Tensorflow 2.12 简单智能商城商品推荐系统搭建
- 前言
- 架构
- 数据
- 召回
- 排序
- 部署
- 调用
- 结尾
前言
基于 Tensorflow 2.12 搭建一个简单的智能商城商品推荐系统demo~
主要包含6个部分,首先是简单介绍系统架构,接着是训练数据收集、处理,然后是召回模型、排序模型的搭建以及训练、导出等,最后是部署模型提供REST API接口以及如何调用进行推荐。
Tensorflow是谷歌开源的机器学习框架,可以帮助我们轻松地构建和部署机器学习模型。这里记录学习使用Tensorflow来搭建一个简单的智能商城商品推荐系统。
相关版本:
- python 3.1.0
- pandas 2.0.3
- tensorflow 2.12.0
- tensorflow-recommenders 0.7.3
架构
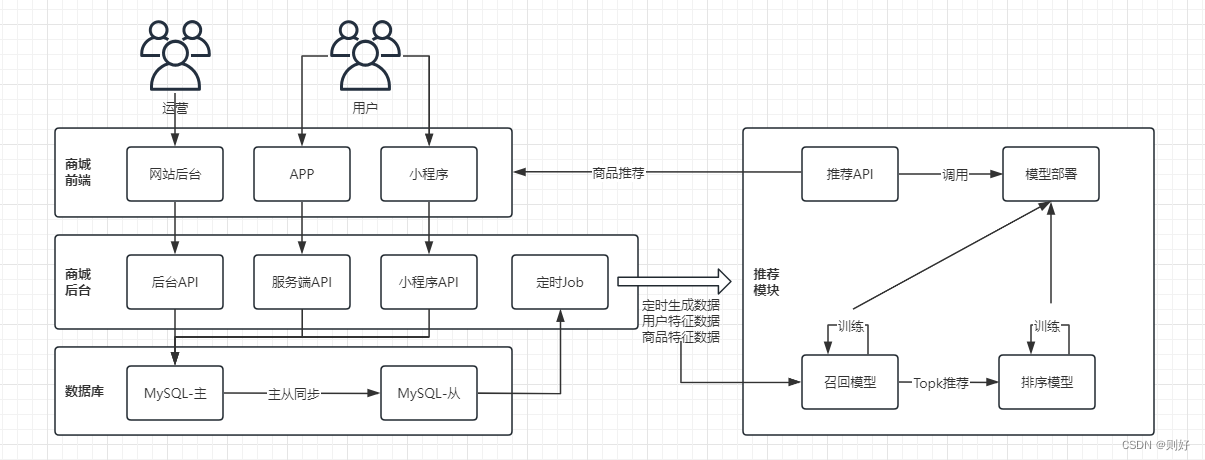
通常一个商城系统主要包含前端、后台,前端包含网站、移动H5、APP、小程序、公众号等,后台主要包含相关的API服务以及存储层等。
首先运营通过后台来录入商品信息、进行上架,然后前端用户通过商城APP、小程序来浏览商品、搜索商品、进行下单购买、关注、收藏等。
一般系统中都会保留用户的这些操作数据,例如浏览数据、搜索数据、下单数据等,结合运营录入的商品数据,通过定时Job生成用户的特征数据、商品的特征数据,然后使用机器学习来找到用户喜欢的但又没有购买过的商品,进行简单的AI推荐。
这里简单的画了一个图:
数据
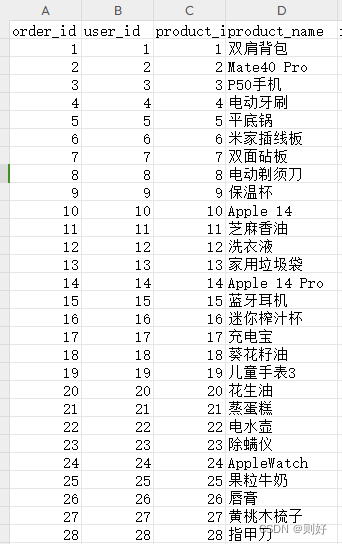
数据收集部分这里就不展开讲了,相信现在大部分电商系统都有保留用户的一些搜索数据、下单数据等,以及后台录入的商品数据,通过一个定时JOB,定时把数据查询出来导出为CSV文件即可,作为后续进行模型训练的数据集。
当然没有也没关系,可以写一个简单的Java方法、或者python方法随机生成数据,写到CSV文件中。
这里先从最简单的开始,只使用用户的下单数据以及商品数据来进行训练(主要特征为用户Id、商品Id)。
召回
主要是训练一个双塔召回模型,根据用户的历史下单数据以及商品数据,召回几百到数千条用户喜欢的商品(基于内容的推荐)。
召回模型搭建分为以下几部分:
1、数据处理
2、模型搭建
3、模型训练
4、模型评估
5、模型导出
import pprint
import pandas as pd
from typing import Dict, Text
import numpy as np
import tensorflow as tf
import tensorflow_recommenders as tfrs
# -*- coding:utf-8 -*-
# 使用pandas加载数据
order_df = pd.read_csv("C:\\data\\python\\data\\blog\\order.csv", encoding="gbk")
pprint.pprint(order_df.shape)
pprint.pprint(order_df.head(5))
# 处理数据类型(转为字符串)
order_df['user_id'] = order_df['user_id'].astype(str)
order_df['product_id'] = order_df['product_id'].astype(str)
# 将DataFrame(pandas)转换为Dataset(tensorflow)
order_df = tf.data.Dataset.from_tensor_slices(dict(order_df))
for x in order_df.take(1).as_numpy_iterator():
pprint.pprint(x)
# 准备嵌入向量的词汇表(用户的)
user_ds = order_df.map(lambda x: {
"user_id": x["user_id"],
"product_id": x["product_id"]
})
