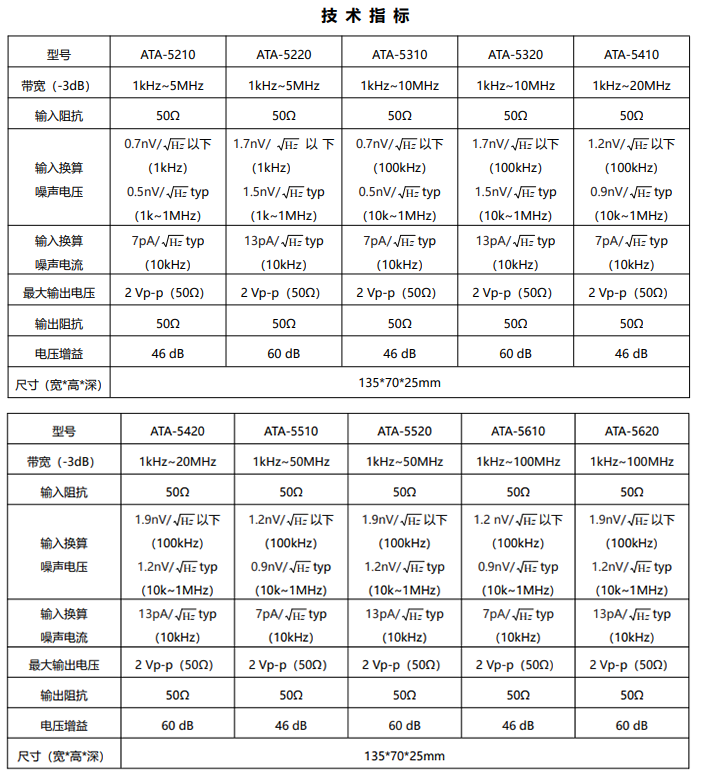
视频车流量识别基本思想是使用背景消去算法将运动物体从图片中提取出来,消除噪声识别运动物体轮廓,最后,在固定区域统计筛选出来符合条件的轮廓。
基于统计背景模型的视频运动目标检测技术:
- 背景获取:需要在场景存在运动目标的情况下获得背景图像;
- 背景扰动:背景中可以含有轻微扰动的对象,如树枝、树叶的摇动,扰动部分不应该被看做是前景运动目标;
- 外界光照变化:一天中不同时间段光线、天气等的变化对检测结果的影响;
- 背景中固定对象的移动:背景里的固定对象可能移动,如场景中的一辆车开走、一把椅子移走,对象移走后的区域在一段时间内可能被误认为是运动目标,但不应该永远被看做是前景运动目标;
- 视频抖动影响:视频抖动容易造成背景被识别出来,出现大面积移动物体,需要提前进行防抖处理;
- 阴影的影响:通常前景目标的阴影也被检测为运动目标的一部分,这样将影响对运动目标的进一步处理和分析;
视频运动目标检测识别OpenCV技术过程如下面流程图所示,较为复杂。主要是图像形态学。
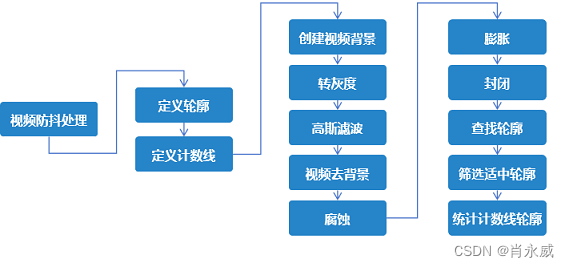
首先通过高速公路上的摄像头获取到一段车流量视频,先预处理:利用灰度线性变换,为了只关注视频中车辆移动的特征,不关注不同车辆的不同颜色的干扰特征;然后对灰度视频去除背景,进一步抑制车辆外的其他特征;接着进行高斯滤波降噪得到噪声很少的二值化黑白视频。然后进行腐蚀,膨胀,闭运算等形态学的相关操作,进一步完善我们近景移动车辆的特征,抑制其他无关特征。接着通过外接矩形框的方式对近景的每辆车查找轮廓,确定检测线的高度,将外接矩形框抽象为一点,设置检测线的偏移量,来进一步提高车辆统计的精度。结果 我们获取到的视频中所有车辆都能通过经过检测线的形式来准确记录。结论 基于opencv的车辆检测与计数,能够将摄像头记录的视频中车辆信息给精确记录,但是对部分车辆的精确度还不够高,通过之后的改进,可以运用到我们的实际生活中,完善我们的智能交通管理体系。
1. 图像形态学概述
图像形态学操作是指基于形状的一系列图像处理操作的合集,主要是基于集合论基础上的形态学数学对图像进行处理。
形态学有四个基本操作:腐蚀、膨胀、开操作、闭操作,膨胀与腐蚀是图像处理中最常用的形态学操作手段。
-
膨胀的原理:
膨胀操作是将图像中的物体边缘膨胀或者扩张。他将原始图像中的每个像素替换为它的相邻像素中的最大值。膨胀可以使物体变得更加的粗壮或者消除小的孤立区域。 -
腐蚀的原理:
腐蚀操作是将图像中的物体边缘腐蚀或者缩小。他将原始图像中的每个像素替换为它的相邻像素中的最小值。腐蚀可以使物体变得更加细小或者消除小的噪声点。 -
开操作:先腐蚀后膨胀,可以去掉小的对象。
-
闭操作:先膨胀后腐蚀,可以填充小对象。
2. OepnCV实现过程
2.1. 视频获取与处理
2.1.1. 视频防抖处理
详见OpenCV防抖实践及代码解析笔记,此处略过。
2.1.1. 摄像头捕获图像的主要函数
- cv2.VideoCapture(x)——默认x填为0,作为启用本机摄像头——你可以设置1,启用其它摄像头/甚至可以传入文件;
- cap.isOpened()——判断是否摄像设备/视频源是否打开——打开返回true;
- cap.read()——读取视频源/设备读取的数据的帧图像——返回两个参数:第一个为是否读取到帧图像,第二个为帧图像;
- imshow(x,y)——这里用来显示读取到的帧图像——前参数为窗口标题,后参数为图像。
