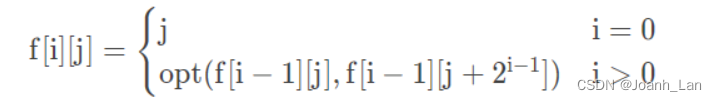Kafka Consumer - 消费者
跟生产者一样,消费者也属于kafka的客户端,不过kafka消费者是从kafka读取数据的应用,侧重于读数据。一个或多个消费者订阅kafka集群中的topic,并从broker接收topic消息,从而进行业务处理。今天来学习下kafka consumer基本使用。
消费者example
组件版本
- kafka_2.13-3.3.1
- JDK17
- apache-maven-3.6.0
Maven依赖
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.3.1</version>
</dependency>
消费者代码
public static void main(String[] args){
String topicName = "consumer-topic";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "app_01");
props.put("enable.auto.commit", true);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, MessageDto> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topicName));
try {
while (true) {
ConsumerRecords<String, MessageDto> records = consumer.poll(Duration.ofSeconds(1));
records.forEach(record -> {
System.out.println("Message received " + record.value());
});
}
}finally {
consumer.close();
}
}
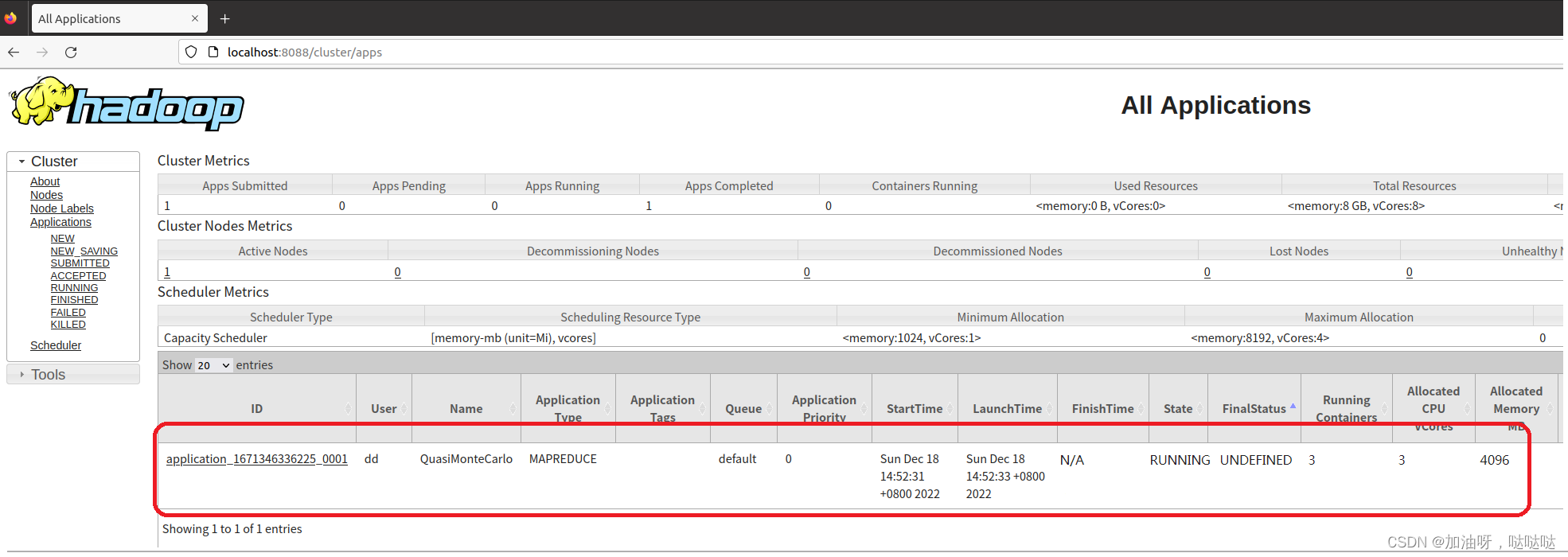
