期刊:2023 IEEE/CVF International Conference on Computer Vision (ICCV)
标题:Rethinking(重新审视) Vision Transformers(ViT) for MobileNet Size and Speed(MobileNet的规模和速度)
——重新审视ViT能否达到MobileNet的规模和速度
论文:https://arxiv.org/pdf/2212.08059.pdf
源码:GitHub - snap-research/EfficientFormer: EfficientFormerV2 [ICCV 2023] & EfficientFormer [NeurIPs 2022]
一、摘要
研究背景:随着视觉Transformers(ViTs)在计算机视觉任务中的成功,最近的技术试图优化ViT的性能和复杂性,以实现在移动设备上的高效部署。研究人员提出了多种方法来加速注意力机制,改进低效设计,或结合mobile-friendly的轻量级卷积来形成混合架构。
研究问题:然而,ViT及其变体仍然比轻量级的CNNs具有更高的延迟或更多的参数,即使对于多年前的MobileNet也是如此。实际上,延迟和大小对于资源受限硬件上的高效部署都至关重要。
主要工作:
- 1. 重新审视了ViT的设计选择,并提出了一种具有低延迟和高参数效率的改进型超网络。
- 2. 进一步引入了一种细粒度联合搜索策略,该策略可以通过同时优化延迟和参数量来找到有效的架构。
研究成果:所提出的模型EfficientFormerV2在ImageNet-1K上实现了比MobileNetV2和MobileNetV1高约4%的top-1精度,具有相似的延迟和参数。论文证明,适当设计和优化的ViT可以以MobileNet级别的大小和速度实现高性能。
二、网络架构
EfficientFormerV2网络架构如下:
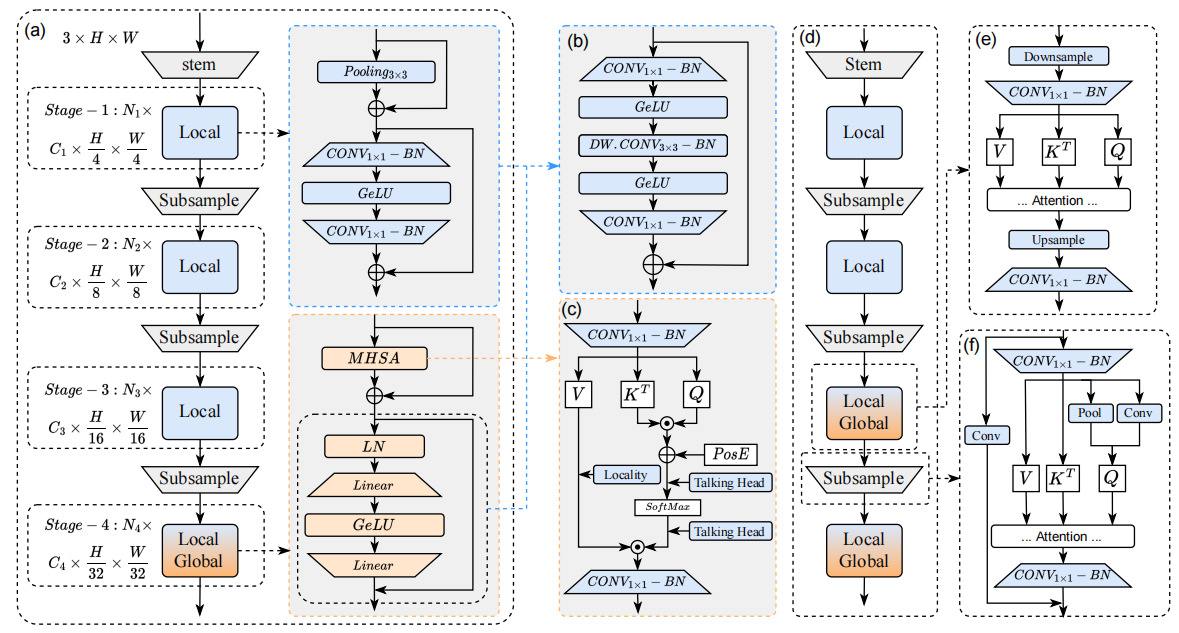
3.1. Token Mixers vs. Feed Forward Network(FFN代替Token Mixers)
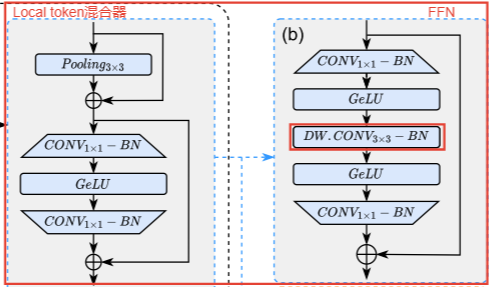
前人工作:PoolFormer和EfficientFormer采用3 x 3个平均池化层作为local token(局部标记)混合器。(local token混合器的作用)增强局部信息可以提高性能,并使ViT在没有显式位置嵌入的情况下更加鲁棒。
动机1:用相同内核大小的深度卷积(DWCONV)替换这些层不会引入延迟开销,而性能提高了0.6%,额外参数可以忽略不计(0.02M)。
动机2:此外,最近的工作表明,在ViT中的前馈网络(FFN)中添加局部信息捕获层也是有益的,以提高性能,同时开销较小。
改进:基于这些观察,删除了显式残差连接的局部标记混合器,并将深度方向的 3 × 3 CONV 移动到FFN中,以获得启用局部性的统一FFN。将统一的 FFN 应用于网络的所有阶段。这种设计修改将网络架构简化为只有两种类型的块 (Local FFN 和 Gobel Attention),并在相同延迟下将准确率提高到 80.3%,参数开销很小(0.1M)。
代码如下:
FFN深度卷积前馈网络:
# 深度卷积前馈网络
class FFN(nn.Module):
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
mlp_hidden_dim = int(dim * mlp_ratio) # 隐藏层维度
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop, mid_conv=True) # 多层感知机
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones(dim).unsqueeze(-1).unsqueeze(-1), requires_grad=True) # 缩放因子
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_2 * self.mlp(x)) # 残差连接
else:
x = x + self.drop_path(self.mlp(x))
return x# 多层感知机
class Mlp(nn.Module):
"""
Implementation of MLP with 1*1 convolutions.
Input: tensor with shape [B, C, H, W]
"""
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0., mid_conv=False):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.mid_conv = mid_conv
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
if self.mid_conv:
self.mid = nn.Conv2d(hidden_features, hidden_features, kernel_size=3, stride=1, padding=1,
