文章目录
- 查看自己显卡的指令
- 框架选什么
- 张量的阶数
- 验证集存在的意义
- 分类问题
- 一般的全连接的代码格式(板子)
- 上面训练的详解
- 一些省略
- 梯度消失和梯度爆炸
- Dropout
- 回归问题
- 一般回归的全连接的板子
- batch-size
- 超参数搜索策略
此系列的深度学习主要是理论性的介绍,具体的实践,到时候可以参考我的另一篇专栏,此系列就是我个人向的学习笔记,此时对于深度学习的理解还是不够深刻,勿怪。
查看自己显卡的指令
在jupyter当中:
!nvidia-smi
linux下:
nvidia-smi
windows:
直接我的电脑 管理,直接看,或者电脑本身就知道了。
框架选什么
对于现在也就是2023/10/23日来说(叠加),框架的选择主要也就只有两种选择方法:
- tensorflow
- pytorch
其他的框架相对于这两款都不温不火,但二者非要我来说:
学tensorflow只会让你变成tf男孩,pytorch才是天(bushi),tensorflow适合开发,pytorch适合科研,但个人建议还是选择pytorch吧,tensorflow太答辩了,特别是1.0 与 2.0的问题,版本甚至不向前兼容啥的。也能理解,但就造成了之前的代码不可使用。
此篇文章为了讲解相关的原理,暂时使用tensorflow的2.8版本进行介绍,之后会再出一版pytorch放在一个新的专栏当中的。
张量的阶数
- 向量数据:2D张量,形状为(samples, features)。
- 时间序列数据或序列数据:3D张量,形状为(samples, timesteps, features)。
- 图像:4D张量,形状为(samples, height,width, channels)或(samples, channels,height,width)。
- 视频:5D张量,形状为(samples,frames, height,width, channels)或(samples,frames, channels, height, width)
验证集存在的意义
评估模型的重点是将数据划分为三个集合:训练集、验证集和测试集。在训练数据上训练模型,在验证数据上评估模型。一旦找到了最佳参数,就在测试数据上最后测试一次。
你可能会问,为什么不是两个集合:一个训练集和一个测试集?在训练集上训练模型,然后在测试集上评估模型。这样简单得多!原因在于开发模型时总是需要调节模型配置,比如选择层数或每层大小[这叫作模型的超参数(hyperparameter),以便与模型参数(即权重)区分开]。这个调节过程需要使用模型在验证数据上的性能作为反馈信号。这个调节过程本质上就是一种学习:在某个参数空间中寻找良好的模型配置。因此,如果基于模型在验证集上的性能来调节模型配置,会很快导致模型在验证集上过拟合,即使你并没有在验证集上直接训练模型也会如此。
造成这一现象的关键在于信息泄露(information leak)。每次基于模型在验证集上的性能来调节模型超参数,都会有一些关于验证数据的信息泄露到模型中。如果对每个参数只调节一次,那么泄露的信息很少,验证集仍然可以可靠地评估模型。但如果你多次重复这一过程(运行一次实验,在验证集上评估,然后据此修改模型),那么将会有越来越多的关于验证集的信息泄露到模型中。
最后,你得到的模型在验证集上的性能非常好(人为造成的),因为这正是你优化的目的。你关心的是模型在全新数据上的性能,而不是在验证数据上的性能,因此你需要使用一个完全不同的、前所未见的数据集来评估模型,它就是测试集。你的模型一定不能读取与测试集有关的任何信息,既使间接读取也不行。如果基于测试集性能来调节模型,那么对泛化能力的衡量是不准确的。
将数据划分为训练集、验证集和测试集可能看起来很简单,但如果可用数据很少,还有几种高级方法可以派上用场。我们先来介绍三种经典的评估方法:简单的留出验证、K 折验证,以及带有打乱数据的重复 K 折验证。
关于信息泄露比较白话的说法就是,我们实际上自己在调整超参数的时候,我们看到了相对应的正确率,然后我们会根据这个正确率或者损失大小,去手动再进行调整超参数,这样会造成什么情况呢?当我们的数据只有数据集和测试集的时候,我们人为调整的过程,实际上等效于将我们的数据训练出来的东西,去接近测试集,但是我们在生活中的产品的使用中,并不存在这种情况,我们生活中,在测试的时候,都是只测试一次的,这就造成了认为产生的信息泄露。
也就是说验证集的作用就是:相对于只有测试集的,避免人工调参的信息泄露。
分类问题
一般的全连接的代码格式(板子)
pytorch的板子之后再整理。
tensorflow:
import numpy as np
import pandas as pd
from tensorflow import keras
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
import os
import matplotlib.pyplot as plt
# 数据准备
#----------------------------------------------------------------------
# fashion_mnist图像分类数据集 这个数据集就是一个比较出名的分类的数据集,用于将一个图片分类成10个时尚品的类别
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
# 得到的是np 也是把数据集分成三个部分,数据集验证集和测试集。
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
#----------------------------------------------------------------------
# 特征工程
#----------------------------------------------------------------------
# 标准化
scaler = StandardScaler()
# x_train: [None, 28, 28] -> [None, 784]
x_train_scaled = scaler.fit_transform(x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28)
x_valid_scaled = scaler.transform(x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28)
x_test_scaled = scaler.transform(x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28)
