1 明确目标
进行性能分析时,需要明确优化的目标,例如,是优化整体的性能,还是某个功能的性能。
明确优化目标后就需要能够知道当前的性能瓶颈,性能消耗在什么地方,以及如何去衡量,这样也能够在优化过程中以及优化完成后用相同的方式去衡量效果。
2 基础命令
2.1 基本指标查看
CPU
- mpstat -P ALL 1:查看CPU的各种状态下的时间,可以用于查找CPU时间分布不均衡的问题
- pidstat 1:展示进程的CPU使用情况
- top:查看当前的负载以及占用CPU和内存较高的进程
内存
- free -m
- vmstat 1:查看内存、swap、cpu等使用情况
磁盘:
- df -h:查看磁盘使用情况
- iostat -xz 1:查看磁盘的读写情况
错误
- dmesg |tail:查看内核的相关日志
- grep ERROR /var/log/messages:查看系统和服务的错误信息
其他:
- sar:用于输出系统行为的信息,例如,sar -w 1可以用于查看创建进程的速度
2.2 线程
上面的命令默认情况下都是查看进程的情况,现在很多程序都是多线程,因此,需要能够查看线程的情况。
- top -H -p 6666:查看6666进程下面所有线程的cpu和内存情况
- pidstat -p:后面既可以指定进程ID,也可以指定线程ID
因此,通常的方式是,通过top查看到占用较高的某个线程,然后通过pidstat持续观察该线程的cpu占用情况,如果持续飙高,再通过日志或者代码定位该线程对应的逻辑模块。
3 perf命令
3.1 perf的基本原理
每隔固定时间,CPU产生一个中断,看当前是哪个进程、哪个函数,就更新相应的进程和函数的计数器,通过这种定时采集的方式,就知道CPU有多少时间在某个进程或者某个函数上了。
3.2 基本使用方法
- perf list:查看可用的采样点
- perf record:采集程序运行的特征,配合perf script生成trace的数据,然后就可以用于生成火焰图
- perf top:可以查看函数级别的占用情况
- perf probe:在可执行文件或者so种插入监测点,然后再通过perf record进行数据采集
3.3 火焰图分析
生成火焰图,除了使用perf工具,还需要生成火焰图的脚本:FlameGraph
然后用下面的方式生成火焰图:
# -F 100表示采样频率,每秒100次
# -p 31955表示对31599进程进行采样
# -g表示记录调用栈
# sleep 180表示总共采样180s
perf record -F 100 -p 31955 -g -- sleep 180
perf script -i perf.data &> perf.unfold
./FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded
./FlameGraph/flamegraph.pl perf.folded > perf.svg
然后就可以用浏览器打开perf.svg进行分析。
火焰图的特点:
- 每个小方块表示一个函数
- 方块的颜色深浅没有关系,是随机取的颜色
- 纵轴表示调用栈的深度,调用的方向是从下往上,也就是下面的函数调用了上面的函数,因此,函数越往上则越底层
- 横轴的宽度表示占用时间,但是从左到右并不表示时间顺序,而只是按照字母表顺序排列
怎么用火焰图查找性能问题呢?
