在北京时间9月19日23:35分,Intel在美国加州圣何塞举办了2023英特尔on技术创新大会。在会议上,Intel相关负责人进行发言,并阐释了本次会议的三大重点内容,分别为Intel Meteor Lake架构概览,Intel 4制程工艺与Intel Meteor Lake AI解读。

Intel未来的技术方向
根据IDM2.0战略,Intel计划在四年内实现五个制程节点的目标,2024年在制程节点上打平对手,2025年实现赶超。即遵循摩尔定律提升制造工艺,目标4年5个节点。目前Intel已经实现Intel 7制程工艺的大规模,大批量的生产。而Intel 4制程工艺也已经在提高产量了,在2023年下半年,Intel就会实现Intel 3制程工艺的投产,在2024上半年Intel会进行Intel 20A制程工艺 的投产,在2024下半年Intel会进行Intel 18A制程工艺的投产。

Intel 4制程工艺
目前,intel 4制造工艺相比与Intel 7制程工艺晶体管密度提高了2倍以上,并通过极紫外光刻EUV技术制造18层金属层堆栈来给高性能计算应用进行优化。


Intel 4制程工艺还针对RC进行了优化,通过在最下面的金属互连层使用eCu以达成更低电阻率以及电子迁移寿命的延长。
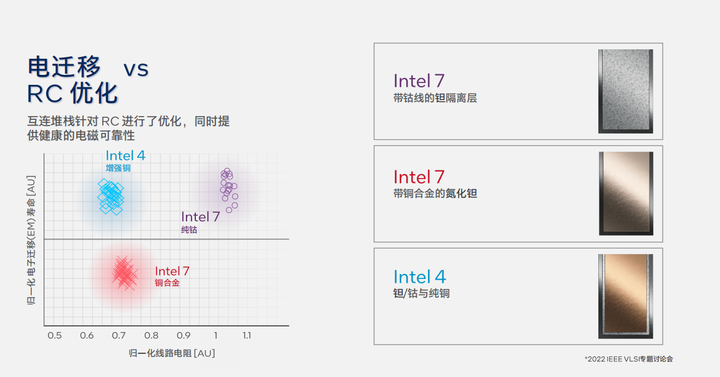
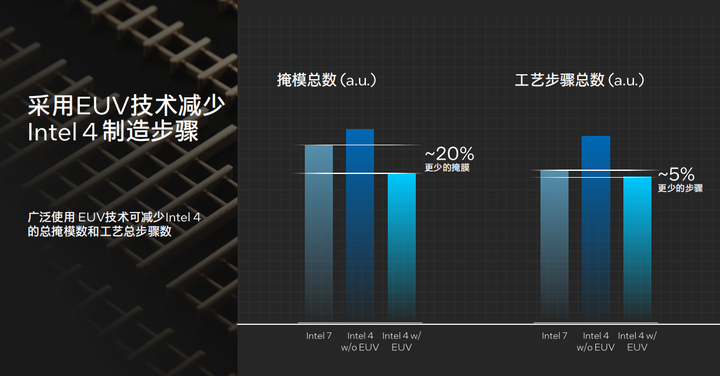
在采用EUV技术后可以大大减少Intel 4制程工艺制造步骤,这一举措减少了20%的掩膜以及5%的步骤。而EUV技术也带来了更标准化的网格化的互联架构,有助于工艺可预测性设计优化。