#----------------------------------------------------------------------
# 构造神经网络dnn 这边也可以使用类来实现不用用这个Sequential进行实现,这边只是给个例子,后面回归会使用类
#----------------------------------------------------------------------
model = keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28, 28]))
for _ in range(20):
model.add(keras.layers.Dense(100, activation="selu"))
# 批处理正则化
# model.add(keras.layers.BatchNormalization())
model.add(keras.layers.AlphaDropout(rate=0.2))
# AlphaDropout相对于普通Dropout优势: 1. 均值和方差不变 2. 归一化性质也不变
# model.add(keras.layers.Dropout(rate=0.5))
# 分类网络的最后一层使用softmax 进行概率统一化
model.add(keras.layers.Dense(10, activation="softmax"))
#----------------------------------------------------------------------
# 定义最后的目标(损失)函数 优化器(也就是优化的方向,这边sgd就是随机下降梯度算法,传入的就是默认的学习率) metric算子就是需要计算什么,后面打印用
#----------------------------------------------------------------------
# sparse_categorical_crossentropy和categorical_crossentropy的区别就是前者用的是整数后者用的是one-hot编码
#
model.compile(loss="sparse_categorical_crossentropy",optimizer = keras.optimizers.SGD(0.001),metrics = ["accuracy"])
#----------------------------------------------------------------------
# callbacks和保存模型
#----------------------------------------------------------------------
logdir = './dnn-selu-dropout-callbacks'
if not os.path.exists(logdir):
os.mkdir(logdir)
output_model_file = os.path.join(logdir,"fashion_mnist_model.h5")
# 第二个参数就是保存的位置和只保存最佳的参数
# 第三个就是当性能(默认是val_loss)连续五次的变化(epoch)不超过1e-3,就直接停止
callbacks = [
keras.callbacks.TensorBoard(logdir),
keras.callbacks.ModelCheckpoint(output_model_file,save_best_only = True),
keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3),
]
#----------------------------------------------------------------------
# 开始训练
#----------------------------------------------------------------------
history = model.fit(x_train_scaled,y_train,epochs=10,
validation_data=(x_valid_scaled, y_valid),
callbacks = callbacks)
# 训练的时候会自动打印那些正确率啥的,还有就是你前面加的算子
#----------------------------------------------------------------------
# 画图
#----------------------------------------------------------------------
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)
#----------------------------------------------------------------------
# 评估模型
#----------------------------------------------------------------------
model.evaluate(x_test_scaled, y_test, verbose=0)
#----------------------------------------------------------------------
输出:
(5000, 28, 28) (5000,)
(55000, 28, 28) (55000,)
(10000, 28, 28) (10000,)
Epoch 1/10
1719/1719 [==============================] - 16s 8ms/step - loss: 0.8931 - accuracy: 0.6938 - val_loss: 0.5760 - val_accuracy: 0.8026
Epoch 2/10
17/1719 [..............................] - ETA: 11s - loss: 0.6089 - accuracy: 0.7739/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py:3000: UserWarning: You are saving your model as an HDF5 file via `model.save()`. This file format is considered legacy. We recommend using instead the native Keras format, e.g. `model.save('my_model.keras')`.