横轴的宽度表示占用时间,因此,方块越宽表示占用时间越多,所以,我们的目的就是找到比较宽的方块。
在最下面找比较宽的方块,当找到一个比较宽的方块时,再在这个方块的上面的方块中找比较宽的方块,这样一步一步往上找,根据代码分析出性能出现问题的地方,然后对这部分代码进行优化。
4 ftrace
内核文档:ftrace - Function Tracer
ftrace提供tracefs的接口供用户使用,4.1内核以前的版本,tracing所有的控制文件都在debugfs中,tracefs通常会挂载到/sys/kernel/debug/tracing,为了向后兼容,新的内核在挂载debugfs时,会同时将tracefs挂载到/sys/kernel/debug/tracing和/sys/kernel/tracing。
- current_tracer:当前使用的tracer
- available_tracers:可用的tracer类型
- tracing_on:打开(1)和关闭(0)tracer
- trace & trace_pipe:两个文件都可以查看tracer采集的数据,但是trace是个静态的文件,每次读取该文件展示的都是当前缓冲区中的数据,而trace_pipe是个动态的文件,每次读取只能读取到新的数据,已经读取的数据不会被输出
- trace_options:控制数据采集的选项,例如,数据的展示和tracer的工作方式
- options/:可用的选项,可以通过修改下面的文件控制,也可以将文件名写入trace_options控制
- kprobe_events:开启kprobe_events
- uprobe_events:uprobe tracers
- uprobe_profile:
- events/:所有的监测点,按照分组进行组织
- available_events:可用的events,将上面events目录中的所有文件都列在这里
- trace_marker:
4.1 Tracers
- function:可以用于监测所有的内核函数
- function_graph:function类型的tracer只是在函数的入口添加监测点,而function_graph类型的tracer会在函数的入口和出口添加监测点,可以用于绘制函数调用关系图
- blk:块设备的检测点,被blktrace命令使用
- hwlat:用于检测硬件是否有延迟
4.2 perf-tools
从上面可以看到,ftrace基本就是通过tracefs提供操作的接口,但是里面的目录和文件又很多,而某个功能其实一般也只用到了几个文件而已,为了方便对某个功能的使用,perf-tools用shell脚本的方式对这些功能进行了封装,可以通过命令的方式使用。
用例1:uprobe
uprobe脚本可以对用户态的程序添加监测点:./uprobe 'p:/lib64/libdl-2.28.so:dlopen +0(%di):string'对libdl-2.28.so里面的dlopen添加监测点,当系统中有程序使用dlopen调用so时,就会打印一个事件,表明某个程序调用了dlopen,并且调用的so的路径。
用例2:kprobe
kprobe脚本可以对内核的函数添加监测点,可以添加监测点的函数列表位于/sys/kernel/debug/tracing/available_filter_functions中。使用./kprobe 'p:do_sys_open filename=+0(%si):string'可以监测open系统调用,并且打印出文件名。
用例3:tracepoint
tpoint脚本可以列出内核现在的tracepoint,然后进行监测。使用./tpoint syscalls:sys_enter_openat可以打印有哪些进程在调用打开文件。
4.3 日常使用
使用日志进行性能分析时,除了使用火焰图从整体上看时间的分布,经常会有需要看某个函数占用的耗时。
perf-tools中的funcgraph脚本可以监测到函数从进入到出来的耗时,但是该功能只能对内核函数使用,无法对用户态使用。
5 再看perf probe
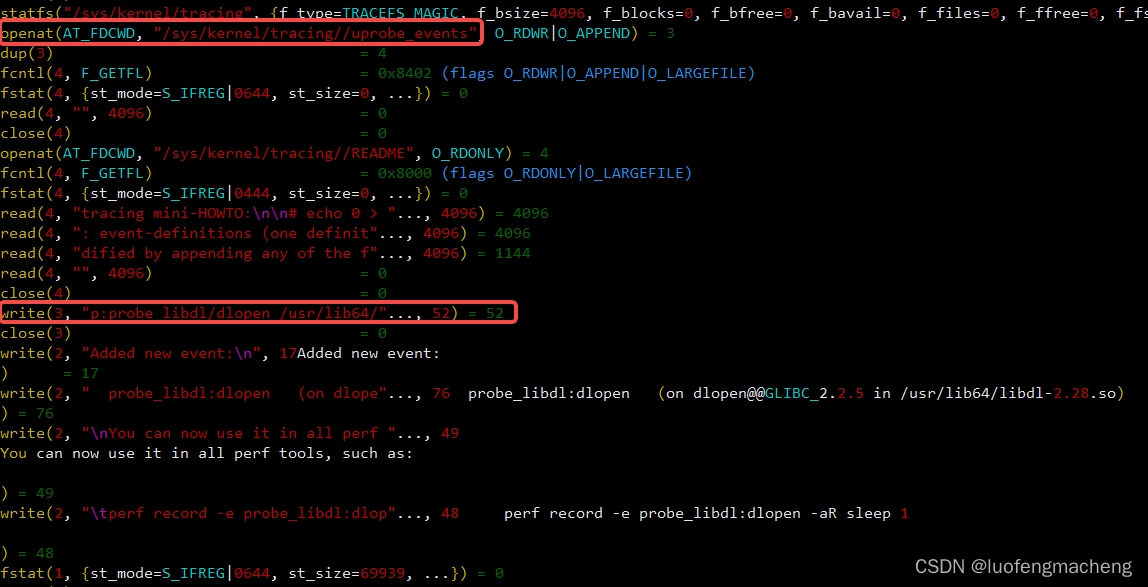
