pytorch入门教程、一些基础函数的概念(参考代码),主要是带着读了一遍pytorch官方文档、另外推荐一个网站 www.paperswithcode.com,感觉很厉害的样子。
P5. PyTorch加载数据初认识_哔哩哔哩_bilibili
import torch
torch.cuda.is_available()
dir(), help()
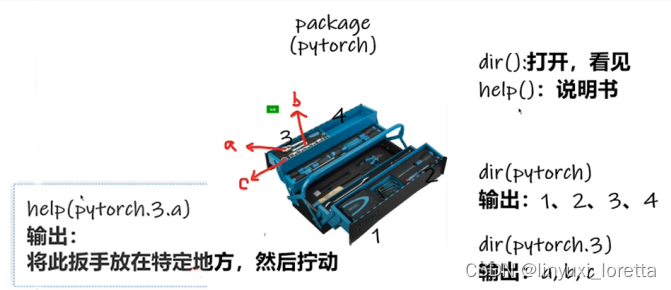

前后双下划线代表一种规范,这个变量不允许篡改
help(torch.cuda.is_available)
python, python控制台,jupyter对比


Tensorboard

tensorboard --logdir=logs
tensorboard --logdir=logs --port=6007
logdir=事件文件所在文件夹名
出现问题:
解决:

transforms
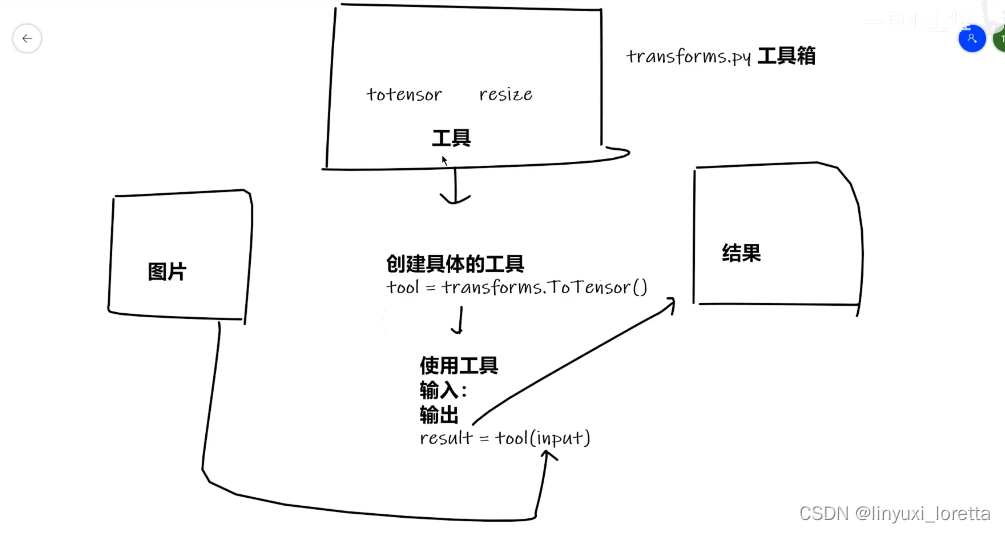


python中__call__的作用

直接调用对象就是进入__call__

settings>>case

关注输入和输出类型
多看官方文档
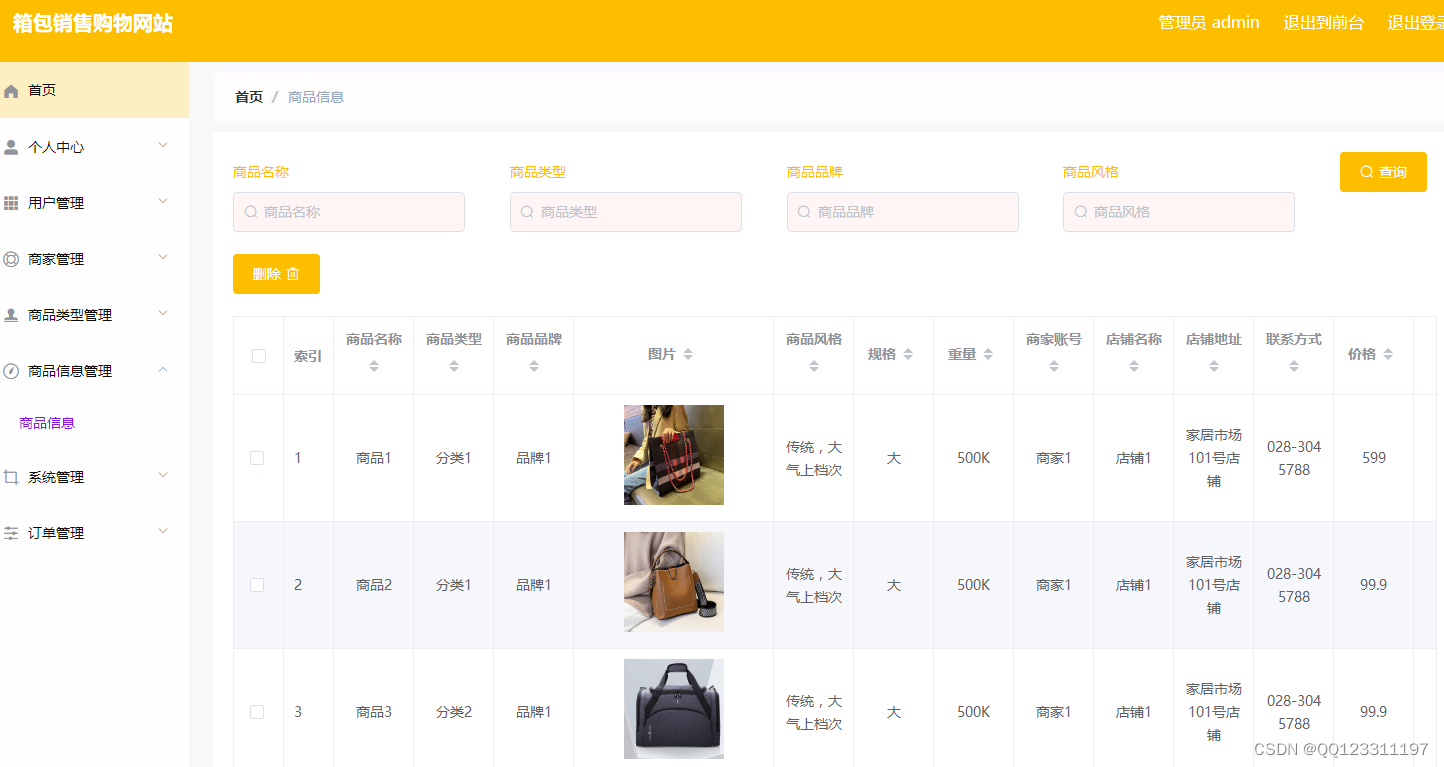
torchvision.datasets 数据集:
COCO 常用 目标检测、语义分割
CIFAR 物体识别
torchvision.models
一些常见的神经网络,有的已经预训练好了
semantic segmentation语义分割
dataset dataloader

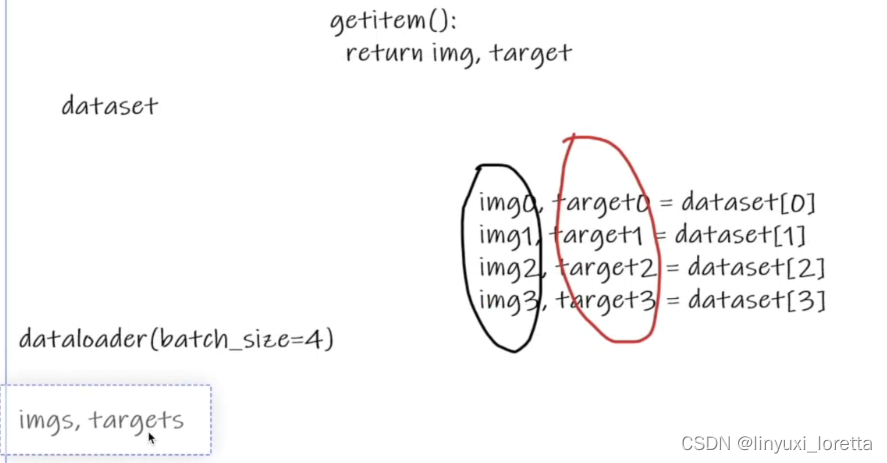
python API “package包”
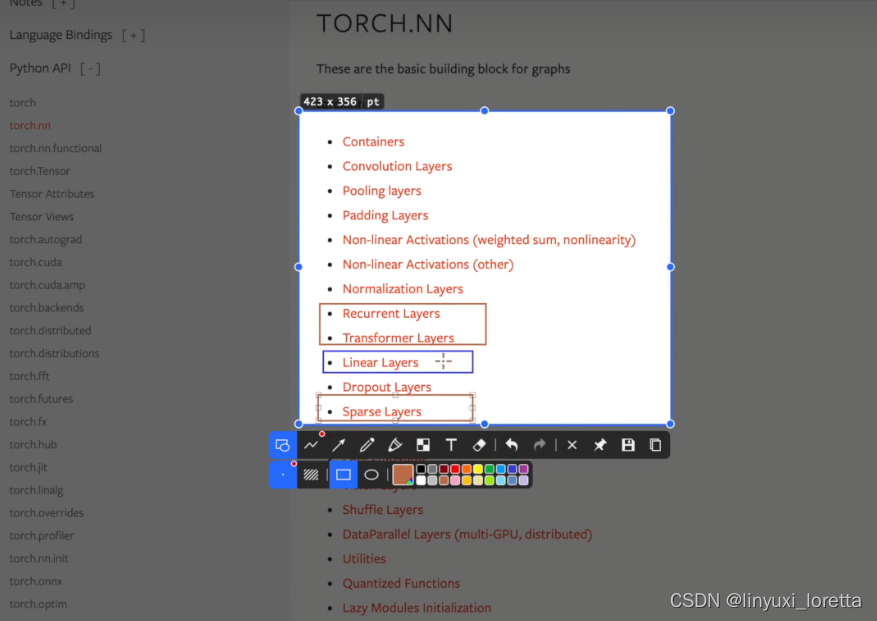
关于神经网络的工具主要在 torch.nn 里

