使用强化学习训练 AI 去玩神奇宝贝
这两天在逛 Youtube 的时候意外发现了一个非常有趣的视频,十天的时间已经获得了两百多万的点击:
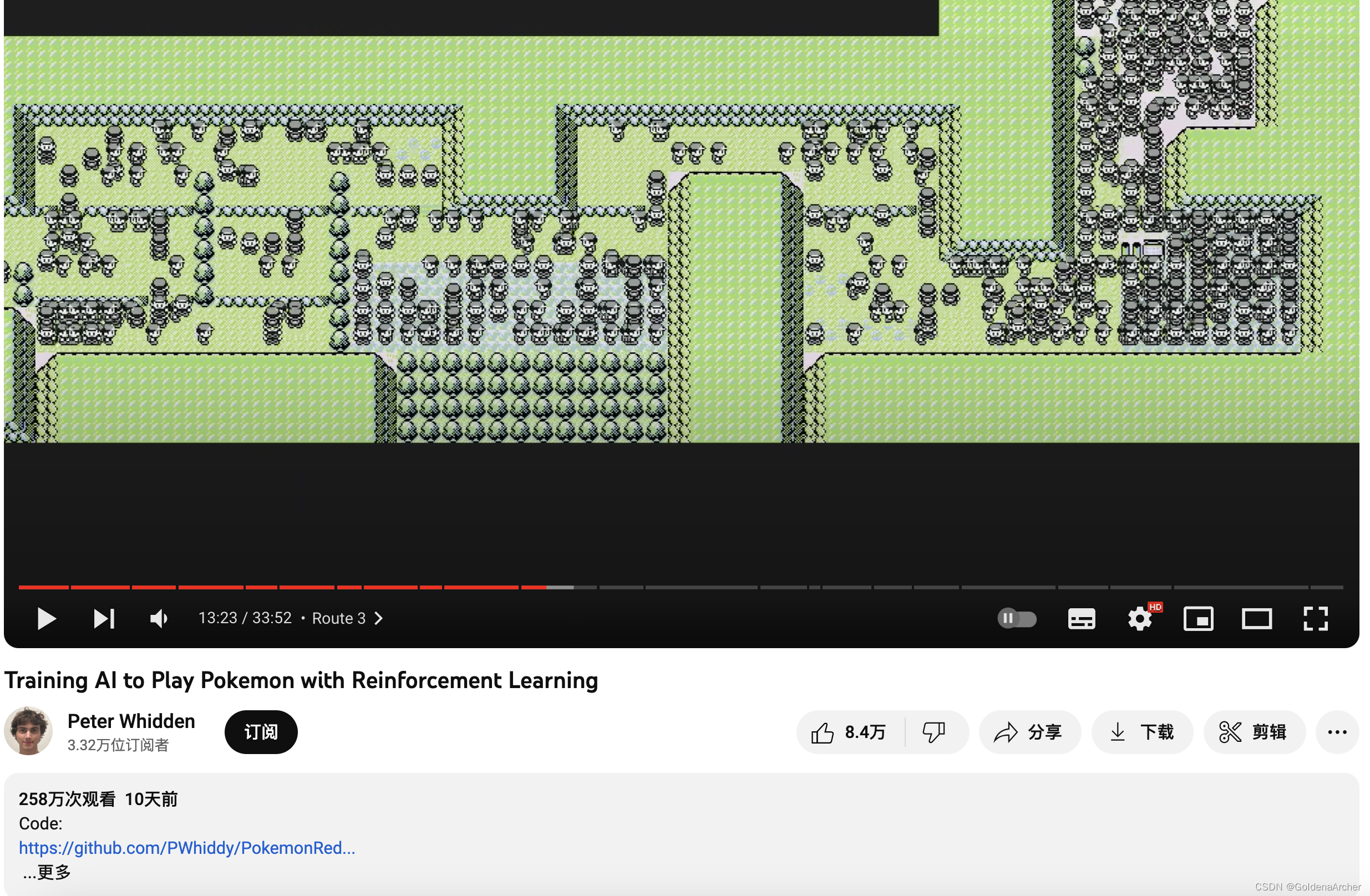
现在已经 360w 点击了
视频的名称就和题目的名称一样:Training AI to Play Pokemon with Reinforcement Learning,Git 地址在这里:PokemonRedExperiments,作者也提供了代码可以直接运行,让别人也可以跑一下基于神奇宝贝红的强化学习。
我个人觉得,这个视频对于完全不了解 AI 的人来说,也是一个非常好的入门教程,所以就总结归纳一下作者第一阶段做了什么
基础介绍
第一步还是要了解一下名词,首先是三种学习模型,提供的数据假设为动物数据,其中:
-
监管学习中,模型会学习标签过的数据
如数据中提供了已经标记过的分类:猫、狗、大象、老虎、狐狸等,机器会将未标记的数据与以标记的数据一一对应,再人工对其标记的数据进行对错的评判
通过训练后,机器可以对 已分类 的数据进行正确的标签
-
非监管学习,模型会学习没有标签的数据
依旧以动物为例,机器会通过学习已经提供的数据集将其进行分类,如它可能推导出 一些动物具有哺乳行为,所以将其归类到一起。一些东西会飞,所以将其归类到一起
