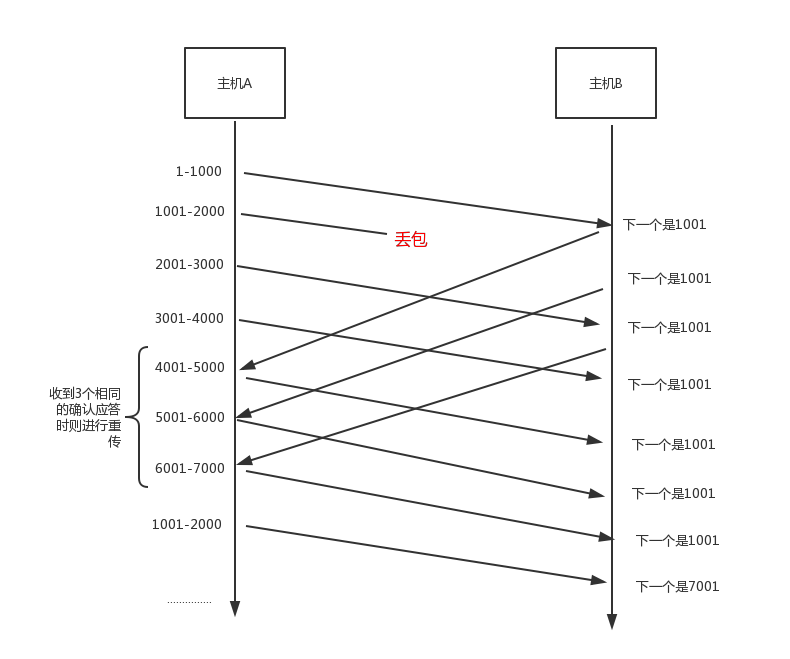
当发送方重发这个 1 ~ 1000 的数据包并且接收方接收到这个数据包的时候,这次不是会返回一个 1001 的确认序号,而是会返回一个原本正确的确认序号,表示该序列号之前的全部数据我都已经成功接收到了。
通过使用滑动窗口的机制 TCP 传输数据的效率会得到优化,理论上:窗口越大,传输效率越高,但是也不代表着窗口的大小可以无限大。如果窗口太大,传输效率很快的话,接收方短时间内接收到的数据太多的话也会发生丢包的现象,那么该如何控制这个窗口的大小呢?这里就又需要使用到一个机制——流量控制。
5. 流量控制
流量控制是根据接收方的接受能力来反向制约发送方发送数据的速度。每次当接收方接受到发送方发送来数据包的时候,接收方会将这个数据包放到接收缓冲区当中,并且接收方会将接收缓冲区的剩余大小通过 ACK 数据包发送给 发送方告诉发送方我还有多少的剩余空间,你下一次滑动窗口的大小不应该超过这个大小。

这个模型就相当于生产者——消费者模型,A是生产者,B是消费者,而接收方 B 的接收缓冲区就类似一个阻塞队列。第一次 A 向 B 发送一个数据包,B 在接收到 A 发送的数据之后就会将 B 缓冲区当中剩余大小 3000 通过 ACK 发送给 A ,A 接收到这个 3000 之后就会控制下次滑动窗口的大小为 3000 ,当 B 再次接收到 A 传来的数据的时候,由于第一次接收到的数据还没有处理完,那么这次传来的数据就会放入到缓冲区当中,此时缓冲区的剩余大小就是 0 了,B 就会将这个 0 返回给 A ,当 A 接收到这个 0 的时候,A 就会进入 TIME_WAIT 状态。等待一段时间之后 A 会向 B 发送一个窗口探测包,这个窗口探测包也没有其他的业务逻辑,就是为了让对端返回一个携带缓冲区大小的 ACK 数据包,如果返回的 ACK 数据包显示缓冲区有剩余空间,那么 A 就会根据这个剩余空间大小指定下次滑动窗口的大小继续传输数据,如果返回的 ACK 数据包显示缓冲区的剩余空间大小还是为 0 的话,会继续等待。
这个缓冲区剩余空间大小会存储在 TCP 报头的 16位窗口大小 中
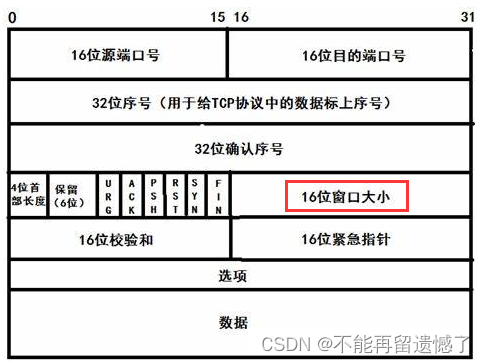
那么这个窗口大小最多只能表示到 64 kb吗,不是的,在选项中还存在一个叫做 窗口扩展因子 来表示窗口大小乘以 2 的多少次方。
流量控制是通过接收能力来反向制约发送方传输数据的机制,但是在网络传输的过程中不止有发送方和接收方需要考虑接收能力,整个通信路上的所有中间节点也需要考虑到接受能力,而考虑通信路径中间节点的接收能力就需要使用到 拥塞控制 这个机制了。
6. 拥塞控制
虽然TCP有了滑动窗口这个大杀器,能够高效可靠的发送大量的数据。但是如果在刚开始阶段就发送大
量的数据,仍然可能引发问题。
