文章目录
- Abstract
- Introduction
- Object detection with R-CNN
- Module design
- Test-time detection
- Visualization, ablation, and modes of error
- Semantic segmentation
- Conclusion
论文链接
源代码
Abstract
在经典PASCAL VOC数据集上测量的对象检测性能在过去几年中趋于稳定,表现最好的方法是复杂的集成系统,通常将多个低级图像特征与高级上下文相结合。在本文中,我们提出了一种简单且可扩展的检测算法,相对于之前在VOC 2012上的最佳结果提高了30%以上的平均精度(mAP),达到53.3%的amAP。我们的方法结合了两个关键的见解:
(1)人们可以将高容量卷积神经网络(cnn)应用于自下而上的区域建议,以定位和分割对象;
(2)当标记训练数据稀缺时,对辅助任务进行监督预训练,然后进行特定领域的微调,可以显著提高性能
证明了简单的边界盒回归方法可以有效地减少错误定位,而错误定位是主要的误差模式
由于我们将区域建议与CNN结合在一起,我们称我们的方法为R-CNN:具有CNN特征的区域,我们还将R-CNN与OverFeat进行了比较,OverFeat是最近提出的基于类似CNN架构的滑动窗口检测器。我们发现,在200类ILSVRC2013检测数据集上,R-CNN的性能大大优于OverFeat