saving_api.save_model(
1719/1719 [==============================] - 16s 9ms/step - loss: 0.5796 - accuracy: 0.7998 - val_loss: 0.5197 - val_accuracy: 0.8270
Epoch 3/10
1719/1719 [==============================] - 13s 7ms/step - loss: 0.5043 - accuracy: 0.8278 - val_loss: 0.4659 - val_accuracy: 0.8504
Epoch 4/10
1719/1719 [==============================] - 13s 7ms/step - loss: 0.4571 - accuracy: 0.8411 - val_loss: 0.4407 - val_accuracy: 0.8544
Epoch 5/10
1719/1719 [==============================] - 13s 7ms/step - loss: 0.4280 - accuracy: 0.8504 - val_loss: 0.4318 - val_accuracy: 0.8618
Epoch 6/10
1719/1719 [==============================] - 13s 7ms/step - loss: 0.4056 - accuracy: 0.8566 - val_loss: 0.4215 - val_accuracy: 0.8660
Epoch 7/10
1719/1719 [==============================] - 13s 7ms/step - loss: 0.3873 - accuracy: 0.8621 - val_loss: 0.4584 - val_accuracy: 0.8532
Epoch 8/10
1719/1719 [==============================] - 13s 7ms/step - loss: 0.3694 - accuracy: 0.8692 - val_loss: 0.4269 - val_accuracy: 0.8716
Epoch 9/10
1719/1719 [==============================] - 13s 7ms/step - loss: 0.3582 - accuracy: 0.8727 - val_loss: 0.4026 - val_accuracy: 0.8738
Epoch 10/10
1719/1719 [==============================] - 13s 8ms/step - loss: 0.3469 - accuracy: 0.8766 - val_loss: 0.4028 - val_accuracy: 0.8712
图片见下
[0.4599243104457855, 0.8568000197410583]
图片:
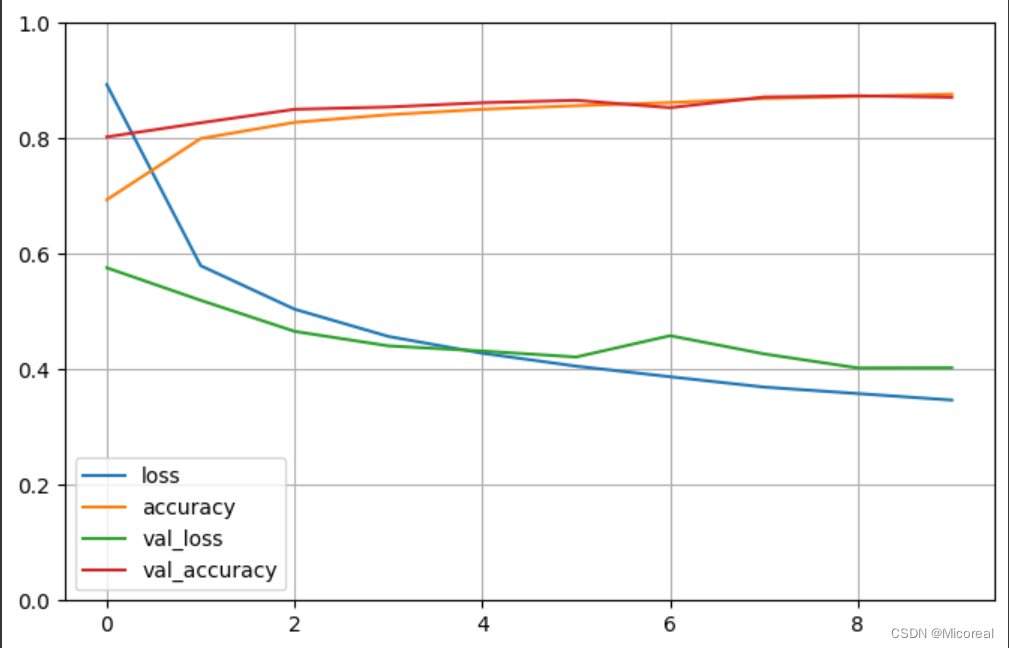
上面训练的详解
- loss:训练集损失值
- accuracy:训练集准确率
- val_loss:测试集损失值
- val_accruacy:测试集准确率
以下 5 种情况可供参考:
- train loss 不断下降,test loss 不断下降,说明网络仍在学习;(最好的)
- train loss 不断下降,test loss 趋于不变,说明网络过拟合;(max pool 或者正则化)
- train loss 趋于不变,test loss 不断下降,说明数据集 100%有问题;(检查 dataset)
- train loss 趋于不变,test loss 趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;(减少学习率)
- train loss 不断上升,test loss 不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
一些省略
关于前向传播, 反向传播,很早之前就已经写过一版了,这边也不赘述。
梯度消失和梯度爆炸
梯度消失和梯度爆炸的原因都是一致的,我们在链式求导法则当中是一系列连乘的效果,这种值在没有进行约束的情况下,会造成什么效果呢? 要么就是他会让我们的梯度几乎不变化,要么就是他会让我们的梯度变化巨大,这就分别就是梯度消失和梯度爆炸,(w-学习率*导数),(导数=链式求导)。
那由于这种原因,我们的解决方法就是把每一层的神经网络的输出,加上一层bn(批归一化),就是把那些数值非线性的放到对应的位置上,这个确实可以解决,但是每层都加,会大大减缓这种问题的发生
相同的,我们也可以从别的地方下手,比如我们可以从激活函数下手,我们发现我们在每一层上加上了sigmoid函数之后,会把原本的数据映射到0-1之间,求导之后就很容易会造成梯度消失,转而我们可以替换成relu或者selu这种比较优良的算法。
Dropout
上面的代码中我们采用的是AlphaDropout,这个和普通的Dropout有什么区别吗?正常的是全随机的去除某几个点,或者说是将其w变为0,进行训练,而AlphaDropout做到的是伪随机,是在不改变分布的情况下的伪随机。(参数是去掉多少百分比的点,一般10%-20%之间吧,个人感觉)。