测试验证
-
创建topic
./bin/kafka-topics.sh --create --topic consumer-topic --bootstrap-server localhost:9092 -
启动生产者 - 这里使用kafka自带的生产者脚本进行测试
./bin/kafka-console-producer.sh --topic consumer-topic --bootstrap-server localhost:9092 -
测试结果

至此 一个简单的kafka消费者程序已经开发完成,代码不多,开发起来也快。但是关于kafka 消费者内部有很多的原理、细节需要去梳理,否则出现问题就会茫然失措,不知所以。
pull VS poll
上面的消费者程序有一个很核心的细节需要关注,即kafka 消费者以什么的方式对数据进行消费。对比其他传统的消息中间件,消息消费的方式主要有两种:
- 推送模式 - broker 主动推送消息给消费者
- 拉取模式- 消费者主动从broker拉取消息
kafka在设计之处,就考虑这个问题:消费者从broker拉取数据,还是broker主动推送数据给消费者。在这方面kafka采用更为传统的设计:消费者主动拉取,其优势如下:
- 拉取模式 可以根据消费者自身的消费能力对数据处理。如生产者大量数据,消费者消费能力有限
- 拉取模式 消费者可以根据实际情况对数据进行批量处理。推送模式很难做到这一点
- broker被设计成无状态模式,broker不需要对记录每一个消费者的偏移量,由客户端自己控制 便于kafka集群扩展
消息传递语义
在介绍消息传递语义之前,首先要了解下kafka 消费者位置(也叫做偏移量)管理。
位移管理
kafka 消费者端需要为每个读取的topic 分区保存消费进度,即当前分区中消费者消费消息的最新位置。该位置也叫做偏移量- offset。消费者需要定期地想kafka提交自己的位置信息,实际上,偏移量通常是下一条待消费消息的位置。如下图
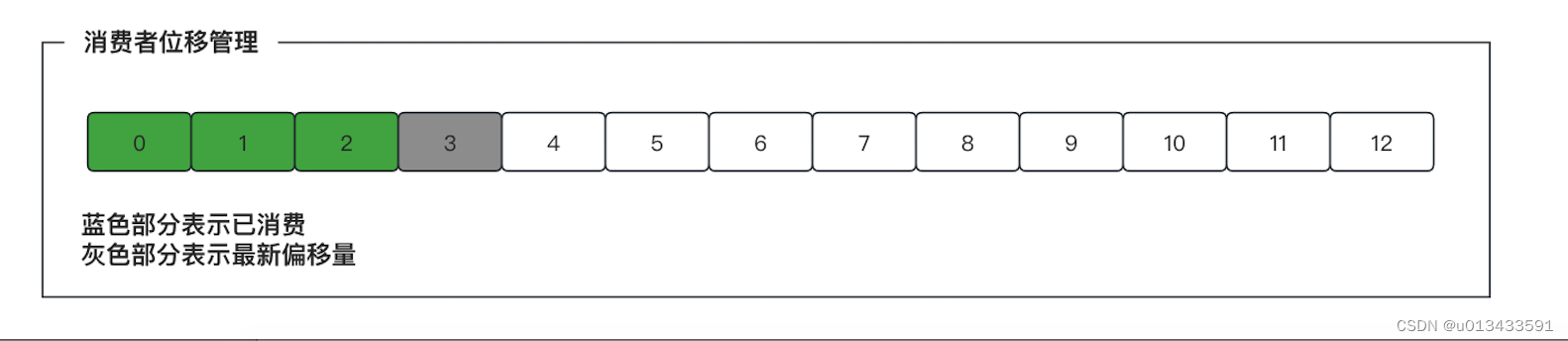