其中必然会产生一些分类上的问题,如蝙蝠不属于鸟类,但是蝙蝠会飞,因此动物学上这个分类是错的。不过在任何阶段都不会有人工参与,而是通过塞入更多、更细化的数据让机器继续学习分类
-
强化学习,模型会学习没有标签的数据,但是会有人工参与
比如说模型通过数据分析将数据中的动物分成了若干类,这个时候的人工参与就是设立一个奖励机制,如机器成功的分出了一个新的类别则获取 1 点奖励,出于获取更多奖励的目的,机器会继续学习并将获取的数据进行更细的分类。
这样完成了一个周期后,会需要再一次的人工参与,对模型运行的结果进行调校,调整奖励机制,重设数据集进行重新计算
开始游戏
这个视频就是基于这个强化学习进行实现,基础设定为:
-
AI 可以随意点击任何按钮(上下左右 AB)
-
AI 对于系统没有任何的前置知识
-
AI 在读取到不同的场景是会将其保存
-
创建不同等级的奖励,使得 AI 可以通过简单的奖励,最终达成困难的奖励
这里最初的奖励是去了解周边的环境
前面已经提到,AI 会将遇到的不同场景保存下来,这样在遇到不同场景时,AI 可以将当前场景对比已经出现的场景,如果出现场景不一样的情况时,就会获得奖励,并将不同的场景保存下来
就此,作者开始了最初的几轮训练
不过在第一轮的训练过程中,作者发现 AI 会停留在固定的几个场所并且不动了。在分析了场景后,发现 AI 成功的找到了一个 bug:
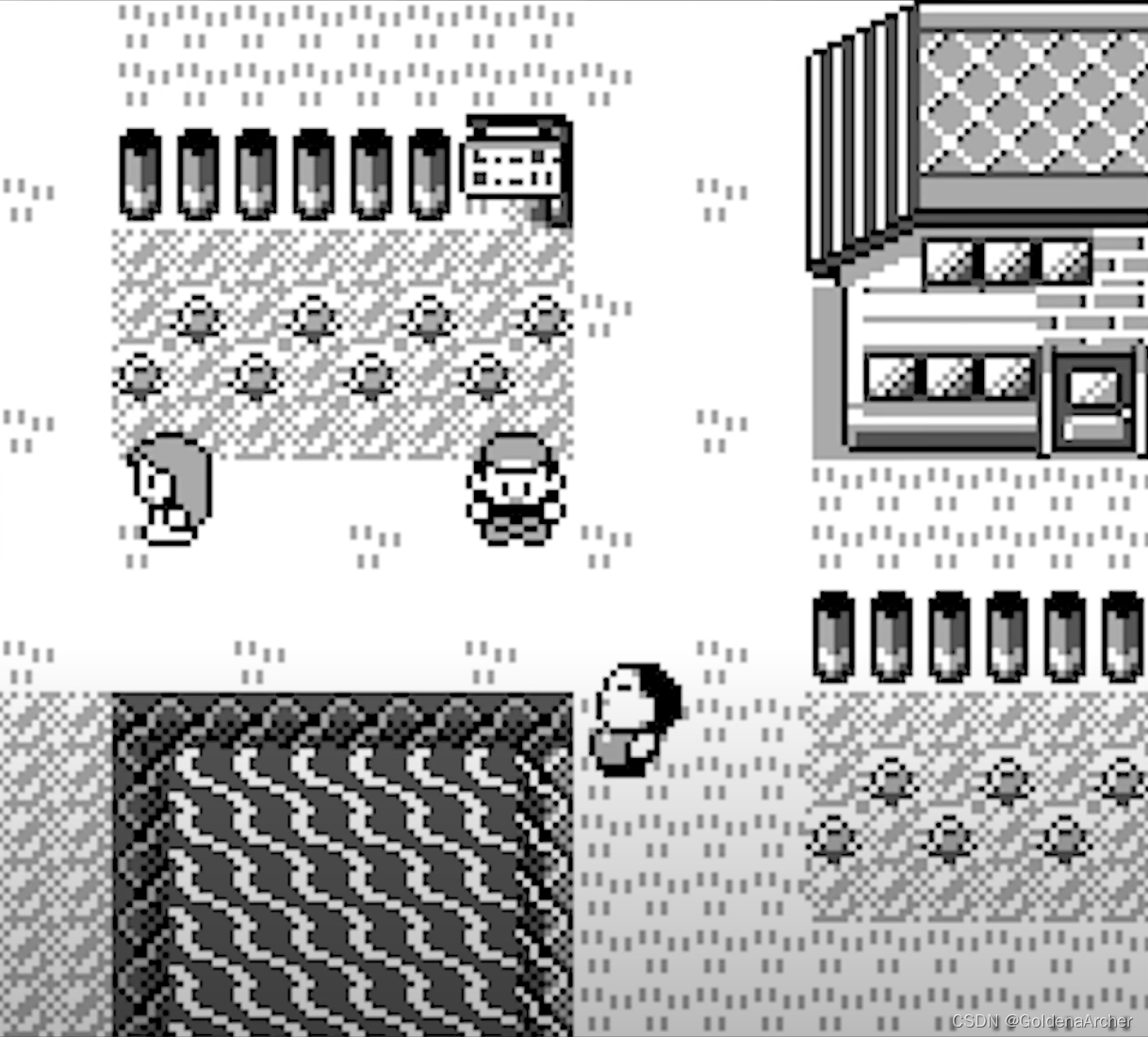


即,停留在有动画(移动的行人/水波)所在的地方。这个时候附近的动画满足了 不同的场景 这一需求,使得 AI 可以停留在这里不停的刷分
这时候作者修改了奖励机制,将本来两个场景之中只有几个像素的区别就能获得奖励,修改到了两个场景有数百个像素差距才能够获得奖励。
这时候作者重新启动了学习过程,保证其过程是可重复的
终于,在调整了奖励机制后,AI 成功抵达了第二个城市
训练神奇宝贝
这时候,单纯做旅游的奖励机制已经无法继续推进游戏了,与神奇宝贝对战的场景太过相似,无法触发奖励机制:
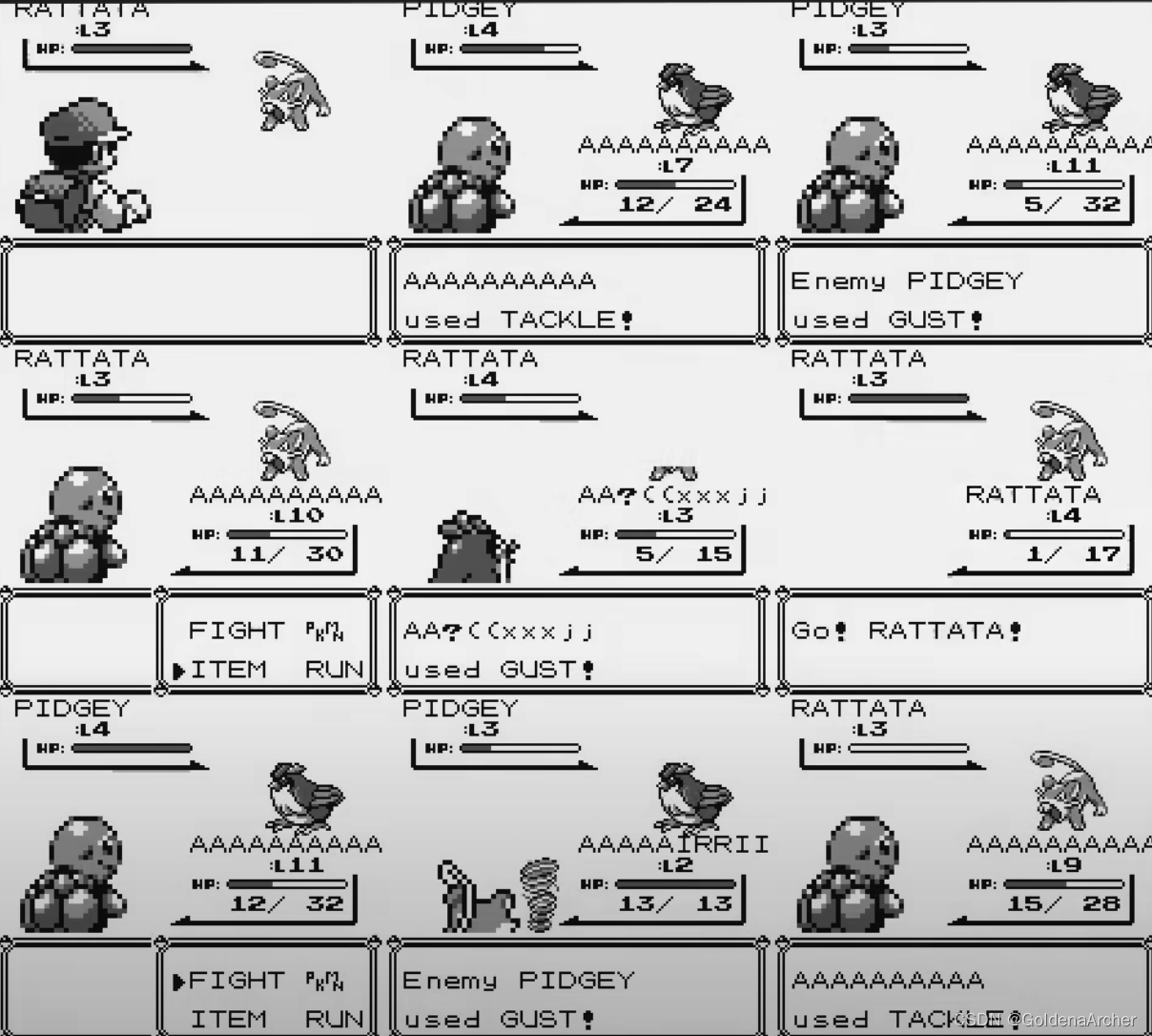
引起,比起对战,AI 的本能选择就是:

逃跑
这时候作者添加了第二个奖励机制,也就是神奇宝贝的等级奖励,此时对于 AI 的奖励如下:
| 目标 | 奖励 |
|---|---|
| 探险 | 1 |
| 等级 | 3 |
按照正常的推断来说,这样 AI 的目标就会更多的关注在打赢战斗、抓小精灵、升级
最终,AI 学会了升级小精灵,并且学会在一个攻击技能次数用光后,切换到另一个技能攻击:
切换技能这一点,对于之后另一个突破来说也是非常有用的,同时,也是在版本 60 的时候,AI 第一次和其他的训练家进行了对战,也最终突破了第一个森林

就在前景一片大好时,作者又发现了几个奇怪的点:
- 尽管当对战一定会失败的时候,AI 还是会选择对战
- AI 不知道为什么从来不会访问医院
第一点作者并没有提出什么很好的解决方案,第二点作者最初添加了一个惩罚机制:
| 目标 | 奖励 |
|---|---|
| 探险 | 1 |
| 等级 | ∑ i = 1 6 l e v e l \sum_{i=1}^{6} level ∑i=16level |
| 失败 | -1 |
但是这并没有达成作者的目的,反而是让 AI 在要失败的当口,选择不去点击任何的按钮
通过观察,作者最终发现问题出在了神奇宝贝中心里。当 AI 选择将神奇宝贝存储到电脑中时,因为小精灵的等级直接与奖励挂钩,因此 AI 一下子就会失去大量的奖励,这也造成了 AI 最终决定不去小精灵中心
比如说,AI 此刻持有两只小精灵,一只等级 13,一只等级 12,此刻小精灵的奖励为 26。AI 进入了医院,在某一次随机操作中选择将一只小精灵保存进了电脑,这样一下子 AI 就失去了 50%的小精灵奖励
这使得 AI 对小精灵中心产生了负面的印象,并且在大量的训练中都对中心唯恐避之不及的态度
最终,作者选择调整了等级的奖励:
| 目标 | 奖励 |
|---|---|
| 探险 | 1 |
| 等级 | m a x ( Δ l e v e l , 0 ) max(\Delta level, 0) max(Δlevel,0) |
在进行了这样的修改后,AI 终于访问了训练中心
打道馆
当 AI 学会移动、升级、捕捉小精灵、和训练师对战后,自然而然的它也学会了访问了道馆。不过 AI 在这里又遇到了大问题——在此之前 AI 和训练时的对战只需要使用主要技能,因此也只需要依赖主要技能。而主要技能(大多为普通系)对于第一个道馆(岩系)的效果非常不佳。
当 AI 输了太多次后,它就会尝试避免道馆
不过在调整了奖励机制,以及花费更多训练时间后,AI 终于遇到了一个边界条件,让它学会了使用更有效的技巧:
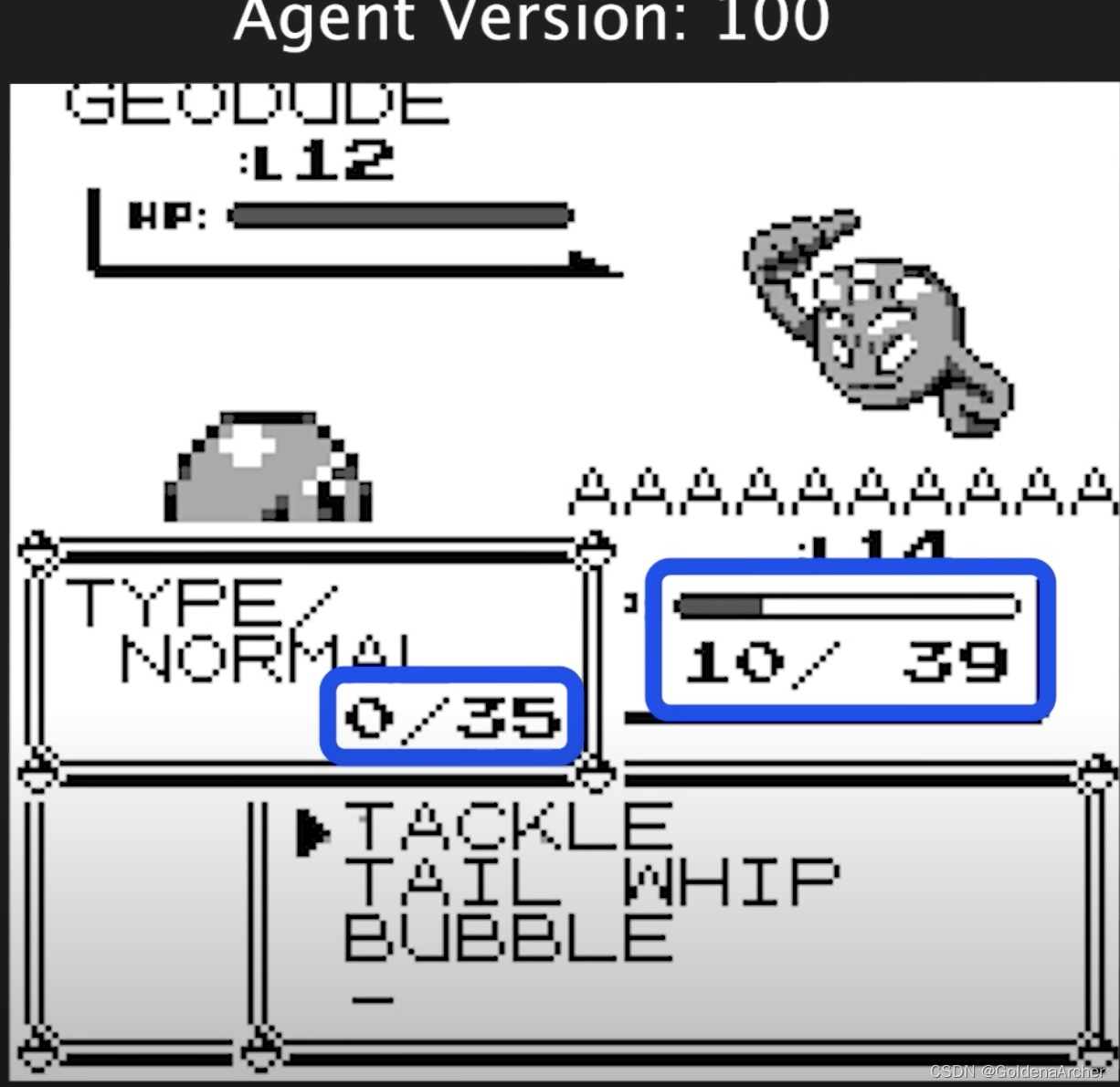
这个边界条件就是:
-
AI 手中另一个神奇宝贝已经晕了过去,它手上只剩下了一个战损的杰尼龟
-
杰尼龟撞击的使用次数已经完全耗尽了
AI 现在只能使用杰尼龟的泡泡技能
水系技能对岩石系技能特别的有效,在第 100 个版本时,AI 终于学会使用默认使用水系技能对战岩石系。从这以后的训练也证明了这点,在 v100 之前,AI 没有能够战胜道馆首领。在 v100 之后,AI 战胜道馆首领的次数明显增加