回归问题
实际上我们仅从肉眼看分类问题和回归问题,我们并不能看出二者的差别是什么,可能唯一的区别就是对于回归问题,我们需要改变其损失函数,最后不需要加上softmax层,将参数概率化这一步吧。
这边举一篇比较经典的例子:Wide&Deep论文,也可以当作回归的板子来使用
一般回归的全连接的板子
import numpy as np
import pandas as pd
from tensorflow import keras
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
import os
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
# 准备数据集 验证集 测试集
# -----------------------------------------------------------------------------
housing = fetch_california_housing()
print(housing.data.shape)
print(housing.target.shape)
x_train_all, x_test, y_train_all, y_test = train_test_split(housing.data, housing.target, random_state = 7)
x_train, x_valid, y_train, y_valid = train_test_split(x_train_all, y_train_all, random_state = 11)
# -----------------------------------------------------------------------------
# 特征工程
# -----------------------------------------------------------------------------
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.transform(x_valid)
x_test_scaled = scaler.transform(x_test)
# -----------------------------------------------------------------------------
# 用类的方式构建模型
# -----------------------------------------------------------------------------
class WideDeepModel(keras.models.Model):
def __init__(self):
super().__init__()
"""定义模型的层次"""
self.hidden1_layer = keras.layers.Dense(30, activation='relu')
self.hidden2_layer = keras.layers.Dense(30, activation='relu')
self.output_layer1 = keras.layers.Dense(1)
def call(self, input):
"""完成模型的正向计算"""
input1,input2 = input
hidden1 = self.hidden1_layer(input1)
hidden2 = self.hidden2_layer(hidden1)
concat = keras.layers.concatenate([input2, hidden2])
output1 = self.output_layer1(concat)
output2 = input1
return [output2,output1]
# -----------------------------------------------------------------------------
model = WideDeepModel()
model.build(input_shape=[(None, 5),(None,6)])
print(model.summary())
model.compile(loss=["mean_squared_error","mean_squared_error"],optimizer = keras.optimizers.SGD(0.001))
callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-2)]
history = model.fit([x_train_scaled[:,:5],x_train_scaled[:,2:]], [y_train,y_train],
validation_data = ([x_valid_scaled[:,:5],x_valid_scaled[:,2:]], [y_valid,y_valid]),epochs = 10,callbacks = callbacks)