Introduction
这篇论文首次表明,与基于更简单的hog特征的系统相比,CNN可以在PASCAL VOC上显著提高目标检测性能
为了实现这一结果,我们专注于两个问题:用深度网络定位目标和只用少量带注释的检测数据训练高容量模型
我们通过在“使用区域识别”范式中运行来解决****CNN定位问题,该范式在目标检测和语义分割方面都取得了成功
我们使用一种简单的技术(仿射图像扭曲)从每个区域建议中计算固定大小的CNN输入,而不考虑区域的形状
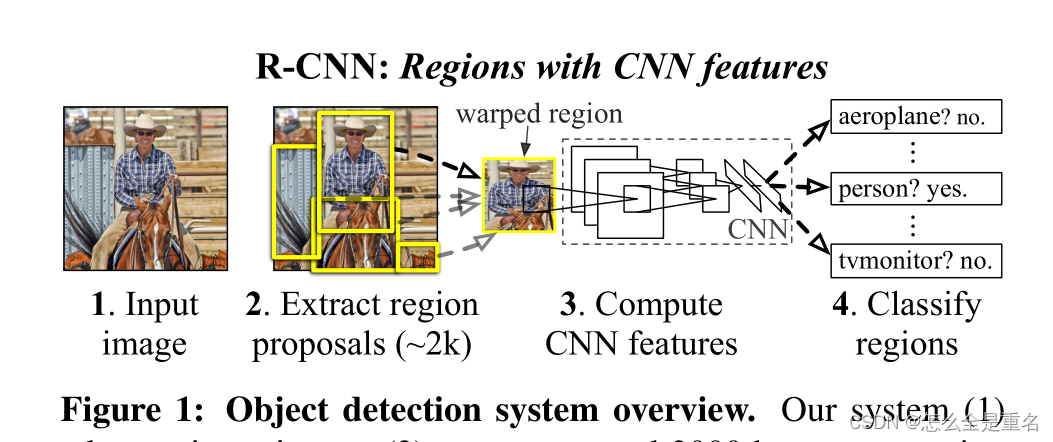
(1)获取输入图像,(2)提取大约2000个自下而上的区域建议,(3)使用大型卷积神经网络(CNN)计算每个建议的特征,然后(4)使用特定类别的线性支持向量机对每个区域进行分类
检测面临的第二个挑战是标记数据稀缺,目前可用的数量不足以训练大型CNN
本文的第二个主要贡献是表明,在大辅助数据集(ILSVRC)上进行监督预训练,然后在小数据集(PASCAL)上进行特定领域的微调,是在数据稀缺时学习高容量cnn的有效范例
我们证明了简单的边界盒回归方法可以有效地减少错误定位,而错误定位是主要的误差模式
Object detection with R-CNN
Module design
我们的目标检测系统由三个模块组成。
第一个生成与类别无关的区域建议,这些建议定义了我们的检测器可用的候选检测集。