2.2. 图像去背景及转灰度
2.2.1. 图像去背景简明原理及定义
视频去背景又叫视频背景扣除,也叫视频前后景分割和提取。对于视频来说,是以时间轴为顺序,每张图片前后有一个关联关系。如果图片的像素在一段时间内不发生变化,我们就认为这个像素是背景色,如果发生频繁的变化,我们就认为是前景色。这是视频去背景算法的原理,但也会有一些缺点,比如一棵树在风吹的时候,那这颗树就从背景识别成了前景。
MOG去背景API:cv2.bgsegm.createBackgroundSubtractorMOG([history, nminxtures, backgroundRatio, noiseSigma])
creatBackgroundSubtractorMOG()是以混合高斯模型为基础的前后景分割算法,是一个类,放在opencv下面的一个子包bgsegm里,我们可以通过这个类创建一个mog对象。
- history:表示建模时需要多长时间的参考帧,默认是200毫秒。假设视频的播放速度是一秒钟显示25张图片,也就是25帧,那么建模参考的图片就是5张。
- nminxtures:高斯值范围,默认是5,就是把一张图片分成5x5个小块,每个小块都有一个高斯值,然后算出一个参考模型
- backgroundRatio:背景比例,就是背景在整张图片中的占比,默认是0.7,就是默认一张图中70%是背景。
- noiseSigma:噪音的参数,这个参数设置为0就是自动降噪,默认值也是0
一般情况下,我们使用这个类时,一般都用默认参数即可,默认值下效果就比较不错了。
MOG2算法,也是高斯混合模型分离算法,是MOG的改进算法。它基于Z.Zivkovic发布的两篇论文,即2004年发布的“Improved adaptive Gausian mixture model for background subtraction”和2006年发布的“Efficient Adaptive Density Estimation per Image Pixel for the Task of Background Subtraction”中提出。该算法的一个重要特征是 它为每个像素选择适当数量的高斯分布,它可以更好地适应不同场景的照明变化等。
2.2.2. 图像转灰度
把图像转换为灰度图像后,进行高斯平滑处理去噪声。
2.2.3. 高斯滤波
GaussianBlur()为了减少图像中的噪声。在边缘检测中,必须计算像素强度的数值导数,这通常会导致“噪声”边缘。换句话说,图像中相邻像素(尤其是靠近边缘)的强度可能会波动很大,从而产生不代表我们正在寻找的主要边缘结构的边缘。 模糊可以平滑边缘附近的强度变化,从而更容易识别图像中的主要边缘结构。
dst=cv2.GaussianBlur(src,ksize,sigmaX,sigmaY,borderType)
参数:
- dst是返回值,表示进行高斯滤波后得到的处理结果。
- src 是需要处理的图像,即原始图像。它能够有任意数量的通道,并能对各个通道 独立处理。图像深度应该是CV_8U、CV_16U、CV_16S、CV_32F 或者 CV_64F中的一 种。
- ksize 是滤波核的大小。滤波核大小是指在滤波处理过程中其邻域图像的高度和宽 度。需要注意,滤波核的值必须是奇数。
- sigmaX 是卷积核在水平方向上(X 轴方向)的标准差,其控制的是权重比例。
- sigmaY是卷积核在垂直方向上(Y轴方向)的标准差。如果将该值设置为0,则只采用sigmaX的值