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 2)
plt.show()
plot_learning_curves(history)
model.evaluate([x_test_scaled[:,:5],x_test_scaled[:,2:]], [y_test,y_test], verbose=0)
输出:
(20640, 8)
(20640,)
Model: "wide_deep_model_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_9 (Dense) multiple 180
dense_10 (Dense) multiple 930
dense_11 (Dense) multiple 37
=================================================================
Total params: 1147 (4.48 KB)
Trainable params: 1147 (4.48 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
None
Epoch 1/10
363/363 [==============================] - 5s 11ms/step - loss: 7.7861 - output_1_loss: 6.1213 - output_2_loss: 1.6648 - val_loss: 7.4389 - val_output_1_loss: 6.5286 - val_output_2_loss: 0.9103
Epoch 2/10
363/363 [==============================] - 2s 5ms/step - loss: 6.9222 - output_1_loss: 6.1213 - output_2_loss: 0.8009 - val_loss: 7.3594 - val_output_1_loss: 6.5286 - val_output_2_loss: 0.8308
Epoch 3/10
363/363 [==============================] - 2s 4ms/step - loss: 6.8590 - output_1_loss: 6.1213 - output_2_loss: 0.7377 - val_loss: 7.3015 - val_output_1_loss: 6.5286 - val_output_2_loss: 0.7728
Epoch 4/10
363/363 [==============================] - 2s 4ms/step - loss: 6.8141 - output_1_loss: 6.1213 - output_2_loss: 0.6928 - val_loss: 7.2605 - val_output_1_loss: 6.5286 - val_output_2_loss: 0.7319
Epoch 5/10
363/363 [==============================] - 2s 4ms/step - loss: 6.7801 - output_1_loss: 6.1213 - output_2_loss: 0.6588 - val_loss: 7.2233 - val_output_1_loss: 6.5286 - val_output_2_loss: 0.6947
Epoch 6/10
363/363 [==============================] - 2s 5ms/step - loss: 6.7522 - output_1_loss: 6.1213 - output_2_loss: 0.6310 - val_loss: 7.1959 - val_output_1_loss: 6.5286 - val_output_2_loss: 0.6673
Epoch 7/10
363/363 [==============================] - 2s 6ms/step - loss: 6.7302 - output_1_loss: 6.1213 - output_2_loss: 0.6090 - val_loss: 7.1744 - val_output_1_loss: 6.5286 - val_output_2_loss: 0.6458
Epoch 8/10
363/363 [==============================] - 2s 6ms/step - loss: 6.7118 - output_1_loss: 6.1213 - output_2_loss: 0.5905 - val_loss: 7.1550 - val_output_1_loss: 6.5286 - val_output_2_loss: 0.6264
Epoch 9/10
363/363 [==============================] - 2s 4ms/step - loss: 6.6962 - output_1_loss: 6.1213 - output_2_loss: 0.5750 - val_loss: 7.1474 - val_output_1_loss: 6.5286 - val_output_2_loss: 0.6188
