网页解析
- 豆瓣电影
- 解析方式
- 正则表达式
- Xpath
- bs4
- 翻页
- 掌桥科研
- 正则表达式
- Xpath
- bs4
豆瓣电影
解析方式
先爬取数据:
# -- coding: utf-8 --**
import requests
import json
import time
import pandas as pd
url='https://movie.douban.com/top250?start=0&filter='
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
response = requests.get(url=url, headers=header)
print(response)
正则表达式
import re
data = pd.DataFrame()
pattern1 = re.compile(r'<span class="title">([^&]*?)</span>')
titles = pattern1.findall(res.text)
# 通过正则表达式获取class属性为rating_num的span标签并用捕获组提取标签内容
pattern2 = re.compile(r'<span class="rating_num".*?>(.*?)</span>')
ranks = pattern2.findall(res.text)
pattern3 = re.compile(r'<span class="inq">(.*?)</span>')
quito = pattern3.findall(res.text)
data['标题'] = titles
data['评分'] = ranks
data['经典台词'] = quito
data

Xpath
from lxml import etree
import requests
tree = etree.HTML(res.text)
data = pd.DataFrame()
name = []
Ename = []
rate = []
quito = []
for i in range(1,26):
# 通过XPath语法从页面中提取电影标题
title_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[%d]/div/div[2]/div[1]/a/span[1]'% i)
name.append(title_spans[0].text)
Etitle_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[%d]/div/div[2]/div[1]/a/span[2]'% i)
Ename.append(Etitle_spans[0].text[3:])
# 通过XPath语法从页面中提取电影评分
rank_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[%d]/div/div[2]/div[2]/div/span[2]'% i)
rate.append(rank_spans[0].text)
quito_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[%d]/div/div[2]/div[2]/p[2]/span'% i)
quito.append(quito_spans[0].text)
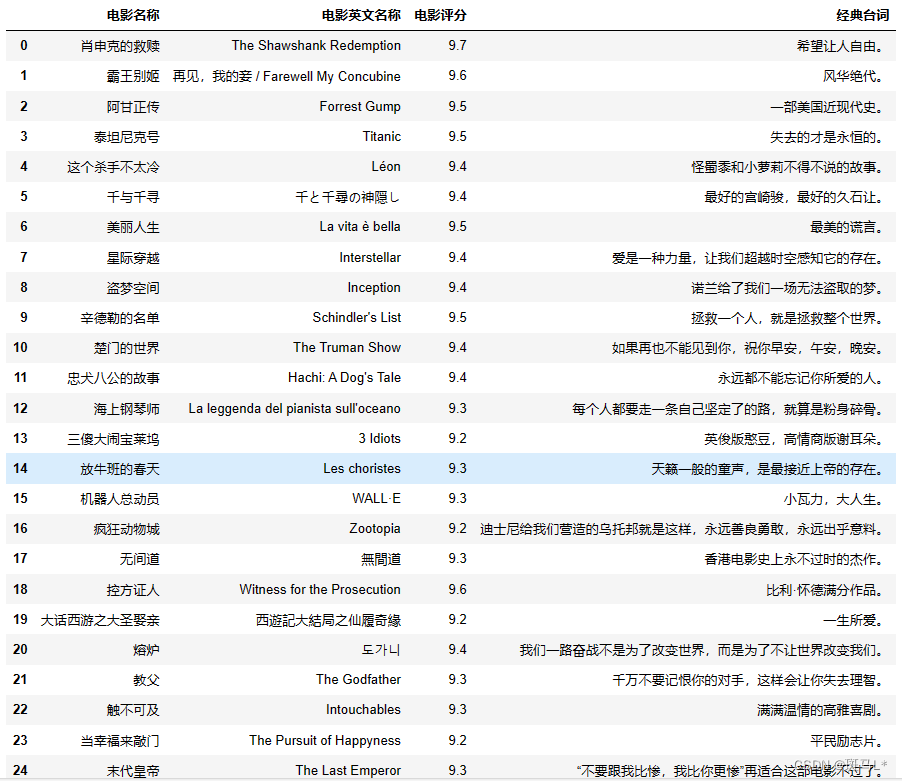
data['电影名称'] = name
data['电影英文名称'] = Ename
data['电影评分'] = rate
data['经典台词'] = quito
data
bs4
from bs4 import BeautifulSoup
soup = BeautifulSoup(res.text,'lxml')
article = soup.find('div',class_="article")
data = pd.DataFrame()
li = article.find_all('li')
name = []
Ename = []
rate = []
quito = []
for l in li:
# print(li[i].find_all('span',class_='title')[0].text)
# print(li[i].find_all('span',class_='rating_num')[0].text)
# print(li[i].find_all('span',class_='inq')[0].text)
name.append(l.find_all('span',class_='title')[0].text)