perf probe可以操作监测点,执行perf probe -x /lib64/libdl-2.28.so 'dlopen\@\@GLIBC_2.2.5'可以增加监测点probe_libdl:dlopen,然后通过perf record -e probe_libdl:dlopen -a -- sleep 5可以采集dlopen的调用。
然后执行perf script可以直接查看采集到的数据:

通过对perf probe进行strace发现,它也是通过操作ftrace中的tracefs实现的。
perf也对ftrace进行了简单的封装,提供了perf ftrace命令,可以通过perf ftrace进行内核函数监测,使用命令perf ftrace -p 53901 -t function -T do_sys_open监测某个进程对open系统调用的情况。
6 perf_event_open
使用perf probe只是增加监测点,但是要获取实际的数据,就需要通过perf record命令,而perf record就是使用perf_event_open进行数据的获取。
下面是perf_event_open中的示例程序,用于统计printf的指令的数量:
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <string.h>
#include <sys/ioctl.h>
#include <linux/perf_event.h>
#include <asm/unistd.h>
// hw_event:perf_event_attr的指针
// pid:要进行trace的进程
// cpu:要进行trace的cpu
static long perf_event_open(struct perf_event_attr *hw_event, pid_t pid,
int cpu, int group_fd, unsigned long flags) {
int ret;
ret = syscall(__NR_perf_event_open, hw_event, pid, cpu, group_fd, flags);
return ret;
}
int main(int argc, char **argv) {
struct perf_event_attr pe;
long long count;
int fd;
memset(&pe, 0, sizeof(struct perf_event_attr));
pe.type = PERF_TYPE_HARDWARE; // 指定事件类型
pe.size = sizeof(struct perf_event_attr);
pe.config = PERF_COUNT_HW_INSTRUCTIONS; // 失效指令?
pe.disabled = 1; // 默认关闭,后续可以通过ioctl或者prctl进行开启
pe.exclude_kernel = 1; // 忽略内核空间的事件
pe.exclude_hv = 1; // 忽略hypervisor的事件
// pid=0,表示对当前进程进行trace
// cpu=-1,表示对所有cpu进行trace
fd = perf_event_open(&pe, 0, -1, -1, 0);
if (fd == -1) {
fprintf(stderr, "Error opening leader %llx\n", pe.config);
exit(EXIT_FAILURE);
}
// 通过ioctl控制perf_event的运行
// PERF_EVENT_IOC_RESET:重置事件的统计值
// PERF_EVENT_IOC_ENABLE:启用事件
ioctl(fd, PERF_EVENT_IOC_RESET, 0);
ioctl(fd, PERF_EVENT_IOC_ENABLE, 0);
// 执行printf,这次统计的就是该printf的指令数量
printf("Measuring instruction count for this printf\n");
// PERF_EVENT_IOC_DISABLE:停用事件
ioctl(fd, PERF_EVENT_IOC_DISABLE, 0);
// 读取统计值
read(fd, &count, sizeof(long long));
