作者:JackTian
来源:公众号「杰哥的IT之旅」
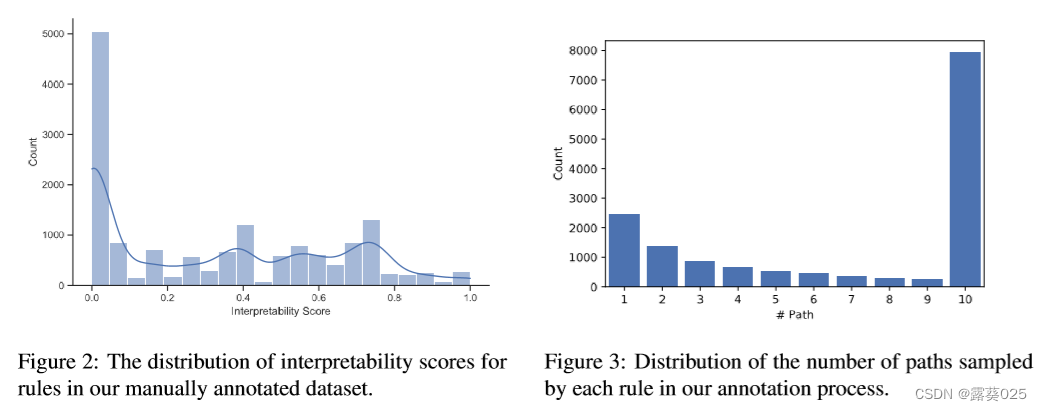
ID:Jake_Internet
链接:30 个常用的 Linux 命令!
命令 1:last用于显示用户最近登录信息,包括用户名、登录时间、登录来源等信息
单独执行last命令,将会读取/var/log/wtmp的文件,并把该文件内容记录的登入系统的用户名单全部显示出来。
last -na | head
-n <显示列数>或-<显示列数>:设置列出名单的显示列数-a:把从何处登入系统的主机名称或 IP 地址,显示在最后一行
命令 2:过滤当前目录下以 1024 开头的文件,并统计这些文件的数量
ls | egrep ^1024 | wc -l
ls:用于显示目录内容列表egrep:用于在文件内查找指定的字符串^1024是一个正则表达式,用于匹配以数字 1024 开头的文件。egrep命令将在输入中查找匹配这个模式的行
命令 3:过滤当前目录下以 1024 开头的文件,并显示这些文件的大小以及总用量
ls | egrep ^1024 | xargs du -ch
xargs:xargs 命令是给其他命令传递参数的一个过滤器du:显示每个文件和目录的磁盘使用空间-c:除了显示个别目录或文件的大小外,同时也显示所有目录或文件的总和-h:以K、M、G为单位,提高信息的可读性
命令 4:显示当前目录下所有以"1024"开头、后缀名为".xml"的文件且只显示第一个文件的开头部分信息
ll 1024*.xml -rt | head -1
-r:逆序排列-t:按时间信息排序head:显示文件的开头部分,在未指定行数时默认显示前10行。-1:只显示输出的第一行
若当前目录下以"1024"开头、后缀名为".xml"的文件存在 N 个,那么这样方便辨别当前目录下最早接收到的此 xml 文件的时间点是什么时间。
命令 5:显示当前目录下所有以"1024"开头、后缀名为".xml"的文件且只显示第一个文件的开头部分信息并只打印出文件的第6、7、8个字段
ll 1024*.xml -rt | head -1 | awk '{print $6, $7, $8}'
awk '{print $6, $7, $8}':将上一个命令的输出传递给 awk 命令,awk 可以按照指定的格式提取文本内容,这里只打印出文件的第6、7、8个字段,也就是文件的月、日、时间点。
命令 6:列出当前目录下所有以.xml结尾的文件,并显示第8个字段(时间点)和第9个字段 xml 的文件名
ls -l *.xml | awk '{print $8,$9}' | grep -v '^$'
-v:反转匹配操作,也就是查找不包含某个字符串的行^:锚定行的开始,如:‘^1024’ 匹配所有以 1024 开头的行$:锚定行的结束,如:‘1024$’ 匹配所有以 1024 结尾的行
命令 7:在 interface_check.log 日志文件中查找包含"2023-10-16"到"2023-10-22"区间的所有行,如果这些行中包含"异常",则打印出来。
awk '/2023-10-16/,/2023-10-22/ {if ($0 ~ /异常/) print}' interface_check.log
awk '/2023-10-16/,/2023-10-22/:从包含"2023-10-16"的行开始,到包含"2023-10-22"的行结束{if ($0 ~ /异常/) print}':在awk中,$0表示包含执行过程中当前行的文本内容,~表示匹配正则表达式操作。如果一行文本中包含"异常",那么就打印这一行
命令 8:循环创建六个名为test-1到test-6的空文件
for i in {1..6}; do touch "test-${i}"; done