if len(l.find_all('span',class_='title'))==2:
Ename.append(l.find_all('span',class_='title')[1].text[3:])
else:
Ename.append('-')
rate.append(l.find_all('span',class_='rating_num')[0].text)
quito.append(l.find_all('span',class_='inq')[0].text)
data['电影名称'] = name
data['电影英文名称'] = Ename
data['电影评分'] = rate
data['经典台词'] = quito
data
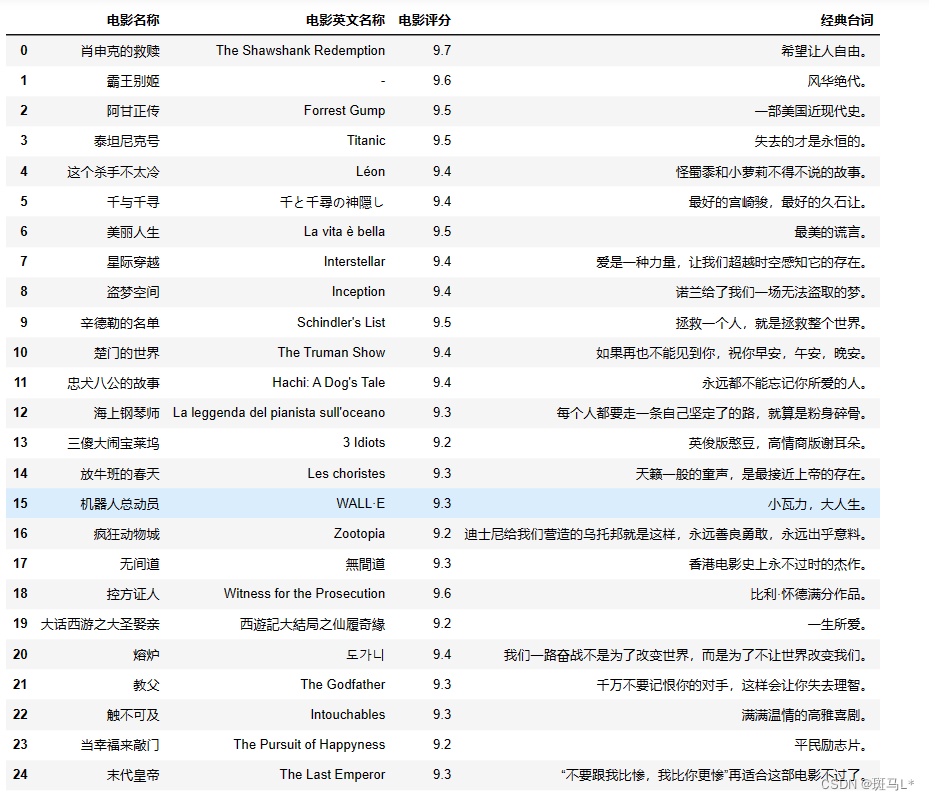
翻页
将上面解析数据的代码定义成函数
结果:
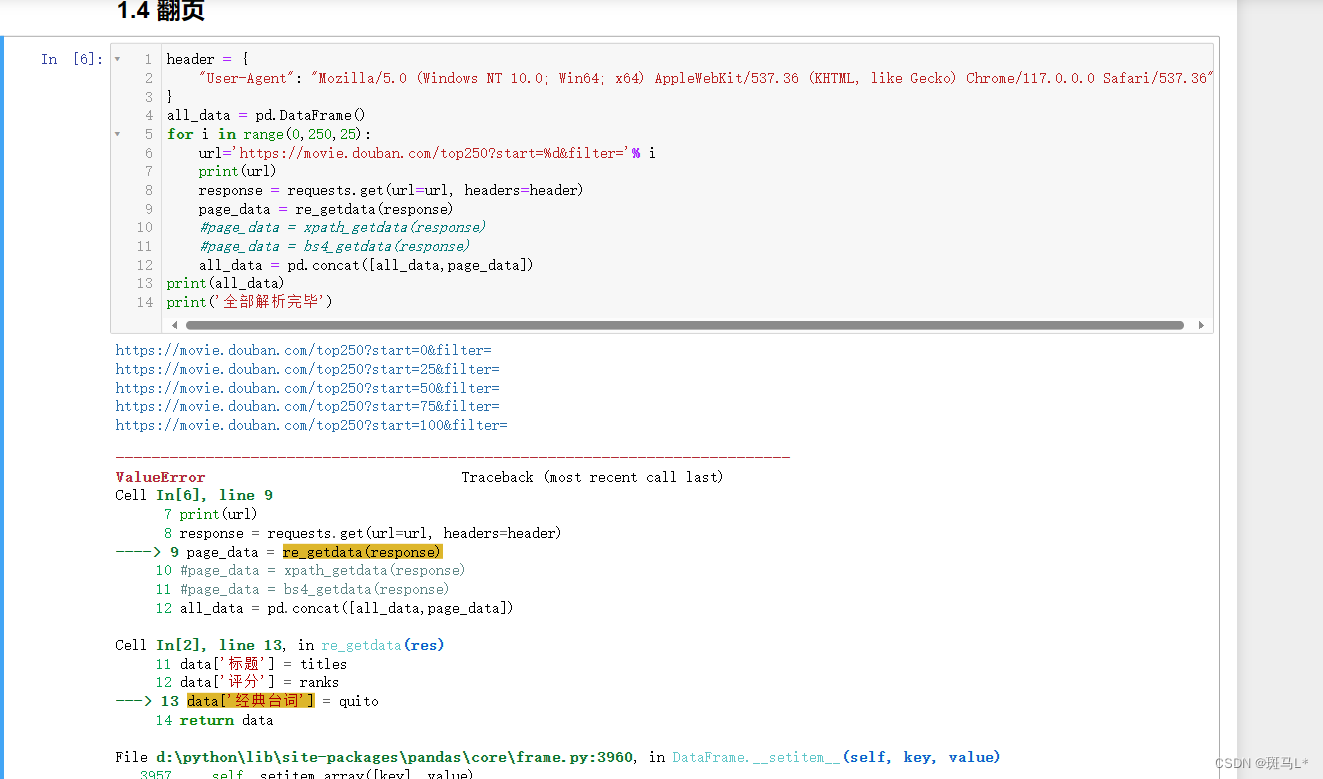
报错了,报错出现在100-125中的某个电影的台词,查看网页发现有一部电影没有一句简描:
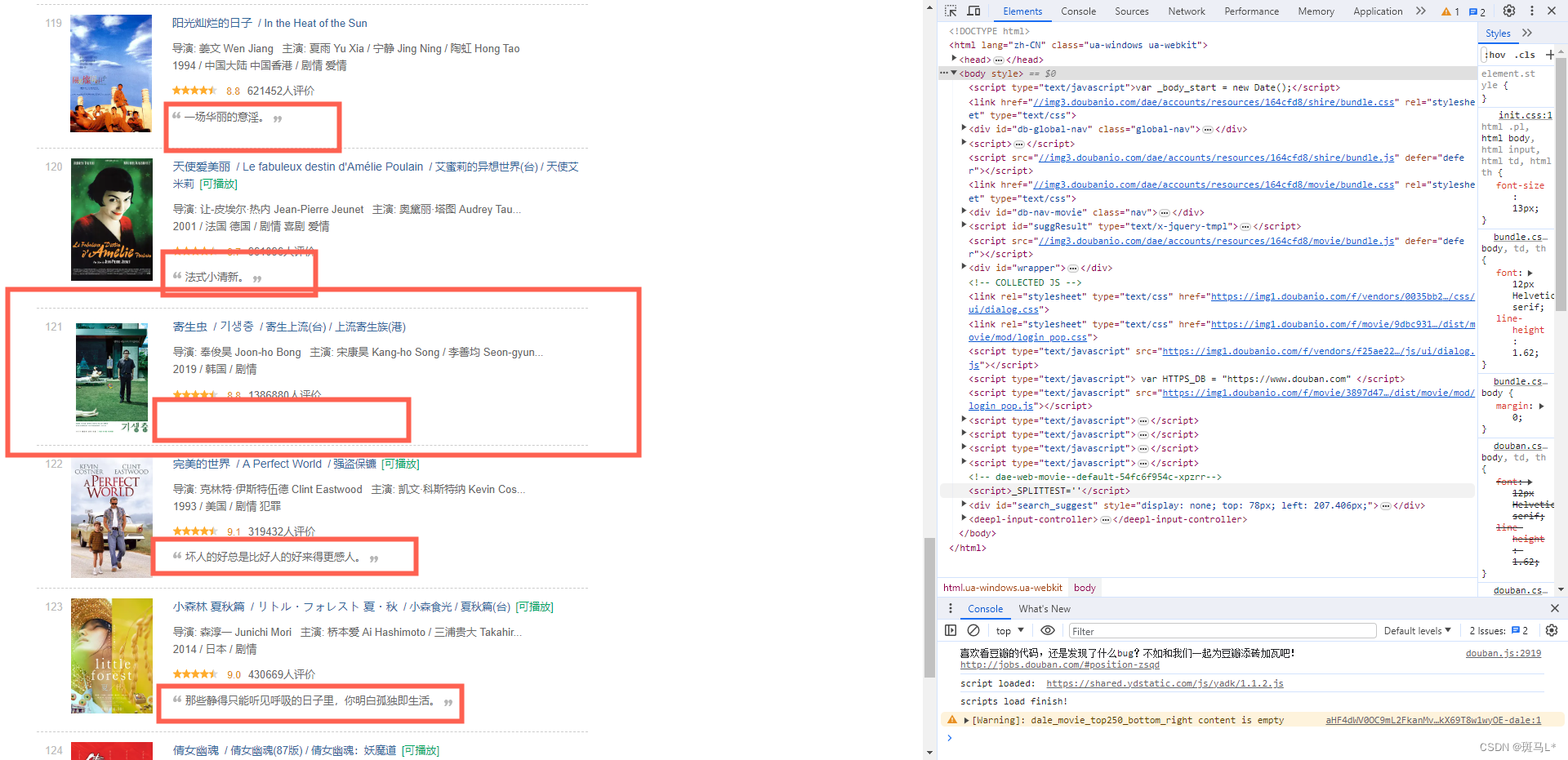
正则直接提取的整页,不方便判断第几个是空缺的,这里直接放弃这个字段(可以尝试正则一个个提取来判断空缺):
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
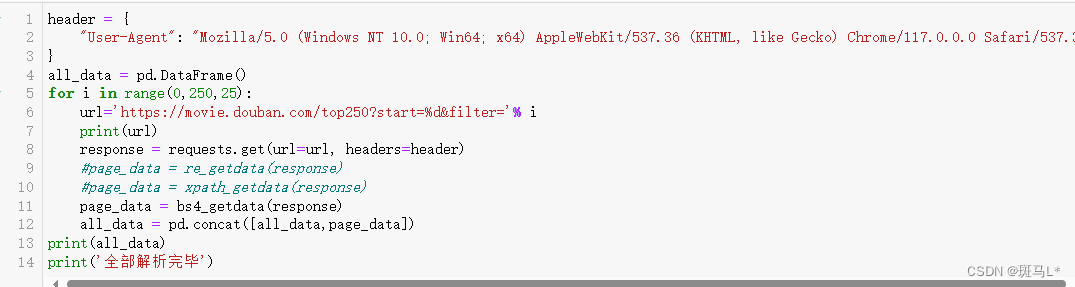
all_data = pd.DataFrame()
for i in range(0,250,25):
url='https://movie.douban.com/top250?start=%d&filter='% i
print(url)
response = requests.get(url=url, headers=header)
page_data = re_getdata(response)
