一、数据库类型
关系型数据库:MYSQL
非关系型数据库:NoSQL、MongoDB、Cassandra、Dynamo
主流关系数据库:
商用数据库,例如:Oracle,SQL Server,DB2等;
开源数据库,例如:MySQL,PostgreSQL等;
桌面数据库,以微软Access为代表,适合桌面应用程序使用;
嵌入式数据库,以Sqlite为代表,适合手机应用和桌面程序
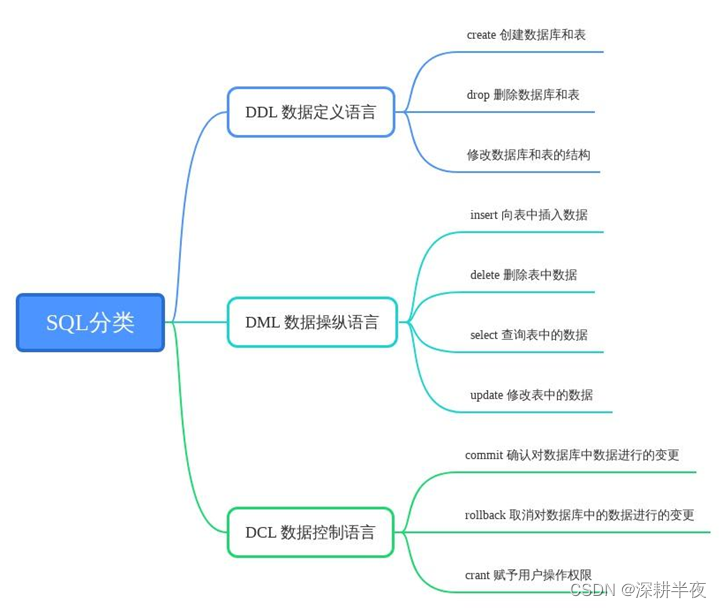
2.SQL语言定义了三种操作数据库的能力:
DDL: Data Definition Language
DDL允许用户定义数据,即创建表、删除表、修改表结构这些操作。通常,DDL由数据库管理员执行
DML: Data Manipulation Language
DML为用户提供添加、删除、更新数据的能力,这些是应用程序对数据库的日常操作。
DQL: Data Query Language
DQL允许用户查询数据,这也是通常最频繁的数据库日常操作。
二、关系模型
数据模型:层次模型、网状模型、关系模型
关系数据库是建立在关系模型上的,而关系模型本质上是若干个存储数据的二维表,可以把它们看做很多Excel表。
表的每一行称为记录(Record),记录是一个逻辑意义上的数据;
表的每一列称为字段(Column),同一个表的每一行记录都拥有相同的若干字段。
字段定义了数据类型(整型、浮点型、字符串、日期等),以及是否允许为NULL。注意NULL表示字段数据不存在。一个整型字段如果为NULL不表示它的值为0,同样的,一个字符串型字段为NULL也不表示它的值为空串''。
和Excel表有所不同的是,关系数据库的表和表之间需要建立“一对多”,“多对一”和“一对一”的关系,这样才能够按照应用程序的逻辑来组织和存储数据。
1.主键
主键:关系型数据库中的一条记录中有若干个属性,若其中某一个属性组(注意是组)能唯一标识一条记录,该属性组就可以成为一个主键 。
表中的某一列(或几列)会被定为主键,表示数据唯一性。
比如
1.1.学生表(学号,姓名,性别,班级)
其中每个学生的学号是唯一的,学号就是一个主键
1.2.课程表(课程编号,课程名,学分)
其中课程编号是唯一的,课程编号就是一个主键
1.3.成绩表(学号,课程号,成绩)
成绩表中单一一个属性无法唯一标识一条记录,学号和课程号的组合才可以唯一标识一条记录,所以 学号和课程号的属性组是一个主键 。
成绩表中的学号不是成绩表的主键,但它和学生表中的学号相对应,并且学生表中的学号是学生表的主键,则称成绩表中的学号是学生表的外键 。
同理 成绩表中的课程号是课程表的外键。
2.外键:
如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键。由此可见,外键表示了两个关系之间的相关联系。以另一个关系的外键作主关键字的表被称为主表,具有此外键的表被称为主表的从表。外键又称作外关键字。
ALTER TABLE students
ADD CONSTRAINT fk_class_id
FOREIGN KEY (class_id)
REFERENCES classes (id);
其中,外键约束的名称fk_class_id可以任意,FOREIGN KEY (class_id)指定了class_id作为外键,REFERENCES classes (id)指定了这个外键将关联到classes表的id列(即classes表的主键)。
3.联合主键
关系数据库实际上还允许通过多个字段唯一标识记录,即两个或更多的字段都设置为主键,这种主键被称为联合主键。
4.主键和外键的用途
定义主键和外键主要是为了维护关系数据库的完整性,总结一下:
1.主键是能确定一条记录的唯一标识,比如,一条记录包括身份正号,姓名,年龄。
身份证号是唯一能确定你这个人的,其他都可能有重复,所以,身份证号是主键。
2.外键用于与另一张表的关联。是能确定另一张表记录的字段,用于保持数据的一致性。
比如,A表中的一个字段,是B表的主键,那他就可以是A表的外键。
二.数据库 mysql sql 之间的关系和区别

Sql是草图 mysql是建筑师 数据是砖块 sql是处理砖块(数据)的工人
SQL书写规则:
1)语句以英文 ;结尾
2)不区分关键字的大小写
3)表名与列名不区分大小写
4) 输入符号的时候只能用英文
5)列名不能加单引号
三、MySQL 和redis区别
1.MySQL的优缺点
优点:
1.体积小、速度快、总体拥有成本低,开源,提供的接口支持多种语言连接操作
2..MySQL 的核心程序采用完全的多线程编程。线程是轻量级的进程,它可以灵活地为用户提供服务,而不过多的系统资源。用多线程和C语言实现的MySQL ,充分利用CPU资源
3.有一个非常灵活而且安全的权限和口令系统。当客户与MySQL 服务器连接时,他们之间所有的口令传送被加密,而且MySQL 支持主机认证
4.支持大型的数据库, 可以方便地支持上千万条记录的数据库。作为一个开放源代码的数据库,可以针对不同的应用进行相应的修改
5.支持多种操作系统,如Linux、Windows、AIX、FreeBSD、HP-UX、MacOS、NovellNetware、OpenBSD、OS/2 Wrap、Solaris等
缺点:
1.不支持备份
2.不支持自定义数据类型
3.对存储过程和触发器支持不够友好
4.MySQL最大的缺点是其安全系统,主要是复杂而非标准,另外只有到调用mysqladmin来重读用户权限时才发生改变
2.Redis的优缺点
优点:
1.支持多种数据类型 例如set、zset、list、hash、string这五种数据类型,操作方便
2.性能很好,基于纯内存操作,所以读写性能很好,可以达到10w/s的频率
3.支持数据持久化,便于数据备份、恢复,支持简单的事务,操作满足原子性
4.支持主从复制,实现读写分离,分担读的压力
5.可以设置过期时间,过期自动删除,也可以做持久化
缺点:
1.数据存储在内存,主机断电数据就会丢失
2.存储容量受到物理内存的限制,只能用于小数据量的高性能操作
3.用于缓存时,容易出现’缓存雪崩‘,’缓存击穿‘、‘缓存穿透’等问题
4.修改配置文件,进行重启,将硬盘中的数据加载进内存,时间比较久。在这个过程中,redis不能提供服务
3.两者区别
类型上:MySQL是关系型数据库,Redis是非关系型(缓存)数据库
需求上:MySQL和Redis因为需求的不同,一般都是配合使用
作用上:MySQL用于持久化的存储数据到硬盘,功能强大,但是速度较慢
Redis用于存储使用较为频繁的数据到缓存中,读取速度快
数据存放位置 :MySQL数据放在磁盘,Redis数据放在内存
应用场景:MySQL和Redis都需要根据具体业务场景去选型
数据类型:MySQL:字符串、列表、集合
Redis:String、Hash、List、Set、Zset
四、SQL语句 常见语句使用
1.select
例1.
 2.