因为网络上有很多的计算机,可能当前的网络状态就已经比较拥堵。在不清楚当前网络状态下,贸然发
送大量的数据,是很有可能引起雪上加霜的。
TCP引入 慢启动 机制,先发少量的数据,探探路,摸清当前的网络拥堵状态,再决定按照多大的速度传
输数据;
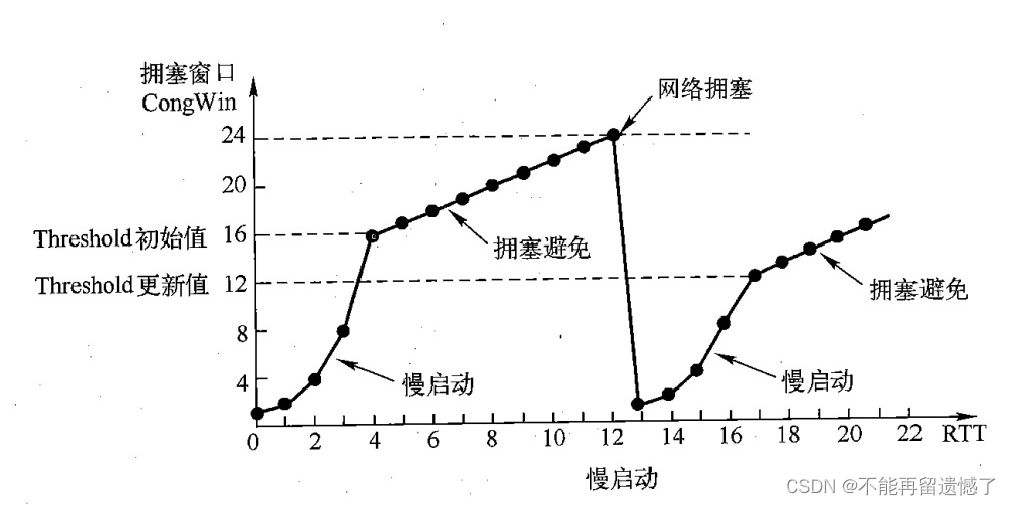
一开始发送的数据大小很小(小窗口),如果当前发送数据的大小不会发生丢包的问题,那么下一次发送的数据的大小就会以 2的次方 增长(增大窗口),当快到达阈值的时候,这个增长速度就会由指数增长转换为线性增长,传输数据的大小会以线性增长的趋势继续增长。当出现丢包的现象时,就会把窗口大小缩小,重新进行前面的 慢开始 -> 指数增长 -> 线性增长 的过程,并且在这个过程中会根据丢包时窗口的大小重新指定线性增长的阈值(为了防止指数增长一下就达到了丢包的极限),慢启动阈值会变成原来的一半,同时拥塞窗口置回1。
但是这个当窗口大小增加到一定程度的时候发生丢包,窗口大小就置为 1 的话,这个窗口大小又需要重复前面的增长过程,这样也会造成效率的变慢,所以这里就做出了优化,不是让窗口大小直接变为 1 ,而是省略了指数增长的过程,直接进行线性增长。
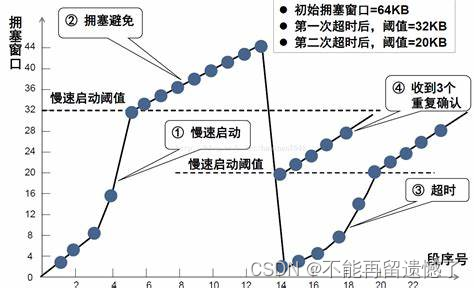
拥塞控制就类似一个不断试错的过程,如果此时窗口大小不会发生丢包的现象,那么下一次传输数据的时候窗口大小就会增大;如果此时窗口大小在传输数据的时候会发生丢包现象,那么下一次传输数据的时候窗口大小就会缩小。
这里流量控制和拥塞控制都是为了确定传输数据的窗口大小,那么这两个究竟以哪个机制的结果为最终窗口的大小呢?答案是:以这两个机制中窗口大小较小的窗口为最终窗口大小。
7. 延时应答
理论上当主机 B 接收到 主机 A 传来的数据包的时候会立即返回一个 ACK 数据包,告诉主机 A 我缓冲区还剩多少空间。但是呢,其实这个 ACK 可以不用立刻返回,而是等主机 B 处理了一些数据之后,重新计算缓冲区剩余空间的大小,然后返回给主机 A ,此时主机 A 收到的主机 B 的缓冲区的剩余空间的大小就更大了,那么下一次主机 A 发送数据的时候窗口的大小就可以更大一些,传输效率就更快一些。

TCP的延时应答是一种提高传输效率的机制,它基于流量控制来引入。通过延迟应答,应用程序能从缓冲区多取走一些数据,使剩余缓冲区空间更大,从而获得一个更大的窗口。实际上,TCP的延迟时间不一定用时间来衡量,有时会用传输轮次来衡量。这种机制的作用是设法使窗口更大一些,以提高TCP的传输效率。
8. 捎带应答
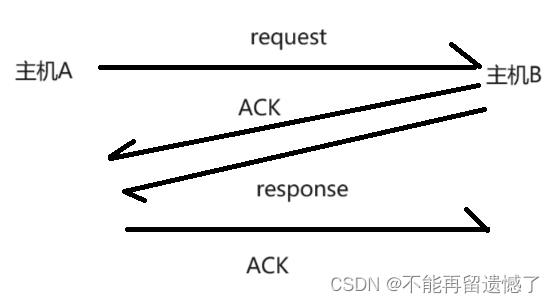
