# cording:utf8
from pyspark.sql import SparkSession
from pyspark.sql.types import IntegerType, StringType, StructType
import pyspark.sql.functions as F
if __name__ == '__main__':
# 0.构建执行环境入口对象SparkSession
spark = SparkSession.builder.\
appName('movie_demo').\
master('local[*]').\
getOrCreate()
sc = spark.sparkContext
# 1.读取文件
schema = StructType().add('user_id', StringType(), nullable=True). \
add('movie_id', IntegerType(), nullable=True).\
add('rank', IntegerType(), nullable=True).\
add('ts', StringType(), nullable=True)
df = spark.read.format('csv').\
option('sep', '\t').\
option('header', False).\
option('encoding', 'utf-8').\
schema(schema=schema).\
load('../input/u.data')
# TODO 1:用户平均分
df.groupBy('user_id').\
avg('rank').\
withColumnRenamed('avg(rank)', 'avg_rank').\
withColumn('avg_rank', F.round('avg_rank', 2)).\
orderBy('avg_rank', ascending=False).\
show()
# TODO 2:电影的平均分查询
df.createTempView('movie')
spark.sql('''
SELECT movie_id, ROUND(AVG(rank),2) as avg_rank FROM movie GROUP BY movie_id ORDER BY avg_rank DESC
''').show()
# TODO 3:查询大于平均分的电影数量
print('大于平均分电影数量为:', df.where(df['rank'] > df.select(F.avg('rank')).first()['avg(rank)']).count())