for i in {1..6}:for 循环,用于迭代数字 1 到 6。每次循环,数字 i 将加 1do:for 循环的开始touch "test-${i}":每次循环中所要执行的命令。touch用于创建一个新的空文件或更新已存在文件的修改时间。"test-${i}"是一个字符串,其中${i}会被替换为当前的循环数。所以,在第一次循环中,它会执行touch test-1,在第二次循环中,它会执行touch test-2,依此类推done:for 循环的结束
命令 9:查找/var/log/secure*文件中包含"Accepted"的行,并使用awk命令提取这些行的第1、2、3、9、11个字段,然后将这些字段打印出来
grep "Accepted" /var/log/secure* | awk '{print $1,$2,$3,$9,$11}'
awk '{print $1,$2,$3,$9,$11}':打印出每一行的第 1、2、3、9、11 个字段
命令 10:从/var/log/secure文件中查找所有包含Failed password的行,并从这些行中提取 IPv4 地址,然后删除重复的地址并统计每个地址出现的次数
grep "Failed password" /var/log/secure | grep -E -o "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)"|uniq -c
grep "Failed password" /var/log/secure:这部分命令会从/var/log/secure文件中查找包含Failed password的行,/var/log/secure用来记录安全相关的信息,记录最多的是哪些用户登录服务器的相关日志grep -E -o "(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)":这部分命令使用grep的扩展正则表达式匹配 IP 地址。它会匹配 IPv4 地址,并以十六进制形式输出。-E表示使用扩展的正则表达式,-o表示只输出文件中匹配到的部分uniq -c:用于删除重复的行,并统计匹配的次数
命令 11:从/var/log/secure文件中查找所有包含Failed password的行,提取出对应的IP地址,并统计来自不同IP地址的失败尝试,然后对这些结果进行排序
grep "Failed password" /var/log/secure | perl -e 'while($_=<>){ /for(.*?) from/; print "$1\n";}'|uniq -c|sort -nr
perl -e 'while($_=<>){ /for(.*?) from/; print "$1\n";}':这部分命令使用 Perl 语言编写了一个简单的脚本来处理从上一步命令输出的每一行。这个脚本会匹配for (.*?) from,然后打印出匹配到的部分,也就是 IP 地址sort -nr:用于对上一步处理后的结果进行排序,其中-n表示根据数字排序,-r表示将结果倒序排列
命令 12:在当前目录下查找所有以2023-09-开头的目录,并删除目录及其目录下的文件
find . -type d -name "2023-09-*" -exec rm -rf {} \;
find:用来在指定目录下查找文件.:在当前目录下进行查找-type <文件类型>:只寻找符合指定的文件类型的文件-name <范本样式>:指定字符串作为寻找文件或目录的范本样式-exec <执行指令>:若 find 指令的返回值为 True,则执行后面的命令rm:可删除一个目录中的一个或多个文件、目录,也可以将某个目录及其下属的所有文件、子目录进行删除,-r:递归处理,将指定目录下的所有文件与子目录一并处理,-f:强制删除文件或目录{}和\:是find命令的语法,表示命令的结束
命令 13:在当前目录下查找所有以2022-开头的目录,并删除目录及其目录下的文件
find . -type d -name "2022-*" -exec rm -rf {} \;
命令 14:客户端服务器与服务端服务器如何验证传输速率?