Epoch 10/10
363/363 [==============================] - 2s 5ms/step - loss: 6.6839 - output_1_loss: 6.1213 - output_2_loss: 0.5626 - val_loss: 7.1270 - val_output_1_loss: 6.5286 - val_output_2_loss: 0.5983
图片
[6.655601978302002, 6.074487209320068, 0.5811142325401306]
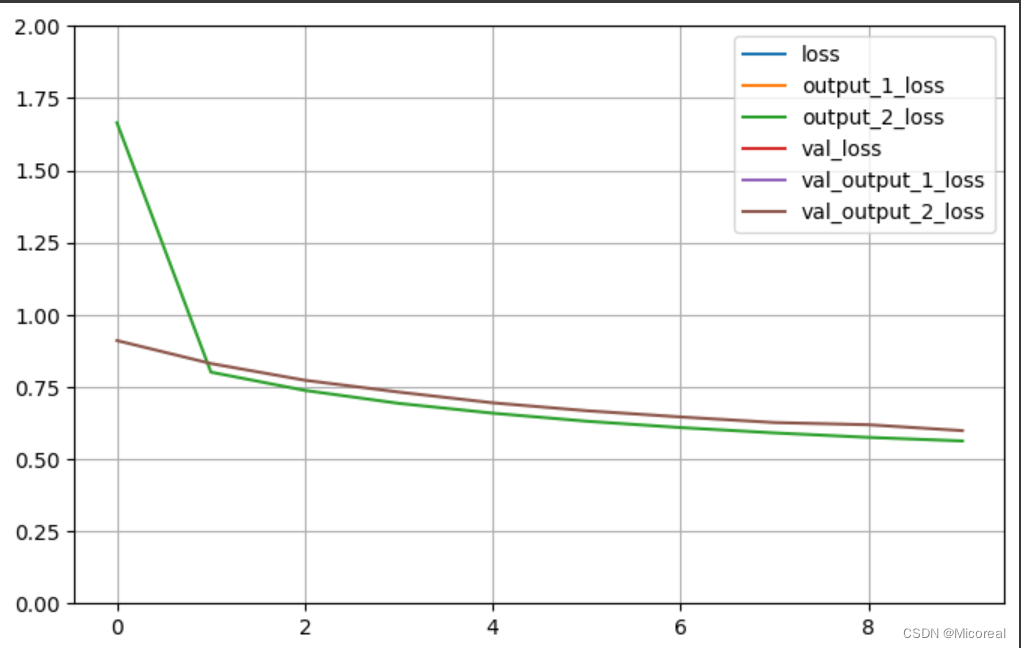
batch-size
这个概念主要要和epoch尽心区分开,前者是总的训练多少次,batch-size是一次训练加载多少数据,举个例子假设数据共有100条,我把batch-size设置为10,epoch设置为10,那么我的训练过程就是10(batch-size)条,10条取数据去训练模型,训练了10轮之后,一个batch完了,就开始下一个epoch,这样讲解比较清楚。
超参数搜索策略
- 网格搜索
- 随机搜索
- 遗传算法搜索
- 启发式搜索
这边只是举一些例子,而网格搜索可以使用sklearn当中的GridSearchCV进行使用,并且搭配上tf.keras.wrappers.scikit_learn.KerasRegressor进行使用,这边暂时不进行介绍
在最新的tensorflow当中已经取消掉了这个接口,现在已经移到别的地方进行维护:
pip install scikeras[tensorflow] # gpu compute platform
pip install scikeras[tensorflow-cpu] # cpu
原本的库变成了:
from tensorflow.keras.wrappers.scikit_learn import KerasClassifier
变成了
from scikeras.wrappers import KerasClassifier
然后下面就是给出相关的网格的板子:
import numpy as np
import pandas as pd
from tensorflow import keras
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from scikeras.wrappers import KerasRegressor
from sklearn.model_selection import GridSearchCV
# 准备数据集 验证集 测试集
# -----------------------------------------------------------------------------
housing = fetch_california_housing()
x_train_all, x_test, y_train_all, y_test = train_test_split(housing.data, housing.target, random_state = 7)
x_train, x_valid, y_train, y_valid = train_test_split(x_train_all, y_train_all, random_state = 11)
print(x_train.shape, y_train.shape)
print(x_valid.shape, y_valid.shape)
print(x_test.shape, y_test.shape)
# -----------------------------------------------------------------------------
# 特征工程
# -----------------------------------------------------------------------------
scaler = StandardScaler()
x_train_scaled = scaler.fit_transform(x_train)
x_valid_scaled = scaler.transform(x_valid)
x_test_scaled = scaler.transform(x_test)
# -----------------------------------------------------------------------------
# RandomizedSearchCV
# 1. 因为是sklearn的接口,转化为sklearn的model
# 2. 定义参数集合
# 3. 搜索参数
# 构造模型的回调函数
# -----------------------------------------------------------------------------
def build_model(hidden_layers = 1,layer_size = 30,learning_rate = 3e-3):
model = keras.models.Sequential()
