HTTP基本要点
HTTP请求,由客户端向服务端发出,可以分为 4 部分内容:请求方法(Request Method)、请求的网址(Request URL)、请求头(Request Headers)、请求体(Request Body)。
请求方法
| 方 法 | 描述 | 描 述 |
|---|---|---|
| GET | 请求页面,并返回页面内容 | |
| HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 | |
| POST | 大多用于提交表单或上传文件,数据包含在请求体中 | |
| PUT | 从客户端向服务器传送的数据取代指定文档中的内容 | |
| DELETE | 请求服务器删除指定的页面 | |
| CONNECT | 把服务器当作跳板,让服务器代替客户端访问其他网页 | |
| OPTIONS | 允许客户端查看服务器的性能 | |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
请求头
Accept:请求报头域,用于指定客户端可接受哪些类型的信息。
Accept-Language:指定客户端可接受的语言类型。
Accept-Encoding:指定客户端可接受的内容编码。
Host:用于指定请求资源的主机 IP 和端口号,其内容为请求 URL 的原始服务器或网关的位置。从 HTTP 1.1 版本开始,请求必须包含此内容。
Cookie:也常用复数形式 Cookies,这是网站为了辨别用户进行会话跟踪而存储在用户本地的数据。它的主要功能是维持当前访问会话。例如,我们输入用户名和密码成功登录某个网站后,服务器会用会话保存登录状态信息,后面我们每次刷新或请求该站点的其他页面时,会发现都是登录状态,这就是 Cookies 的功劳。Cookies 里有信息标识了我们所对应的服务器的会话,每次浏览器在请求该站点的页面时,都会在请求头中加上 Cookies 并将其发送给服务器,服务器通过 Cookies 识别出是我们自己,并且查出当前状态是登录状态,所以返回结果就是登录之后才能看到的网页内容。
Referer:此内容用来标识这个请求是从哪个页面发过来的,服务器可以拿到这一信息并做相应的处理,如做来源统计、防盗链处理等。
User-Agent:简称 UA,它是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本、浏览器及版本等信息。在做爬虫时加上此信息,可以伪装为浏览器;如果不加,很可能会被识别出为爬虫。
Content-Type:也叫互联网媒体类型(Internet Media Type)或者 MIME 类型,在 HTTP 协议消息头中,它用来表示具体请求中的媒体类型信息。例如,text/html 代表 HTML 格式,image/gif 代表 GIF 图片,application/json 代表 JSON 类型,更多对应关系可以查看此对照表:http://tool.oschina.net/commons。
请求体
Content-Type 和 POST 提交数据方式的关系
| Content-Type | 提交数据的方式 |
|---|---|
| application/x-www-form-urlencoded | 表单数据 |
| multipart/form-data | 表单文件上传 |
| application/json | 序列化 JSON 数据 |
| text/xml | XML 数据 |
响应
响应,由服务端返回给客户端,可以分为三部分:响应状态码(Response Status Code)、响应头(Response Headers)和响应体(Response Body)。
响应状态码
常见的错误代码及错误原因
| 状态码 | 说 明 | 详 情 |
|---|---|---|
| 100 | 继续 | 请求者应当继续提出请求。服务器已收到请求的一部分,正在等待其余部分 |
| 101 | 切换协议 | 请求者已要求服务器切换协议,服务器已确认并准备切换 |
| 200 | 成功 | 服务器已成功处理了请求 |
| 201 | 已创建 | 请求成功并且服务器创建了新的资源 |
| 202 | 已接受 | 服务器已接受请求,但尚未处理 |
| 203 | 非授权信息 | 服务器已成功处理了请求,但返回的信息可能来自另一个源 |
| 204 | 无内容 | 服务器成功处理了请求,但没有返回任何内容 |
| 205 | 重置内容 | 服务器成功处理了请求,内容被重置 |
| 206 | 部分内容 | 服务器成功处理了部分请求 |
| 300 | 多种选择 | 针对请求,服务器可执行多种操作 |
| 301 | 永久移动 | 请求的网页已永久移动到新位置,即永久重定向 |
| 302 | 临时移动 | 请求的网页暂时跳转到其他页面,即暂时重定向 |
| 303 | 查看其他位置 | 如果原来的请求是 POST,重定向目标文档应该通过 GET 提取 |
| 304 | 未修改 | 此次请求返回的网页未修改,继续使用上次的资源 |
| 305 | 使用代理 | 请求者应该使用代理访问该网页 |
| 307 | 临时重定向 | 请求的资源临时从其他位置响应 |
| 400 | 错误请求 | 服务器无法解析该请求 |
| 401 | 未授权 | 请求没有进行身份验证或验证未通过 |
| 403 | 禁止访问 | 服务器拒绝此请求 |
| 404 | 未找到 | 服务器找不到请求的网页 |
| 405 | 方法禁用 | 服务器禁用了请求中指定的方法 |
| 406 | 不接受 | 无法使用请求的内容响应请求的网页 |
| 407 | 需要代理授权 | 请求者需要使用代理授权 |
| 408 | 请求超时 | 服务器请求超时 |
| 409 | 冲突 | 服务器在完成请求时发生冲突 |
| 410 | 已删除 | 请求的资源已永久删除 |
| 411 | 需要有效长度 | 服务器不接受不含有效内容长度标头字段的请求 |
| 412 | 未满足前提条件 | 服务器未满足请求者在请求中设置的其中一个前提条件 |
| 413 | 请求实体过大 | 请求实体过大,超出服务器的处理能力 |
| 414 | 请求 URI 过长 | 请求网址过长,服务器无法处理 |
| 415 | 不支持类型 | 请求格式不被请求页面支持 |
| 416 | 请求范围不符 | 页面无法提供请求的范围 |
| 417 | 未满足期望值 | 服务器未满足期望请求标头字段的要求 |
| 500 | 服务器内部错误 | 服务器遇到错误,无法完成请求 |
| 501 | 未实现 | 服务器不具备完成请求的功能 |
| 502 | 错误网关 | 服务器作为网关或代理,从上游服务器收到无效响应 |
| 503 | 服务不可用 | 服务器目前无法使用 |
| 504 | 网关超时 | 服务器作为网关或代理,但是没有及时从上游服务器收到请求 |
| 505 | HTTP 版本不支持 | 服务器不支持请求中所用的 HTTP 协议版本 |
响应头
响应头包含了服务器对请求的应答信息,如 Content-Type、Server、Set-Cookie 等。下面简要说明一些常用的头信息。
Date:标识响应产生的时间。
Last-Modified:指定资源的最后修改时间。
Content-Encoding:指定响应内容的编码。
Server:包含服务器的信息,比如名称、版本号等。
Content-Type:文档类型,指定返回的数据类型是什么,如 text/html 代表返回 HTML 文档,application/x-javascript 则代表返回 JavaScript 文件,image/jpeg 则代表返回图片。
Set-Cookie:设置 Cookies。响应头中的 Set-Cookie 告诉浏览器需要将此内容放在 Cookies 中,下次请求携带 Cookies 请求。
Expires:指定响应的过期时间,可以使代理服务器或浏览器将加载的内容更新到缓存中。如果再次访问时,就可以直接从缓存中加载,降低服务器负载,缩短加载时间。
响应体
最重要的当属响应体的内容了。响应的正文数据都在响应体中,比如请求网页时,它的响应体就是网页的 HTML 代码;请求一张图片时,它的响应体就是图片的二进制数据。
web网页基础
节点树及节点间的关系
在 HTML 中,所有标签定义的内容都是节点,它们构成了一个 HTML DOM 树。
我们先看下什么是 DOM。DOM 是 W3C(万维网联盟)的标准,其英文全称 Document Object Model,即文档对象模型。它定义了访问 HTML 和 XML 文档的标准:
W3C 文档对象模型(DOM)是中立于平台和语言的接口,它允许程序和脚本动态地访问和更新文档的内容、结构和样式。
根据 W3C 的 HTML DOM 标准,HTML 文档中的所有内容都是节点:
-
整个文档是一个文档节点
-
每个 HTML 元素是元素节点
-
HTML 元素内的文本是文本节点
-
每个 HTML 属性是属性节点
-
注释是注释节点
HTML DOM 将 HTML 文档视作树结构,这种结构被称为节点树
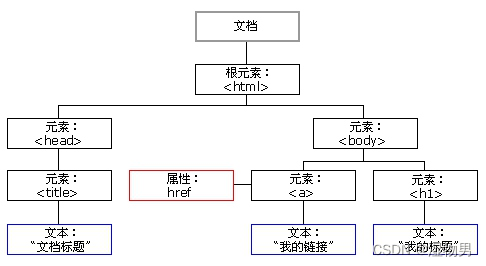
通过 HTML DOM,树中的所有节点均可通过 JavaScript 访问,所有 HTML 节点元素均可被修改,也可以被创建或删除。
节点树中的节点彼此拥有层级关系。我们常用父(parent)、子(child)和兄弟(sibling)等术语描述这些关系。父节点拥有子节点,同级的子节点被称为兄弟节点。
在节点树中,顶端节点称为根(root)。除了根节点之外,每个节点都有父节点,同时可拥有任意数量的子节点或兄弟节点。
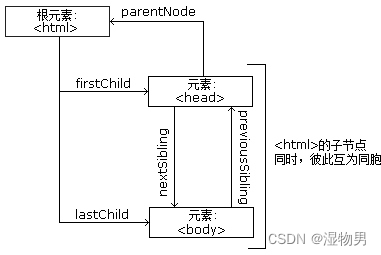
选择器
我们知道网页由一个个节点组成,CSS 选择器会根据不同的节点设置不同的样式规则,那么怎样来定位节点呢?
在 CSS 中,我们使用 CSS 选择器来定位节点。例如,上例中 div 节点的 id 为 container,那么就可以表示为 #container,其中 # 开头代表选择 id,其后紧跟 id 的名称。另外,如果我们想选择 class 为 wrapper 的节点,便可以使用.wrapper,这里以点(.)开头代表选择 class,其后紧跟 class 的名称。另外,还有一种选择方式,那就是根据标签名筛选,例如想选择二级标题,直接用 h2 即可。这是最常用的 3 种表示,分别是根据 id、class、标签名筛选,请牢记它们的写法。
另外,CSS 选择器还支持嵌套选择,各个选择器之间加上空格分隔开便可以代表嵌套关系,如 #container .wrapper p 则代表先选择 id 为 container 的节点,然后选中其内部的 class 为 wrapper 的节点,然后再进一步选中其内部的 p 节点。另外,如果不加空格,则代表并列关系,如 div#container .wrapper p.text 代表先选择 id 为 container 的 div 节点,然后选中其内部的 class 为 wrapper 的节点,再进一步选中其内部的 class 为 text 的 p 节点。这就是 CSS 选择器,其筛选功能还是非常强大的。
另外,CSS 选择器还有一些其他语法规则
| 选 择 器 | 例 子 | 例子描述 |
|---|---|---|
| .class | .intro | 选择 class=“intro” 的所有节点 |
| #id | #firstname | 选择 id=“firstname” 的所有节点 |
| * | * | 选择所有节点 |
| element | p | 选择所有 p 节点 |
| element,element | div,p | 选择所有 div 节点和所有 p 节点 |
| element element | div p | 选择 div 节点内部的所有 p 节点 |
| element>element | div>p | 选择父节点为 div 节点的所有 p 节点 |
| element+element | div+p | 选择紧接在 div 节点之后的所有 p 节点 |
| [attribute] | [target] | 选择带有 target 属性的所有节点 |
| [attribute=value] | [target=blank] | 选择 target=“blank” 的所有节点 |
| [attribute~=value] | [title~=flower] | 选择 title 属性包含单词 flower 的所有节点 |
| :link | a:link | 选择所有未被访问的链接 |
| :visited | a:visited | 选择所有已被访问的链接 |
| :active | a:active | 选择活动链接 |
| :hover | a:hover | 选择鼠标指针位于其上的链接 |
| :focus | input:focus | 选择获得焦点的 input 节点 |
| :first-letter | p:first-letter | 选择每个 p 节点的首字母 |
| :first-line | p:first-line | 选择每个 p 节点的首行 |
| :first-child | p:first-child | 选择属于父节点的第一个子节点的所有 p 节点 |
| :before | p:before | 在每个 p 节点的内容之前插入内容 |
| :after | p:after | 在每个 p 节点的内容之后插入内容 |
| :lang(language) | p:lang | 选择带有以 it 开头的 lang 属性值的所有 p 节点 |
| element1~element2 | p~ul | 选择前面有 p 节点的所有 ul 节点 |
| [attribute^=value] | a[src^=“https”] | 选择其 src 属性值以 https 开头的所有 a 节点 |
| [attribute$=value] | a[src$=“.pdf”] | 选择其 src 属性以.pdf 结尾的所有 a 节点 |
| [attribute*=value] | a[src*=“abc”] | 选择其 src 属性中包含 abc 子串的所有 a 节点 |
| :first-of-type | p:first-of-type | 选择属于其父节点的首个 p 节点的所有 p 节点 |
| :last-of-type | p:last-of-type | 选择属于其父节点的最后 p 节点的所有 p 节点 |
| :only-of-type | p:only-of-type | 选择属于其父节点唯一的 p 节点的所有 p 节点 |
| :only-child | p:only-child | 选择属于其父节点的唯一子节点的所有 p 节点 |
| :nth-child(n) | p:nth-child | 选择属于其父节点的第二个子节点的所有 p 节点 |
| :nth-last-child(n) | p:nth-last-child | 同上,从最后一个子节点开始计数 |