客户端:
iperf3 -c 服务端服务器IP -b 1000M -t 20
iperf3:是网络性能测试工具 iperf 的第三版,用于测量网络带宽和吞吐量-c:指定 iperf3 运行在客户端模式,用于向指定的服务端服务器发送请求-b:指定测试的带宽为 1000M(即 1Gbps)-t:指定测试时间为 20 秒。
服务端:
iperf3 -s
iperf3 -s命令是启动 iperf3 服务端,用于接收来自客户端服务器的请求。会监听在默认的端口:5201,并准备接收来自客户端服务器的连接和测试请求。当客户端连接到服务端后,服务端会开始进行网络性能测试,并输出测试结果。
命令 15:以可读格式显示当前目录及其子目录的磁盘使用情况,但只显示到第一层目录
du --max-depth=1 -h
--max-depth=1它限制了 du 命令在查看目录时递归的深度。如果一个目录下有子目录,--max-depth=1将只显示子目录的磁盘使用情况,而不显示子目录下的文件或目录-h:以K、M、G为单位来显示磁盘使用情况
命令 16:获取系统硬件关于制造商、产品名称和序列号等硬件信息
dmidecode | grep -A 8 "System Information" | egrep "Manufacturer | Product | Serial"
dmidecode:可以从计算机的主板 BIOS 中获取关于硬件系统的信息grep -A 8 “System Information”: 执行dmidecode命令后,会有很多系统信息显示出来。用grep命令筛选含有“System Information”的行,并显示匹配行后的 8 行数据egrep “Manufacturer | Product | Serial”:经过上面命令过滤后,再对后三项信息进行过滤,最终只显示系统信息中的Manufacturer(制造商)、Product(产品名称)和Serial(序列号)的行数据
命令 17:读取并打印出/etc/redhat-release或/etc/issue文件的第一行的第一个字段和第二个字段,用于获取运行环境的操作系统信息
cat /etc/redhat-release 2>/dev/null || cat /etc/issue | awk 'NR==1 {print $1 $2}'
cat /etc/redhat-release 2>/dev/null:查看/etc/redhat-release文件,该文件中包含了操作系统的版本信息。如果读取失败,则将错误信息输出到/dev/null中,2>表示错误重定向||:逻辑或操作符,如果第一个命令执行失败了,则执行第二个命令cat /etc/issue | awk ‘NR==1 {print $1 $2}’: 如果上一个命令执行失败,就执行该命令。首先读取/etc/issue文件,它包含了操作系统的版本信息,然后用管道符将原始输出通过awk命令进行处理,"NR==1 {print $1 $2}"的意思是打印第一行中的前两个字段,即发行版本和版本号
命令 18:读取/proc/cpuinfo文件的内容,过滤出CPU名称,提取出CPU名称进行去重,并在每行前面显示该名称的出现次数
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
cat /proc/cpuinfo:查看该系统文件内容,其中包含了关于每个 CPU 的详细信息grep name:过滤包含name关键字的行,即以model name为标签的 CPU 行cut -f2 -d::使用cut命令提取字段2,即冒号后的内容,-d:指定分隔符为冒号uniq -c:使用uniq进行去重,-c参数在每行前面显示该行的出现次数
命令 19:获取并显示服务器硬盘的型号和产品名称
fdisk -l | grep "Disk model" 2>/dev/null || lshw -class disk | grep product | grep -v "Virtual" | grep -v "DVD-ROM"
fdisk -l:用于列出系统中所有的硬盘分区和其相关的详细信息grep “Disk model” 2>/dev/null:使用grep过滤包含“Disk model”的行,列出每个硬盘的型号。同时,2>/dev/null用于将标准错误输出重定向到一个空文件||:逻辑或操作符,用于在第一个命令执行失败时,则执行第二个命令lshw -class disk | grep product | grep -v “Virtual” | grep -v “DVD-ROM”:如果第一个命令执行失败,则使用lshw -class disk来获取硬盘信息。然后,grep命令过滤包含product关键字的行,并使用grep -v命令过滤包含“Virtual"和"DVD-ROM”等虚拟设备,最终输出硬盘的型号信息
命令 20:读取系统的DMidecode信息,找到关于内存设备的制造商信息,过滤掉任何未知或未标识的信息,并显示结果中不重复行的出现次数
dmidecode | grep -C 16 "Memory Device" | grep Manufacturer | grep -v "Unknown" | grep -v "NO" | uniq -c
