目录
1 YOLOV8部署
2 标注软件labelme安装
3 将labelme转化为YOLOV8支持的数据格式
4 开始训练
5 利用训练结果进行测试
1 YOLOV8部署
我的一篇博客已经提到,这里不再赘述:
YOLO V8语义分割模型部署-CSDN博客YOLO V8语义分割模型部署
https://blog.csdn.net/qq_41694024/article/details/133983334
2 标注软件labelme安装
我们采用一键安装的方式:
pip install labelme
这个对python版本有要求,python版本最好是3.8。如果不是那就再茶ungjiange虚拟环境吧。
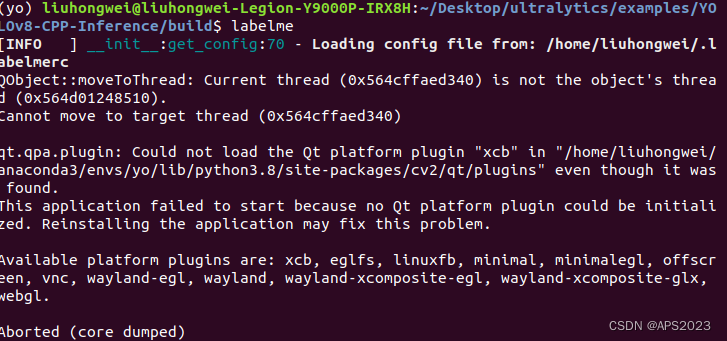
直接命令行输入labelme启动,可能会出现这个问题:
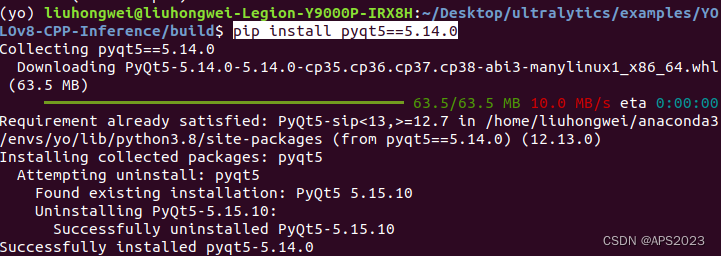
(yo) liuhongwei@liuhongwei-Legion-Y9000P-IRX8H:~/Desktop/ultralytics/examples/YOLOv8-CPP-Inference/build$ labelme [INFO ] __init__:get_config:70 - Loading config file from: /home/liuhongwei/.labelmerc QObject::moveToThread: Current thread (0x564cffaed340) is not the object's thread (0x564d01248510). Cannot move to target thread (0x564cffaed340) qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "/home/liuhongwei/anaconda3/envs/yo/lib/python3.8/site-packages/cv2/qt/plugins" even though it was found. This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem. Available platform plugins are: xcb, eglfs, linuxfb, minimal, minimalegl, offscreen, vnc, wayland-egl, wayland, wayland-xcomposite-egl, wayland-xcomposite-glx, webgl.这是QT版本太高了.....,降低QT版本:
pip install pyqt5==5.14.0
再次启动labelme:
可以用了。
label使用就是打开一个含有图像的文件夹就可以,使用很简单,上过本科的一看界面就会,给大家展示一张标注结果:

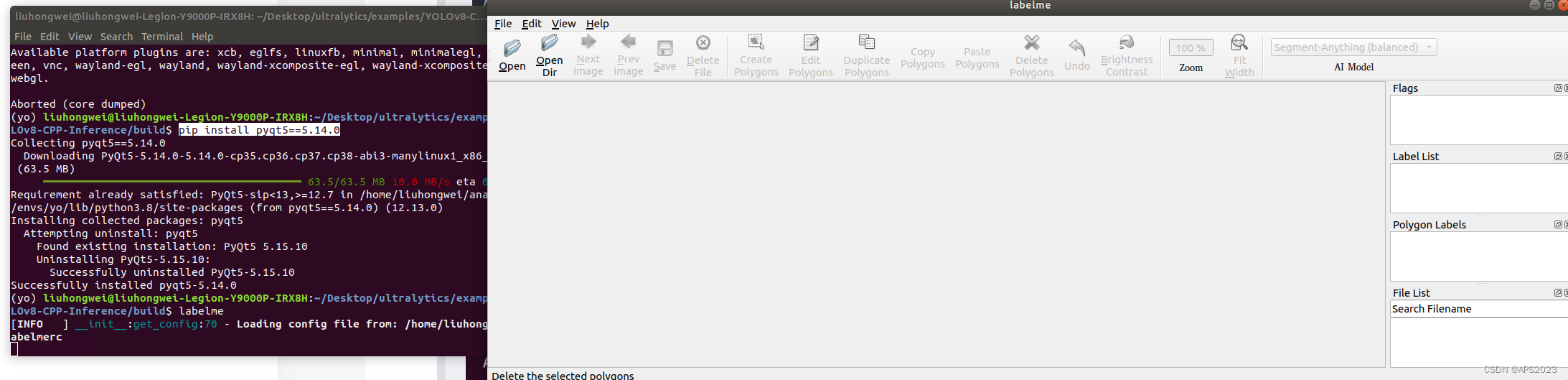

3 将labelme转化为YOLOV8支持的数据格式
先装依赖:
pip install pycocotools用我的脚本将labelme形式的标注文件转化为yolo格式的文件:
''' Created on Oct 23, 2023 @author: Liuhongwei ''' import os import sys import argparse import shutil import math from collections import OrderedDict import json import cv2 import PIL.Image from sklearn.model_selection import train_test_split from labelme import utils class Labelme2YOLO(object): def __init__(self, json_dir): self._json_dir = json_dir self._label_id_map = self._get_label_id_map(self._json_dir) def _make_train_val_dir(self): self._label_dir_path = os.path.join(self._json_dir, 'YOLODataset/labels/') self._image_dir_path = os.path.join(self._json_dir, 'YOLODataset/images/') for yolo_path in (os.path.join(self._label_dir_path + 'train/'), os.path.join(self._label_dir_path + 'val/'), os.path.join(self._image_dir_path + 'train/'), os.path.join(self._image_dir_path + 'val/')): if os.path.exists(yolo_path): shutil.rmtree(yolo_path) os.makedirs(yolo_path) def _get_label_id_map(self, json_dir): label_set = set() for file_name in os.listdir(json_dir): if file_name.endswith('json'): json_path = os.path.join(json_dir, file_name) data = json.load(open(json_path)) for shape in data['shapes']: label_set.add(shape['label']) return OrderedDict([(label, label_id) \ for label_id, label in enumerate(label_set)]) def _train_test_split(self, folders, json_names, val_size): if len(folders) > 0 and 'train' in folders and 'val' in folders: train_folder = os.path.join(self._json_dir, 'train/') train_json_names = [train_sample_name + '.json' \ for train_sample_name in os.listdir(train_folder) \ if os.path.isdir(os.path.join(train_folder, train_sample_name))] val_folder = os.path.join(self._json_dir, 'val/') val_json_names = [val_sample_name + '.json' \ for val_sample_name in os.listdir(val_folder) \ if os.path.isdir(os.path.join(val_folder, val_sample_name))] return train_json_names, val_json_names train_idxs, val_idxs = train_test_split(range(len(json_names)), test_size=val_size) train_json_names = [json_names[train_idx] for train_idx in train_idxs] val_json_names = [json_names[val_idx] for val_idx in val_idxs] return train_json_names, val_json_names def convert(self, val_size): json_names = [file_name for file_name in os.listdir(self._json_dir) \ if os.path.isfile(os.path.join(self._json_dir, file_name)) and \ file_name.endswith('.json')] folders = [file_name for file_name in os.listdir(self._json_dir) \ if os.path.isdir(os.path.join(self._json_dir, file_name))] train_json_names, val_json_names = self._train_test_split(folders, json_names, val_size) self._make_train_val_dir() # convert labelme object to yolo format object, and save them to files # also get image from labelme json file and save them under images folder for target_dir, json_names in zip(('train/', 'val/'), (train_json_names, val_json_names)): for json_name in json_names: json_path = os.path.join(self._json_dir, json_name) json_data = json.load(open(json_path)) print('Converting %s for %s ...' % (json_name, target_dir.replace('/', ''))) img_path = self._save_yolo_image(json_data, json_name, self._image_dir_path, target_dir) yolo_obj_list = self._get_yolo_object_list(json_data, img_path) self._save_yolo_label(json_name, self._label_dir_path, target_dir, yolo_obj_list) print('Generating dataset.yaml file ...') self._save_dataset_yaml() def convert_one(self, json_name): json_path = os.path.join(self._json_dir, json_name) json_data = json.load(open(json_path)) print('Converting %s ...' % json_name) img_path = self._save_yolo_image(json_data, json_name, self._json_dir, '') yolo_obj_list = self._get_yolo_object_list(json_data, img_path) self._save_yolo_label(json_name, self._json_dir, '', yolo_obj_list) def _get_yolo_object_list(self, json_data, img_path): yolo_obj_list = [] img_h, img_w, _ = cv2.imread(img_path).shape for shape in json_data['shapes']: # labelme circle shape is different from others # it only has 2 points, 1st is circle center, 2nd is drag end point if shape['shape_type'] == 'circle': yolo_obj = self._get_circle_shape_yolo_object(shape, img_h, img_w) else: yolo_obj = self._get_other_shape_yolo_object(shape, img_h, img_w) yolo_obj_list.append(yolo_obj) return yolo_obj_list def _get_circle_shape_yolo_object(self, shape, img_h, img_w): obj_center_x, obj_center_y = shape['points'][0] radius = math.sqrt((obj_center_x - shape['points'][1][0]) ** 2 + (obj_center_y - shape['points'][1][1]) ** 2) obj_w = 2 * radius obj_h = 2 * radius yolo_center_x= round(float(obj_center_x / img_w), 6) yolo_center_y = round(float(obj_center_y / img_h), 6) yolo_w = round(float(obj_w / img_w), 6) yolo_h = round(float(obj_h / img_h), 6) label_id = self._label_id_map[shape['label']] return label_id, yolo_center_x, yolo_center_y, yolo_w, yolo_h def _get_other_shape_yolo_object(self, shape, img_h, img_w): def __get_object_desc(obj_port_list): __get_dist = lambda int_list: max(int_list) - min(int_list) x_lists = [port[0] for port in obj_port_list] y_lists = [port[1] for port in obj_port_list] return min(x_lists), __get_dist(x_lists), min(y_lists), __get_dist(y_lists) obj_x_min, obj_w, obj_y_min, obj_h = __get_object_desc(shape['points']) yolo_center_x= round(float((obj_x_min + obj_w / 2.0) / img_w), 6) yolo_center_y = round(float((obj_y_min + obj_h / 2.0) / img_h), 6) yolo_w = round(float(obj_w / img_w), 6) yolo_h = round(float(obj_h / img_h), 6) label_id = self._label_id_map[shape['label']] return label_id, yolo_center_x, yolo_center_y, yolo_w, yolo_h def _save_yolo_label(self, json_name, label_dir_path, target_dir, yolo_obj_list): txt_path = os.path.join(label_dir_path, target_dir, json_name.replace('.json', '.txt')) with open(txt_path, 'w+') as f: for yolo_obj_idx, yolo_obj in enumerate(yolo_obj_list): yolo_obj_line = '%s %s %s %s %s\n' % yolo_obj \ if yolo_obj_idx + 1 != len(yolo_obj_list) else \ '%s %s %s %s %s' % yolo_obj f.write(yolo_obj_line) def _save_yolo_image(self, json_data, json_name, image_dir_path, target_dir): img_name = json_name.replace('.json', '.png') img_path = os.path.join(image_dir_path, target_dir,img_name) if not os.path.exists(img_path): img = utils.img_b64_to_arr(json_data['imageData']) PIL.Image.fromarray(img).save(img_path) return img_path def _save_dataset_yaml(self): yaml_path = os.path.join(self._json_dir, 'YOLODataset/', 'dataset.yaml') with open(yaml_path, 'w+') as yaml_file: yaml_file.write('train: %s\n' % \ os.path.join(self._image_dir_path, 'train/')) yaml_file.write('val: %s\n\n' % \ os.path.join(self._image_dir_path, 'val/')) yaml_file.write('nc: %i\n\n' % len(self._label_id_map)) names_str = '' for label, _ in self._label_id_map.items(): names_str += "'%s', " % label names_str = names_str.rstrip(', ') yaml_file.write('names: [%s]' % names_str) if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument('--json_dir',type=str, help='Please input the path of the labelme json files.') parser.add_argument('--val_size',type=float, nargs='?', default=None, help='Please input the validation dataset size, for example 0.1 ') parser.add_argument('--json_name',type=str, nargs='?', default=None, help='If you put json name, it would convert only one json file to YOLO.') args = parser.parse_args(sys.argv[1:]) convertor = Labelme2YOLO(args.json_dir) if args.json_name is None: convertor.convert(val_size=args.val_size) else: convertor.convert_one(args.json_name)将标注文件全部放在labelmeannotation文件夹内:
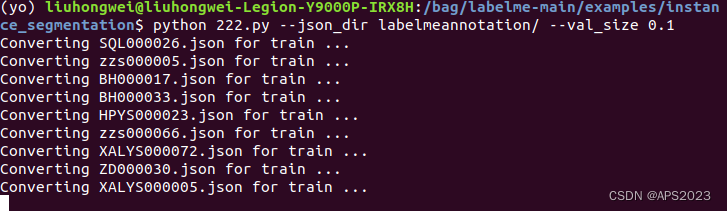
启动脚本,参数1为这个文件夹,参数2为val占数据集的比例,比如是0.1。命令如下:
python 222.py --json_dir labelmeannotation/ --val_size 0.1开始转换ing:
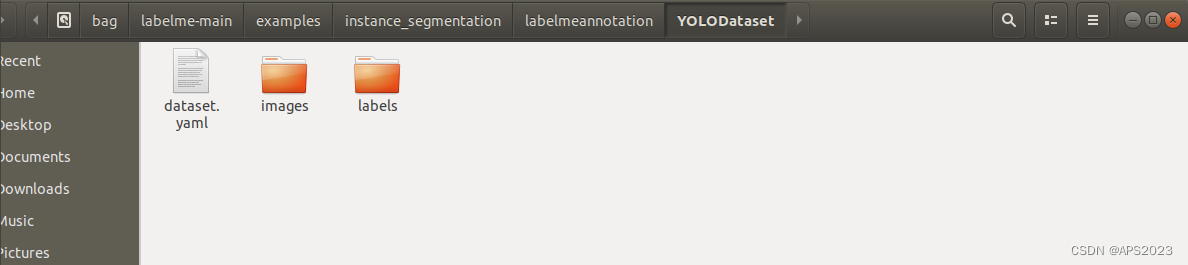
转化完毕:
转化好的文件在labelmeannotation文件夹内。
我们把这个文件拷贝到yolo的主目录下:
新建一个文件default_copy.yaml,里面有几个部分注意修改。
# Ultralytics YOLO 🚀, AGPL-3.0 license # Default training settings and hyperparameters for medium-augmentation COCO training task: detect # (str) YOLO task, i.e. detect, segment, classify, pose mode: train # (str) YOLO mode, i.e. train, val, predict, export, track, benchmark # Train settings ------------------------------------------------------------------------------------------------------- model: # (str, optional) path to model file, i.e. yolov8n.pt, yolov8n.yaml data: /home/liuhongwei/Desktop/ultralytics/YOLODataset/dataset.yaml # (str, optional) path to data file, i.e. coco128.yaml epochs: 300 # (int) number of epochs to train for patience: 50 # (int) epochs to wait for no observable improvement for early stopping of training batch: -1 # (int) number of images per batch (-1 for AutoBatch) imgsz: 640 # (int | list) input images size as int for train and val modes, or list[w,h] for predict and export modes save: True # (bool) save train checkpoints and predict results save_period: -1 # (int) Save checkpoint every x epochs (disabled if < 1) cache: False # (bool) True/ram, disk or False. Use cache for data loading device: 0 # (int | str | list, optional) device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu workers: 16 # (int) number of worker threads for data loading (per RANK if DDP) project: # (str, optional) project name name: /home/liuhongwei/Desktop/ultralytics/666/ # (str, optional) experiment name, results saved to 'project/name' directory exist_ok: False # (bool) whether to overwrite existing experiment pretrained: True # (bool | str) whether to use a pretrained model (bool) or a model to load weights from (str) optimizer: auto # (str) optimizer to use, choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto] verbose: True # (bool) whether to print verbose output seed: 0 # (int) random seed for reproducibility deterministic: True # (bool) whether to enable deterministic mode single_cls: False # (bool) train multi-class data as single-class rect: False # (bool) rectangular training if mode='train' or rectangular validation if mode='val' cos_lr: False # (bool) use cosine learning rate scheduler close_mosaic: 10 # (int) disable mosaic augmentation for final epochs (0 to disable) resume: False # (bool) resume training from last checkpoint amp: True # (bool) Automatic Mixed Precision (AMP) training, choices=[True, False], True runs AMP check fraction: 1.0 # (float) dataset fraction to train on (default is 1.0, all images in train set) profile: False # (bool) profile ONNX and TensorRT speeds during training for loggers freeze: None # (int | list, optional) freeze first n layers, or freeze list of layer indices during training # Segmentation overlap_mask: True # (bool) masks should overlap during training (segment train only) mask_ratio: 4 # (int) mask downsample ratio (segment train only) # Classification dropout: 0.0 # (float) use dropout regularization (classify train only) # Val/Test settings ---------------------------------------------------------------------------------------------------- val: True # (bool) validate/test during training split: val # (str) dataset split to use for validation, i.e. 'val', 'test' or 'train' save_json: False # (bool) save results to JSON file save_hybrid: False # (bool) save hybrid version of labels (labels + additional predictions) conf: # (float, optional) object confidence threshold for detection (default 0.25 predict, 0.001 val) iou: 0.7 # (float) intersection over union (IoU) threshold for NMS max_det: 300 # (int) maximum number of detections per image half: False # (bool) use half precision (FP16) dnn: False # (bool) use OpenCV DNN for ONNX inference plots: True # (bool) save plots during train/val # Prediction settings -------------------------------------------------------------------------------------------------- source: # (str, optional) source directory for images or videos show: False # (bool) show results if possible save_txt: False # (bool) save results as .txt file save_conf: False # (bool) save results with confidence scores save_crop: False # (bool) save cropped images with results show_labels: True # (bool) show object labels in plots show_conf: True # (bool) show object confidence scores in plots vid_stride: 1 # (int) video frame-rate stride stream_buffer: False # (bool) buffer all streaming frames (True) or return the most recent frame (False) line_width: # (int, optional) line width of the bounding boxes, auto if missing visualize: False # (bool) visualize model features augment: False # (bool) apply image augmentation to prediction sources agnostic_nms: False # (bool) class-agnostic NMS classes: # (int | list[int], optional) filter results by class, i.e. classes=0, or classes=[0,2,3] retina_masks: False # (bool) use high-resolution segmentation masks boxes: True # (bool) Show boxes in segmentation predictions # Export settings ------------------------------------------------------------------------------------------------------ format: torchscript # (str) format to export to, choices at https://docs.ultralytics.com/modes/export/#export-formats keras: False # (bool) use Kera=s optimize: False # (bool) TorchScript: optimize