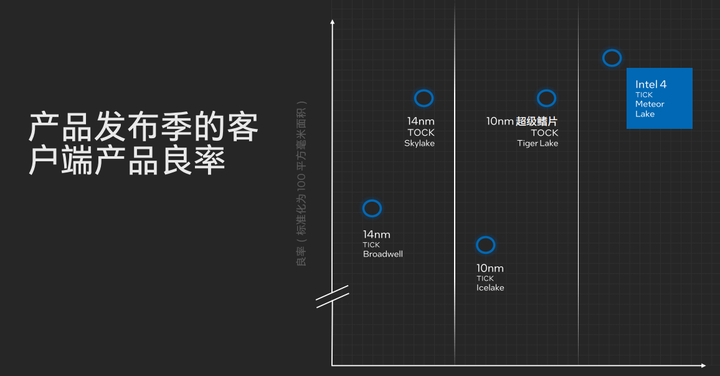
在采用了Intel 4制程工艺和EUV技术后,Intel的生产良率也变得更高,相比较曾经intel在14nm工艺和10nm工艺时代的良率,第一代的intel 4制程工艺就已经达到14nm工艺和10nm工艺成熟期的水准了。得益于Intel 4制程工艺的进步,这对未来Intel 20A制程工艺和Intel 18A制程工艺都会有更大的帮助。
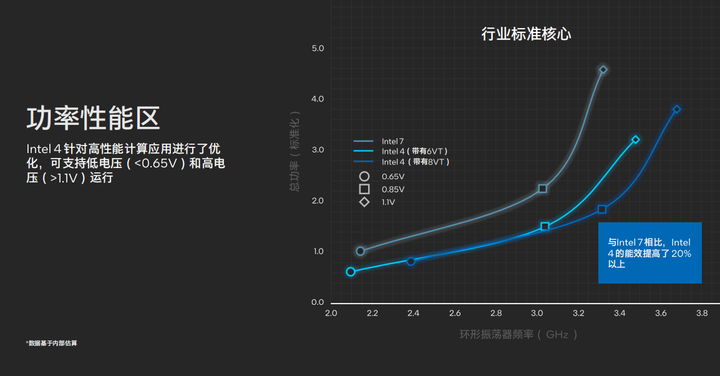
在Intel 4制程工艺的工艺福利之下,能效比这方面也有了极大的提升,Intel 4制程工艺(6VT)和Intel 4制程工艺(8VT)在在3.0Ghz的频率下的功耗比Intel 7制程工艺减少了50%,而且可以支持在0.65V以下的低电压和1.1V的高电压中工作。
封装技术
摩尔在《电子学》中写道:在构建大系统时,将其分解为单独封装并互联的较小功能可能更经济。Intel最早的封装技术是从Die上面的节点向外引金属线发展到把Die的凸点和金属直连,提供更高的密度,并采用多芯片封装,把CPU和PCH装在一个芯片中。未来Intel会把2.5D封装和3D混合封装在一起,这代表Intel最新的封装技术,可以更好的实现更高密度Die与Die的封装。
3D封装技术是一种先进的封装技术,它可以将多个芯片在垂直方向上叠层封装在一个封装体内,实现高密度、高性能、低功耗、低延迟的芯片集成。3D封装技术的核心是通过TSV来实现芯片之间的垂直互连,TSV是一种在芯片或晶圆上制作的微小的垂直导通孔,可以把上下层的芯片电路相互连接。3D封装技术可以提高芯片的集成度和功能性,实现更多的功能模块和存储容量;可以缩短芯片之间的信号传输距离,降低信号延迟和功耗,提高系统速度和效率;可以减小封装体积和重量,节省空间和成本,适应小型化和便携化的需求;可以兼容不同的芯片工艺和材料,实现异构集成,提高系统灵活性和可靠性。
在2020年,Lakefield处理器采用了Intel Foveros技术,实现了Ice Lake加上4核Atom的“1+4”混合架构,在Lakefield上,Intel将内存和处理器封装在一起,这就是现在的3D封装技术。

Foveros封装技术有着更好的叠加行以及更高的密度,实现了Die与Die的连接,采用主动式3D堆叠,实现了50微米兼具晶片间互联,并做到了12×12mm的封装尺寸。
Intel最早通过Lakefield处理器实现3D封装技术,但实际大规模量产是在Meteor Lake上,3D封装技术为Meteor Lake这样的模块化技术提供了最原始的技术支持。
Meteor Lake封装制造流程
Meteor Lake由四个功能模块构成,从Intel和第三方代工厂拿到这些模块,再把它们通过Die与Die的模式封装到中间基础的模块晶圆上,基础模块在封装过程中是不进行切割的,这就对每个模块的优良性有要求了,所以要对每个模块进行测试保证非常好的良品率最后实现3D封装。

前代架构简介
在先前的12代酷睿桌面端Alder Lake架构中,Intel首度引入了高性能混合架构即每颗处理器内包含两种核心:性能核(Peformance-core)和能效核(Efficient-core),性能核采用Golden Cove微架构,能效核采用Gracemont微架构。并且引入硬件线程调度器可以根据实时的计算需求将需要更高性能的线程引导到合适的性能核中,并配合操作系统做出更好的调度。并且采用intel 7制程工艺(10nm Enhanced SuperFin),晶体管密度高达100亿个/平方毫米,在后续的13代酷睿桌面端Raptor Lake架构中,Intel通过Intel 7制程工艺的大幅提升,将13代酷睿处理器的频率推到新的高度,并同时增加处理器的缓存,添加更多新的超频功能特性,甚至在液氦超频的帮助下,将I9 13900K推进到9Ghz的大关。成为第一个踏入9Ghz大关的处理器。