groups=hidden_features)
self.mid_norm = nn.BatchNorm2d(hidden_features)
self.norm1 = nn.BatchNorm2d(hidden_features)
self.norm2 = nn.BatchNorm2d(out_features)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x) # 1x1卷积
x = self.norm1(x)
x = self.act(x) # 激活层,GELU激活
if self.mid_conv:
x_mid = self.mid(x) # 3x3卷积
x_mid = self.mid_norm(x_mid)
x = self.act(x_mid)
x = self.drop(x)
x = self.fc2(x) # 1x1卷积
x = self.norm2(x)
x = self.drop(x)
return x3.2 MHSA Improvements
多头自注意力MHSA
class Attention4D(torch.nn.Module):
def __init__(self, dim=384, key_dim=32, num_heads=8,
attn_ratio=4,
resolution=7,
act_layer=nn.ReLU,
stride=None):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
if stride is not None:
self.resolution = math.ceil(resolution / stride)
self.stride_conv = nn.Sequential(nn.Conv2d(dim, dim, kernel_size=3, stride=stride, padding=1, groups=dim),
nn.BatchNorm2d(dim), )
self.upsample = nn.Upsample(scale_factor=stride, mode='bilinear')
else:
self.resolution = resolution
self.stride_conv = None
self.upsample = None
self.N = self.resolution ** 2
self.N2 = self.N
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.q = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),
nn.BatchNorm2d(self.num_heads * self.key_dim), )
self.k = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.key_dim, 1),
nn.BatchNorm2d(self.num_heads * self.key_dim), )
self.v = nn.Sequential(nn.Conv2d(dim, self.num_heads * self.d, 1),
nn.BatchNorm2d(self.num_heads * self.d),
)
self.v_local = nn.Sequential(nn.Conv2d(self.num_heads * self.d, self.num_heads * self.d,
kernel_size=3, stride=1, padding=1, groups=self.num_heads * self.d),
nn.BatchNorm2d(self.num_heads * self.d), )
self.talking_head1 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)
self.talking_head2 = nn.Conv2d(self.num_heads, self.num_heads, kernel_size=1, stride=1, padding=0)
self.proj = nn.Sequential(act_layer(),
nn.Conv2d(self.dh, dim, 1),
nn.BatchNorm2d(dim), )
points = list(itertools.product(range(self.resolution), range(self.resolution)))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N, N))
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x): # x (B,N,C)
B, C, H, W = x.shape
if self.stride_conv is not None:
x = self.stride_conv(x)
q = self.q(x).flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2) # 降维为2维,转置