# 准备嵌入向量的词汇表(商品的)
product_ds = order_df.map(lambda x: x["product_id"])
# 随机数种子
tf.random.set_seed(42)
# 打乱数据
shuffled = user_ds.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
# 切分数据,分为训练数据以及验证数据
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
# 数据分片
user_ids = user_ds.batch(1_000_000).map(lambda x: x["user_id"])
product_ids = product_ds.batch(1_000)
# 获取唯一的用户Id列表以及商品列表
unique_user_ids = np.unique(np.concatenate(list(user_ids)))
pprint.pprint(unique_user_ids[:5])
unique_product_ids = np.unique(np.concatenate(list(product_ids)))
pprint.pprint(unique_product_ids[:5])
# 将用户特征映射到用户embedding中,查询塔
user_model = tf.keras.Sequential([
tf.keras.layers.StringLookup(vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, 32)
])
# 将商品特征映射到商品embedding中,候选条目塔
product_model = tf.keras.Sequential([
tf.keras.layers.StringLookup(vocabulary=unique_product_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_product_ids) + 1, 32)
])
# 定义模型指标
metrics = tfrs.metrics.FactorizedTopK(
candidates=product_ds.batch(128).map(product_model)
)
# 任务类,把损失函数和指标计算放在一起,本身是一个keras层
task = tfrs.tasks.Retrieval(
metrics=metrics
)
# 完整的双塔召回模型类,负责循环训练模型
class RecModel(tfrs.Model):
# 初始化方法
def __init__(self, user_model, product_model):
super().__init__()
self.user_model: tf.keras.Model = user_model
self.product_model: tf.keras.Model = product_model
self.task: tf.keras.layers.Layer = task
# 计算损失
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
# 获取用户特征
user_embeddings = self.user_model(features["user_id"])
# 获取商品特征
positive_product_embeddings = self.product_model(features["product_id"])
# 计算损失
return self.task(user_embeddings, positive_product_embeddings)
# 创建模型实例
model = RecModel(user_model, product_model)
model.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate=0.05))
# 缓存数据
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