TCP的捎带应答是建立于延迟应答之上的机制。当发送端发送请求给接收端以后,接收端的内核不会立即返回ACK(应答报文)给发送端,而是等待一段时间,这段时间内可以处理发送端传来的请求并计算出响应,然后再将响应与 ACK 合并为一个数据包发送给发送端。这种机制减少了网络中的数据传输量,提高了传输效率。
原本数据传输
捎带应答后数据传输
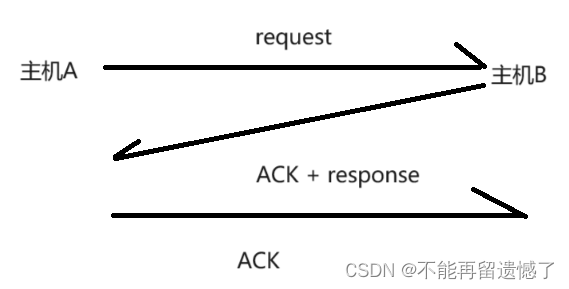
通过捎带应答,就可以使原本应该传输两个数据包的的过程变成了传输一个数据包的过程,提高了传输的效率。
9. 面向字节流
我们都知道 TCP 传输是面向字节流的,既然是面向字节流的那么每次可以传输的数据的大小是可变化的,不像 UDP 将数据打包成数据报的形式进行传输。那么这时就会出现问题:当我一个滑动窗口传入了多个数据报的时候,因为另一端还在处理数据,不能及时处理这些刚传来的数据,那么这些刚传过来的数据就会进入接收缓冲区当中,但是由于 TCP 是面向字节流传输的 ,接收端并不能区别出那些数据是属于一个数据报,哪些数据又是属于另一个数据包。这个现象叫做 粘包 问题。

那么如何解决 TCP 面向字节流传输数据时的无法区别出哪些数据属于一个数据包的情况呢?这就需要程序员在应用层做出协议,就是以什么符号作为不同数据包的分隔符。

这里是以 “\n” 作为不同数据包的分隔符。当然也可以程序员在每个数据包前面加上一个数字表示这个数据包的长度,然后接收端从接收缓冲区读取数据的时候就会先读取到这个长度,然后就会读取这个长度的数据。

这些是需要程序员在应用层自己做出的协议,而实际上有许多现成的协议我们就可以使用。像什么XML 数据格式、 JSON 数据格式和 protobuffer 数据格式都自己规定了数据结束的形式。
10. 异常情况的处理
TCP异常情况的处理机制主要涉及到以下几个方面:
- 进程崩溃。当进程异常崩溃的时候,那么 TCP 的文件描述符表也就会自动释放,就相当于调用了
close()方法,那么此时该进程上的通信方就会触发 FIN ,当对方收到这个 FIN 的时候,就会返回 ACK + FIN ,然后这段再返回一个 ACK ,这也就是正常的四次回收过程。TCP 连接是独立于进程之外的。 - 主机关机。当主机关机的时候也会触发强制关闭进程的操作,就跟 1 问题一样,此时该通信端就会触发 FIN ,当对方接收到了之后就会返回 ACK + FIN ,但是呢这里跟 1 不同的是,就是主机关机了之后整个系统都关闭了,如果再在系统关闭之前该通信端接收到了 ACK + FIN 并且返回了 ACK ,那么就会执行完成正常的 4 次握手;但是如果这端接收到 ACK + FIN 数据包之前系统就关闭的话,那么该端就不会返回 ACK ,当另一端等待一段时间触发超时重传几次没有收到 ACK 的话,就会向对端发送一个“复位报文段”,这个“复位报文段”的 RST 标志位为 1 ,如果发送的这个“复位报文段”也没有回应的话,就会自动放弃这个连接