| :nth-of-type(n) | p:nth-of-type | 选择属于其父节点第二个 p 节点的所有 p 节点 |
| :nth-last-of-type(n) | p:nth-last-of-type | 同上,但是从最后一个子节点开始计数 |
| :last-child | p:last-child | 选择属于其父节点最后一个子节点的所有 p 节点 |
| :root | :root | 选择文档的根节点 |
| :empty | p:empty | 选择没有子节点的所有 p 节点(包括文本节点) |
| :target | #news:target | 选择当前活动的 #news 节点 |
| :enabled | input:enabled | 选择每个启用的 input 节点 |
| :disabled | input:disabled | 选择每个禁用的 input 节点 |
| :checked | input:checked | 选择每个被选中的 input 节点 |
| :not(selector) | :not | 选择非 p 节点的所有节点 |
| ::selection | ::selection | 选择被用户选取的节点部分 |
爬虫基本原理
获取网页
首先要做的是获取网页的源代码,向服务器发送一个请求,返回的就是网页源代码,可以利用python提供的urllib,requests等库帮我们实现,得到响应之后解析数据结构中的网页源代码即可。
提取信息
通常采用正则表达式提取想要的数据,也可以根据网页节点属性、CSS选择器、XPath来提取,如 Beautiful Soup、pyquery、lxml 等库
保存数据
将数据简单保存为txt或保存到数据库
JavaScript 渲染页面
有时候,我们在用 urllib 或 requests 抓取网页时,得到的源代码实际和浏览器中看到的不一样。
这是一个非常常见的问题。现在网页越来越多地采用 Ajax、前端模块化工具来构建,整个网页可能都是由 JavaScript 渲染出来的,也就是说原始的 HTML 代码就是一个空壳,例如:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>This is a Demo</title>
</head>
<body>
<div id="container">
</div>
</body>
<script src="app.js"></script>
</html>
body 节点里面只有一个 id 为 container 的节点,但是需要注意在 body 节点后引入了 app.js,它便负责整个网站的渲染。
在浏览器中打开这个页面时,首先会加载这个 HTML 内容,接着浏览器会发现其中引入了一个 app.js 文件,然后便会接着去请求这个文件,获取到该文件后,便会执行其中的 JavaScript 代码,而 JavaScript 则会改变 HTML 中的节点,向其添加内容,最后得到完整的页面。
但是在用 urllib 或 requests 等库请求当前页面时,我们得到的只是这个 HTML 代码,它不会帮助我们去继续加载这个 JavaScript 文件,这样也就看不到浏览器中的内容了。
这也解释了为什么有时我们得到的源代码和浏览器中看到的不一样。
因此,使用基本 HTTP 请求库得到的源代码可能跟浏览器中的页面源代码不太一样。对于这样的情况,我们可以分析其后台 Ajax 接口,也可使用 Selenium、Splash 这样的库来实现模拟 JavaScript 渲染。
会话与Cookies
静态网页与动态网页
静态网页的内容只采用html编写,加载速度快,编写简单,但是不能使用URL传入参数来动态地改变页面上的内容,动态网页应运而生,它可以动态解析 URL 中参数的变化,关联数据库并动态呈现不同的页面内容,非常灵活多变。