# 开始训练
model.fit(cached_train, epochs=3)
# 评估模型
model.evaluate(cached_test, return_dict=True)
# 为训练好的模型建立索引,这里设置召回前100条商品条目
index = tfrs.layers.factorized_top_k.BruteForce(model.user_model, k=100)
index.index_from_dataset(
tf.data.Dataset.zip((product_ds.batch(100), product_ds.batch(100).map(model.product_model)))
)
# 进行预测
scores, products = index(tf.constant(["42"]))
pprint.pprint(f"用户Id 42 召回结果: {products[0, :5]}")
# 保存、加载模型路径
path = "C:\\data\\python\\data\\blog\\index\\"
# 保存模型
tf.saved_model.save(index, path)
# 加载模型
loaded = tf.saved_model.load(path)
# 进行预测
scores, products = loaded(["42"])
pprint.pprint(f"用户Id 42 召回结果: {products[0, :5]}")
排序
排序部分,主要是根据用户对商品的评分数据训练出一个排序模型,当然有的系统不一定有评分模块,可以以用户的订单数据为基础,结合系统中的其他数据,经过一定的转换算法来生成评分数据,如用户下单记录可以先简单理解为用户喜欢这个商品,记录用户对这个商品的基础评分1分,假如用户多次购买这个商品,在基础分上再加1分,其它的数据如用户分享过的、点赞过的、搜索过的商品都可以加1分或者作为基础分,这样来把系统中的隐式反馈数据转换为显式评分数据,方便后续进行排序模型训练。这里先简单的以用户的下单数据来作为评分数据进行训练,即用户下单的商品都赋值为1分(下图中rating列)。
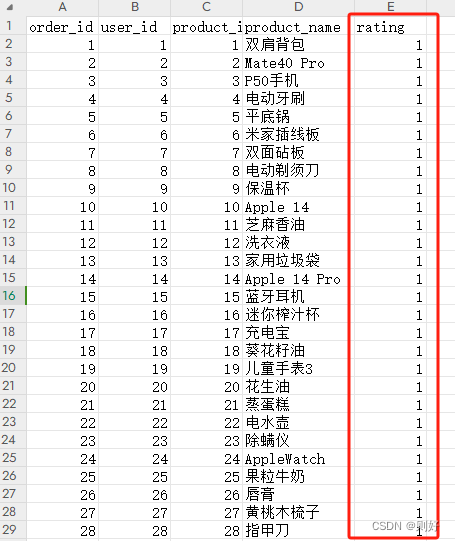
排序模型搭建同样分为以下几部分:
1、数据处理
2、模型搭建
3、模型训练
4、模型评估
5、模型导出
import pprint
from typing import Dict, Text
import pandas as pd
import numpy as np
import tensorflow as tf
import tensorflow_recommenders as tfrs
# 使用pandas加载数据
order_df = pd.read_csv("C:\\data\\python\\data\\blog\\order.csv", encoding="gbk")
pprint.pprint(order_df.shape)
pprint.pprint(order_df.head(5))
# 处理数据类型
order_df['user_id'] = order_df['user_id'].astype(str)
order_df['product_id'] = order_df['product_id'].astype(str)
order_df['rating'] = order_df['rating'].astype(float)
# 将DataFrame(pandas)转换为Dataset(tensorflow)
order_df = tf.data.Dataset.from_tensor_slices(dict(order_df))
for x in order_df.take(1).as_numpy_iterator():
pprint.pprint(x)
# 准备嵌入向量的词汇表
ratings = order_df.map(lambda x: {
"user_id": x["user_id"],
"product_id": x["product_id"],