在Alder Lake和Raptor Lake两代架构中,Intel都实现了单核与多核性能的大幅提升。为了实现更强的能耗比来增强笔记本的续航能力,新架构Meteor Lake应运而生。
Meteor Lake架构简介

Meteor Lake架构旨在提升处理器的能耗比,将性能与功耗达成完美的平衡,并且首次将人工智能加速引擎NPU集成到CPU处理器上,这样Intel便可以引领人工智能在PC端的普及。而且,Meteor Lake的集成显卡也有着极大的功能提升,这代GPU成了Intel锐炫图形架构,可以达到独立显卡级的性能,并能达到前代两倍的图形性能。由于Meteor Lake架构采用了Intel 4制程工艺以及升级了性能核和能效核的架构(性能核架构为Redwood Cove微架构,能效核为Crestmont微架构)更是带来了飞跃般的性能提升。
Meteor Lake架构介绍
Meteor Laker的下一代分离式模块架构由四个模块构成,分别为计算模块,SOC模块,GPU模块和IO模块,并通过Intel Foveros 3D封装技术连接。这四个模块通过每个模块上面的电源管理模块相互协同工作。

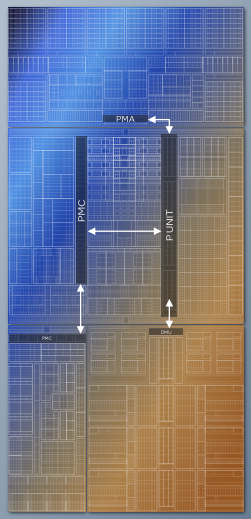
计算模块

在计算模块上Meteor Lake仍旧采用了高性能混合架构,如图所示,在上方左右各排布有4个能效核,总计8个能效核,在下方各排布有3个性能核,总计6个性能核,合在一起为6打和8小核,中间是环形Ring总线。这个规格看起来就是下代Intel酷睿 ULTRA 5了。
SOC模块

在全新的SOC模块中,Meteor Lake通过DLVRs,动态总线频率调整,SOC算法,增强调度等方式添加了一个全新的低功耗岛能效核,它适用于轻型工作负载并通过计算模块按需开启,集成了低功耗人工智能引擎,起到辅助计算的功能。
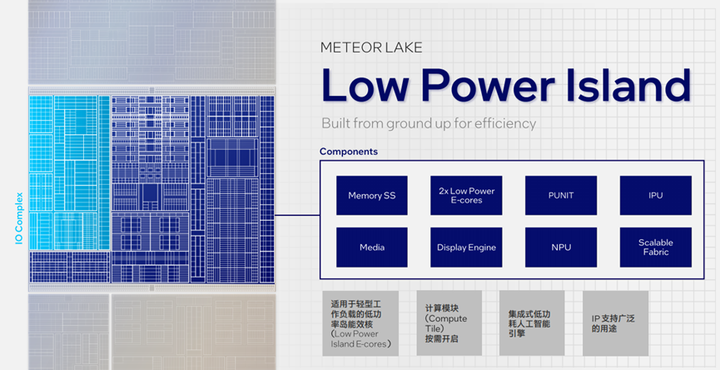