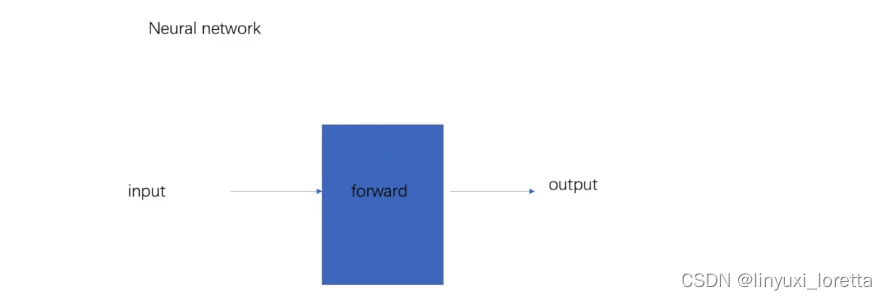
vgg16 model 很常用
CNN相关
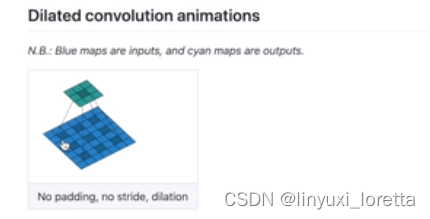
dilation 空洞卷积 默认是1
ceil model 默认false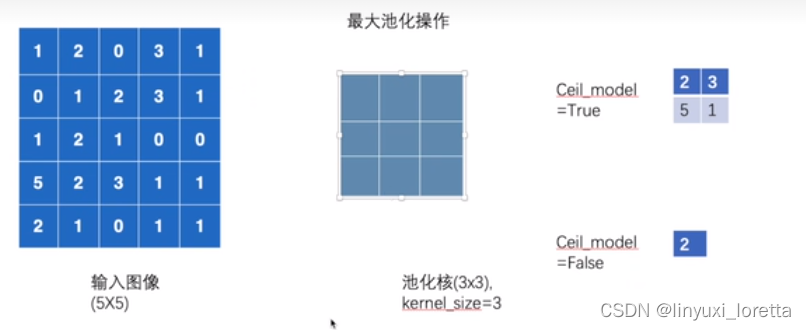
ceil向上取整,floor向下取整
relu激活函数(sigmoid也可,但效果比relu差)适用于神经层运算,sigmoid激活函数适合作输出层的分类
sigmoid有时候会存在梯度消失,relu是个很好的替代
relu inplace

nn.BatchNorm2d
批处理归一化
BN可以解决梯度消失或者梯度爆炸


recurrent layers
用在文字识别中的特定的网络结构
Transformer layers
nlp常用,在cv领域表现也还不错
transformer在目标检测已经屠榜了 估计不久会取代cnn、
TF是出了2才好用,TF1简直是惨绝人寰
2022年回來看Transformer是主流了
dropout层 防止过拟合
embedding NLP