k = self.k(x).flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 2, 3)
v = self.v(x)
v_local = self.v_local(v) # 通过一个3x3的卷积将局部信息注入V中
v = v.flatten(2).reshape(B, self.num_heads, -1, self.N).permute(0, 1, 3, 2) # 降维为2维,转置
attn = (
(q @ k) * self.scale # 矩阵乘法,计算相似度
+
(self.attention_biases[:, self.attention_bias_idxs] # 融合一个位置编码
if self.training else self.ab)
)
# attn = (q @ k) * self.scale
attn = self.talking_head1(attn) # 1x1卷积->全连接,实现注意力头部之间的通信
attn = attn.softmax(dim=-1)
attn = self.talking_head2(attn) # 同上
x = (attn @ v) # 注意力融合
out = x.transpose(2, 3).reshape(B, self.dh, self.resolution, self.resolution) + v_local # 最后再与v_local融合
if self.upsample is not None:
out = self.upsample(out)
out = self.proj(out) # 输出再进行激活 + 卷积 + 正则
return outLocal Global模块(AttnFFN)
class AttnFFN(nn.Module):
def __init__(self, dim, mlp_ratio=4.,
act_layer=nn.ReLU, norm_layer=nn.LayerNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
resolution=7, stride=None):
super().__init__()
self.token_mixer = Attention4D(dim, resolution=resolution, act_layer=act_layer, stride=stride) # MHSA多头自注意力
mlp_hidden_dim = int(dim * mlp_ratio) # 隐藏层维度
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop, mid_conv=True) # 深度卷积
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity() # drop_path概率
self.use_layer_scale = use_layer_scale
if use_layer_scale: # 缩放因子
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones(dim).unsqueeze(-1).unsqueeze(-1), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones(dim).unsqueeze(-1).unsqueeze(-1), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_1 * self.token_mixer(x)) # 多头自注意力 + 残差连接
x = x + self.drop_path(self.layer_scale_2 * self.mlp(x)) # mlp深度卷积 + 残差连接
else:
x = x + self.drop_path(self.token_mixer(x))
x = x + self.drop_path(self.mlp(x))
return x
# 深度卷积前馈网络
class FFN(nn.Module):
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
mlp_hidden_dim = int(dim * mlp_ratio) # 隐藏层维度
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop, mid_conv=True) # 多层感知机
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones(dim).unsqueeze(-1).unsqueeze(-1), requires_grad=True) # 缩放因子
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(self.layer_scale_2 * self.mlp(x)) # 残差连接
else:
x = x + self.drop_path(self.mlp(x))
return x