由于Meteor Lake采用了性能核(P core),能效核(E core),低功耗岛能效核(LP E core)的3D高性能混合架构设计,在系统调度方面有着全新的体验。
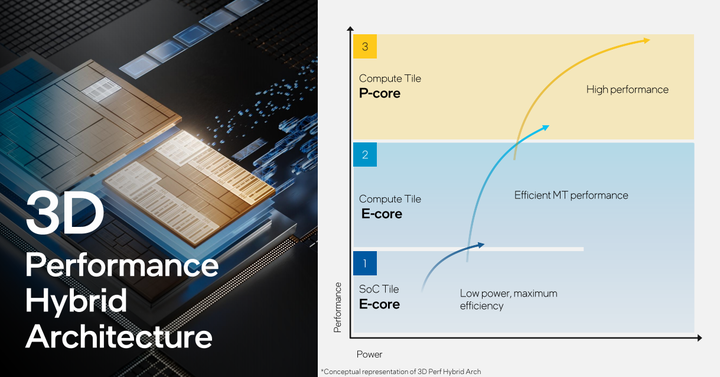
在较低的负载情况下,系统会优先将任务交给LP E core来执行,这样可以做到以较低的功耗运行整个系统,当任务负载较大的情况下,系统才会将任务交给E core与P core来完成,这样可以实现最佳的能耗比。
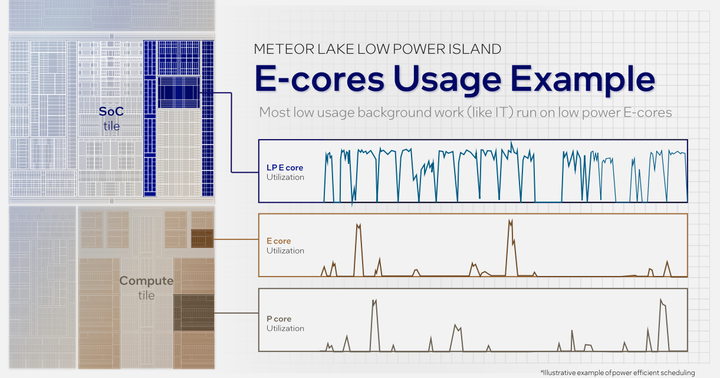
为了更好的调配不同的任务如何在不同的核心中进行切换,Intel使用硬件线程调度器来给系统调配作为参考。

Intel通过给P core,E core,LP E core的IPC能效表现打分来对它们执行指令的能力进行分类。Class 0代表P core、E core在每个时钟内执行这种指令时数量基本一致,就划归为Class 0。.Class 1代表P core在每个时钟周期内执行这种指令时的指令数量大于E core,就划归为Class 1。Class 2代表P core在每个时钟周期内执行这种指令时的指令数量远远大于E core,就划归为Class 2。Class 3代表E core在每个时钟周期内执行一些特定指令时的指令数量大于P core,就划归为Class 3。
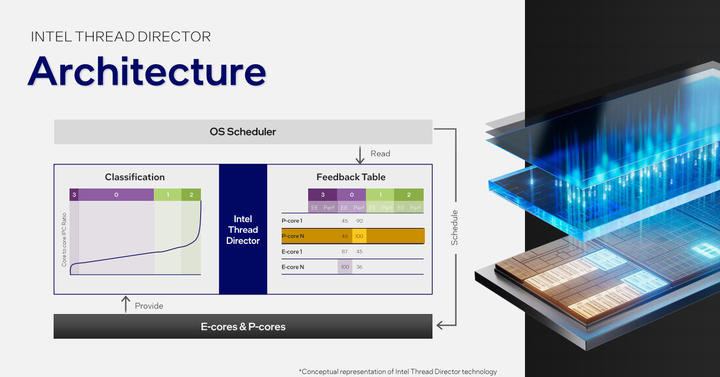
在Meteor Lake上,Intel创新性的把硬件线程调度器增强了对系统的反馈,在其他IP占用功耗时,核心的功耗会被动态分配,通过系统的调度,把核心控制做到更优。所以才可以更好的使用3D高性能混合架构【性能核(P core)+能效核(E core)+低功耗岛能效核(LP E core)】。

Meteor Lake还集成了神经网络处理单元(NPU AI 加速引擎),NPU AI加速引擎是一种专门用于加速机器学习任务的芯片,比如图像分类、机器翻译、物体检测等。NPU可以提高神经网络的运算效率,降低功耗和成本,适用于边缘计算和云计算等场景,并支持多种深度学习框架和算法,如TensorFlow、PyTorch等。如今NPU AI加速引擎多用于云服务器,比如实现语言处理、数据分析、AI训练等功能,加快服务器运算速度和节省服务器资源。在智能手机方面可以实现AI场景识别游戏优化等功能。在车载智能芯片实现车辆的自动驾驶、路况分析等功能。