无状态HTTP
HTTP 的无状态是指 HTTP 协议对事务处理是没有记忆能力的,也就是说服务器不知道客户端是什么状态。当我们向服务器发送请求后,服务器解析此请求,然后返回对应的响应,服务器负责完成这个过程,而且这个过程是完全独立的,服务器不会记录前后状态的变化,也就是缺少状态记录。这意味着如果后续需要处理前面的信息,则必须重传,这导致需要额外传递一些前面的重复请求,才能获取后续响应,然而这种效果显然不是我们想要的。为了保持前后状态,我们肯定不能将前面的请求全部重传一次,这太浪费资源了,对于这种需要用户登录的页面来说,更是棘手。
这时两个用于保持 HTTP 连接状态的技术就出现了,它们分别是会话和 Cookies。会话在服务端,也就是网站的服务器,用来保存用户的会话信息;Cookies 在客户端,也可以理解为浏览器端,有了 Cookies,浏览器在下次访问网页时会自动附带上它发送给服务器,服务器通过识别 Cookies 并鉴定出是哪个用户,然后再判断用户是否是登录状态,然后返回对应的响应。
我们可以理解为 Cookies 里面保存了登录的凭证,有了它,只需要在下次请求携带 Cookies 发送请求而不必重新输入用户名、密码等信息重新登录了。
会话
在 Web 中,会话对象用来存储特定用户会话所需的属性及配置信息。这样,当用户在应用程序的 Web 页之间跳转时,存储在会话对象中的变量将不会丢失,而是在整个用户会话中一直存在下去。当用户请求来自应用程序的 Web 页时,如果该用户还没有会话,则 Web 服务器将自动创建一个会话对象。当会话过期或被放弃后,服务器将终止该会话。
Cookies
Cookies 指某些网站为了辨别用户身份、进行会话跟踪而存储在用户本地终端上的数据。
当客户端第一次请求服务器时,服务器会返回一个响应头中带有 Set-Cookie 字段的响应给客户端,用来标记是哪一个用户,客户端浏览器会把 Cookies 保存起来。当浏览器下一次再请求该网站时,浏览器会把此 Cookies 放到请求头一起提交给服务器,Cookies 携带了会话 ID 信息,服务器检查该 Cookies 即可找到对应的会话是什么,然后再判断会话来以此来辨认用户状态。
在后续访问页面时客户端会把 Cookies 发送给服务器,服务器再找到对应的会话加以判断。如果会话中的某些设置登录状态的变量是有效的,那就证明用户处于登录状态
属性结构
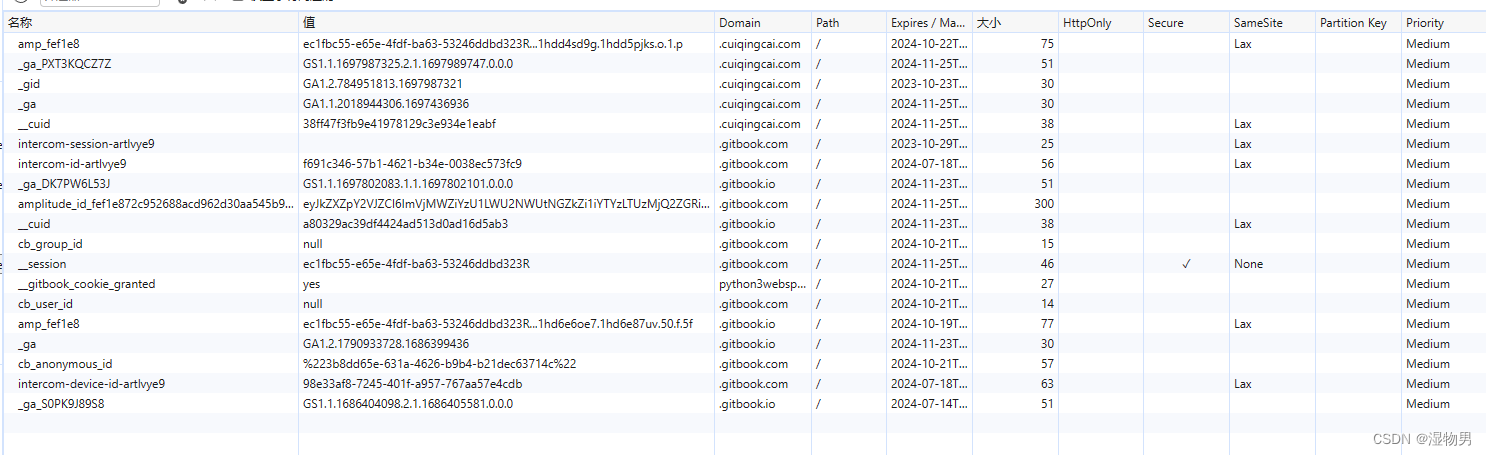
Name,即该 Cookie 的名称。Cookie 一旦创建,名称便不可更改
Value,即该 Cookie 的值。如果值为 Unicode 字符,需要为字符编码。如果值为二进制数据,则需要使用 BASE64 编码。
Max Age,即该 Cookie 失效的时间,单位秒,也常和 Expires 一起使用,通过它可以计算出其有效时间。Max Age 如果为正数,则该 Cookie 在 Max Age 秒之后失效。如果为负数,则关闭浏览器时 Cookie 即失效,浏览器也不会以任何形式保存该 Cookie。
Path,即该 Cookie 的使用路径。如果设置为 /path/,则只有路径为 /path/ 的页面可以访问该 Cookie。如果设置为 /,则本域名下的所有页面都可以访问该 Cookie。
Domain,即可以访问该 Cookie 的域名。例如如果设置为 .zhihu.com,则所有以 zhihu.com,结尾的域名都可以访问该 Cookie。
Size 字段,即此 Cookie 的大小。
Http 字段,即 Cookie 的 httponly 属性。若此属性为 true,则只有在 HTTP Headers 中会带有此 Cookie 的信息,而不能通过 document.cookie 来访问此 Cookie。
