文章目录
- 使用standard analysis对英文进行分词
- 使用standard analysis对中文进行分词
- 安装插件对中文进行友好分词-ik中文分词器
- 下载安装和配置IK分词器
- 使用ik_smart分词器
- 使用ik_max_word分词器
text analysis
使用standard analysis对英文进行分词
ES默认使用standard analysis;如下可以使用POST _analyze测试standard analysis是如何分词的
POST _analyze
{
"analyzer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
该API会将文本内容分词成如下单词
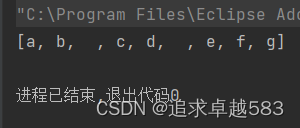
[ the, 2, quick, brown, foxes, jumped, over, the, lazy, dog's, bone ]
使用standard analysis对中文进行分词
默认的 standard analysis 对每个汉字进行了分词,显然这不是我们所期望

安装插件对中文进行友好分词-ik中文分词器
下载安装和配置IK分词器
1、下载ik分词器
gitHub下载地址,找到和当前ES匹配的版本,ik的版本是跟着ES走的。
2、使用wget命令下载zip包
也不局限于这一种方式,只要能把zip下载并上传到服务器上怎么样都行
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.14.0/elasticsearch-analysis-ik-7.14.0.zip
3、在plugins目录下创建ik文件夹,unzip命令进行解压到ES的plugins/ik目录
# 将zip包解压到指定的目录/home/es-kibana/volume/plugin/ik下,并不覆盖已有的文件
unzip -n elasticsearch-analysis-ik-7.14.0.zip -d /home/es-kibana/volume/plugins/ik
因为本人使用Docker安装ES,并在docker run的使用将plugins挂载到了宿主机的 /home/es-kibana/volume/plugins目录下;所以就直接在该目录下创建ik文件夹,并执行上面的解压命令
4、进入容器内部查询plugin list,确认ik安装成功
# 进入容器内部
[root@VM-8-3-opencloudos ik]# docker exec -it b72e9104d50a /bin/bash
# 也可以先看看宿主机plugins目录下的东西是否成功映射给容器内的plugins
[root@b72e9104d50a elasticsearch]# ls
bin config data jdk lib LICENSE.txt logs modules NOTICE.txt plugins README.asciidoc
# 进入bin,查看plugin列表
[root@b72e9104d50a bin]# elasticsearch-plugin list

5、重新启动ES
6、前往kibana的控制台进行中文分词验证
ik提供了两种分词器
- ik_smart
- ik_max_word
使用ik_smart分词器
下图是使用ik_smart分词器的结果,显示将‘我是中国人’分词为[‘我’,‘是’,‘中国人’]

使用ik_max_word分词器
下面尝试使用ik_max_word分词器进行中文分词,它将‘我是中国人’这句中文进行最大限度的分词;结果为[‘我’,‘是’,‘中国人’,‘中国’,‘国人’]












![[极客大挑战 2019]Havefun](https://img-blog.csdnimg.cn/b9bdea0d7d7b45fa816c9d131a983e42.png)