文章目录
- 1 检查失败节点worker启动日志
- 2 检查正常节点worker启动日志
- 3 查看正常节点spark环境配置
- 4 又出现新的ERROR
- 4.1 报错解释
- 4.2 报错解决思路
- 4.3 端口报错解决操作
集群下电停机后再次启动时,发现其中一台节点的worker启动失败。
1 检查失败节点worker启动日志
检查启动日志报以下错:
Spark Command: bin/java -cp /opt/hdSpace/spark/conf/:/opt/hdSpace/spark/jars/*:/opt/hdSpace/hadoop/etcihadoop/ -Dspark.deploy.recoveryode=Z00KEEPER -Dspark,deploy .zookeeper,url=hadoop01,hadoop02,hadoop03-Dspark.deploy.zookeeper.dir=/spark -Dspark.worker.cleanup.enabled=true -Dspark.worker.cleanup.interval-86400
-Dspark.worker.cleanup.appDataTtl-259200 -Xmx1g org.apache. spark.deploy.worker,orker --webui-port 8081
spark://hadoop01:7077
======================================
/opt/hdSpace/spark/bin/spark-class: line 99: /opt/hdSpace/spark/bin/java: No such file or directory
根据/opt/hdSpace/spark/bin/java: No such file or directory,问题定位大致是目录的原因,涉及到jdk的目录,这里将jdk目录解析到了spark目录下,而spark/bin/java中根本没有jdk。
2 检查正常节点worker启动日志
于是找一台正常启动worker的节点查看日志:
Spark Command: /opt/java8/bin/java
只看第一行的前半句日志,jdk目录的配置似乎出现了问题。
于是检查spark-env.sh。
发现JAVA_HOME的配置写的是变量:
export JAVA_HOME=${JAVA_HOME}
于是echo一下:
# echo ${JAVA_HOME}
/opt/java8
看上去是没问题的,因为这里确实是jdk的目录。
此时,需要和其他节点的配置做一个对比,因为这套集群的spark并不是我安装的,spark配置文件的分发我不能保证正确。
3 查看正常节点spark环境配置
再次查看一台其他正常启动的worker的spark-env.sh:
export JAVA_HOME=/opt/java8
这里写的是绝对路径,于是将失败节点也配置为了绝对路径,再次启动worker,该目录问题解决。
- 经过对比检查,解决了jdk目录的问题。
4 又出现新的ERROR
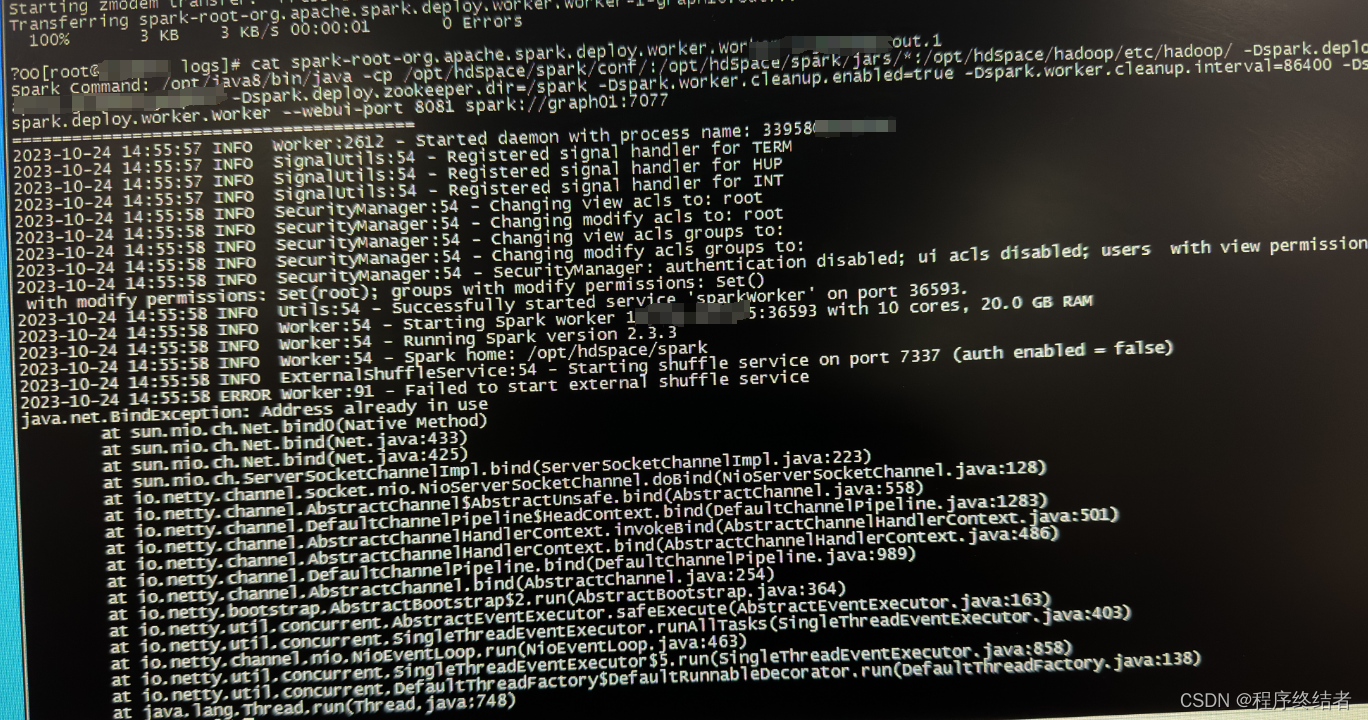
INFO ExternalShuffleService:54 - Starting shuffle service on port 7337 (auth enabled = false)
ERROR Worker:91 - Failed to start external shuffle service
java.net.BindException: Address already in use
at sun.nio.ch.NET.bind0...
4.1 报错解释
这是因为端口7337被占用了,端口 7337 在 Spark Cluster 模式中通常用于 Spark 的 Executor 进程之间进行通信。Executor 进程是 Spark 应用程序的工作单元,它们负责执行 Spark 任务,并将结果返回给 Driver 程序。Executor 之间需要进行数据交换和通信,而端口 7337 通常用于这些通信。当进行Shuffle操作(如reduceByKey或groupByKey)时,数据需要从不同的 Executor 之间传输,以进行数据重组。这也可能涉及到端口 7337。
4.2 报错解决思路
此时需要查看端口(例如 7337 端口)的网络连接,可以使用 netstat 命令或 ss 命令。
使用 netstat 命令:
netstat -tuln | grep 7337
上述命令将显示所有监听(-l)的UDP(-u)和TCP(-t)连接,然后使用 grep 过滤出包含 “7337” 的行,这些行表示占用了 7337 端口的连接。
使用 ss 命令:
ss -tuln | grep 7337
与 netstat 类似,这个命令也会列出占用 7337 端口的网络连接。
这将显示占用 7337 端口的网络连接的相关信息,包括本地地址、远程地址等。如果有进程正在使用这个端口,可以从相关的信息中找到它。
4.3 端口报错解决操作
[root@hadoop10 logs]# lsof -i:7337
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 24611 root IPv6 108223 0t0 TCP *:7337 (LISTEN)
[root@hadoop10 logs]# kill -9 24611
[root@hadoop10 logs]# ss -tuln grep 7337
[root@hadoop10 logs]# jps
24448 DataNode
25089 HRegionServer
35141 Jps
34890 Worker
将占用端口kill掉后,重新启动spark节点,worker启动成功。