- borderType是边界样式,该值决定了以何种方式处理边界。一般情况下,不需要考虑该值,直接采用默认值即可。 在该函数中,sigmaY和borderType是可选参数。sigmaX是必选参数,但是可以将该参数设置为0,让函数自己去计算sigmaX的具体值。
在实际使用中,高斯滤波使用的可能是不同大小的卷积核,核的宽度和高度可以不相同,但是它们都必须是奇数,可以根据使用需求选定合适的卷积核。
2.2.4. 去背景二值化
我们需要使用函数:cv2.createBackgroundSubtractorMOG() 创建一个背景对象。这个函数有些可选参数,比如要进行建模场景的时间长度,高斯混合成分的数量,阈值等。将他们全部设置为默认值。然后在整个视频中我们是需要使用backgroundsubtractor.apply() 就可以得到前景的掩模了。
移动的物体会被标记为白色,背景会被标记为黑色的,前景的掩模就是白色的了。
2.3. 图像形态学处理过程
2.3.1. 定义卷积核
cv2.getStructuringElement(shape, ksize) ,返回指定形状和尺寸的结构元素。
参数:
- shape:代表形状类型
- cv2. MORPH_RECT:矩形结构元素,所有元素值都是1
- cv2. MORPH_CROSS:十字形结构元素,对角线元素值都是1
- cv2. MORPH_ELLIPSE:椭圆形结构元素
- ksize:代表形状元素的大小
2.3.2. 腐蚀
dst = cv.erode( src, kernel[, dst[, anchor[, iterations[, borderType[, borderValue]]]]] )
参数:
- src是输入图像; 通道数可以是任意的,图像类型应该是以下几种类型中的其中之一:CV_8U, CV_16U, CV_16S, CV_32F or CV_64F。
- dst是输出图像,与 SRC 大小和类型相同。
- kernel是用于腐蚀的结构元件;如果 element=Mat(),则使用 3 x 3 矩形结构元素。内核可以使用 getStructuringElement 函数获得。
- anchor是锚点在元素中的位置;默认值 (-1, -1) 表示定位点位于元素中心。
- iterations是施加腐蚀的次数。
- borderType是像素外推法,参考 BorderTypes
- borderValue 常量边框情况下的边框值
腐蚀:将前景物体变小,理解成将图像断开裂缝变大,它沿着物体边界移除像素并缩小物体的大小,会增强图像的暗部。(在图片上画上黑色印记,印记越来越大,去掉微小的移动物体)。

2.3.3. 膨胀
cv2.dilate(img, kernel, iteration)
参数:
- img是目标图片
- kernel是进行操作的内核,默认为3×3的矩阵
- iterations是膨胀次数,默认为1
膨胀:将前景物体变大,理解成将图像断开裂缝变小,通过将像素添加到该图像中的对象的感知边界,扩张放大图像中的明亮白色区域。(在图片上画上黑色印记,印记越来越小,把抓取到的物体变大)。

2.3.4. 开闭运算
morphologyEx(src,op,kernel,dst = None,anchor = None,iterations = None,borderType = None,borderValue = None)
参数:
- src是输入图像,输入图像的通道数是任意的。
- op是形态操作的类型
- cv2.MORPH_ERODE(腐蚀)
- cv2.MORPH_DILATE(膨胀)