2.


2.where 查询某一列
3.and or not 查询某几列或非哪一列
4.order by ASC|DESC;
5.insert into
5.1指定列名和要插入的值:
INSERT INTO table_name (column1, column2, column3, ...)
VALUES (value1, value2, value3, ...);
INSERT INTO Customers (CustomerName, ContactName, Address, City, PostalCode, Country)
VALUES ('Cardinal', 'Tom B. Erichsen', 'Skagen 21', 'Stavanger', '4006', 'Norway');5.2如果要为表的所有列添加值,则无需在 SQL 查询中指定列名。
INSERT INTO table_name
VALUES (value1, value2, value3, ...);6.NULL
NULL值不同于零值或包含空格的字段。具有NULL值的字段是在创建记录期间留空的字段!
6.1
WHERE column_name IS NULL;6.2
WHERE column_name IS NOT NULL;7.update
update语句用于修改表中已有的记录。
UPDATE Customers
SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
WHERE CustomerID = 1; where必须指定否则整个表都会更新8. DELETE
DELETE 语句用于删除表中已有的记录。
8.1.以下 SQL 语句从"Customers"表中删除客户"Alfreds Futterkiste":
DELETE FROM Customers WHERE CustomerName='Alfreds Futterkiste';8.2 删除所有行不删除表
DELETE FROM Customers; 9. LIMIT
LIMIT 子句用于指定要返回的记录数。
以下 SQL 语句从"客户"表中选择前三个记录,其中地区为"德国":
SELECT * FROM Customers
WHERE Country='Germany'
LIMIT 3;10. MIN()
MIN()函数返回所选列的最小值。MAX()函数返回所选列的最大值。
SELECT MIN(Price)/ MAX(Price) AS SmallestPrice
FROM Products;11. COUNT()、AVG() 和 SUM() 函数
COUNT() 函数返回符合指定条件的行数。AVG() 函数返回数值列的平均值 SUM() 函数返回数值列的总和。
SELECT COUNT/AVG/SUM(ProductID)
FROM Products;12. LIKE 运算符
LIKE 运算符在 WHERE 子句中用于搜索列中的指定模式。
LINK与通配符连用
以下 SQL 语句选择 CustomerName 以"a"开头的所有客户:
SELECT * FROM Customers
WHERE CustomerName LIKE 'a%';以下 SQL 语句选择 CustomerName 第二个位置有"r"的所有客户:
SELECT * FROM Customers
WHERE CustomerName LIKE '_r%';13.IN 运算符
IN 运算符允许您在 WHERE 子句中指定多个值。
以下 SQL 语句选择位于"德国"、"法国"或"英国"的所有客户:
实例
SELECT * FROM Customers
WHERE Country IN/NOT IN ('Germany', 'France', 'UK');14. BETWEEN AND运算符
BETWEEN AND运算符选择给定范围内的值。 这些值可以是数字、文本或日期。
以下 SQL 语句选择价格在 10 到 20 之间的所有产品:
SELECT * FROM Products
WHERE Price NOT BETWEEN/ BETWEEN 10 AND 20;BETWEEN 与 IN 示例
以下 SQL 语句选择价格在 10 到 20 之间的所有产品。此外; 不显示 CategoryID 为 1、2 或 3 的产品:
SELECT * FROM Products
WHERE Price BETWEEN 10 AND 20
AND CategoryID NOT IN (1,2,3);15. AS
AS别名用于为表或表中的列提供临时名称。
以下 SQL 语句创建两个别名,一个用于 CustomerID 列,一个用于 CustomerName 列:
SELECT CustomerID AS ID, CustomerName AS Customer
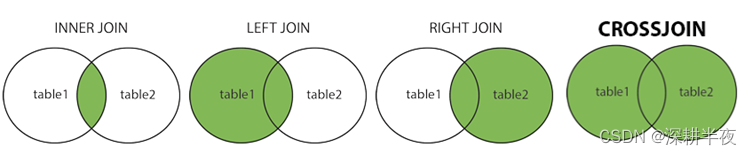
FROM Customers;16. JOIN 连接表
连接表子句用于根据它们之间的相关列组合来自两个或多个表的行。
INNER JOIN:返回两个表中值匹配的记录
LEFT JOIN:返回左表所有记录,右表匹配记录
RIGHT JOIN:返回右表的所有记录,以及左表的匹配记录
CROSS JOIN:返回两个表中的所有记录
 17.自连接
17.自连接
其实自连接,就是说相当于是两张表,以第一张表的mgr为主,去匹配与它对应的第二张表的id
 18. UNION 运算符
18. UNION 运算符
UNION 运算符用于组合两个或多个 SELECT 语句的结果集。
以下 SQL 语句从"客户"和"供应商"表中返回城市(仅不同的值):
SELECT City FROM Customers
UNION
SELECT City FROM Suppliers
ORDER BY City;19. GROUP BY 语句
GROUP BY 语句将具有相同值的行分组为汇总行,例如"查找每个地区的客户数量"。
GROUP BY 语句通常与聚合函数(COUNT()、MAX(), MIN(), SUM(), AVG()) 按一列或多列对结果集进行分组。
下面的 SQL 语句列出了每个地区的客户数量:
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;20.HAVING
HAVING仅在使用GROUP BY子句生成高级报告的输出时才有用。
Having 和where区别?
