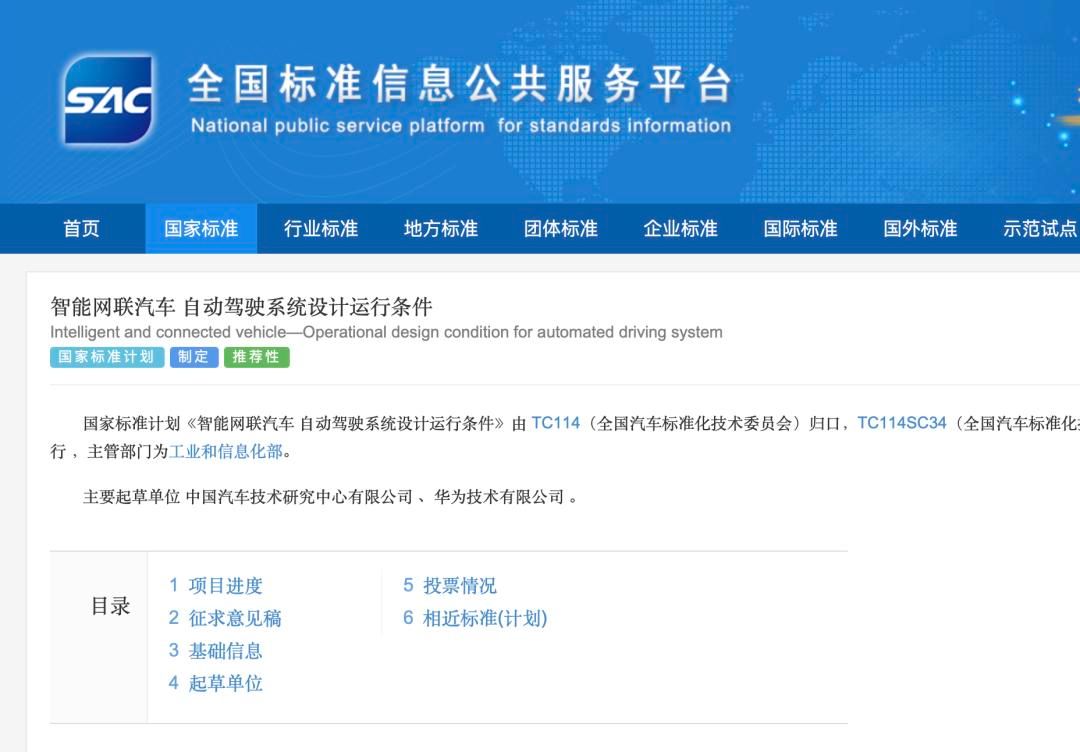
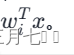基于对象就是对于单一class的设计。
对于有指针的:complex.h complex-test.cpp
对于没有指针的: string.h string-test.cpp
https://blog.csdn.net/ncepu_Chen/article/details/113843775?spm=1001.2014.3001.5501#commentBox
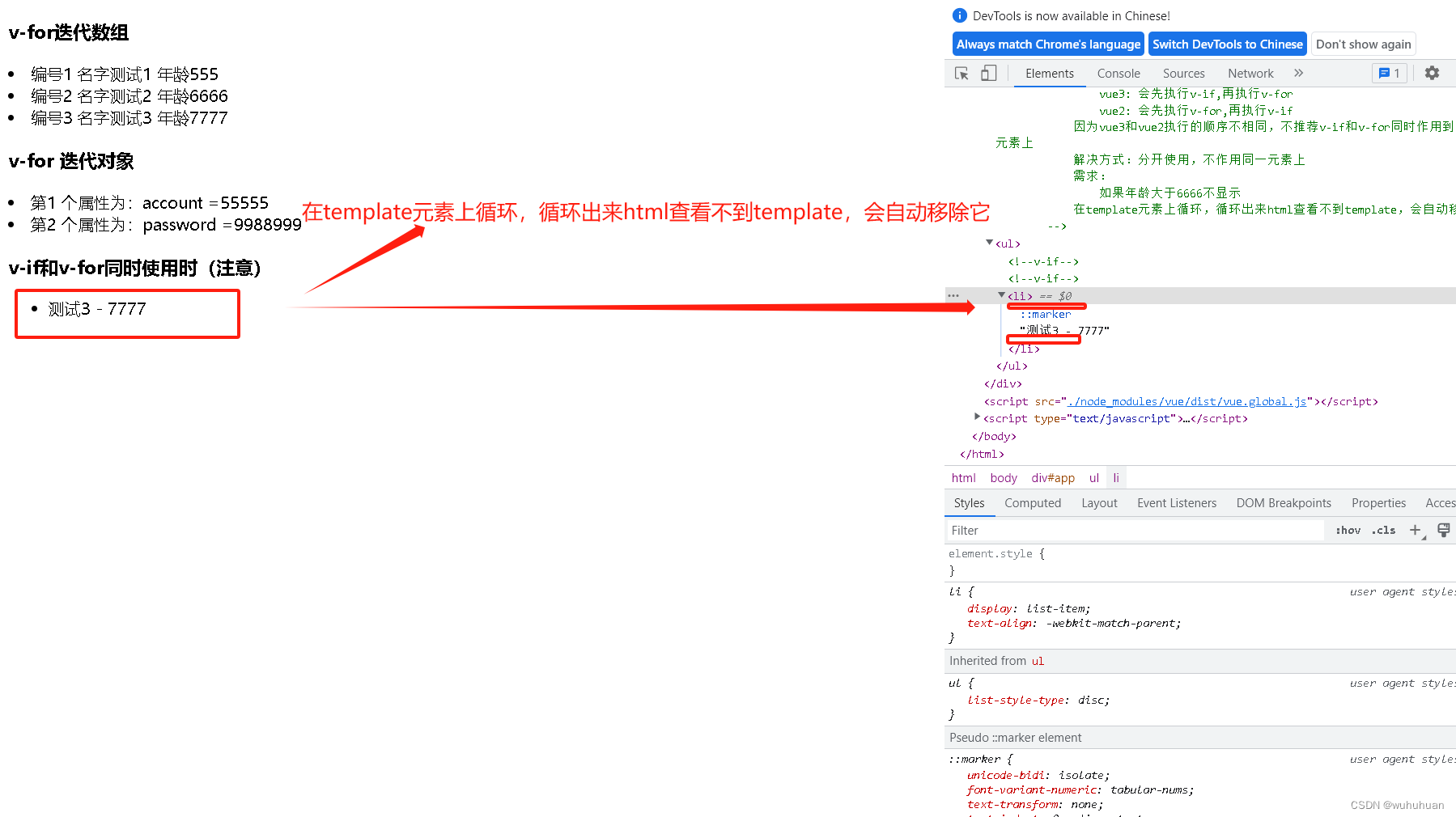
没有指针成员——以复数complex类为例
头文件的写法
从下图可以看到,头文件由四个部分组成:
- 防卫式声明 即头文件的最上面两行和最下面两行
- 前置声明
- 类的声明
- 类的定义
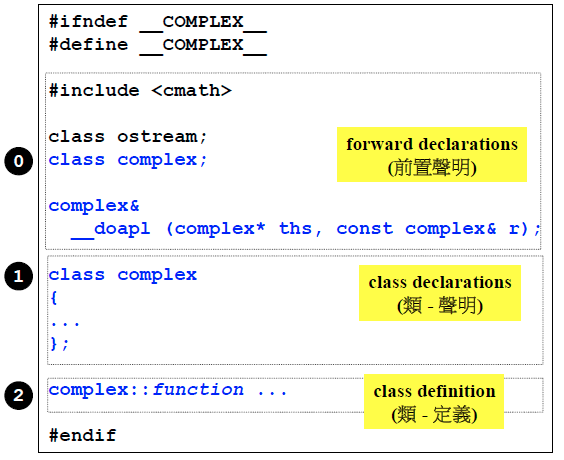
类的声明
这里以构造复数类为例,可以看到这个类中明显的有数据和函数两部分。对于数据部分,这里定义的是double类。

a. 模板
如果我需要不同类型(如int,float)怎么办呢?难道每次都重新写一次?为了偷懒(不是),就引出了模板template概念。
模板的好处就是: 写类的时候不用把类型给固定下来,可以后面用的时候再指定类型。用模板就是先告诉编译器,还没有决定用哪个类型,类型由使用者之后决定。(模板的延伸很多,之后的讲解还是以double的情况来说)

b. 内联函数
定义内联函数有两种方式:
| 1)在类声明内定义的函数,自动成为inline函数 | 2)在类声明外定义的函数,并加上inline关键字 |
|---|---|
 |  |
由程序员定义的inline只是一种建议,至于是不是真正的inline,还得要编译器说了算(不能太复杂,要在编译器的能力范围之内)。
c. 访问级别
分为三类: public,private,protected
一般来说,数据只能供类内部使用,应该设置为private,而函数可以只被内部或者被外部使用。对于复数类的例子,在主函数中通过对象直接调取private的数据成员就是错误的。
构造函数
当想创建一个对象的时候,就会自动调用构造函数:
complex c1(2,1); // 创建一个对象,实部2,虚部1
complex c2; // 创建一个对象,但没有给参数
complex* p = new complex(4); // complex(4, 0) 用动态方式创建一个复数
构造函数有几个特点:
-
写法比较独特,名称一定是和函数类的名称相同;
-
构造函数是可以有参数的,比如实部和虚部;
-
构造函数可以自带默认参数(其他函数也可以),在创建对象时如果没指定参数,就按照默认参数创建。
-
构造函数是没有返回类型的,因为它就是想要构造一个特定的class,已经固定下来了
-
只有构造函数有初始化列表的写法:
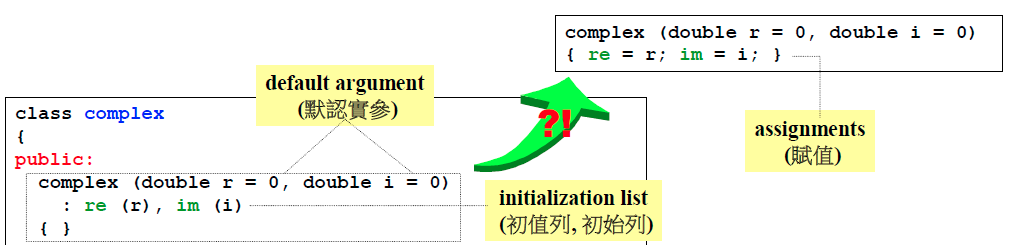 一个变量的设定可以分为两个阶段,一为初始化阶段,二为赋值阶段;如果写成图中右上角的赋值方式,相当于放弃使用初始化列表,这样效率会低一些,不要这么写。
一个变量的设定可以分为两个阶段,一为初始化阶段,二为赋值阶段;如果写成图中右上角的赋值方式,相当于放弃使用初始化列表,这样效率会低一些,不要这么写。 -
构造函数可以有多个,即可以进行函数重载overloading(普通函数也可以)。因为编译器是会综合函数名,函数参数个数,参数类型和返回类型来判断要调用哪个函数的。另外,构造函数的重载是很常见的。
double real () const {return re;} void real(double r) { re = r;} //重载,注意这里不能有const那么下面这种写法正确吗?

答案是:不对。如果创建对象的时候不给参数,那么①可以被调用,因为有默认参数,但②也可以被调用,编译器无法选择,所以这两个不能同时存在。补充:对应于构造函数,还有析构函数,一般对于不带指针的类,不需要特别去写析构函数
构造函数可以写进private中吗?
如果构造函数被写进private中,就不可以在外部构造对象。这和我们最初对类与对象的认知有一点出入,但是在设计模式中的确是有这种情况的,即单例模式。此时是通过调用A类的函数,从而间接的创建对象。

常量成员函数
对于不会改变数据成员内容的函数,要加上const(在函数内容大括号的前面),这里就相当于告诉编译器,这是不会变的。

如果去掉了图中的const, 再用下图中的方法来调用实部,虚部,就会报错:
//这里表示对象的内容是不会变的,但调用的real()函数没有const
//编译器就会理解为这里是可能会变的,这就与const complex造成了矛盾,报错
const complex c1(2,1);
cout << c1.real();
cout << c1.imag();
参数传递
 图中涉及到了三种传参的方式:传值,传引用,传引用const。
图中涉及到了三种传参的方式:传值,传引用,传引用const。
为了提高效率,尽可能使用引用传递参数, 可以避免对参数的复制。如果在函数内不想对变量进行修改,那么就要传引用const。
返回值传递
和上一点相似,返回值也尽量使用引用形式返回。如果要返回的值只是这个函数中的一个局部变量/临时变量,那就一定要用传值来返回。(出了大括号之后就没有生命周期,返回时会报错)比如下面代码,必须要传值返回, 因为返回的必定是个临时对象(没有给名称):
inline complex operator + (const complex& x, const complex& y){
return complex(real(x)+real(y), imag(x)+imag(y));
}
inline complex operator + (const complex& x, const complex& y){
return complex(real(x)+real(y), imag(x)+imag(y));
}
inline complex operator + (const complex& x, const complex& y){
return complex(real(x)+real(y), imag(x)+imag(y));
}
{
int(7); //临时变量
complex c1(2,1);
complex c2;
complex(); //临时变量
complex(4,5); //临时变量,标准库用的较多
cout << complex(2); //临时变量
}
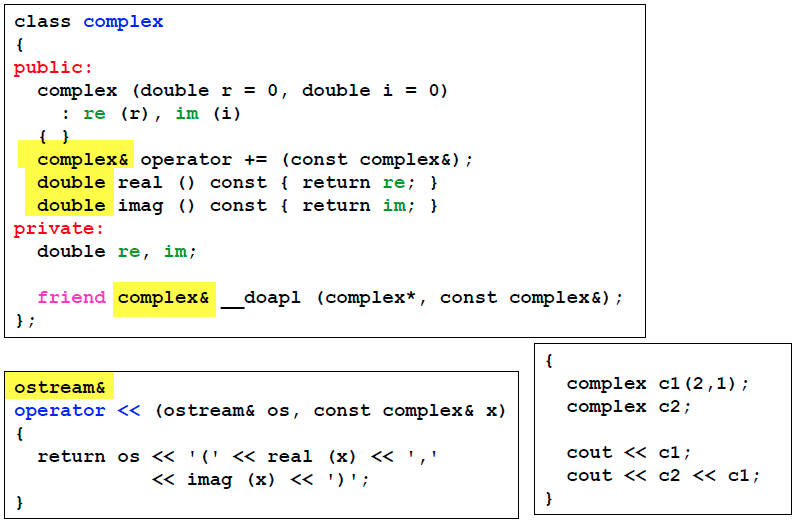
友元
把数据成员设置成private,就是想对其进行封装,外界只能通过public函数间接来取数据。但这里有一种特殊情况:被设置成友元的函数,就可以直接调取私有数据,这比通过公有函数效率更高一点。
相同class的各个对象互为友元,这句话就可以解释下面这个用法为何是成立的。也可以说,在类定义内可以访问其他对象的私有变量。

complex c1(2,1);
complex c2;
c2.func(c1); //c1,c2是同一个类,这样是可以的
操作符重载
操作符重载允许我们对操作符,如加减乘除,进行重新定义。操作符重载有两种写法:
| 1)对成员函数重载: 会把重载的符号作用在左操作数,有this | 2)对全局函数重载:没有this |
|---|---|
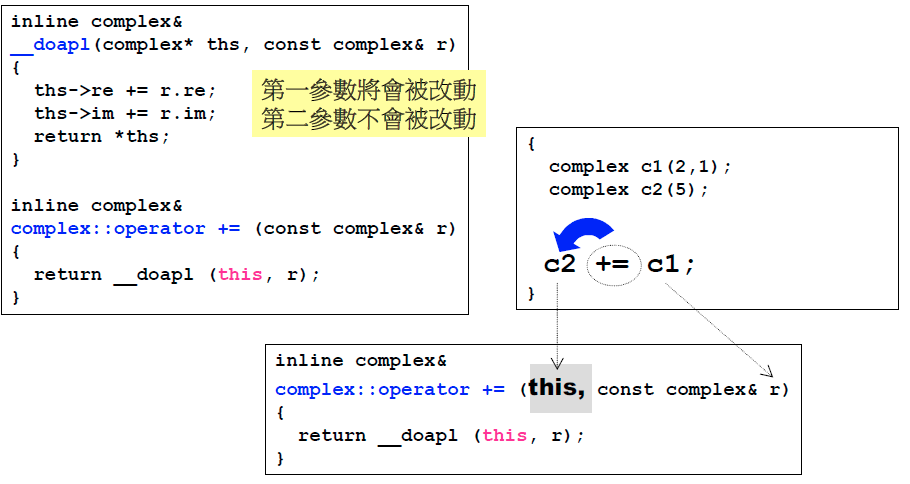 |  |
对于成员函数:
所有的成员函数一定带着一个隐藏参数this指针, 这个this(指针)指向调用这个函数的调用者。代码中参数部分不可以写这个this,但是在函数内部可以用this。图中,会把c2的地址传到this指针中。
对于上图中的complex::operator += ,其返回类型设置为complex&,是为了可以处理连续赋值的情况:
//从右向左, c1加到c2之后,还要返回一个结果加到c3上
c3 += c2 += c1;
传递者不需要直到接受者是以引用形式接受????我不理解 https://zhuanlan.zhihu.com/p/98355681
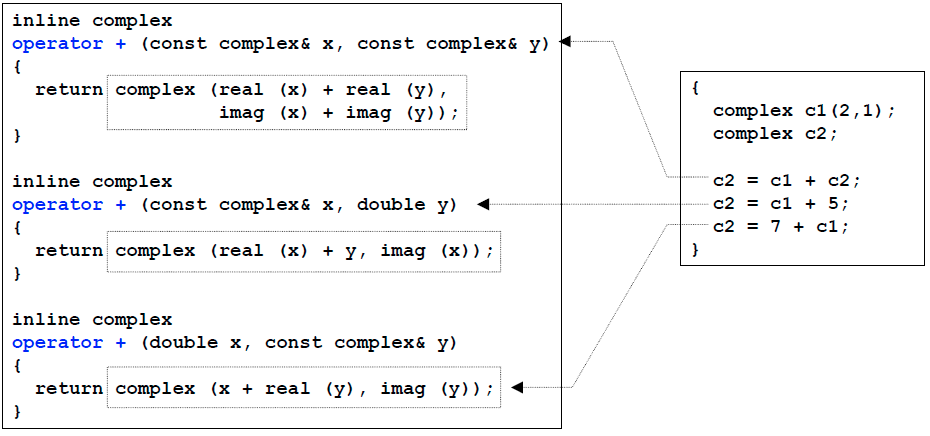
对于非成员函数:
如由上图所示,为了应付三种加法,这里要写三种函数。注意这里的返回值一定不能用引用,因为return的都是临时变量。
有的时候,运算符重载是必须写在非成员函数中的,举3个例子:
1)右上图的第二种和第三种写法, 表示的是“复数+double”和“double+复数”,这个是成员函数的写法不能表示的,因为左操作数不是复数!
2)只有一个参数的时候:这里表示正负号
 3)对于特殊的操作符,比如
3)对于特殊的操作符,比如<<,要把操作符重载设计成全局函数。因为ostream可能是很早之前就定义好的,我们无法提前知道他要输出的类型,不可能预先在成员函数中定义。
 这里的
这里的operator << 的返回类型也是考虑到连续输出,所以返回ostream&
总结:设计一个class要注意什么?
- 使用构造函数的初始化列表
- 对于不改变私有数据的成员函数,要加const
- 尽量使用引用传值
- 考虑好返回值的类型,为传值或传引用
- 数据要放在
private,函数大部分要放到public
复习complex类的实现过程
范例程序会比视频中的多很多,是以标准库的代码作为的示例。下面主要是梳理写代码的顺序,精简了一些代码。
- 防卫式定义
- 写class的头(名称+大括号)
- 复数类需要的数据,写入
private - 思考要使用的函数:
构造函数(参数是否有默认值,传值/引用,初始化列表);
其他函数(以实现特定功能) - 注意这里可以是成员函数或全局函数(根据需要加inline)
思考要不要给函数加const
是否要在private加入友元函数
考虑好函数的接口(参数,返回值的类型),再考虑定义
有指针成员——以string为例
如果类中带有指针,那么拷贝函数一定不能用编译器自带的版本,要自己写。
由于字符串大小不一,用指针就有一种动态的感觉,不需要提前分配一个具体的大小。第二个函数就是拷贝构造函数,它接受的是自己这种类别的东西,看起来也是构造函数的感觉。第三个是重载操作符;第四个函数是析构函数。
对于有指针成员变量的类,一定要定义拷贝构造函数,拷贝赋值函数和析构函数
析构函数
 对于
对于m_data数组内存,就要通过delete[]进行释放。图中右边的delete是为了释放指针变量p。
拷贝构造函数
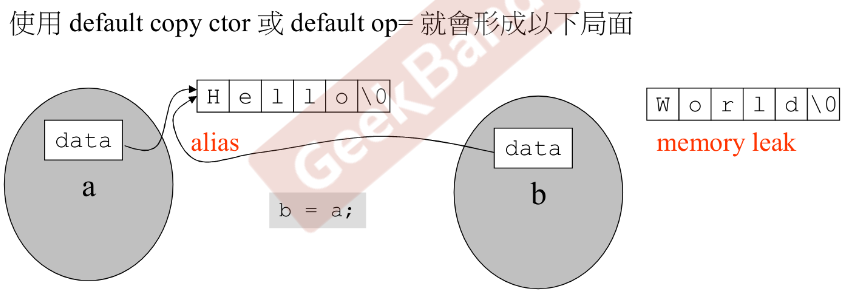
为什么要自己写拷贝构造函数?
因为默认的拷贝构造函数是浅拷贝,如下图所示,要把a拷贝给b。这就会带来两个问题,一是原来b指向的字符串此时没有任何指针指向它,成了孤儿,可能会造成内存泄露的问题;二是此时a和b都指向了同一个字符串,如果改变了a,那么b也会跟着变。
 拷贝构造函数的写法为:这里是新分配了内存,把拷贝的内容放入这里
拷贝构造函数的写法为:这里是新分配了内存,把拷贝的内容放入这里

拷贝赋值函数
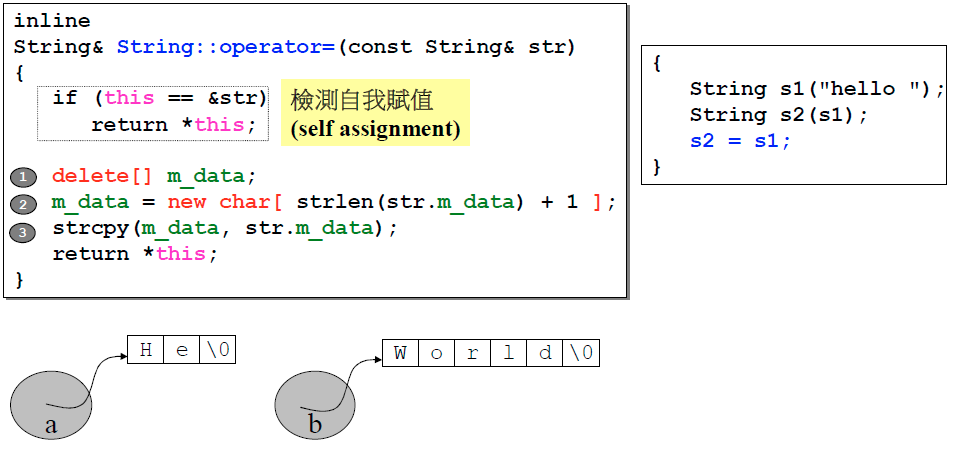
分为四步:
- 检测自我赋值(对于自己给自己赋值的情况,如果不加这一步就会出错)
- 删除原有的指针成员的内存 (主要是删除了这一步)
- 重新给指针成员分配内存,和要赋值的内容一样
- 赋值
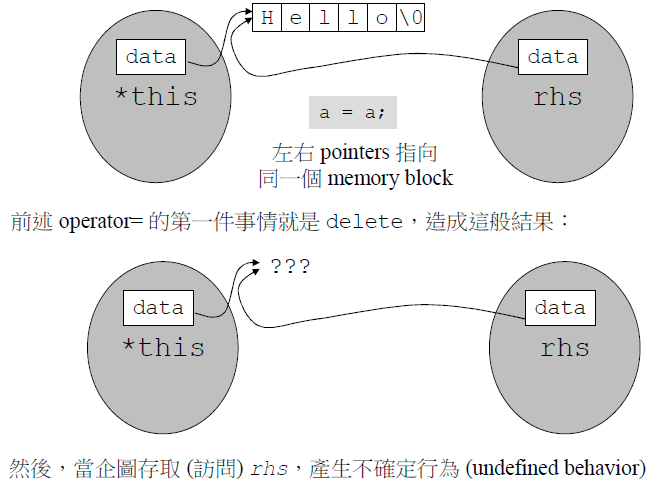
下图就是对于第一步的解释:如果发生了自我赋值但却没有检测,那么进行第二步的时候,指针成员的内存就都没有了,重新分配内存时大小就是0.
堆heap,栈stack与内存管理
栈:是存在于某作用域(scope)的一块内存空间.例如当你调用函数,函数本身就会形成一个stack用来放置它所接收的参数以及返回地址。在函数本体内声明的任何变量,其所使用的内存块都取自上述stack.
堆:是指由操作系统提供的一块global内存空间,程序可动态分配从其中获得若干区块。
class Complex{...};
...
{
//c1所占的空间来自栈
Complex c1(1,2);
//Complex(3)是临时对象,其占用的空间是以new自堆动态分配而得,并由p指向
Complex* p = new Complex(3);
}
| 不同对象的生命期 | |
|---|---|
| stack objects | heap objects |
 c1就是stack object, 生命在作用域结束之后结束,这种作用域内的object又称为auto object,因为能被自动清除 c1就是stack object, 生命在作用域结束之后结束,这种作用域内的object又称为auto object,因为能被自动清除 |  p指向heap object, 生命在它被delete之后结束。如退出作用域时,没有delete,那p指针指向的区域仍存在,导致内存泄漏 p指向heap object, 生命在它被delete之后结束。如退出作用域时,没有delete,那p指针指向的区域仍存在,导致内存泄漏 |
| static local objects | global objects |
 c2就是static object, 生命在作用域(大括号范围)结束之后仍然存在,直到整个程序结束 c2就是static object, 生命在作用域(大括号范围)结束之后仍然存在,直到整个程序结束 |  c3为global object, 生命在整个程序结束后才结束,也可以视为一种static object,作用域是整个程序 c3为global object, 生命在整个程序结束后才结束,也可以视为一种static object,作用域是整个程序 |
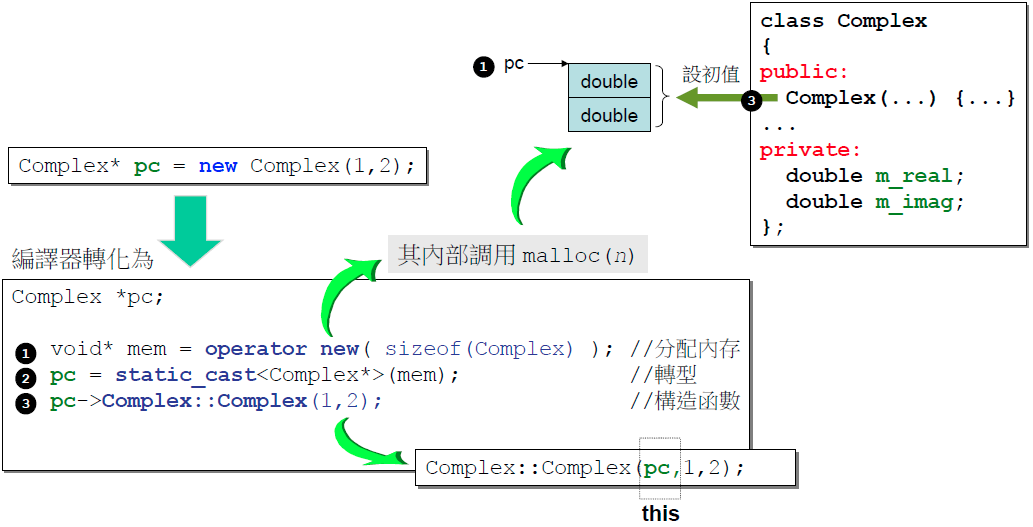
使用new和delete时的内存分配过程
new先分配内存再调用构造函数 | delete先调用析构函数再释放内存 |
|---|---|
 |  |