#page_data = xpath_getdata(response)
#page_data = bs4_getdata(response)
all_data = pd.concat([all_data,page_data])
print(all_data)
print('全部解析完毕')
Xpath中加入判断:
from lxml import etree
import requests
def xpath_getdata(res):
tree = etree.HTML(res.text)
data = pd.DataFrame()
name = []
Ename = []
rate = []
quito = []
for i in range(1,26):
# 通过XPath语法从页面中提取电影标题
title_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[%d]/div/div[2]/div[1]/a/span[1]'% i)
name.append(title_spans[0].text)
Etitle_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[%d]/div/div[2]/div[1]/a/span[2]'% i)
Ename.append(Etitle_spans[0].text[3:])
# 通过XPath语法从页面中提取电影评分
rank_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[%d]/div/div[2]/div[2]/div/span[2]'% i)
rate.append(rank_spans[0].text)
quito_spans = tree.xpath('//*[@id="content"]/div/div[1]/ol/li[%d]/div/div[2]/div[2]/p[2]/span'% i)
if len(quito_spans) == 1:
quito.append(quito_spans[0].text)
else:
quito.append('-')
data['电影名称'] = name
data['电影英文名称'] = Ename
data['电影评分'] = rate
data['经典台词'] = quito
return data
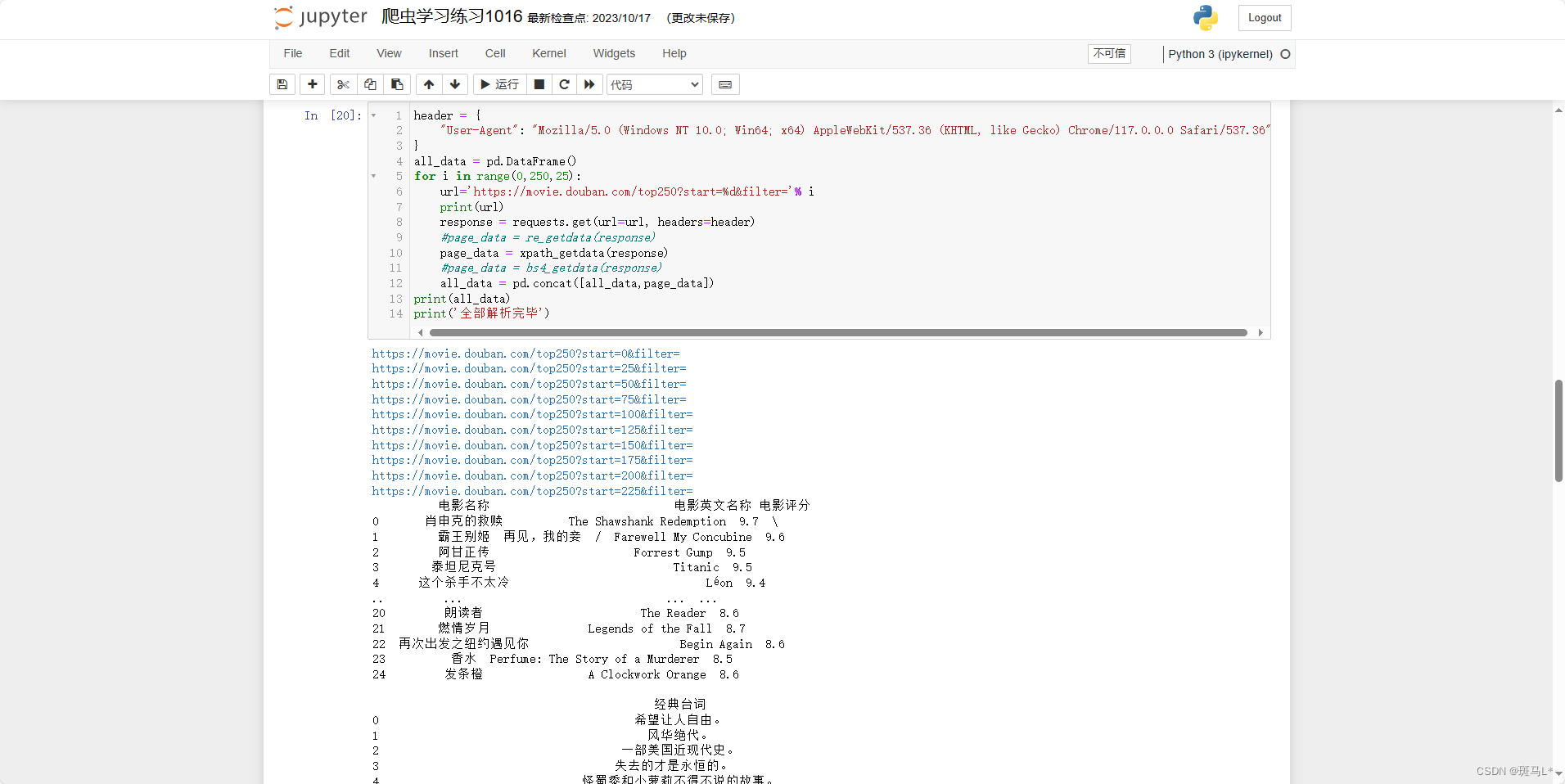
bs4进行相同的更改:
from bs4 import BeautifulSoup
def bs4_getdata(res):
soup = BeautifulSoup(res.text,'lxml')
article = soup.find('div',class_="article")
data = pd.DataFrame()
li = article.find_all('li')
name = []
Ename = []
rate = []
quito = []
for l in li:
# print(li[i].find_all('span',class_='title')[0].text)
# print(li[i].find_all('span',class_='rating_num')[0].text)
# print(li[i].find_all('span',class_='inq')[0].text)
name.append(l.find_all('span',class_='title')[0].text)
if len(l.find_all('span',class_='title'))==2:
Ename.append(l.find_all('span',class_='title')[1].text[3:])
else:
Ename.append('-')
rate.append(l.find_all('span',class_='rating_num')[0].text)
if len(l.find_all('span',class_='inq')) == 1:
quito.append(l.find_all('span',class_='inq')[0].text)
else:
quito.append('-')
data['电影名称'] = name
data['电影英文名称'] = Ename
data['电影评分'] = rate
data['经典台词'] = quito
return data

掌桥科研
先爬取数据:
# -- coding: utf-8 --**
import requests
import pandas as pd
from bs4 import BeautifulSoup
url='https://www.zhangqiaokeyan.com/academic-degree-cn_1/'
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36"
}
res = requests.get(url=url, headers=header)
print(res)
正则表达式
import re
data = pd.DataFrame()
pattern1 = re.compile(r'<a href=.*? target="_blank">(.*?)</a>')
title = pattern1.findall(res.text)
# 通过正则表达式获取class属性为rating_num的span标签并用捕获组提取标签内容
pattern2 = re.compile(r'<div class="item_mid">\s*<span>(.*?)</span>\s*</div>')
year = pattern2.findall(res.text)
pattern3 = re.compile(r'<div class="item_right">\s*<span>(.*?)</span>\s*</div>')
degree = pattern3.findall(res.text)
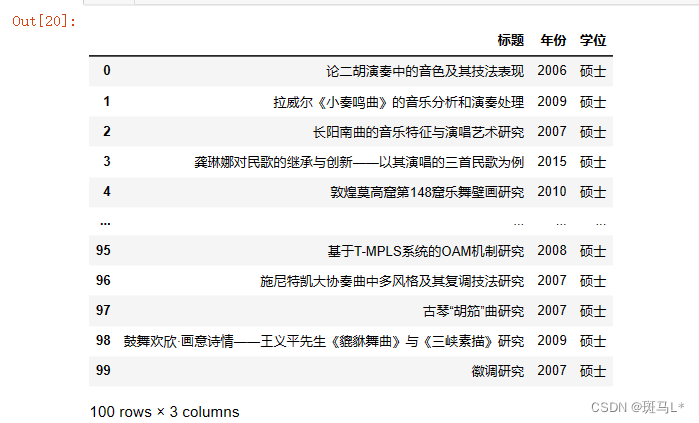
data['标题'] = title[0:100] #匹配到了多的内容
data['年份'] = year
data['学位'] = degree
data
Xpath
from lxml import etree
import requests
tree = etree.HTML(res.text)
data = pd.DataFrame()
title = []
year = []
degree = []
for i in range(2,102):
# 通过XPath语法从页面中提取电影标题
title_spans = tree.xpath('/html/body/div[4]/div[2]/ul/li[%d]/div[1]/div/a'% i)
title.append(title_spans[0].text)
year_spans = tree.xpath('/html/body/div[4]/div[2]/ul/li[%d]/div[2]/span'% i)
year.append(year_spans[0].text[3:])
# 通过XPath语法从页面中提取电影评分
degree_spans = tree.xpath('/html/body/div[4]/div[2]/ul/li[%d]/div[3]/span'% i)
degree.append(degree_spans[0].text)
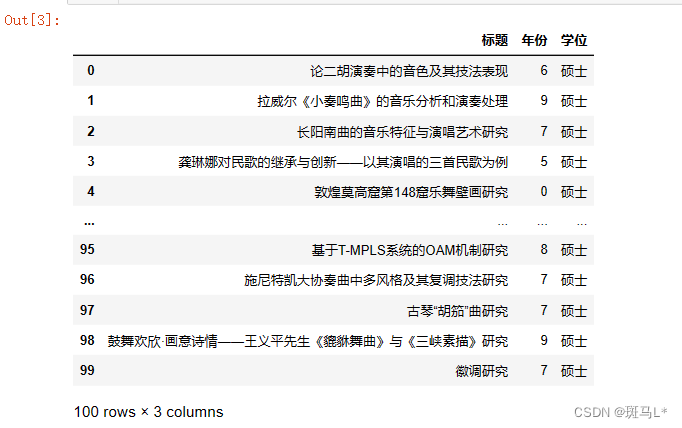
data['标题'] = title
data['年份'] = year
data['学位'] = degree
data
bs4
htm = BeautifulSoup(res.text,'lxml')
ul = htm.find('ul',class_="right_list_3")
li = htm.find_all('li',class_="list_item")
data = pd.DataFrame()
title = []
year = []
degree = []
for i in range(len(li)):
sp = li[i].find_all('div')
title.append(sp[1].find('a').text)
year.append(sp[2].find('span').text)
degree.append(sp[3].find('span').text)
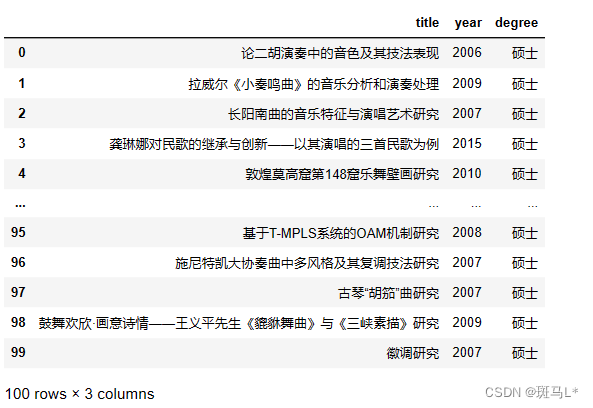
data['title'] = title
data['year'] = year
data['degree'] = degree
data








![[SQL开发笔记]IN操作符: 在WHERE子句中规定多个值](https://img-blog.csdnimg.cn/61963ae9ac534502af20a6d98f5c72cf.png)