也就是在这之后的月亮山,因为 AI 没有能够离开月亮山,大抵是因为地图太过相似,所以探险的奖励分太低。与其继续调整奖励机制,因此作者也就暂停了继续训练,而是将此作为一个阶段性的终结。
一些反思怪时间
其实强化学习,真的跟人的学习还蛮像的,比如说第一阶段里只设置探索奖励,最终确实能够让 AI 抵达下一个城镇,但是也有可能会让 AI 停在某个点一动不动,一点进展都没有。这种情况人也可能遇到,比如说太关注片面的成长(场景带来的奖励),
而忽略了整体的成长(抵达下一个城镇乃至通关整个游戏)
比如说,AI 进入精灵中心可能会导致瞬间失去大量奖励(存储小精灵这一动作引起的),以至于从此避开精灵中心。而对于人来说,因为一次滑铁卢而产生阴影的情况也数不胜数。对于 AI 来说,简单的调整一下奖励机制重新开始就可以解决这个问题,但是对人来说,要解决这个问题不仅仅是一个 重设奖励机制 + 重新开始 就能解决的
又比如说,太过依赖于惯性思维(只使用主技能),因为这个惯性思维在大多数场景下有效,便不考虑新的方法……
总觉得真的是每个点都踩在了自己的痛点上……





![[极客大挑战 2019]Havefun](https://img-blog.csdnimg.cn/b9bdea0d7d7b45fa816c9d131a983e42.png)