Secure,即该 Cookie 是否仅被使用安全协议传输。安全协议。安全协议有 HTTPS,SSL 等,在网络上传输数据之前先将数据加密。默认为 false。
代理基本原理
代理实际上指的就是代理服务器,英文叫作 proxy server,它的功能是代理网络用户去取得网络信息。形象地说,它是网络信息的中转站。在我们正常请求一个网站时,是发送了请求给 Web 服务器,Web 服务器把响应传回给我们。如果设置了代理服务器,实际上就是在本机和服务器之间搭建了一个桥,此时本机不是直接向 Web 服务器发起请求,而是向代理服务器发出请求,请求会发送给代理服务器,然后由代理服务器再发送给 Web 服务器,接着由代理服务器再把 Web 服务器返回的响应转发给本机。这样我们同样可以正常访问网页,但这个过程中 Web 服务器识别出的真实 IP 就不再是我们本机的 IP 了,就成功实现了 IP 伪装,这就是代理的基本原理。
代理的作用
代理有什么作用呢?我们可以简单列举如下。
-
突破自身 IP 访问限制,访问一些平时不能访问的站点。
-
访问一些单位或团体内部资源,如使用教育网内地址段免费代理服务器,就可以用于对教育网开放的各类 FTP 下载上传,以及各类资料查询共享等服务。
-
提高访问速度,通常代理服务器都设置一个较大的硬盘缓冲区,当有外界的信息通过时,同时也将其保存到缓冲区中,当其他用户再访问相同的信息时, 则直接由缓冲区中取出信息,传给用户,以提高访问速度。
-
隐藏真实 IP,上网者也可以通过这种方法隐藏自己的 IP,免受攻击,对于爬虫来说,我们用代理就是为了隐藏自身 IP,防止自身的 IP 被封锁。
代理分类
FTP 代理服务器,主要用于访问 FTP 服务器,一般有上传、下载以及缓存功能,端口一般为 21、2121 等。
HTTP 代理服务器,主要用于访问网页,一般有内容过滤和缓存功能,端口一般为 80、8080、3128 等。
SSL/TLS 代理,主要用于访问加密网站,一般有 SSL 或 TLS 加密功能(最高支持 128 位加密强度),端口一般为 443。
RTSP 代理,主要用于 Realplayer 访问 Real 流媒体服务器,一般有缓存功能,端口一般为 554。
Telnet 代理,主要用于 telnet 远程控制(黑客入侵计算机时常用于隐藏身份),端口一般为 23。
POP3/SMTP 代理,主要用于 POP3/SMTP 方式收发邮件,一般有缓存功能,端口一般为 110/25。
SOCKS 代理,只是单纯传递数据包,不关心具体协议和用法,所以速度快很多,一般有缓存功能,端口一般为 1080。SOCKS 代理协议又分为 SOCKS4 和 SOCKS5,SOCKS4 协议只支持 TCP,而 SOCKS5 协议支持 TCP 和 UDP,还支持各种身份验证机制、服务器端域名解析等。简单来说,SOCK4 能做到的 SOCKS5 都可以做到,但 SOCKS5 能做到的 SOCK4 不一定能做到。
高度匿名代理,高度匿名代理会将数据包原封不动的转发,在服务端看来就好像真的是一个普通客户端在访问,而记录的 IP 是代理服务器的 IP。
普通匿名代理,普通匿名代理会在数据包上做一些改动,服务端上有可能发现这是个代理服务器,也有一定几率追查到客户端的真实 IP。代理服务器通常会加入的 HTTP 头有 HTTP_VIA 和 HTTP_X_FORWARDED_FOR。
透明代理,透明代理不但改动了数据包,还会告诉服务器客户端的真实 IP。这种代理除了能用缓存技术提高浏览速度,能用内容过滤提高安全性之外,并无其他显著作用,最常见的例子是内网中的硬件防火墙。
间谍代理,间谍代理指组织或个人创建的,用于记录用户传输的数据,然后进行研究、监控等目的代理服务器。