"rating": x["rating"]
})
# 随机数种子
tf.random.set_seed(42)
# 打乱数据
shuffled = ratings.shuffle(100_000, seed=42, reshuffle_each_iteration=False)
# 切分数据,分为训练数据以及验证数据
train = shuffled.take(80_000)
test = shuffled.skip(80_000).take(20_000)
# 数据分片
user_ids = ratings.batch(1_000_000).map(lambda x: x["user_id"])
product_ids = ratings.batch(1_000_000).map(lambda x: x["product_id"])
# 获取唯一的用户Id列表以及商品列表
unique_user_ids = np.unique(np.concatenate(list(user_ids)))
pprint.pprint(unique_user_ids[:5])
unique_product_ids = np.unique(np.concatenate(list(product_ids)))
pprint.pprint(unique_product_ids[:5])
# 实现排序模型
class BaseModel(tf.keras.Model):
def __init__(self):
super().__init__()
embedding_dimension = 32
# 用户 embeddings
self.user_embeddings = tf.keras.Sequential([
tf.keras.layers.StringLookup(vocabulary=unique_user_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_user_ids) + 1, embedding_dimension)
])
# 商品 embeddings
self.product_embeddings = tf.keras.Sequential([
tf.keras.layers.StringLookup(
vocabulary=unique_product_ids, mask_token=None),
tf.keras.layers.Embedding(len(unique_product_ids) + 1, embedding_dimension)
])
# 预测模型
self.ratings = tf.keras.Sequential([
tf.keras.layers.Dense(256, activation="relu"),
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(1)
])
def call(self, inputs):
# 获取输入
user_id, product_id = inputs
# 获取用户特征、商品特征
user_embedding = self.user_embeddings(user_id)
product_embedding = self.product_embeddings(product_id)
# 计算评分
return self.ratings(tf.concat([user_embedding, product_embedding], axis=1))
# 完整的模型
class RankModel(tfrs.models.Model):
def __init__(self):
super().__init__()
self.ranking_model: tf.keras.Model = BaseModel()
# 定义损失函数以及评估指标
self.task: tf.keras.layers.Layer = tfrs.tasks.Ranking(
loss = tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.RootMeanSquaredError()]