for mobile int8: False # (bool) CoreML/TF INT8 quantization dynamic: False # (bool) ONNX/TF/TensorRT: dynamic axes simplify: False # (bool) ONNX: simplify model opset: # (int, optional) ONNX: opset version workspace: 4 # (int) TensorRT: workspace size (GB) nms: False # (bool) CoreML: add NMS # Hyperparameters ------------------------------------------------------------------------------------------------------ lr0: 0.01 # (float) initial learning rate (i.e. SGD=1E-2, Adam=1E-3) lrf: 0.01 # (float) final learning rate (lr0 * lrf) momentum: 0.937 # (float) SGD momentum/Adam beta1 weight_decay: 0.0005 # (float) optimizer weight decay 5e-4 warmup_epochs: 3.0 # (float) warmup epochs (fractions ok) warmup_momentum: 0.8 # (float) warmup initial momentum warmup_bias_lr: 0.1 # (float) warmup initial bias lr box: 7.5 # (float) box loss gain cls: 0.5 # (float) cls loss gain (scale with pixels) dfl: 1.5 # (float) dfl loss gain pose: 12.0 # (float) pose loss gain kobj: 1.0 # (float) keypoint obj loss gain label_smoothing: 0.0 # (float) label smoothing (fraction) nbs: 64 # (int) nominal batch size hsv_h: 0.015 # (float) image HSV-Hue augmentation (fraction) hsv_s: 0.7 # (float) image HSV-Saturation augmentation (fraction) hsv_v: 0.4 # (float) image HSV-Value augmentation (fraction) degrees: 0.0 # (float) image rotation (+/- deg) translate: 0.1 # (float) image translation (+/- fraction) scale: 0.5 # (float) image scale (+/- gain) shear: 0.0 # (float) image shear (+/- deg) perspective: 0.0 # (float) image perspective (+/- fraction), range 0-0.001 flipud: 0.0 # (float) image flip up-down (probability) fliplr: 0.5 # (float) image flip left-right (probability) mosaic: 1.0 # (float) image mosaic (probability) mixup: 0.0 # (float) image mixup (probability) copy_paste: 0.0 # (float) segment copy-paste (probability) # Custom config.yaml --------------------------------------------------------------------------------------------------- cfg: # (str, optional) for overriding defaults.yaml # Tracker settings ------------------------------------------------------------------------------------------------------ tracker: botsort.yaml # (str) tracker type, choices=[botsort.yaml, bytetrack.yaml]1.data:改成我们生成文件的dataset.yaml文件路径 其他就用我的就行了




4 开始训练
将YOLODataset文件夹移动到ultralytics文件夹(YOLO主目录),修改/home/liuhongwei/Desktop/ultralytics/YOLODataset/datasetsyaml文件,改成绝对路径。
train: /home/liuhongwei/Desktop/ultralytics/YOLODataset/images/train/ val: /home/liuhongwei/Desktop/ultralytics/YOLODataset/images/val/ nc: 6 names: ['ZD', 'XALYS', 'ZZS', 'BH', 'SQL', 'HPYS']打开我们的yolo环境输入开始训练
yolo cfg=/home/liuhongwei/Desktop/ultralytics/default_copy.yaml
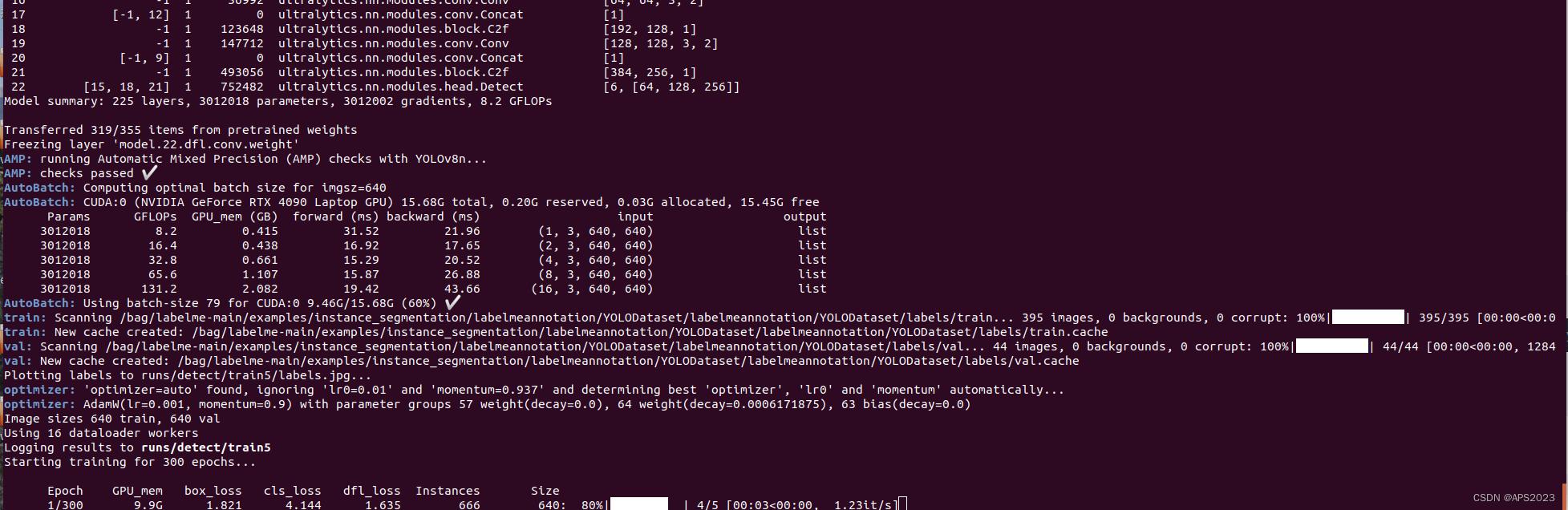
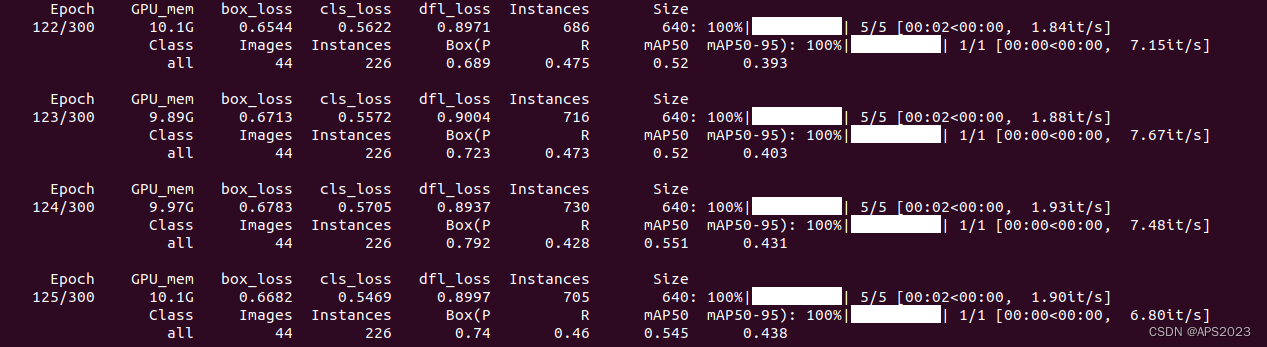
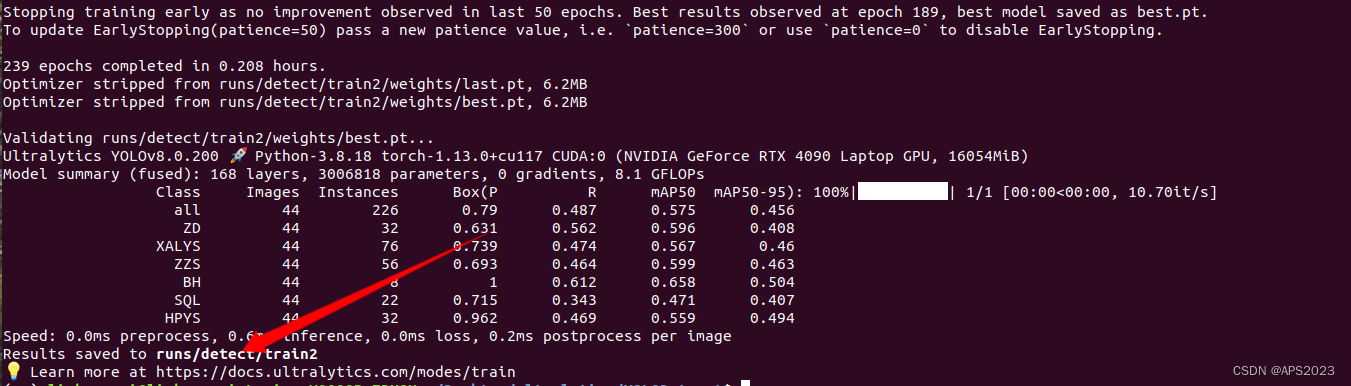
开始训练!这里训练300个epoch!GPU一定显存一定要大!!!mAP一直提高,yolo内部损失函数计算做的很好。
训练完毕!