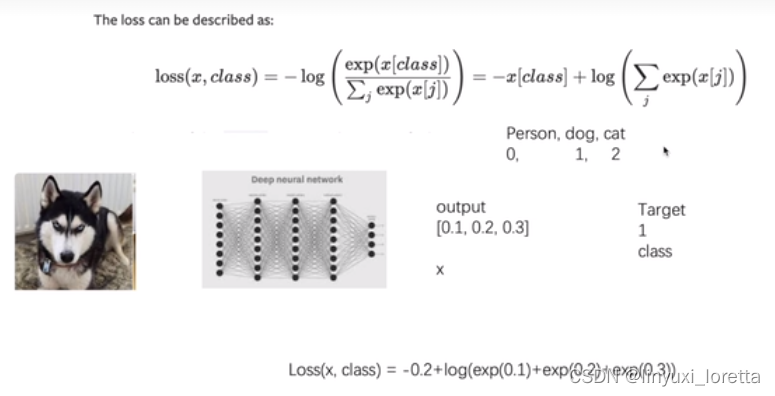
注意这里的交叉熵损失公式是组合了softmax的结果
这里我们算的是类别1的softmax的函数值,我么希望这个值越大越好,但是通常损失函数都是最小化,所以我们最开始在前面加了个负号,然后我们求这个损失函数的最小值就行了
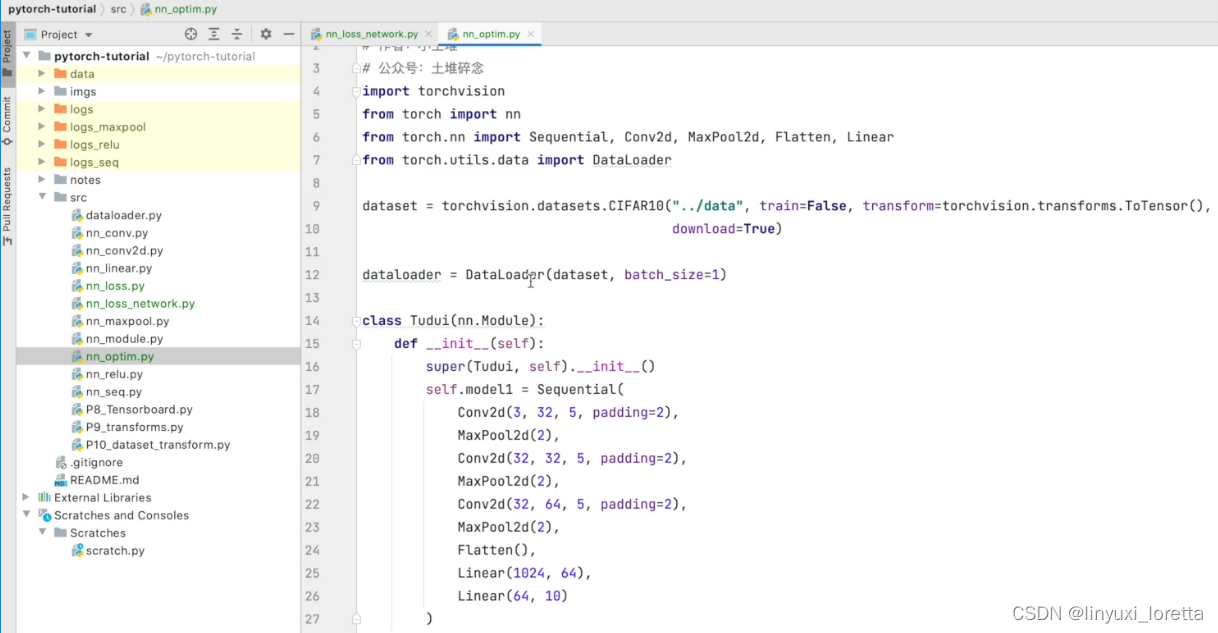
为啥把代码放在src文件下,有啥讲究吗?
src就是source的缩写,代表源代码文件夹。一般软件工程都会有这样一个共识吧
正确率是分类问题中特有的衡量指标

免费的GPU资源:
阿里天池实验室
google colab 一周30小时
梯子: 极光 (免费 据说不好用?
修改>>笔记本设置>>硬件加速

换gpu
model和loss fun.不需要另外赋值
只有数据、 图片、 label需要赋值
test.py

cifar10

超简单实用,推荐的深度学习科研必备网站(轻松找论文,代码项目,写论文综述)| 土堆教程_哔哩哔哩_bilibili
一个非常有用的深度学习必备网站:www.paperswithcode.com

Deep Graph Library(https://www.dgl.ai),图神经网络的实现基本都有