- cv2.MORPH_OPEN(开运算)
- cv2.MORPH_CLOSE(闭元素)
- kernel是输入一个数组作为核。能被getStructuringElement创建。
- anchor是核的锚点位置,负值说明该锚点位于核中心。默认为核中心。
- iterations是整型int。腐蚀与膨胀被应用的次数。默认为None。
2.4. 边缘检测及识别轮廓
在边缘检测中,必须计算像素强度的数值导数,这通常会导致“噪声”边缘,从而产生不代表我们正在寻找的主要边缘结构的边缘。 模糊可以平滑边缘附近的强度变化,从而更容易识别图像中的主要边缘结构。详见GaussianBlur()。
2.4.1. 边缘检测基本原理
在数学中,函数的变化率由导数来刻画,图像我们看成二维函数,其上面的像素值变化,当然也可以用导数来刻画,当然图像是离散的,那我们换成像素的差分来实现。
对于阶跃型边缘,其一阶导数具有极大值,极大值点对应二阶导数的过零点,也就是,准确的边缘的位置是对应于一阶导数的极大值点,或者二阶导数的过零点(注意不仅仅是二阶导数为0值的位置,而且是正负值过渡的零点)。
故边缘检测算子的类型当然就存在一阶和二阶微分算子。常见边缘检测算子:Roberts 、Sobel 、Prewitt、Laplacian、Log/Marr、Canny、Kirsch、Nevitia。
2.4.2. OpenCV轮廓检测
contours, hierarchy = cv2.findContours(image,mode,method)
参数:
- image是输入图像
- mode是轮廓的模式
- cv2.RETR_EXTERNAL只检测外轮廓
- cv2.RETR_LIST检测的轮廓不建立等级关系
- cv2.RETR_CCOMP建立两个等级的轮廓,上一层为外边界,内层为内孔的边界。如果内孔内还有连通物体,则这个物体的边界也在顶层
- cv2.RETR_TREE建立一个等级树结构的轮廓。
- method是轮廓的近似方法
- cv2.CHAIN_APPROX_NOME存储所有的轮廓点,相邻的两个点的像素位置差不超过1
- cv2.CHAIN_APPROX_SIMPLE压缩水平方向、垂直方向、对角线方向的元素,只保留该方向的终点坐标,例如一个矩形轮廓只需要4个点来保存轮廓信息
- cv2.CHAIN_APPROX_TC89_L1,cv2.CV_CHAIN_APPROX_TC89_KCOS
- contours是返回的轮廓
- hierarchy是每条轮廓对应的属性
2.5. 画轮廓线与统计计数线
2.5.1. 画方框
cv2.rectangle(img, pt1, pt2, color, thickness, lineType, shift )
参数表示依次为: (图片,长方形框左上角坐标, 长方形框右下角坐标, 字体颜色,字体粗细)。
在图片img上画长方形,坐标原点是图片左上角,向右为x轴正方向,向下为y轴正方向。左上角(x,y),右下角(x,y) ,颜色(B,G,R), 线的粗细。
2.5.2. 画直线
cv2.line(img, pt1, pt2, color[, thickness[, lineType[, shift]]])
- img,背景图
- pt1,直线起点坐标
- pt2,直线终点坐标
- color,当前绘画的颜色。如在BGR模式下,传递(255,0,0)表示蓝色画笔。灰度图下,只需要传递亮度值即可。
- thickness,画笔的粗细,线宽。若是-1表示画封闭图像,如填充的圆。默认值是1.
- lineType,线条的类型
3. 实践代码
import cv2
import numpy as np
cap = cv2.VideoCapture(r'video1_1.mp4') #加载视频文件, 第2.1章知识点
bgsubmog = cv2.bgsegm.createBackgroundSubtractorMOG() #视频去背景,第2.2章知识点
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (5,5)) #设置形态学处理的kernel,5x5的矩形即可,第八章知识点
min_w = 90 #大轮廓和小轮廓的分界点
min_h = 90 #大轮廓和小轮廓的分界点
cars = [] #汽车轮廓的中心点坐标
line_height = 190 #红计数线位置
offset = 10 #计数线上下的偏移量
carnum = 0 #车辆计数
#------------用while循环读取视频中的图像帧并处理------------
while True: #如果读取成功就将捕获的视频帧显示在video窗口里,如果读取不成功就打印出warning,并退出循环
ret, frame = cap.read() #cap对象的.read()方法
if ret:
cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) #转成灰度图像
blur = cv2.GaussianBlur(frame, (3,3), 5,5) #高斯平滑去噪,第2.2.3章知识点
##gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) # 获取灰度图像——cvtColor颜色控制,返回一个图像
#cv2.imshow('video0', gray)
mask = bgsubmog.apply(blur) #去背景,背景去掉后,留下都是动的物体,比如汽车、刮风动的树、草等,下面是形态学处理去除树和草
cv2.imshow('video1', blur)
erode = cv2.erode(mask, kernel) #腐蚀,去掉小的斑块,腐蚀后草就不见了,树有时还能看到
cv2.imshow('video2', erode)
dilate = cv2.dilate(erode, kernel, iterations=3) #膨胀3次,还原放大,因为腐蚀后物体变小了,不利于我们计算。
close = cv2.morphologyEx(dilate, cv2.MORPH_CLOSE, kernel, iterations=2) #闭操作2次,去掉汽车内部的小块A
cv2.imshow('video3', close)
cnts, h = cv2.findContours(close, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE) #查找轮廓,就是找到每一个移动的汽车了
for c in cnts: #遍历这些轮廓
(x,y, w,h) = cv2.boundingRect(c) #给每个轮廓圈上矩形框,这样轮廓就变成xywh四个参数了
isValid = (w>=min_w) and (h>=min_h) #去除小轮廓,比如车灯的轮廓,我们不需要。判断如果矩形框的最小宽高小于90,就是小轮廓,就忽略continue
if not isValid:
continue #宽高小于90的就忽略,跳过,继续循环;如果大于90,就是有效的车辆,就把这个矩形框的中心点记下来
cv2.rectangle(frame, (x,y), (x+w, y+h), (0,0,255), 2) #在原图上,把大轮廓用红色矩形框圈出来
x1 = int(w/2) #计算大轮廓的中心点,也就是矩形框的中心点,并把中心点都放到cars里面
y1 = int(h/2)
cx = x + x1
cy = y + y1
cpoint = (cx, cy)
cars.append(cpoint)
cv2.line(frame, (10,line_height), (1200, line_height), (255,255,0),2) #画一条计数线,穿过计数线的车就计数
for (x,y) in cars: #看cars里面的中心点是否在计数线的附近,就是车经过了这个计数线我们就计数
if (y<(line_height+offset) and y>(line_height-offset)):
carnum +=1
cars=[]
cv2.putText(frame, 'Cars Count:'+str(carnum), (100, 70), cv2.FONT_HERSHEY_SIMPLEX, 2, (255,0,255), 5) #第18章知识点,讲计数结果显示在视频上
cv2.imshow('video', frame)
else:
print('warning: video is not load correctly or the video is finished')
break
key = cv2.waitKey(1) #每一帧图像就显示一毫秒就可以,然后继续循环
if key == 27: #27是esc的ascall码
break
cap.release() #释放视频资源
cv2.destroyAllWindows() #释放窗口资源
4. 遇到的问题
module ‘cv2’ has no attribute ‘bgsegm’
使用cv2时报错:
AttributeError: module ‘cv2.cv2’ has no attribute ‘bgsegm’
报错原因:使用的python环境中没有安装扩展包contrib
可以通过pip或者conda安装
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple opencv-contrib-python
Installing collected packages: opencv-contrib-python
Successfully installed opencv-contrib-python-4.8.1.78
5. 总结
我在技术实践过程中,总结出现了如下情况:
- 移动车辆速度差别大,易出现重复计数;
- 需要改进识别判断算法;
- 录制视频时注意防抖,使用视频前最好进行防抖处理,如果抖动较大或多的情况下,这种识别技术基本不可用;
- 检测环境尽量远离路口(路口环境复杂,测速变化及速度差别较大);
- 拍摄视频时,选择比较干净的背景,尽量避开树木、桥梁、建筑物等影响。
参考:
深度学习炼丹师-CXD. 基于OpenCV的车辆检测与记数. CSDN博客. 2023.06
肖爱Kun. OpenCV图像处理学习十,图像的形态学操作——膨胀腐蚀. CSDN博客. 2022.08
Spark!. opencv——形态学基本操作(腐蚀与膨胀). CSDN博客. 2021.01
宝贝儿好. 【OpenCV 学习笔记】第二十一章: 图像及视频去背景. CSDN博客. 2022.06
JimmyHua. OpenCV图像处理-平滑处理、形态学操作. 知乎. 2019.05