在这代Meteor Lake的SOC在支持WIFI6E的基础上中首度支持了全新的WIFI7,WIFI7支持2.4Ghz、5Ghz、6Ghz等频段,并将频宽从160MHz升级到320MHz,大大提升数据传输速率,而信号调制方式也从1024-QAM提升到4096-QAM,可在每个符号中携带12比特数据,WIFI7也将OFDMA技术优化,引入了Multi-RU(Multi-Resource Unit)功能。Multi-RU可以为每个用户分配多个RU(Resource Unit),从而提高频谱的利用率和用户的吞吐量。WIFI7也将MU-MIMO技术进一步增强,将支持的空间流数量从8增加到16,从而提高网络的容量和并发性。总的来说WIFI7带有高速低延迟高可靠的特性,适用于现今较火的VR,在线游戏,智能家居等各种场景。
Meteor Lake的SOC还支持8K HDR和AV1格式编码,现如今,越来越多的流媒体都优先使用AV1格式编码(因为AV1格式编码的视频由于其视频质量高和视频文件小的原因可以节省对于流媒体网站的网络带宽要求),而如今各大流媒体平台在8K HDR的视频上普及度也非常之高。甚至可以说AV1格式编码正在逐渐取代H.264格式编码。而为了匹配8K HDR这样高的视频质量所带来的传输带宽提升,Meteor Lake的SOC支持原生的HDMI2.1和Display Port2.1标准。(HDMI2.1的带宽为48bps最大可以输出8K 60Hz 视频,DP2.1的带宽为80Gbps最大可以输出16K 60Hz视频)

Meteor Lake架构还集成了新的DDR内存规格和内存控制器。在**最新的第二代Z790系列芯片组主板Z790 AORUS TACHYON X上,支援的内存频率为12000MHz【1DP,即one dim per(channel)】而这张主板的前代Z790 AORUS TACHYON主板所支持的内存频率为8533MHz,可见这代Meteor Lake的Memory Controller(imc,内存控制器)提升有多大。所支持的内存频率提升幅度达到40%。
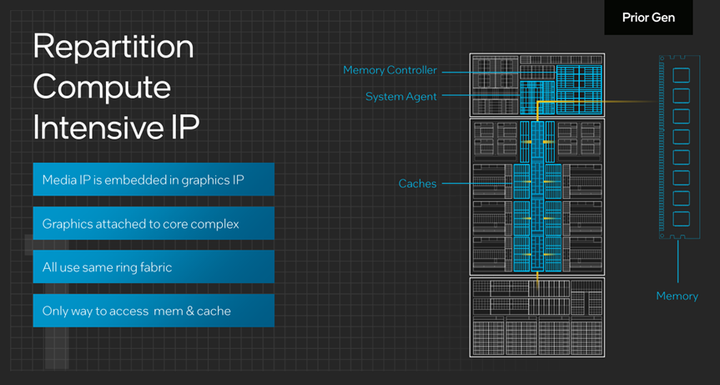