dmidecode:用于显示系统的具体硬件配置信息,如 BIOS、CPU、主板、内存等。grep -C 16 “Memory Device”:使用grep过滤包含"Memory Device"的行,并且显示上下 16 行的内容。这样做是为了将属于同一个内存设备的信息聚合在一起。grep Manufacturer: 使用grep过滤包含Manufacturer的行,即表示筛选内存设备的制造商信息grep -v “Unknown”:使用grep过滤包含"Unknown"的行,即排除制造商信息为"Unknown"的内存设备
-grep -v “NO”:使用grep过滤包含"NO"的行,即排除制造商信息为"NO"的内存设备uniq -c:使用uniq进行去重,-c参数在每行前面显示该行的出现次数
命令 21:将/tmp/secure_failed.txt文件的第一行输出到屏幕,并使用awk命令处理这行,只打印出该行的第一个字段
head -n1 /tmp/secure_failed.txt | awk '{print $1}'
head:用于显示文件的开头部分,-n1:表示只显示第一行awk '{print $1}':表示打印出每一行的第一个字段
命令 22:从/var/log/secure文件的最后2000行中筛选出包含"Failed"的行,并提取其中的 IPv4 地址,然后对这些 IPv4 地址进行排序和统计
tail -n 2000 /var/log/secure | awk '/Failed/{print $(NF-3)}' |grep "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}" | sort | uniq -c |sort -nr| more
tail -n 2000:tail 用于显示文件的末尾部分。-n 2000表示显示最后2000行'/Failed/{print $(NF-3)}':表示当行中包含"Failed"时,则打印出该行的最后一个字段,使用$(NF-3)表示倒数第四个字段grep "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}":这里使用正则表达式[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}用于匹配 IPv4 地址。这部分命令就是筛选出由awk处理过的文本中包含 IPv4 地址的部分sort:对文本文件中所有行进行排序uniq -c:使用uniq进行去重,-c参数在每行前面显示该行的出现次数sort -nr:根据数字结果倒序排序
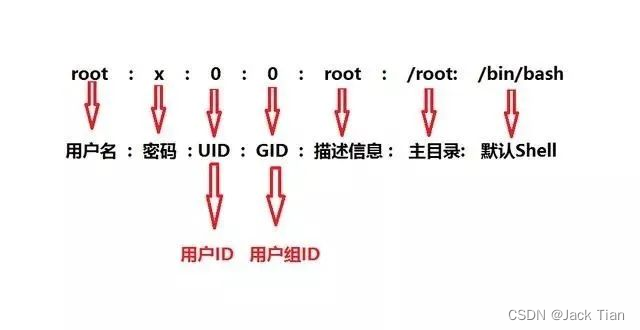
命令 23:查看/etc/passwd文件的内容 ,过滤/bin/bash字段并提取每行中的第一字段的用户名和第七字段的默认Shell
cat /etc/passwd | grep /bin/bash | cut -d ":" -f 1,7
cut -d ":" -f 1,7:cut是文本处理工具,用于从文本中提取指定的字段。它将以冒号为分隔符-d ":",提取每行的第1和第7个字段-f 1,7
由于/etc/passwd文件的格式是固定格式的,每行使用冒号分隔多个字段,所以这里提取的是用户名和默认Shell
命令 24:将vsftpd.service添加到开机自启动配置中
systemctl enable vsftpd.service
命令 25:查看哪些服务已经在开机自启动配置中,并过滤包含vsftpd.service的服务
systemctl list-unit-files --state=enabled | grep vsftpd.service
systemctl list-unit-files命令可以列出所有的服务、挂载点、设备文件--state=enabled参数表示只列出启用的服务
命令 26:查看vsftpd.service服务的状态是否正常运行
systemctl status vsftpd.service
如果正在运行,还可以显示它的进程ID(PID)等信息
命令 27:查看vsftpd.service服务过滤端口以及监听状态是否正常
netstat -anpt | grep 21 | grep "LISTEN"
netstat可以显示系统的网络连接状态,-anpt参数表示显示所有地址、端口和进程信息grep 21过滤出端口为21的行,grep "LISTEN"过滤出处于监听状态的服务
命令 28:查看/var/log/xferlog-*所有日志文件中,FTP 传输未完成的日志
cat /var/log/xferlog-* |grep '* i'
命令 29:查看/var/log/xferlog-*所有日志文件中,FTP 传输已完成的日志
cat /var/log/xferlog-* |grep '* c'
命令 30:通过查看/var/log/xferlog-*所有日志文件中,过滤ftp_user_1用户名称在 2023-10-21 和 2023-10-22 传输未完成的日志
grep "ftp_user_1" /var/log/xferlog-* | grep '* i' | grep "/1024/2023-10-21\|/1024/2023-10-22"

以上就是今天所要分享的全部内容了。
如果你觉得这篇文章对你有点用的话,为本文点个赞、留个言或者转发一下,让更多的朋友看到,因为这将是我持续输出更多优质文章的最强动力!