第二个模块是一个大型的卷积神经网络,从每个区域提取固定长度的特征向量。
第三个模块是一组特定于类的线性支持向量机

Test-time detection
在测试时,我们对测试图像进行选择性搜索以提取大约2000个区域建议(我们在所有实验中都使用选择性搜索的“快速模式”)。
我们wrap每个提议,并通过CNN向前传播,以计算特征。
然后,对于每个类,我们使用为该类训练的支持向量机对每个提取的特征向量进行评分。
给定图像中所有评分区域,我们应用贪婪非最大抑制(独立于每个类),如果该区域与大于1的较高评分区域有交集-过并(IoU)重叠,则拒绝该区域
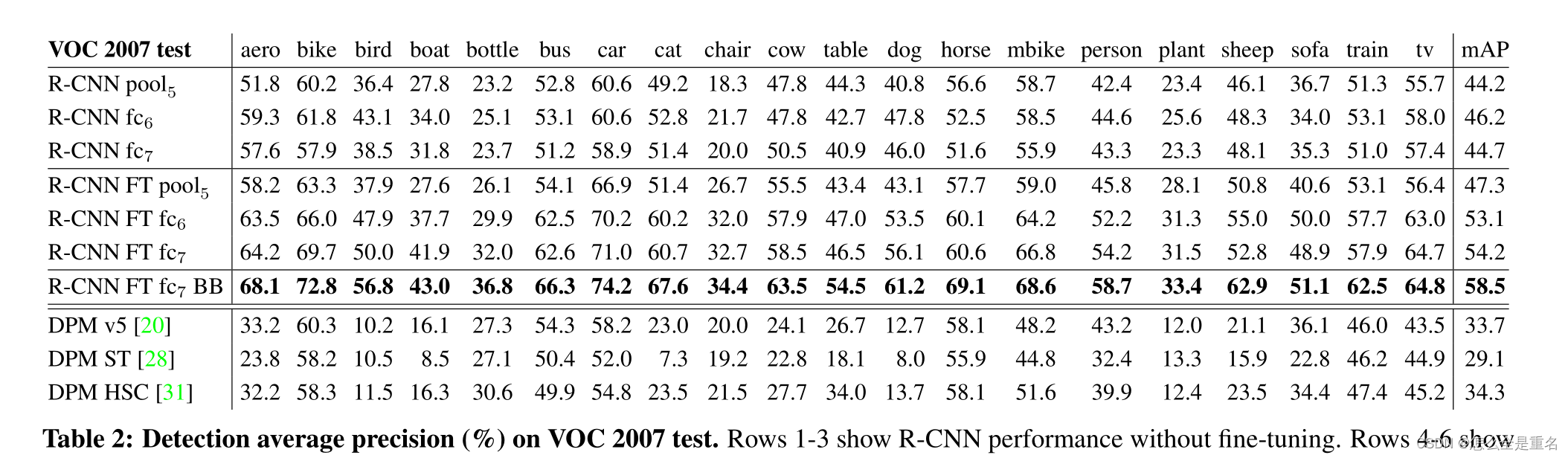
Visualization, ablation, and modes of error

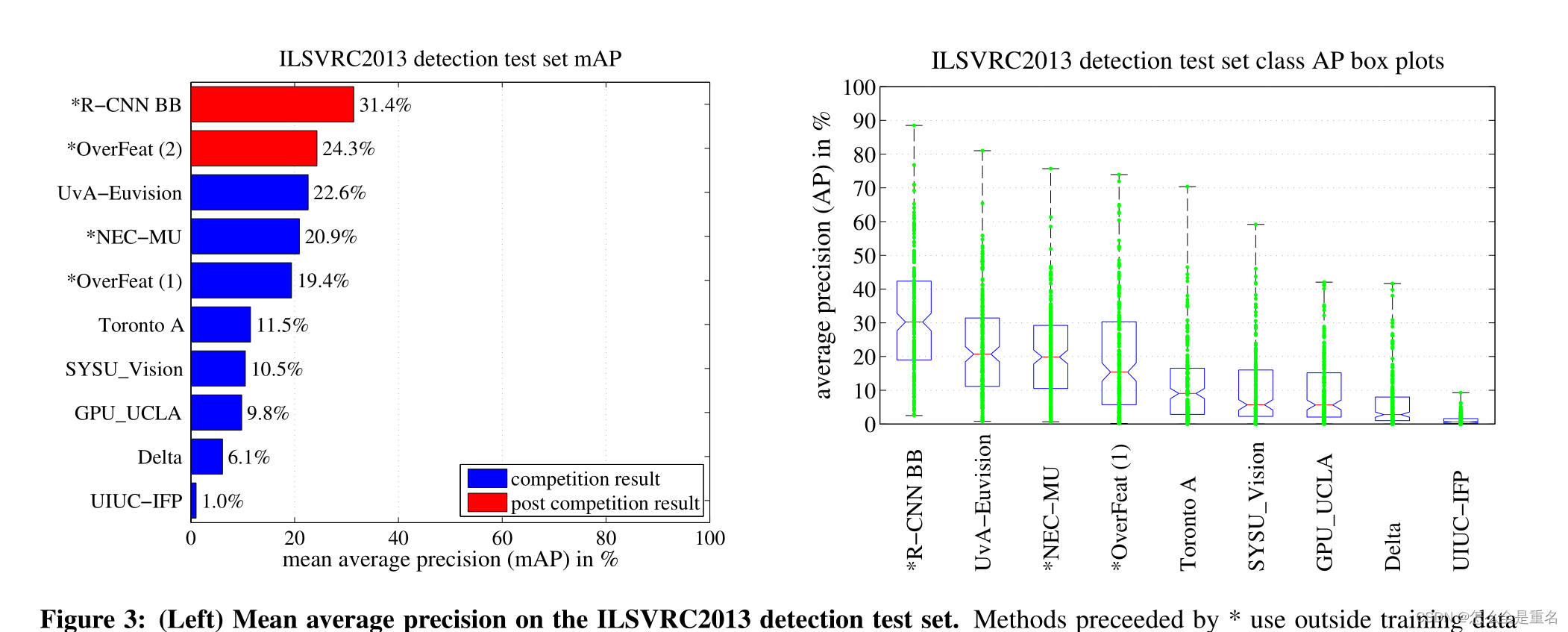
R-CNN与UVA和Regionlets最直接的可比性,因为所有方法都使用选择性搜索区域建议

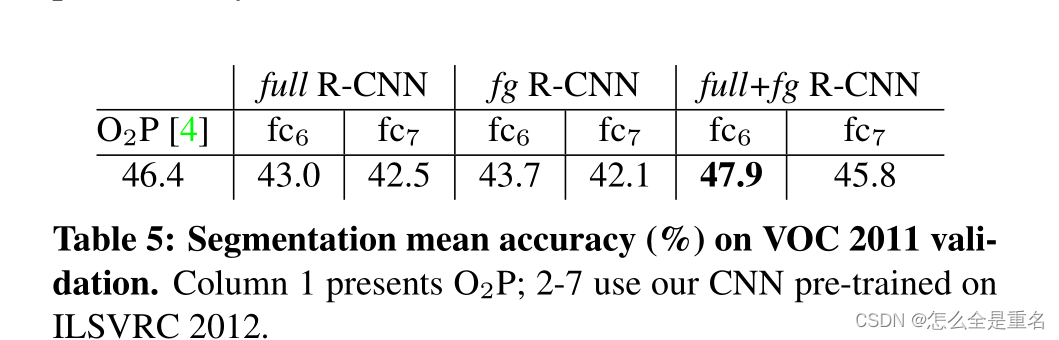
Semantic segmentation

Conclusion
我们最后指出,通过使用计算机视觉和深度学习的经典工具(自下而上的区域建议和卷积神经网络)的组合,我们取得了这些结果,这一点很重要。这两者并不是对立的科学探索路线,而是自然而不可避免的合作伙伴