问题描述: 
上述题目的意思为,人工造出一些数据点,对我们的模型y = Xw + b + ∈进行训练,其中标准模型如下:
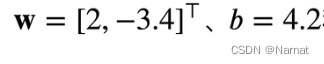
其中W和X都为张量,我们训练的模型越接近题目给出的标准模型越好
训练过程如下:
人造数据集:
说人话,自己利用代码随机创造一些有规律的点,组成点集类似这样:
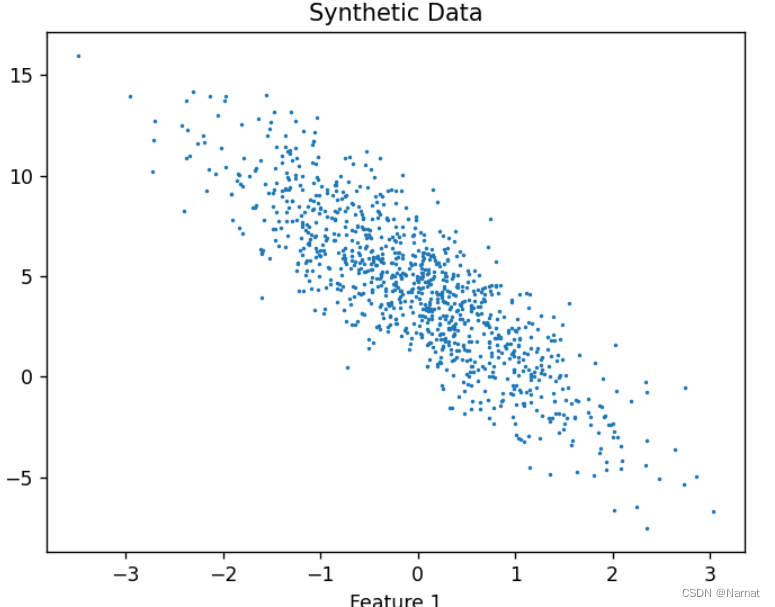
上述点集就服从正态分布:
正态分布(也被称为高斯分布)是统计学中最常见的概率分布之一。它具有以下特征:
1、均值(Mean):正态分布具有一个均值,通常表示为 μ(mu),它代表分布的中心或平均值。分布的对称轴就是均值。
2、方差(Variance):正态分布的方差,通常表示为 σ^2(sigma
squared),代表数据点分散或离散程度的度量。方差越大,数据点越分散。3、随机性:正态分布中的随机变量的值可以取任何实数值,但大多数值集中在均值周围,远离均值的值出现的概率逐渐减小。正态分布的概率密度函数呈钟形曲线,这个曲线是对称的。
正态分布的概率密度函数通常由以下公式表示:
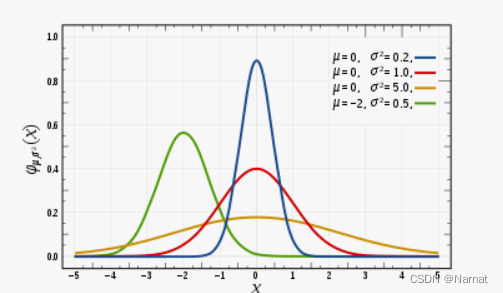
正态分布概率密度函数
4、 正态分布在自然界和科学研究中经常出现,许多现象,如身高、体重、温度测量误差等,都可以近似地用正态分布来描述。正态分布在统计学、机器学习和数据分析中广泛应用,因为它具有许多有用的性质,包括中心极限定理等。
正态分布的特征使得它在各种应用中非常有用,包括假设检验、参数估计、回归分析等。
实现代码:
def synthetic_data(w, b, num_examples):
"""生成 Y = XW + b + 噪声。"""
X = torch.normal(0, 1, (num_examples, len(w)))# 均值为0,方差为1的随机数,n个样本,列数为w的长度
y = torch.matmul(X, w) + b # y = x * w + b
b = torch.normal(0, 0.01, y.shape)
y += b # 加入随机噪音,均值为0.。形状与y的一样
return X, y.reshape((-1, 1))# x, y做成列向量返回
——待完善