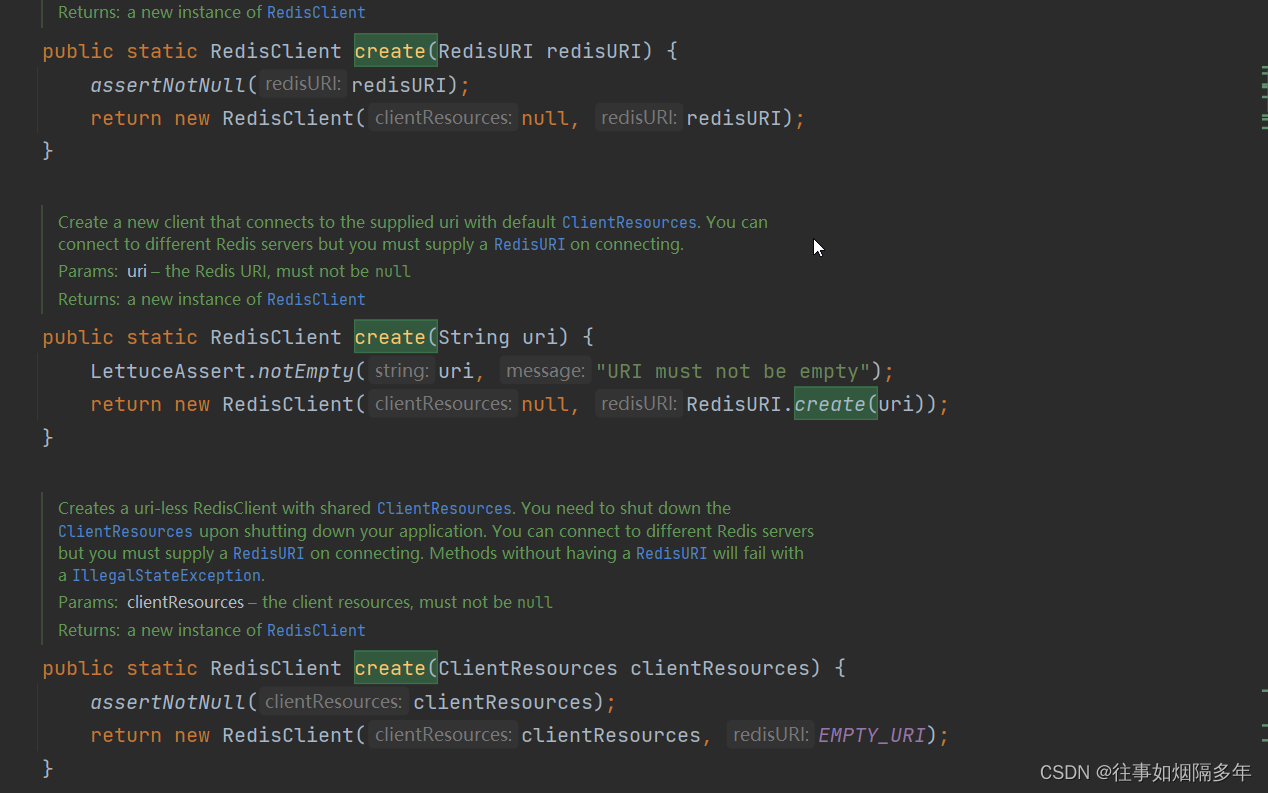
自 LLM 系列文章《知识图谱驱动的大语言模型 Llama Index》、《Text2Cypher:大语言模型驱动的图查询生成》、《Graph RAG: 知识图谱结合 LLM 的检索增强》陆续和大家见面,以及《夜谈 LLM》主题直播同大家交流一番 LLM 和知识图谱、图数据库之后,在上周 NebulaGraph 的研发人员做客开源中国·高手问答活动,同开源中国的大家分享了目前 NebulaGraph 在 LLM 的思考和实践。
此时,距离 ChatGPT 面世已过去半年有余,一起来看看热度散去之后,这项 LLM 技术能给大家带来什么启发和实际效益。
LLM 主题嘉宾
本次做客高手问答的两位 NebulaGraph 研发人员:
- 古思为:GitHub ID @wey-gu,NebulaGraph 布道师,他是首个在 LlamaIndex 社区提出 Graph RAG 概念的人;
- 程训焘:GitHub ID @xtcyclist,NebulaGraph 核心开发者,从事图数据库的开发工作,目前致力于更好地将图数据库与 LLM 结合。
问题汇集
LLM 到底是什么?