从kafka broker读取消息,开发者可以选择提交偏移量的时间,消费者默认自动提交偏移量,这可能会带来一些风险。
最多一次
在这种情况下,在调用poll()后,一旦收到消息批,就立即提交偏移量。如果后续处理失败(如业务处理过程中发生异常,数据只是被从Broker读取出来,并没有真正的处理),消息将丢失。它不会被再次读取,因为这些消息的偏移量已经提交。
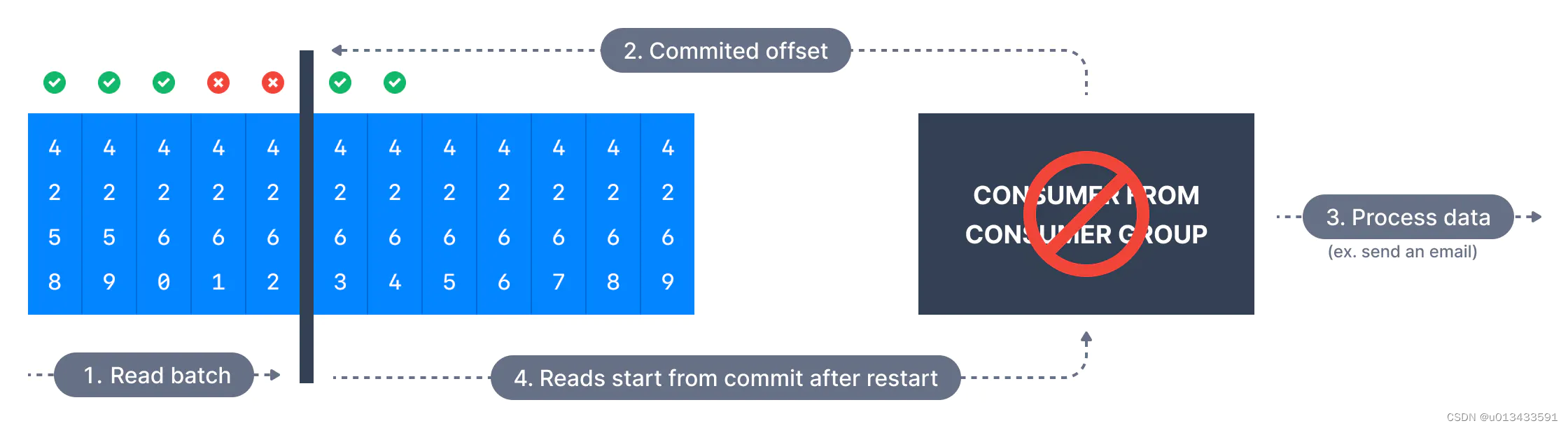
- 批量拉取数据
- 消费者自动提交偏移量
- 对消息进行业务处理,如发送email,此时系统奔溃
- 系统重启后,从上次已提交的偏移量进行读取,在业务上造成消息丢失
至少一次
在至少一次语义定义中,broker消息的每一个消息都会被传递到消费者,但是可能会存在重复拉取的场景,从而导致消息被重复处理。跟最多一次提交位置偏移量的时机不同,至少一次在处理消息后提交偏移量。
因此需要确保消息处理的幂等性,如对数据进行插入、更新操作;防止重复消费导致数据出现错乱。
至少一次消息处理的流程大致如下:
-
批量拉取数据
-
此时消费者并不提交偏移量
-
对消息进行业务处理
3.1 处理完成 提交偏移量 进行下一次拉取数据
3.2 消息处理失败(此时可能有一部分数据处理完成,还有一部分数据尚未处理)
-
重启应用 拉取数据,又会拉取之前的数据 导致消息被重复处理
精确一次
有些场景不仅需要至少一次语义(保证数据不丢失),还需要精确一次语义。每条消息只投递一次,这需要消费者应用程序跟kafka相互配合、相互合作就可以实现精确一次语义
- 使用kafka事务API实现精确一次语义
- 对于消费者应用程序,要有效地实现一次,必须使用幂等性消费
位移配置
props.put("enable.auto.commit", true);
enable.auto.commit 参数默认值为true,kafka默认在后台线程中周期性的提交消费者偏移量
auto.commit.interval.ms默认为5秒,如果enable.auto.commit参数设置为true,即消费者5秒提交一次位移。
在至少一次、精确一次语义中 需要将该参数设置为false,由应用程序手动提交偏移量
//...