# TODO 4:查询高分电影中(>3)打分次数最多的用户,此人打分的平均分
# 找出打分次数最多的人
user_id = df.where('rank>3').\
groupBy('user_id').\
count(). \
withColumnRenamed('count', 'cnt').\
orderBy('cnt', ascennding=False).\
limit(1).\
first()['user_id']
# 算平均分
df.filter(df['user_id'] == user_id).\
select(F.round(F.avg('rank'), 2)).show()
# TODO 5: 查询每个用户的平均分打分,最低打分,最高打分
df.groupBy('user_id').\
agg(
F.round(F.avg('rank'), 2).alias('avg_rank'),
F.min('rank').alias('min_rank'),
F.max('rank').alias('max_rank')
).show()
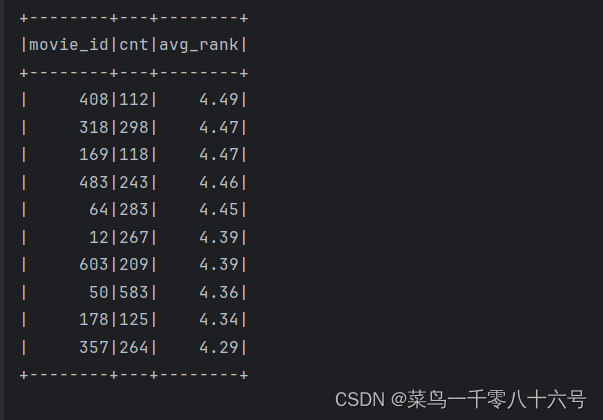
# TODO 6:查询评分超过100次的电影的平均分 排名TOP10
df.groupBy('movie_id').\
agg(
F.round(F.count('movie_id'),2).alias('cnt'),
F.round(F.avg('rank'),2).alias('avg_rank')
).\
where('cnt > 100').\
orderBy('avg_rank', ascending=False).\
limit(10).\
show()
'''
1.agg:它是GroupedData对象的API,作用是:在里面可以写多个聚合
2.alias:它是Column对象的API,可以针对一个列进行改名
3.withColumnRenamed:它是DataFrame的API,可以对DF中的列进行改名,一次改一个列,改多个列可以链式调用
4.orderBy:DataFrame的API,进行排序,参数1是被排序的列,参数2是 升序(True)或降序(False)
5.first:DataFrame的API,取出DF的第一行数据,返回值结果是Row对象
## Row对象:就是一个数组,可以通过row['列名']来取出当前行中,某一列具体数值,返回值不再是DF 或者GroupedData 或者Column 而是具体的值(字符串、数字等)
'''1.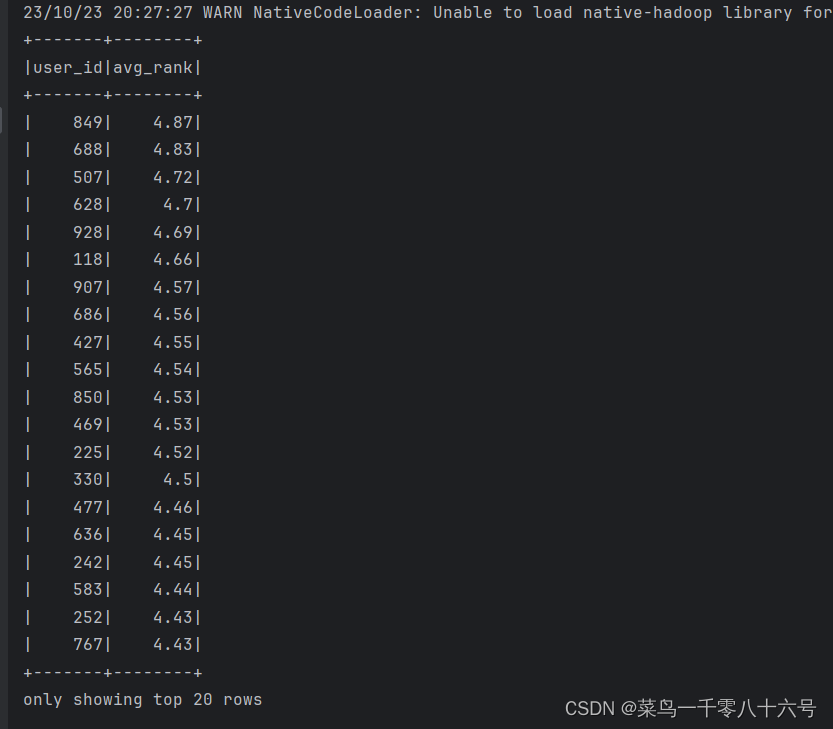
2.
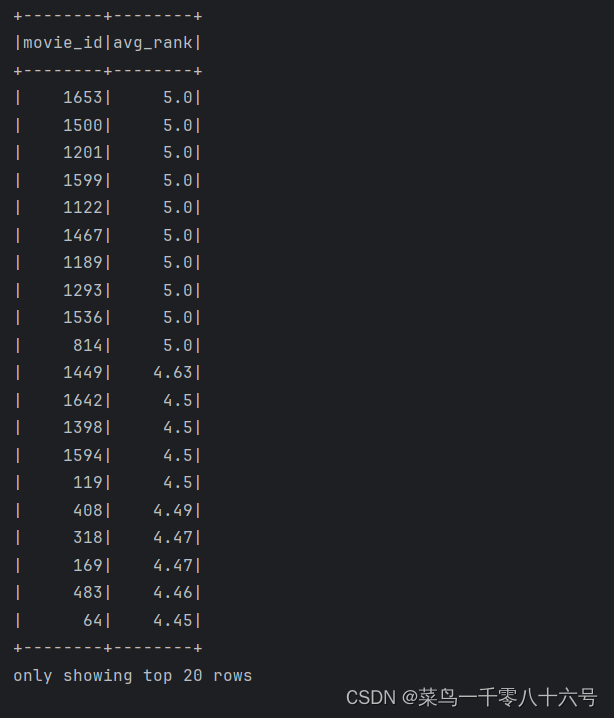
3.

4.

5.
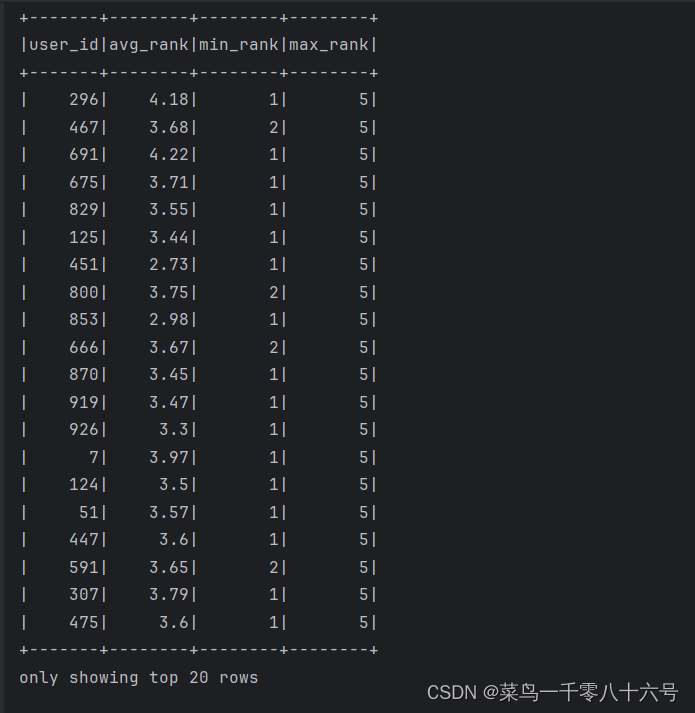
6.