主要问题:1)模型如何生成具有与输入音频一致的面部运动(特别是嘴部和下颌运动)的视频?2)模型如何在保留身份信息的同时生成视觉上逼真的帧?
摘要:
从音频生成说话脸部视频引起了广泛的研究兴趣。一些特定个人的方法可以生成生动的视频,但需要使用目标说话者的视频进行训练或微调。现有的通用方法在生成逼真和与嘴唇同步的视频同时保留身份信息方面存在困难。为了解决这个问题,我们提出了一个两阶段的框架,包括从音频到关键点的生成和从关键点到视频的渲染过程。首先,我们设计了一种基于Transformer的全新关键点生成器,用于从音频中推断出嘴唇和下颌的关键点。说话者面部的先前关键点特征被用来使生成的关键点与说话者的面部轮廓相吻合。然后,我们构建了一个视频渲染模型,将生成的关键点转化为面部图像。在这个阶段,我们从目标脸的下半部和静态参考图像中提取先前的外观信息,有助于生成逼真且保持身份信息的视觉内容。为了更有效地探索静态参考图像的先前信息,我们根据运动场将静态参考图像与目标脸的姿态和表情进行对齐。此外,我们重新使用音频特征以确保生成的面部图像与音频很好地同步。
-
Introduction:
音频驱动的说话脸部视频生成在许多应用中具有价值,如视觉配音,数字助理和动画电影。基于训练范例和数据需求,说话脸部生成方法通常可以分为特定个人和通用个人两种类型。特定个人的方法可以生成照片般逼真的说话脸部视频,但需要使用目标说话者的视频进行重新训练或微调,而这在某些真实场景中可能无法实现。因此,在这个领域中,学习生成通用个人的说话脸部视频是一个更为重要且具有挑战性的问题。这个主题也吸引了很多研究关注。在这篇论文中,我们专注于通过在音频数据和多个参考图像的指导下完成说话者原始视频的下半部分来解决通用个人说话脸部视频生成的问题。主要挑战包括两个方面:1)模型如何生成具有面部运动的视频,特别是与输入音频一致的口部和下颌运动?2)模型如何在保留身份信息的同时生成视觉逼真的帧?为了解决第一个问题,许多方法在生成通用个人说话脸部视频时利用面部关键点作为中间表示。
由于输入的音频和中间的关键点没有固有的视觉内容信息,因此在保留身份信息的同时,从音频和中间关键点产生逼真的面部视频是非常具有挑战性的。我们使用来自上半部脸的姿势先验关键点和来自静态面部图像提取的参考关键点作为音频到关键点生成器的额外输入。对两种关键的的使用有助于防止生成器产生偏离说话者面部轮廓的结果。然后,我们基于多头自注意力模块构建了生成器的网络架构。与简单的串联或加法操作相比,我们的设计在捕获语音单元和关键点之间的关系方面更有优势 。此外,多个静态人脸图像被用来提取先前的外观信息,以生成真实且保留身份的人脸帧。
我们使用基于运动场的对齐模块和面部图像翻译模块建立了关键点到视频渲染网络。对齐模块:将静态参考图像与由关键点生成器生成的关键点结果提供的面部姿势和表情进行对齐。具体实现方法:首先,针对每个静态参考图像,推断出该图像的运动场,即描述图像中不同区域运动情况的信息。然后,利用推断得到的运动场,对该图像以及图像的特征进行变换或扭曲,使其与由关键点生成器生成的面部姿势和表情一致。这样可以确保最终生成的面部图像与静态参考图像在姿势和表情上保持一致,产生逼真的结果。面部图像翻译模块通过整合来自推断的关键点、被遮挡的原始图像、对齐的参考图像和音频的多源特征来生成最终的面部图像。
方法:
给定音频序列和初始输入视频,我们的目标是通过以逐帧方式完善输入视频的下半部分遮挡的脸部,生成一个与音频同步的说话人面部视频。我们的方法概述如图2所示。
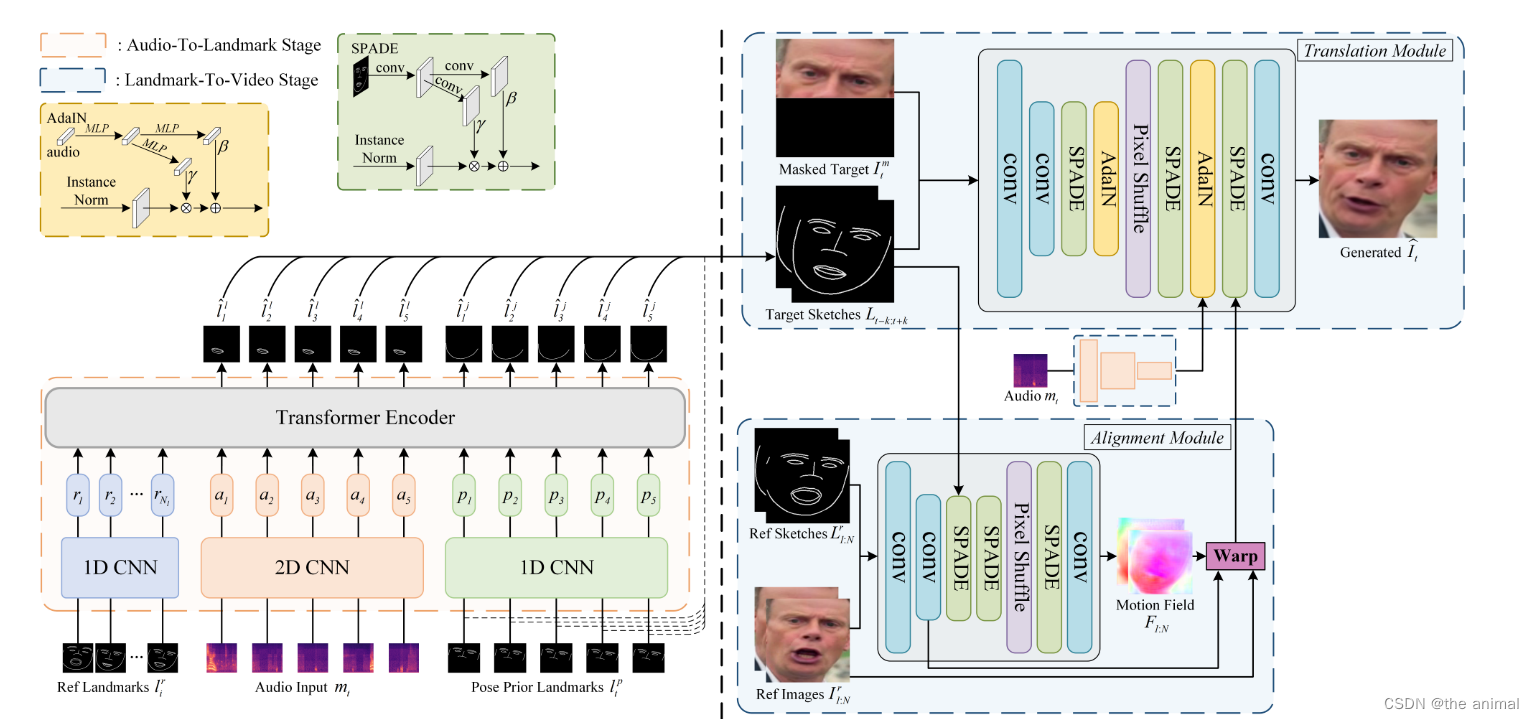