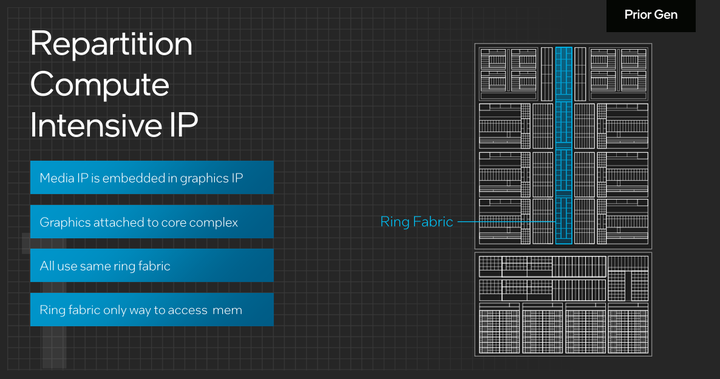
在这代Meteor Lake处理器上,仍旧沿用了Intel自从2008年就在使用Ring环形总线,环形总线的功能是连接处理器内部的性能核以及能效核、二级以及三级缓存,内存控制器、输入输出控制器这些模块。环形总线是一种处理器内互联的拓补结构,通常是双环的结构,通过顺时针和逆时针的方式来传输数据,在任意两个节点之间距离不超过节点总数的一半,所以环形总线的延迟较低。环形总线设计简单,易于拓展。而环形总线的设计非常适合Intel当前处理器的核心规模,若是达到更多的核心规模,就会采用Mesh总线了。比如Intel最新的第四代至强可拓展处理器中最高端型号Intel® Xeon® Platinum 8490H Processor (112.5M Cache, 1.90 GHz)所采用的就是Mesh总线,但Mesh总线比Ring总线更复杂一点,这里就不展开篇幅介绍了。
GPU模块
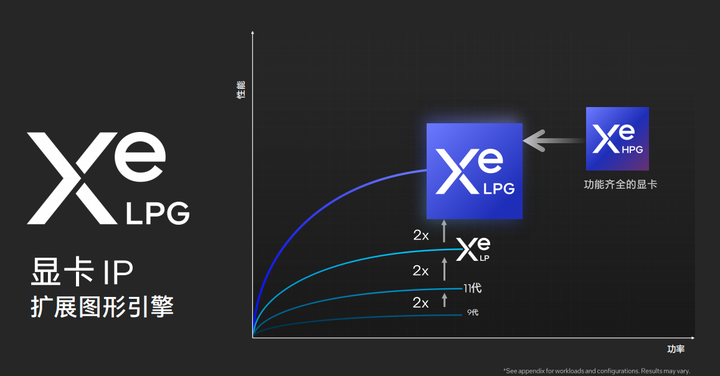
Meteor Lake架构处理器集成了Intel锐炫图形架构,作为集成显卡却可以提供独立显卡级别的性能。Meteor Lake锐炫核显对比上代有着更高的GPU频率、更大的GPU规模、以及更棒的架构设计,最终的结果就是可以提供相较于上一代两倍的图形性能。
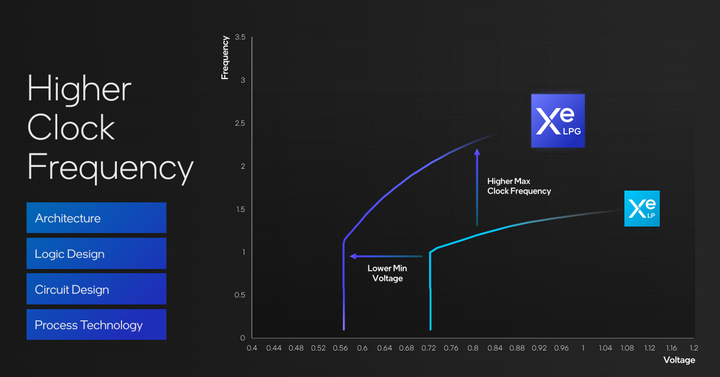
在频率与电压方面,Intel Xe LPG架构对比Intel Xe LP架构在相同频率下(1.0Ghz)电压更低,减少了28%,而在相同电压下(0.72V)则有着两倍的频率提升(2.0Ghz)。能耗比与绝对性能提升幅度巨大。
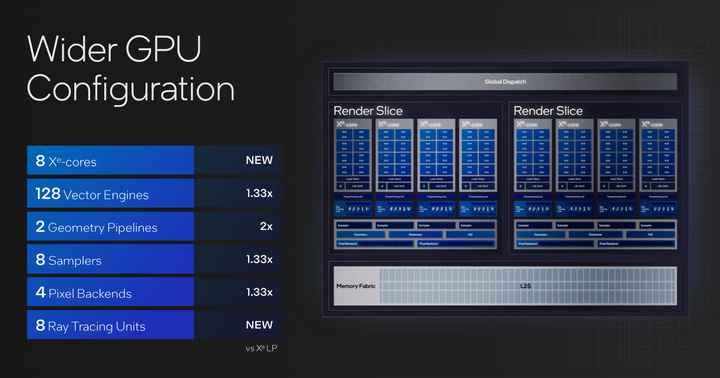
在GPU规模方面,本次Intel Xe LG架构有8个Xe LPG计算单元、128个适量引擎、2个集合管道、8个采样器、4个像素后端和8个光线追踪计算单元。
IO模块

在Meteor Lake的IO模块中,Intel集成了Thunderbolt 4(雷电四)和PCIe Gen5 Controller(PCIe5.0控制器)提供出色的连接性,雷电4是极为先进的接口标准,它的速率可达40Gb/s,它的应用范围非常广,比如用来外接4K或8K高清显示器,外接如今传输速率极快的PCIe4.0或PCIe5.0硬盘。

Meteor Lake AI体验

在Meteor Lake架构中,GPU具有性能并行性和高吞吐量,非常适合在媒体、3D应用程序和渲染管道中引入AI功能、NPU是一个专用的低功耗AI引擎用于维持AI运行和AI卸载、CPU具有快速响应能力,适合执行轻量级、单推理、低延迟的AI任务,这三者相互协作达到了高能效的AI体验。
总结
Meteor Lake毫无疑问又是Intel一大具有历史意义的架构,是40年以来最重要的SOC架构变化,全新的分离式模块化设计是一场空前的架构变革,从现在开始Intel会引领PC踏入AI时代,推动AI的规模化发展。而伴随着Intel 4制程工艺以及后续Intel 3制程工艺的发展,Intel也将为我们带来更强能耗比性能的处理器,就让我们期待全新一代Intel酷睿ULTRA处理器的发布吧。