iman123 提问:老师你好,现在 LLM 很火,我理解的 LLM 它其实是基于已有的知识、数据,汇聚起来可以给你一些非创造性的答案、建议,例如你无法让他去发现、创造未知的科学,不知道我的理解对不对。LLM 其实未来可以代替一些重复性的人工客服工作以及提高一些工作效率,程序员可能不能完全代替,要是可以自己写代码、调试代码、运行代码,那就真像黑客帝国里面的一样了。
wey-gu:的确呢。不过,写代码的分析、调试借助 Copilot 和 Cursor 这样的 AI 辅助工具,已经可以做到比想象中更智能、流畅了。这有一个例子是 @xtcyclist 提了一个 NebulaGraph 内核改动,我用这些辅助工具,几分钟就找到在 NebulaGraph 哪里修改,怎么做修改的的例子,生成测试代码,参考:https://vimeo.com/858182792
某人gmgn3 提问:老师好,大语言模型 LLM 的优势是什么
wey-gu:优势在于它是一个具有相对足够通识知识的一个感知层,具有通过给定的足够上下文解决领域问题的能力(上下文学习、搜索增强),然而给定足够、相关、准确地上下文有时候是难的,这时候知识图谱就能帮助啦。
clearsky1991 提问:LLM 现在很火,可以部署一些在本地自己使用么,对电脑配置都有什么要求,有哪些类似于 ChatGPT 4 的个人本地使用的开源免费项目推荐么?
wey-gu:可以呀,比如 ChatGLM2-6B,量化之后可以跑在 CPU 上呢。这里有我用 ChatGLM2-6B 和本地 Embedding 模型做 LLM + Graph 的例子,可以先尝鲜:https://www.siwei.io/demo-dumps/local-llm/Graph_RAG_Local.htm
LLM 和知识图谱
拉裤兜兜子 提问:大语言模型 LLM 是否可以协助提取分析数据关键信息生成图数据吗?怎么落地?
wey-gu:当然可以,利用 LLM 做提取、KG 的构建,这里有 Demo:https://www.siwei.io/demos/text2cypher/ 和 https://www.siwei.io/demo-dumps/kg-llm/KG_Building.ipynb 。甚至,我们可以在提取知识的基础上,更进一步结合 LLM + NLP 模型一起做这个事儿,比如:论文 REBEL: Relation Extraction By End-to-end Language generation 就论述这么一个想法。
南小山程序员 提问:老师们好,请问大语言模型 LLM 和知识图谱的相关性或者相似性是怎样的呢?感觉二者有很多相似的地方,如:知识图谱旨在捕捉世界的语义关系,并提供一种有效的方式来查询和推理关于实体之间关系的知识,而大语言模型很大程度上也是一种语义关系、语义理解的作用。二者的共同点和最大的区别点又在什么地方呢?
xtcyclist:知识图谱承载了语义,但它不是捕捉语义关系,它捕捉的是各种概念及其相互关系,也就是知识和知识之间的关系。知识和语言、语义,还是有区别,语言是知识的一种载体。大语言模型是语言模型,它本身是不能胜任对知识以及知识之间的关系进行管理的。所以才会出现在 LLM 的 stack 中使用向量数据库、图数据库来管理领域知识的需求。
Elven_Xu 提问:有个场景问题请教一下,关于知识图谱和LLM,看您上面的回答也讲到了两者之间的关系,知识图谱更重于管理知识与知识之间的关系,LLM更重于知识本身,但是通过向量数据库也可以管理知识与知识之间的关系。不知道我这样理解对不对?
如果我的理解是对的,那么是不是说LLM可以取代知识图谱?如果现在转向LLM,那么是不是可以把知识图谱给砍掉了?还是说只是部分可替代性?没太想明白,想跟老师请教一下,谢谢~
wey-gu:LLM 与 KG/Graph 是彼此成就的,谁也不能替代谁:
- LLM + Data/Knowledge 的应用中(上下文学习)中间比如数据分割的细粒度、对领域知识理解等场景下,KG 的引入可以大大缓解幻觉、增强结果搜索,提高智能应用的效果;
- KG 被应用起来的一大障碍是写查询,Text2GraphQuery 在 LLM 之后变得非常非常便宜、高效;
- KG 的构建过程中,LLM 可以帮到很多
我之前做的一些分享和文章、示例代码里都有提及我提到的三个两者互相帮助的场景,可以关注一下。
LLM 的业务实践
八一菜刀 提问:在图数据库中,关系、节点、属性等数据体现,应用层获取数据时主要通过 GQL 语句获取,那么在和 LLM 大模型结合过程中,请问该如何结合呢?比如针对搜索场景,将用户的输入通过 NLP 转化为 GQL 语句的话,这个范围好像太广了(用户输入千奇百怪),无法聚焦,有什么好的处理经验吗?
wey-gu:简单来说两个思路,Text2Cypher、Graph RAG。前者是把问题直接变为图查询语言 Cypher,后者是把问题中的关键信息抽出来,在知识图谱中查子图,然后构造上下文让 LLM 生成答案。这里已经通过一些方法(比如 Chain-of-Thought)已经把问题拆解成了之后的小问题。具体实现方式可以看一下:https://www.siwei.io/graph-rag/ 或者 https://colab.research.google.com/drive/1tLjOg2ZQuIClfuWrAC2LdiZHCov8oUbs?usp=drive_open#scrollTo=iDA3lAm0LatM ,另外我还做了一个小课程:https://youtube.com/watch?v=hb8uT-VBEwQ&t=2797s&pp=ygU
lvxb 提问:LLM 能应运在短文本分类识别判断?有没有什么实际的案例?
xtcyclist::当然可以啊,文本处理类那当然是大语言模型最擅长的地方了。我博士的组最近做了一个“美投365”的公众号,他们用 LLM 分析美股数据和财经消息,有长有短,然后生成评论文章,里面包括了对文本的分类。
图数据库的技术优劣势
iman123 提问:图数据库我之前接触过 Neo4j,NebulaGraph 相比而言有哪些优缺点呢?
wey-gu:关于图数据库 Neo4j 和 NebulaGraph,NebulaGraph 可以说有一些后发优势。后者是我们创始团队在多年的图存储系统积累之上,用新的存储工程方法和实践,面向分布式、超大规模数据设计的。所以,对于大图、高可用、高并发的场景,或者说业务上图在膨胀的场景,用 NebulaGraph 就自然 scale 就好了。其次,NebulaGraph 基于 Apache 2.0 开源,它是支持分布式部署的。
xiaour 提问:图数据库几年前我在做 AI Music APP 的时候用到过,但是我发现,对于寻求极致性能和效率,市面上的图数据库都是有些瓶颈的,往往需要投入大量资源,或者用户忍受响应延迟;我们该怎么处理对于图数据库方面投入成本和收益的冲突呢?
wey-gu:可以来 NebulaGraph 社区聊聊你的瓶颈,这个项目比较擅长线上高并发的场景,很多国内的社交、生活类大厂在用,分布式的设计使得数据量上来了也不用太操心 scale 的问题。图库作为一个新的系统,一定是有一定的人才投入成本的。不过,这个 ROI 问题在有了 LLM 之后有了一些质的变化:
- 构建 KnowledgeGraph 变容易了;
- 查询 KnowledgeGraph(无论是人还是机器)都可能变得非常容易。
不过总体来说,如果 ROI 在场景中说得通,非常推荐试试把图库加进来,这样可以打开很多潜在的可能性。试想下,你实时在图上获得多跳关联,借助一些可视化工具获得直观的数据关系洞察能力,再在图上做一些算法获得新的 feature 和结论等等。
拉裤兜兜子 问:图数据库和大数据框架计算引擎的结合,效率或者图算法的优势互补怎么更好发挥?
wey-gu:图库的优势是实时性,和图查询、少量计算的灵活表达,劣势在于它不擅长涉及到全图或者部分全图数据量的运算。图计算平台相反,适合全图量的访问以及迭代、计算任务,但是默认来说图计算平台数据的实时性是一个短板(常常是从数仓拉数据)。结合的例子,就是计算平台作为计算层,存储层按需选择图库。像 NebulaGraph 这样的存算分离架构,图计算平台就算是集群内部的异构计算、查询层,结合起来就非常顺滑了。
比如用 NebulaGraph 企业版本 NebulaGraph Explorer + NebulaGraph Analytics,我们可以用 API 或者是浏览器里的所见即所得的界面任意规划图上的复杂计算任务 Pipeline。而在这套系统的底层,我们可以按需选择基于图库的查询,亦或者绕过查询层直接从数据库底层扫全图进行图计算任务。
另外一个例子就是,GNN 在全图上训练得到 Inductive 的模型,然后在线上业务中,实时从 NebulaGraph 抽取相关新插入点的子图(比如 3,000 个点),再作为 input 给模型去推理得到预测结果,也是典型的 GNN + 图库的结合案例。例子项目在这里:https://github.com/wey-gu/NebulaGraph-Fraud-Detection-GNN/
参考文献
如果对 LLM 相关实践感兴趣的话,你可以阅读下面的文稿了解更多知识:
- 图数据库在 CAE 领域的应用论文:A Graph-based Approach to Manage CAE Data in a Data Lake
- Survey of Large Language Models:https://arxiv.org/abs/2303.18223
- 《大语言模型综述》:https://github.com/RUCAIBox/LLMSurvey/blob/main/assets/LLM_Survey__Chinese_V1.pdf
- 思为的 LLM 思考和实践:https://www.siwei.io/categories/llm/
谢谢你读完本文 (///▽///)
图数据库 NebulaGraph Graph for LLM 项目招募实习生中,JD 传送门:数据库内核开发工程师(大模型方向)



![[ACTF2020 新生赛]Exec 1](https://img-blog.csdnimg.cn/img_convert/62a8bb1a1d66e870a5c09ba4c312a9d4.png)