- 主机掉电。这种情况主机来不及杀进程,也来不及发送 FIN 数据包,主机就会直接停机了。此时站在对端的角度就不知道这个事情怎么搞。
- 如果对端是发送方的话(接收方掉电),那么对端就会等待掉电端发送的 ACK 数据包,一段时间没接收到的话就会触发超时重传,当重传几次还是没收到 ACK 的话,对端就会触发重置功能,向对端发送一个“复位报文段”,但还是不会得到响应,所以对端就会主动放弃这个连接。
- 而如果对端是接收方(发送方掉电),那么对端就无法确认这一端是没有发送消息还是这一端挂了。其实 TCP 提供了 心跳包 这种机制,接收方会周期性的向发送方发送一个心跳包,如果这个心跳包接收到回应了,则说明对端是存活的;而如果对端没有回应并且发送了几次心跳包还是没有回应的话,那么接收方就会主动放弃这个连接。
- 网线断开。这种情况和上面的主机掉电的处理是类似的。如果发送方在发送数据的时候出现网线断开,那么就会触发超时重传 -> 重置连接 -> 单方面断开连接;而接收方则是会向对端发送心跳包 -> 重置连接 -> 单方面释放连接。
TCP 心跳机制
TCP心跳机制是一种用于检测TCP连接是否正常的机制。它通过定时发送心跳包来告知对方自己仍然在线,并检测连接的有效性。心跳包通常是一个自定义的结构体,可以包含简单的信息,如时间戳、序列号等。
TCP的心跳机制有两种实现方式:
客户端发送心跳包:客户端定时向服务器发送心跳包,以告知服务器自己仍然在线。服务器在收到心跳包后,会回复一个确认包给客户端。如果客户端在一定时间内没有收到服务器的确认包,则认为连接已断,需要采取相应的措施,如重新连接或关闭连接。
服务器发送心跳包:服务器也可以定时向客户端发送心跳包,以检测客户端是否在线。客户端在收到心跳包后,会回复一个确认包给服务器。如果服务器在一定时间内没有收到客户端的确认包,则认为客户端已断线,需要采取相应的措施,如关闭连接或通知客户端重新连接。
TCP的心跳机制可以用于长连接的保活和断线处理。在长连接中,由于网络环境复杂多变,连接可能会因为各种原因断开。通过使用心跳机制,可以及时发现连接断开的情况,从而采取相应的处理措施,保证应用的正常运行。
TCP 和 UDP 的对比
TCP的主要优点是可靠性和有序性,适用于对数据完整性要求较高的场景,如文件传输、电子邮件等。而UDP的主要优点是简单和快速,适用于对速度要求较高的场景,如实时音视频传输、在线游戏等。在实际应用中,可以根据具体需求选择使用TCP或UDP。 当传输的文件的大小较大的时候往往选择 TCP ,因为 UDP 的报文长度限制,使得 UDP 不能传输较大的数据。










![[SQL开发笔记]IN操作符: 在WHERE子句中规定多个值](https://img-blog.csdnimg.cn/61963ae9ac534502af20a6d98f5c72cf.png)