having与where的区别:
having是在分组后对数据进行过滤
where是在分组前对数据进行过滤
having后面可以使用聚合函数
where后面不可以使用聚合
以下 SQL 语句列出了每个地区的客户数量,从高到低排序(仅包括客户超过 5 个的地区):
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
HAVING COUNT(CustomerID) > 5
ORDER BY COUNT(CustomerID) DESC;from>where>group(含聚合)>having>order>select。
21. EXISTS和NOT EXISTS
EXISTS和NOT EXISTS子句的返回值是一个BOOL值
1.首先执行一次外部查询
2.对于外部查询中的每一行分别执行一次子查询,而且每次执行子查询时都会引用外部查询中当前行的值。
3.使用子查询的结果来确定外部查询的结果集。 如果外部查询返回100行,SQL 就将执行101次查询,一次执行外部查询,然后为外部查询返回的每一行执行一次子查询。
如果内层子查询有行返回,则返回ture,进行外层当前行语句的执行.
如果内层子查询无行返回,则返回flase,进行外层当前行语句的执行,当然不会执行,返回为空
以下 SQL 语句返回 TRUE 并列出产品价格低于 20 的供应商:
SELECT SupplierName
FROM Suppliers
WHERE EXISTS (SELECT ProductName FROM Products WHERE Products.SupplierID = Suppliers.supplierID AND Price < 20);22.ANY ALL
23. INSERT INTO SELECT 语句
INSERT INTO SELECT 语句从一个表中复制数据并将其插入到另一个表中。
以下SQL语句将"Suppliers"复制到"Customers"(未填充数据的列,将包含NULL):
INSERT INTO Customers (CustomerName, City, Country)
SELECT SupplierName, City, Country FROM Suppliers;24. CASE 语句
CASE 语句遍历条件并在满足第一个条件时返回一个值(如 if-then-else 语句)
以下 SQL 遍历条件并在满足第一个条件时返回一个值:
SELECT OrderID, Quantity,
CASE
WHEN Quantity > 30 THEN 'The quantity is greater than 30'
WHEN Quantity = 30 THEN 'The quantity is 30'
ELSE 'The quantity is under 30'
END AS QuantityText
FROM OrderDetails;25. NULL 函数
26. 注释
单行注释以--开头。
任何介于 -- 和行尾之间的文本都将被忽略(不会被执行)。
27.运算符 + - * / % 位运算符 & | ^ 与 或 异或 比较运算符
 五、表指令
五、表指令
1.打开已存在的数据库 USE db_name;
2.查看当前用户已打开的数据库 SELECT DATABASE();
3.创建数据表
语法:CREATE TABLE [IF NOT EXISTS] table_name(column_name data_type,……); (列之间用逗号分割)
CREATE TABLE user(username VARCHAR(20),age INT,salary DOUBLE(8,2));
4.查看数据库表 SHOW TABLES;
5.查看数据表结构 DESC user;