printf("Used %lld instructions\n", count);
close(fd);
}
通过上面的示例可以看出,整个逻辑不复杂,就是通过perf_event_open打开一个fd,并且需要告知需要获取的是什么数据,然后通过ioctl开启内核统计,再执行用例并关闭统计,最后调用read读取需要的数据。
因此,这里重要的是:我们需要获取什么数据,然后对应到perf_event_attr中的type和config。
上面的代码只是对某个事件进行了统计,得到某个事件发生了多少次,这种对应了perf-tools和bcc-tools中的*count工具。但是,有时候我们除了想知道事件发生了多少次,还需要对事件的某个属性进行分类的统计,或者分析函数的调用栈,总之,希望可以得到更多详细的数据。
这被称为“采样”:设定相应的频率/定时时间,当定时时间到,就会收集一些数据,然后进行相应的分析。
在perf_event_attr中有几个跟采样相关的字段:
- sample_period、sample_freq:采样周期是指多少个事件溢出一次,当溢出时,采集的数据就会放到mmap的buffer中;采样频率则通过时钟中断进行定时采样
- sample_type:指定要采样的数据,PERF_SAMPLE_TIME(记录时间)、PERF_SAMPLE_READ(记录所有事件的计数)、PERF_SAMPLE_CPU(记录CPU编号)、PERF_SAMPLE_REGS_USER(记录用户态的寄存器的状态)、PERF_SAMPLE_STACK_USER(记录用户态的栈)
- sample_regs_user:设置要采样的寄存器
- sample_stack_user:设置要采样的栈大小
用C程序计算C代码执行了多少条机器指令
7 bcc & bpftrace
由于eBPF程序的编写门槛太高,于是就出现了一些高级语言,能够帮助快速编写eBPF程序:
- bcc:一套工具集,用户可以直接用高级语言(python、C++、lua)编写用户态程序
- bpftrace:用户可以使用类似awk的方式编写eBPF程序
总之,上述两种方式都是基于eBPF的跟踪工具,bcc可以用于编写复杂逻辑,而bpftrace可以用于快速编写单行程序。
下面的bcc程序用于统计块IO的分布直方图:
#!/usr/bin/env python
from bcc import BPF
from time import sleep
# 定义加载到eBPF虚拟机的内核代码
bpf_text = """
#include <uapi/linux/ptrace.h>
#include <linux/blkdev.h>
struct proc_key_t {
char name[TASK_COMM_LEN];
u64 slot;
};
// 定义一个histogram类型的BPF map对象,它的名字为dist
// key的类型为proc_key_t,里面包含进程的名称和计算范围
BPF_HISTOGRAM(dist, struct proc_key_t);
// 定义tracepoint的跟踪点
// block:跟踪块这个类别
// block_rq_issue:要跟踪的函数,这个函数的含义是发起IO请求
// block/block_rq_issue位于/sys/kernel/tracing/events子目录中
// 也可以通过perf list|grep block_rq_issue得到
TRACEPOINT_PROBE(block, block_rq_issue)
{
// 从bytes参数中得到要读取的数据,然后求log
struct proc_key_t key = {.slot = bpf_log2l(args->bytes / 1024)};
// 从内核空间中读取进程名,然后保存到key中
bpf_probe_read_kernel(&key.name, sizeof(key.name), args->comm);
// 将刚才计算的值追加到直方图中
dist.increment(key);
return 0;
}
"""
# 将上述的内核代码载入,相当于执行bpf_prog_load
b = BPF(text=bpf_text)
print("Tracing block I/O... Hit Ctrl-C to end.")