得到我们的训练结果:




5 利用训练结果进行测试
YOLOV8为我们封装好了测试的功能包:
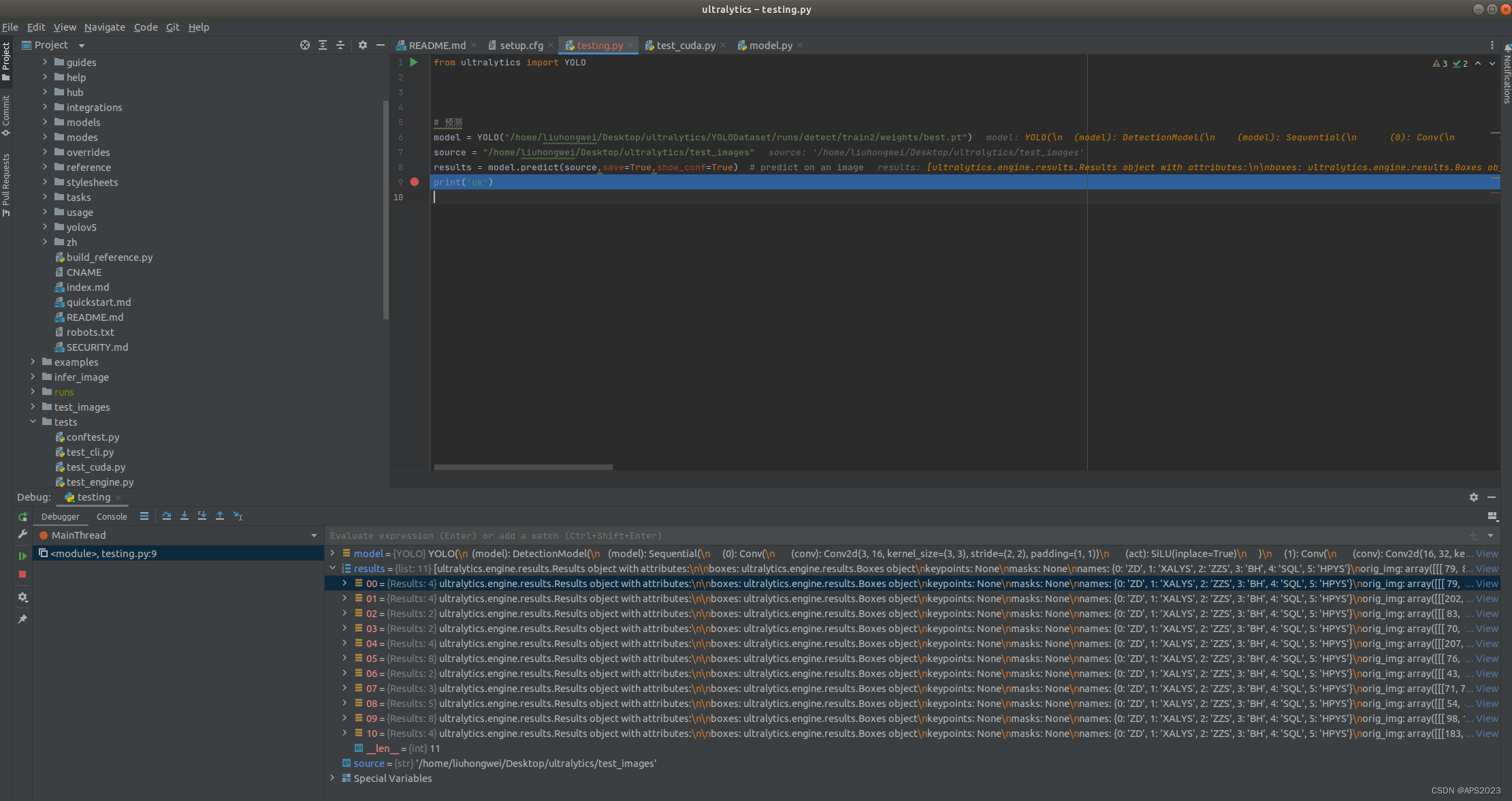
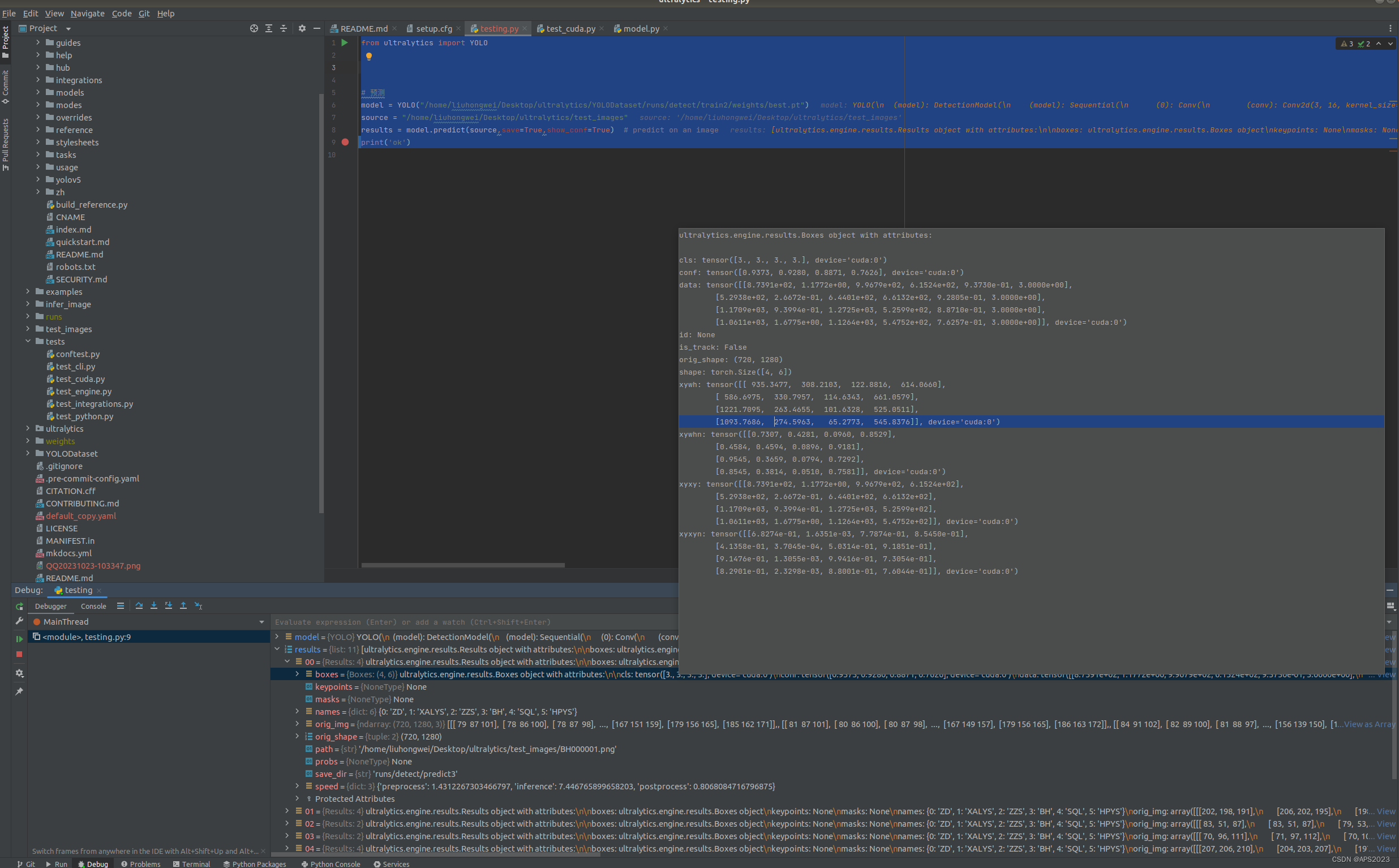
直接调用我的代码即可:
from ultralytics import YOLO # 预测 model = YOLO("/home/liuhongwei/Desktop/ultralytics/YOLODataset/runs/detect/train2/weights/best.pt") source = "/home/liuhongwei/Desktop/ultralytics/test_images" results = model.predict(source,save=True,show_conf=True) # predict on an image print('ok')