一、概念部分
1.1 大数据、数仓、数据湖、中台的概念
| 区别 | 数仓 | 数据湖 |
|---|---|---|
| 使用场景 | 批处理,BI,数据可视化 | 机器学习、预测分析、数据分析 |
| Schema | 写入型 | 读取型 |
| 数据源类型 | OLTP为主的结构化数据 | loT,日志,各个端等结构非结构均可 |
| 性价比 | 需要快速查询,高优化存储需要高成本 | 查询实时性要求地,可使用低成本存储套件 |
| 数据质量 | 高,需要高度监管 | 一般,部分数据无监管 |
| 面对用户 | 业务分析和决策 | 数据开发,数据科学家和业务分析 |
部分参考资料:
数据湖 VS 数据仓库之争?阿里提出大数据架构新概念:湖仓一体-阿里云开发者社区
数据湖是什么_数据湖和数据仓库的差别_数据湖架构-AWS云服务
1.2 数仓分层理论
- 为什么要分层?
- 如何分层?
1.3 数据模型之建模理论
1.4 数据治理:结合项目来沟通
- 数据资源管理:包括但不限于元数据,血缘,共享渠道,权限管控
- 数据质量管控:如何考核质量,如何动态获取,如何处置问题数据
- 数据安全把控:哪些问题需要关注,具体的管控方法如数据分级管理,审计和脱敏等
- SLA:如何高效运维,无法达成的SLA除了技术层面的优化如何通过沟通和任务分级来解决等
- 数据服务输出:API网关,表共享管理,标签/算法等如何更便捷的使用数据
二、技术框架部分
重点考核部分。请各位ETL工程师补充完善。
2.1 Hadoop生态
- yarn的基本理念和底层架构
- hdfs的读写基本流程,数据如何分片,多副本写入算法等
- mr的原理描述
- 目前hadoop的局限不足,有那些优化空间如namenode的瓶颈问题等
2.2 其他大数据技术
- Kafka等消息队列:为什么能做到高吞吐,高性能,one copy原理等
- Flink等实时流处理:双流join,断流监控处理等
- 运维调度工具
2.3 传统数据库的技术问题
