一、Spark SQL的Shuffle分区数目设定

在允许spark程序时,查看WEB UI监控页面发现,某个Stage中有200个Task任务,也就是说RDD有200分区Partion。
产生原因:
在Spark SQL中,当Job中产生Shuffle时,默认的分区数(spark.sql.shuffle.partions)为200,在实际项目中要合理的设置。local模式建议适当降低,集群模式下应动态调整。
配置修改:

二、异常数据处理API
(1)去重方法dropDuplicates
功能:对DF的数据进行去重,如果重复数据有多条,取第一条。

# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
if __name__ == '__main__':
spark = SparkSession.builder.\
appName('wordcount').\
master('local[*]').\
getOrCreate()
sc = spark.sparkContext
'''读取数据'''
df = spark.read.format('csv').\
option('sep', ';').\
option('header', True).\
load('../input/people.csv')
# 数据清洗:数据去重
# dropDuplicates 是DataFrame的API,可以完成数据去重
# 无参数使用,对全部的列 联合起来进行比较,去除重复项,只保留一条
df.dropDuplicates().show()
df.dropDuplicates(['age', 'job']).show()
无参数:
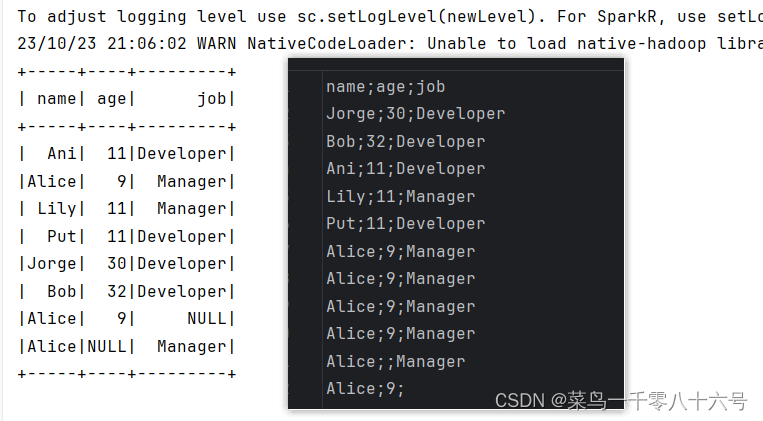
有参数:

(2)删除有缺失值的行方法dropna
功能:如果数据中包含null通过dropna来进行判断,符合条件就删除这一行数据

# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
if __name__ == '__main__':
spark = SparkSession.builder.\
appName('wordcount').\
master('local[*]').\
getOrCreate()
sc = spark.sparkContext
'''读取数据'''
df = spark.read.format('csv').\
option('sep', ';').\
option('header', True).\
load('../input/people.csv')
# 数据清洗:缺失值处理
# dropna API是可以对缺失值的数据进行删除
# 无参数使用,只要列中有Null 就删除这一行数据
df.dropna().show()
# thresh = 3 表示,最少满足三个有效列,不满足 就删除当前行数据
df.dropna(thresh=3).show()
df.dropna(thresh=2, subset=['name', 'age']).show()指定thresh参数:

指定subset:

(3)填充缺失值数据fillna
功能:根据参数的规则,来进行null的替换

# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
if __name__ == '__main__':
spark = SparkSession.builder.\
appName('wordcount').\
master('local[*]').\
getOrCreate()
sc = spark.sparkContext
'''读取数据'''
df = spark.read.format('csv').\
option('sep', ';').\
option('header', True).\
load('../input/people.csv')
# 对缺失值进行填充
# DataFrame的fillna对缺失值的列进行填充
df.fillna('loss').show()
# 对指定的列进行填充
df.fillna('N/A', subset=['job']).show()
# 设定一个字典,对所有的列进行填充缺失值
df.fillna({'name':'未知姓名', 'age':1, 'job':'worker'}).show()全局填充:

指定列填充:

通过字典填充: