通俗聊聊损失函数中的均方误差以及平方误差
机器学习中的所有算法都依赖于最小化或最大化某一个函数,我们称之为“目标函数”。最小化的这组函数被称为“损失函数”。损失函数是衡量预测模型预测期望结果表现的指标。寻找函数最小值的最常用方法是“梯度下降”。把损失函数想象成起伏的山脉,梯度下降就像从山顶滑下,目的是到达山脉的最低点。
损失函数可以大致分为两类:分类损失(Classification Loss)和回归损失(Regression Loss)。下面这篇博文,就将重点介绍5种回归损失。
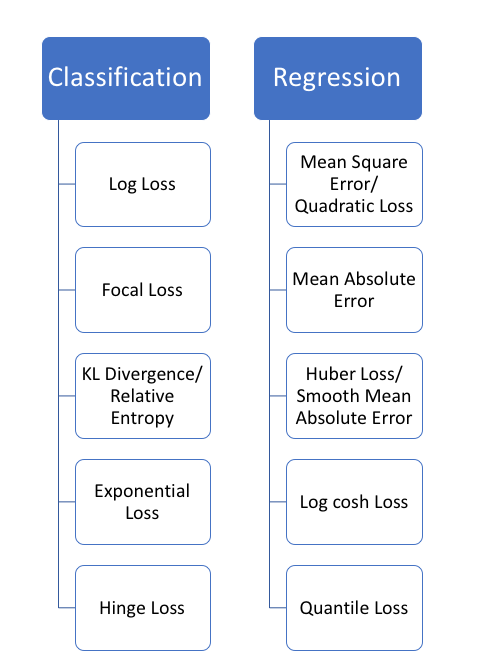
回归函数预测实数值,分类函数预测标签
1 均方误差
均方误差又称为二次损失,L2损失(Mean Square Error, Quadratic Loss, L2 Loss)
均方误差(MSE)是最常用的回归损失函数。MSE是目标变量与预测值之间距离平方之和。
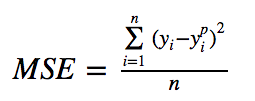
下面是一个MSE函数的图,其中真实目标值为100,预测值在-10,000至10,000之间。预测值(X轴)= 100时,MSE损失(Y轴)达到其最小值。损失范围为0至∞。