# 因为不知道第一个输入的shape是多大的,因此我们需要单独从for循环里拿出来,for循环里的是输出再次作为输入,这边注意的是input_shape。
model.add(keras.layers.Dense(layer_size,activation='relu',input_shape=x_train.shape[1:]))
for _ in range(hidden_layers - 1):
model.add(keras.layers.Dense(layer_size,activation = 'relu'))
model.add(keras.layers.Dense(1))
optimizer = keras.optimizers.SGD(learning_rate)
model.compile(loss = 'mse', optimizer = optimizer)
return model
# -----------------------------------------------------------------------------
# KerasRegressor返回一个sk的model,build_fn是一个回调函数 !重点! 重点参数需要加在后面,这是新的版本下需要注意的,框架的封装性不是很好
# -----------------------------------------------------------------------------
sklearn_model = KerasRegressor(model = build_model,hidden_layers = 1,layer_size = 30,learning_rate = 3e-3)
# -----------------------------------------------------------------------------
callbacks = [keras.callbacks.EarlyStopping(patience=5, min_delta=1e-2)]
# 设置网格训练的参数,注意和回调函数相对应
# -----------------------------------------------------------------------------
param_distribution = {
'hidden_layers':[1,2,3,4,5],
'layer_size': [5,10,15,20,25,30],
'learning_rate': [1e-4,2e-3,1e-3,2e-2,1e-5]
}
grid_search_cv =GridSearchCV(estimator=sklearn_model,param_grid=param_distribution)
grid_search_cv.fit(x_train_scaled, y_train, epochs = 5, validation_data = (x_valid_scaled, y_valid), callbacks = callbacks)
# -----------------------------------------------------------------------------
# 选择最好的模型 以及相关最好的参数
model = grid_search_cv.best_estimator_.model_
model.evaluate(x_test_scaled, y_test)
print(grid_search_cv.best_params_)
print(grid_search_cv.best_score_)
print(grid_search_cv.best_estimator_)
如果是使用随机搜索的话,这边只给出不一样的地方:
random_search_cv = RandomizedSearchCV(sklearn_model,
param_distribution,
n_iter = 1,#多少个参数集合
n_jobs = -1)
random_search_cv.fit(x_train_scaled, y_train, epochs = 100,
validation_data = (x_valid_scaled, y_valid),
callbacks = callbacks)
最后给出最后的网格搜索的输出,只给出最后的,不然全部打印得有好几千字了吧。hh
{'hidden_layers': 2, 'layer_size': 15, 'learning_rate': 0.002}
0.5949557467666313
KerasRegressor(
model=<function build_model at 0x7f9ffd542a70>
build_fn=None
warm_start=False
random_state=None
optimizer=rmsprop
loss=None
metrics=None
batch_size=None
validation_batch_size=None
verbose=1
callbacks=None
validation_split=0.0
shuffle=True
run_eagerly=False
epochs=1
hidden_layers=2
layer_size=15
learning_rate=0.002
)