)
def call(self, features: Dict[str, tf.Tensor]) -> tf.Tensor:
return self.ranking_model((features["user_id"], features["product_id"]))
def compute_loss(self, features: Dict[Text, tf.Tensor], training=False) -> tf.Tensor:
# 获取实际评分
labels = features.pop("rating")
# 获取预测评分
rating_predictions = self(features)
# 计算损失
return self.task(labels=labels, predictions=rating_predictions)
# 实例化模型
model = RankModel()
model.compile(optimizer=tf.keras.optimizers.Adagrad(learning_rate=0.05))
# 缓存训练和评估数据
cached_train = train.shuffle(100_000).batch(8192).cache()
cached_test = test.batch(4096).cache()
# 训练模型
model.fit(cached_train, epochs=3)
# 评估模型
model.evaluate(cached_test, return_dict=True)
# 测试排序模型
test_ratings = {}
test_product_ids = ["1", "2", "3", "4", "5"]
for product_id in test_product_ids:
test_ratings[product_id] = model({
"user_id": np.array(["1"]),
"product_id": np.array([product_id])
})
# 倒序打印排序结果
for product, score in sorted(test_ratings.items(), key=lambda x: x[1], reverse=True):
print(f"排序结果 {product}: {score}")
# 保存模型
tf.saved_model.save(model, "C:\\data\\python\\data\\blog\\rank\\")
# 加载模型
loaded = tf.saved_model.load("C:\\data\\python\\data\\blog\\rank\\")
# 进行排序
print(loaded({"user_id": np.array(["42"]), "product_id": ["42"]}).numpy())
部署
召回以及排序模型训练好之后,我们需要进行部署,提供接口给前端应用进行调用,TensorFlow也提供了部署的组件(TensorFlow Serving),方便开发者快速进行部署,以便提供推荐服务。
1、拉取镜像
docker pull tensorflow/serving
2、配置文件
这里我们有两个训练好的模型,一个是召回模型(index),一个是排序模型(rank),还需要再编写一个配置文件(models.config),配置两个模型的相关信息(包含模型的名称、路径、以及生成模型的平台),具体如下:
model_config_list:{
config:{
name:"index",
base_path:"/models/index",
model_platform:"tensorflow"
},
config:{
name:"rank",
base_path:"/models/rank",
model_platform:"tensorflow"
}
}
编写完成后,总的文件以及相关目录如下:
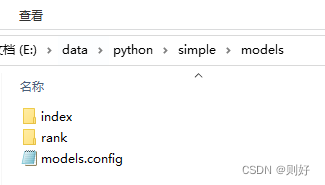
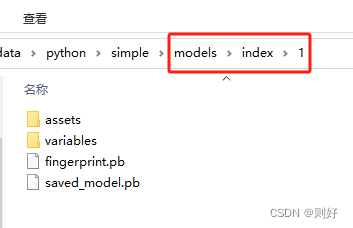