- OLAP/OLTP区别
- 传统数据库索引,如mysql的B+树原理解析
2.4 数仓建设的lambda架构
- 实时数仓和离线数仓共存的架构解析
2.5 性能优化相关
- 如果高效使用索引
- 大数据中的数据倾斜及解决方案
- 小文件问题
- 数据建模前的模型设计考量
- 上线后的任务监控和优化
- 服务器资源的监控和调试
三、代码能力
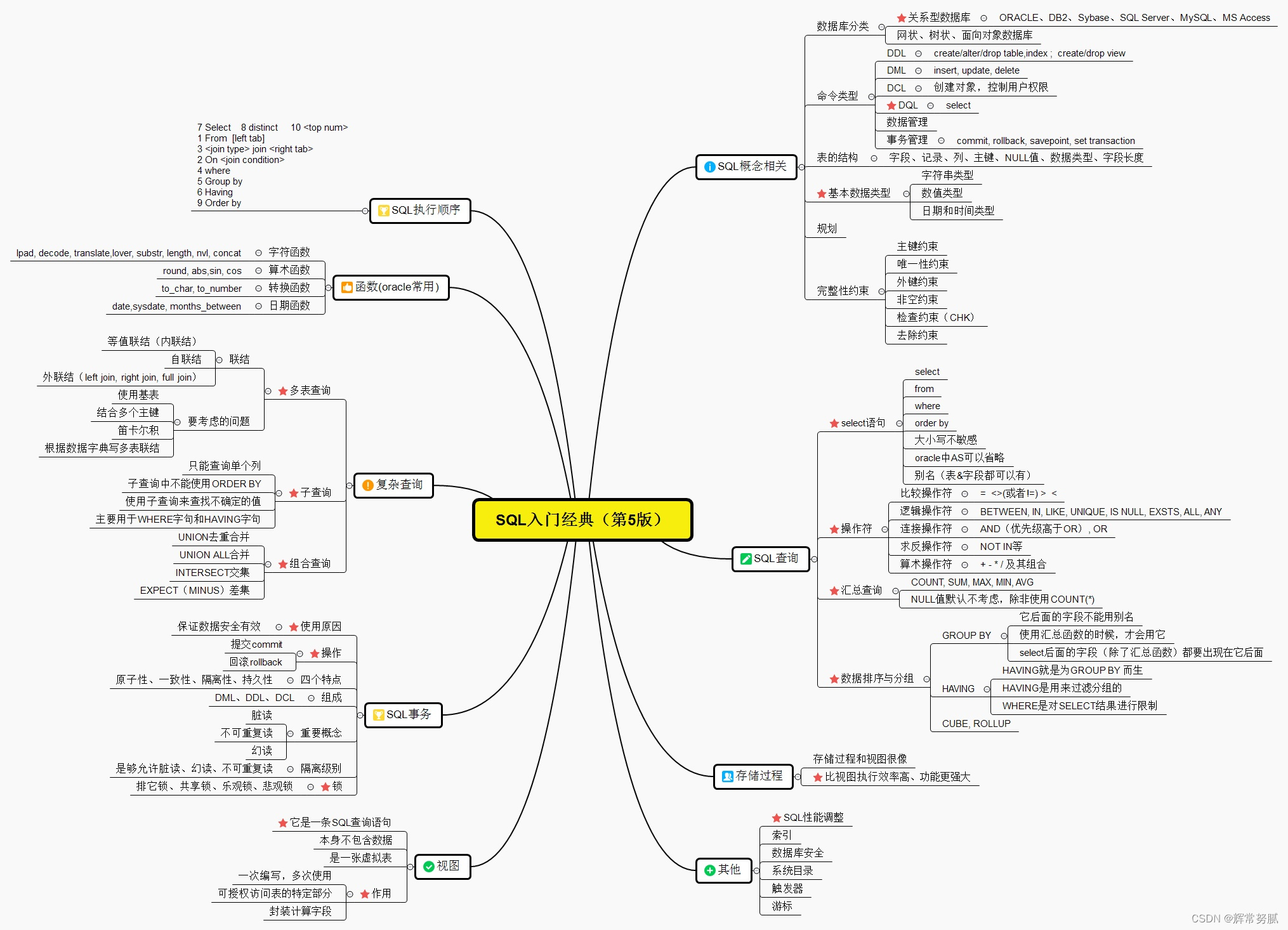
3.1 SQL
- 常用窗口函数考察
- Join相关
- 复制查询如子查询,行转列,排序分组等
3.2 数据结构和算法
目前该部分不做强制要求,是否需要考察需要看候选人背景,有开发背景的可以适当考核。
- 常见数据结构的实现和基本操作:基本的链表(反转,是否有环),二叉树(BFS/DFS,高度等),大小堆(如何创建),hash表(原理和冲突解决),树(BFS/DFS,是否有环)等结构
- 常见的数组操作:几种排序和查找的考察(二分查找及其优化的空间,各种排序原理如选排,插排,冒泡,快排等和时间复杂度),一些简答的如topN大的数查询,寻找重复数字,矩阵转置等
- 常见算法思路:分治,贪心,动规(背包问题),递归回溯(8皇后)原理等
- 综合编码能力考察:java/python任选实现以上问题
四、开放问题
以下问题并没有标准答案,需要去考量解决问题的思路,考察综合能力,如沟通,管理和应急处置等。
4.1 项目中遇到的技术问题
- 项目使用的架构和数据流解析
- 从0搭建的过程中的问题
- 硬件配置如何考量
- 软件如何选型
4.2 项目中遇到的沟通问题
- 项目技术落地推动问题
- 升级沟通
- 交付延期
- 和售前的gap
- 开发团队之间技术gap
4.3 项目中遇到的管理问题
- 人月不足
- 团队流动快
- 人员技术层次不一致
- 日常管理方法
4.4 业务能力考察
- 项目中解决的业务问题:沟通为主
4.5 自我提升
- 如何快速学习新技术
- 项目中完全没遇到过的问题的解决思路