# trace until Ctrl-C
dist = b.get_table("dist")
try:
sleep(99999999)
except KeyboardInterrupt:
# 打印直方图
dist.print_log2_hist("Kbytes", "Process Name", section_print_fn=bytes.decode)
从上面的例子中,我们知道,要想编写bcc程序,最关键是要知道要跟踪的点以及对获取的数据如何处理。例如,这里的内核代码是跟踪block_rq_issue这个tracepoint,然后根据参数得到对应的数据,再将数据计算后更新map,而在用户代码中只有map的获取和打印逻辑。
下面的代码实现了跟上述代码一样的目的:获取块IO的调用直方图
#!/usr/bin/bpftrace
BEGIN
{
printf("Tracing block device I/O... Hit Ctrl-C to end.\n");
}
tracepoint:block:block_rq_issue
{
@[args->comm] = hist(args->bytes);
}
END
{
printf("\nI/O size (bytes) histograms by process name:");
}
- BEGIN表示加载完eBPF程序后执行的动作,通常用于打印表头或者提示信息。
- tracepoint:block:block_rq_issue表示跟踪block:block_rq_issue的tracepoint
- 当跟踪某个函数时,一个关键的点是,该函数有哪些参数,例如,这里使用的是args->bytes,那么,block_rq_issue是否有其他参数呢?通过bpftrace -vl tracepoint:block:block_rq_issue可以查看该跟踪点的所有参数
- hist()是一个map函数,输出行以2次方的间隔开始
- END在跟踪结束后执行
8 关系
上面提到了很多名词,例如,uprobe、kprobe、perf、perf_event_open等,下面对这些词汇的关系进行整理:
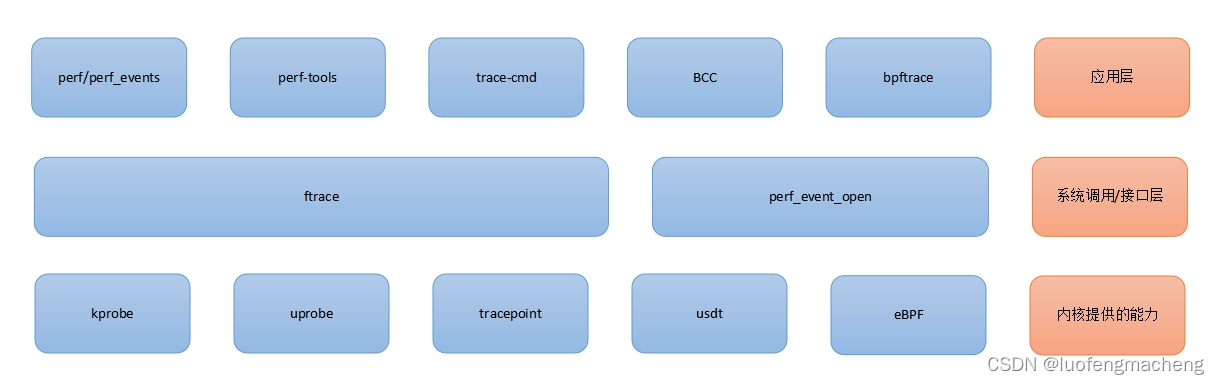
内核提供的能力:
- kprobe:动态探针,用于跟踪内核函数
- uprobe:动态探针,用于跟踪用户态函数
- tracepoint:静态探针,内核已经预先定义了一些跟踪点,可以通过
perf list tracepoint查看 - usdt:
- eBPF:扩展的BPF机制
接口层:
- ftrace:一套trace系统,对用户提供debugfs的接口
- perf_event_open:系统调用,用于读取内核的统计和采样数据
应用层:
- perf/perf_events:用于性能分析,FlameGraph
- trace-cmd:trace-cmd: A front-end for Ftrace
- perf-tools:基于ftrace的分析工具
- BCC:基于eBPF的用于开发内核跟踪程序的工具集,能够简化eBPF程序的编写,用户态的语言可以使用python、C++、lua
- bcc-tools:使用bcc编写的工具
- bpftrace:基于bcc进行更高层的抽象,能够使用类似于awk的语言快速编写eBPF工具,特别是单行程序
参考文档
- 译|2008|User-Space Probes (Uprobes)
- The bpftrace One-Liner Tutorial
- bpftrace Reference Guide