这些文件在dockerfile中进行添加或者启动容器后上传都可以,这里注意一个点,模型文件夹里面还需要再建一个版本号文件夹,例如1,用来表示版本号,具体可见下面截图:
3、启动容器
这里直接以上面拉取的tensorflow/serving镜像为基础,启动容器,同时挂载本地的models文件夹到容器的models文件夹下,以及指定多模型配置文件(models.config),即可运行,具体如下:
docker run -t -p 8501:8501 --mount type=bind,source=E:\data\python\simple\models,target=/models -e MODEL_NAME=index -t tensorflow/serving --model_config_file=/models/models.config &
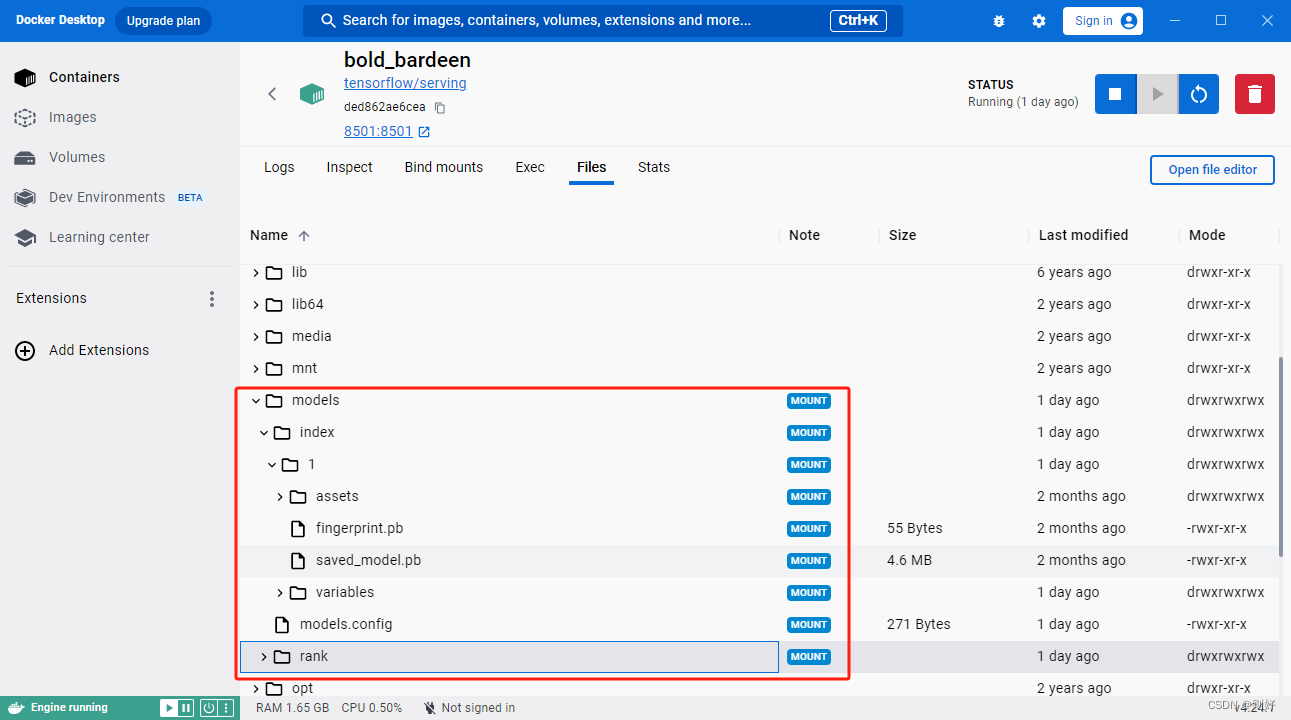
如果有用docker desktop,可以在containers界面看到启动的容器,点击进去查看日志,可以看到两个模型已经成功加载,服务也成功启动,相关截图如下:
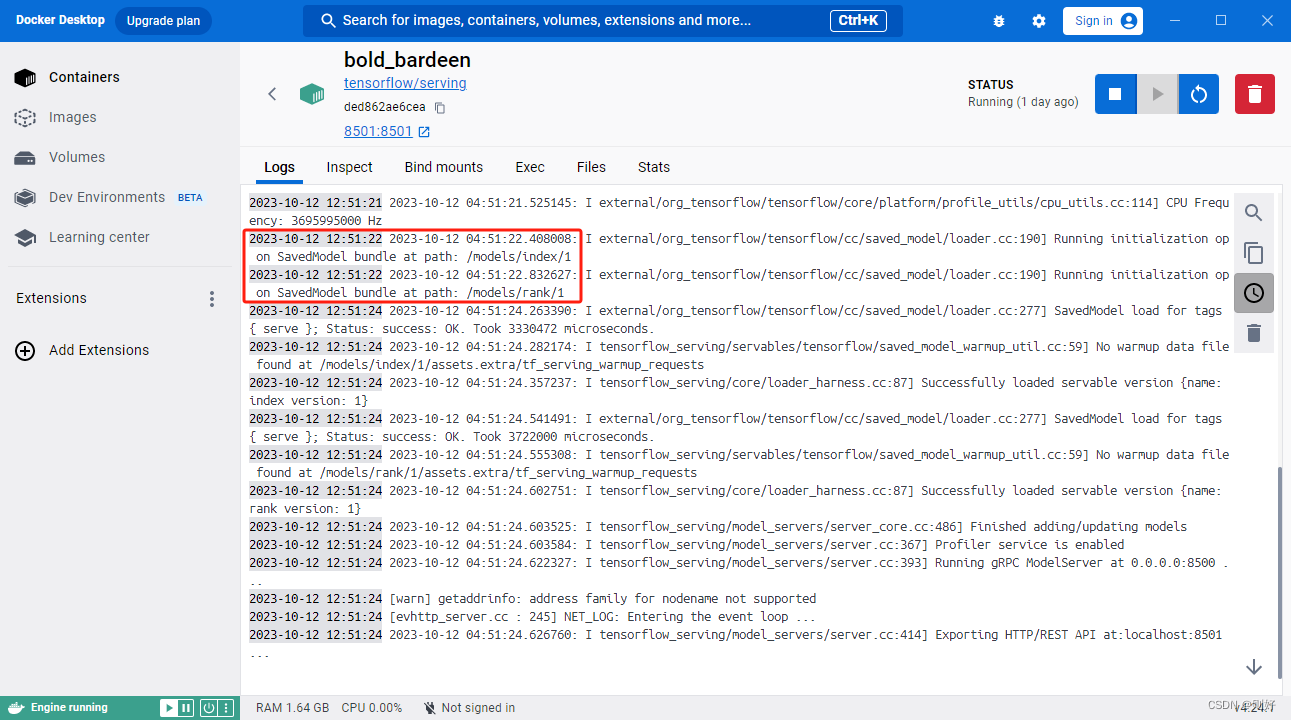
查看容器的文件目录,可以看到我们挂载进去的models文件夹以及下面的相关模型、配置文件,截图如下:
调用
推荐模型部署好之后,我们就可以用http post的方式来调用推荐服务提供的rest api接口了。召回服务的调用路径为:http://localhost:8501/v1/models/index:predict,其中v1对应之前建立的版本号文件夹1,index对应的是召回模型名称,predict是表示进行预测的意思,同理排序模型的调用路径为:http://localhost:8501/v1/models/rank:predict。
这里模拟为用户Id为1和2的两个用户进行商品推荐,示例如下:
# 1、先进行召回推荐,这里使用curl命令来进行调用
curl -d '{"instances":["1","2"]}' -X POST http://localhost:8501/v1/models/index:predict
# 召回推荐返回如下:
{
"predictions": [ # 推荐列表
{ # 用户Id为1召回结果
"output_1": [3.94739556,2.27907419, ...... ], # 召回的依据:分数,100个
"output_2": ["59001","3039", ...... ] # 召回商品Id,与分数一一对应,100个
},
{ # 用户Id为2召回结果
"output_1": [2.272927,2.263876706, ...... ],
"output_2": ["11632","7338", ...... ]
}
]
}
# 2、将召回推荐的结果再输入排序模型来进行排序,得到最终的推荐结果,这里对用户Id为1的召回结果进行排序,用户Id为2同理:
curl -d '{"inputs":{"customer_id":["1","1", ...... ],"product_id":["59001","3039", ......(这里是召回的100个商品Id,太长了省略) ]}}' -X POST http://localhost:8501/v1/models/rank:predict
# 排序返回如下,可以取排序后分数最高的前10个商品作为最终的结果推荐给用户:
{
"outputs": [ # 排序列表
[1.19891763], # 排序的依据分数,与请求参数中的商品Id一一对应,100条
[1.15422344],
......
]
}
结尾
一个简单的推荐系统demo搭建到这里就结束了,当然生产的推荐肯定不会这么简单,需要我们收集更多的用户特征、商品特征,以及优化、调整超参数~






![[SQL开发笔记]WHERE子句 : 用于提取满足指定条件的记录](https://img-blog.csdnimg.cn/112a932af7774594b42ad28bf2a85e78.png)