**音频到关键点生成阶段(Audio-To-Landmark Generation):左侧橙色部分。基于Transformer的关键点生成器以音频、参考关键点和姿势先验关键点为输入,预测嘴唇和下颌的关键点,然后与姿势先验关键点结合构建目标草图。为简单起见,省略了位置编码和模态编码。
关键点到视频渲染阶段(Landmark-To-Video Rendering):右侧蓝色部分。根据目标草图,对齐模块以多个参考图像及其草图作为输入,获取运动场,将参考图像及其特征扭曲到目标头部姿势和表情。借助音频特征、扭曲后的图像和特征,翻译模块将连接了下半部遮蔽目标脸的目标草图转化为最终的面部图像。
Overview of our framework. It can be divided into two stages: (1) Audio-To-Landmark Generation (left orange part). The
transformer-base landmark generator takes the audio, reference landmarks, and pose prior landmarks as input to predict the landmarks
of lip and jaw, which are then combined with pose prior landmarks to construct the target sketches. Positional encodings and modality
encodings are omitted for simplicity. (2) Landmark-To-Video Rendering (right blue part). According to target sketches, the alignment
module takes multiple reference images and their sketches as input to obtain the motion fields, which warp the reference images and their
features to target head pose and expression. With the assistance of audio features and warped images and features, the translation module
translates the target sketches concatenated with the lower-half masked target face to the resulted face image.
**
我们的框架由两个阶段组成。第一阶段将音频信号和说话者面部的先验关键点作为输入以预测嘴唇和下巴的界标。第二阶段由对齐模块和翻译模块组成。基于运动场,对齐模块将参考图像及其特征与目标脸部姿势和表情进行配准。翻译模块在音频特征的指导下,以及来自被遮挡的目标脸部和已配准的参考图像的先验外观信息的指导下,从关键点合成完整的面部图像。基于运动场,对齐模块将参考图像及其特征与目标脸部姿势和表情进行配准。翻译模块在音频特征的指导下,以及来自被遮挡的目标脸部和已配准的参考图像的先前外观信息的指导下,从关键点合成完整的面部图像。
3.1. Audio-To-Landmark Generation
在这个阶段,网络的目标是一次生成 T = 5 T = 5 T=5 个相邻帧的嘴唇 { l ^ l t ∈ R 2 × n l } t = 1 T \{\hat{l}_{lt} \in \mathbb{R}^{2 \times nl}\}_{t=1}^T {
l^lt∈R2×nl}t=1T 和下颌 { j ^ l t ∈ R 2