props.put("enable.auto.commit", false);
//...
while (true) {
ConsumerRecords<String, MessageDto> records = consumer.poll(Duration.ofSeconds(1));
records.forEach(record -> {
System.out.println("Message received " + record.value());
});
//提交偏移量
consumer.commitSync();
}
根据不用的应用场景,kakfa提供了多个API让开发者对消费者位移进行手动管理
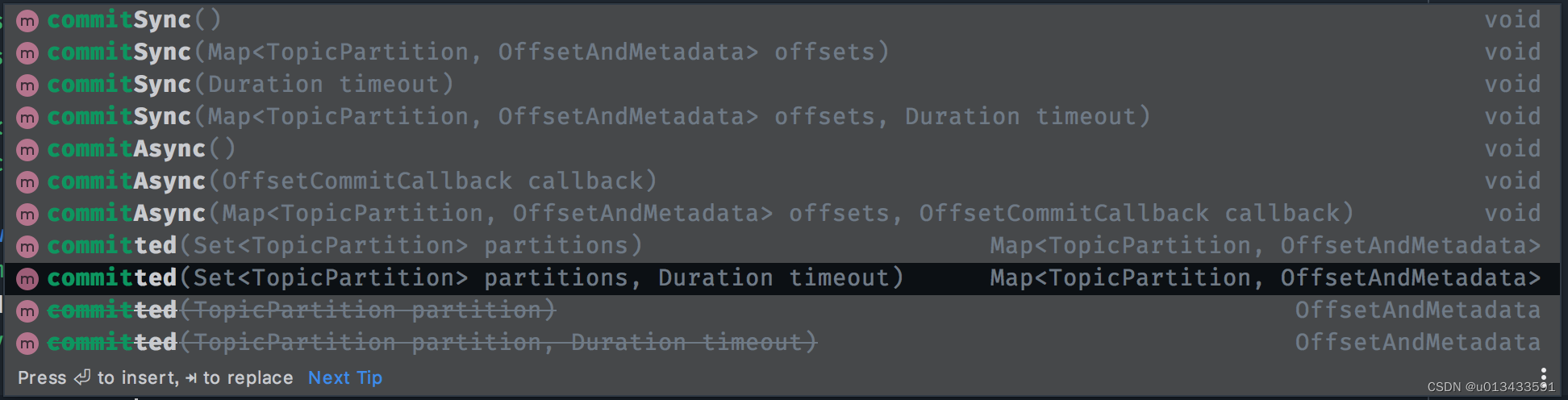
auto.offset.reset
指定消费者从broker拉取数据的位置,有以下几个选项可以配置
- earliest - 从最开始进行消费
- latest - 从最后消费的偏移量进行消费 默认值
- none - 如果未找到使用者组的先前偏移量,则向使用者抛出异常
消费者组
props.put(ConsumerConfig.GROUP_ID_CONFIG, "app_01");
在开发kafka消费者代码时,必须指定消费者组,否则会报错,那么该参数有什么作用呢。在回答这个问题之前,先假设两个应用场景
- kafka中消息特别多,需要增加消费者加快消息处理的速度,避免出现消息堆积
- 某一类消息特别重要,需要被多个应用程序同时消费 - 如购买商品的消息,需要被库存应用、积分应用同时消费
借用RocketMQ中的概念(个人觉得比较合适),以上两种应用场景叫做集群消费、广播消费
- 集群消费 - 多个消费者共同消费某一个主题内的消息
- 广播消费 - 每一个消息被多个消费者同时消费
kafka 内部以消费者组的方式实现以上两点要求
- 同一个消费组的不同消费实例 共同消费topiic的消息
- 同一个消息被不同的消费组同时消费
在开发代码时,只需要按需更改一下配置即可
props.put(ConsumerConfig.GROUP_ID_CONFIG, "app_B");
props.put("client.id", "client_02");