一、 ProPainter
1.算法简介
ProPainter是由新加坡南洋理工大学(Nanyang Technological University)的S-Lab团队开发的一款视频修复工具。它融合了图像和特征修复的优势,以及高效的Transformer技术,旨在提供高质量的视频修复效果,同时保持高效性。
ProPainter包含以下功能:
- 对象去除:能够轻松去除视频中的不需要的对象。
- 水印删除:可用于删除视频中的水印,提高视觉质量。
- 视频内容完整性修复:能够修复损坏的视频内容,使其看起来 完整和连贯。
2.项目部署
想对ProPainter有更多了解或者想部署ProPainter项目的可以我之前的博客:
一键智能视频编辑与视频修复算法——ProPainter源码解析与部署
3.项目局限性
ProPainter当前开源的代码只有视频移除对象部分的源码,但在移除对象之前,要生成mask图,ProPainter不提供生成mask图像的代码,生成mask图像的代码要借助目标分割与目标追踪。
比如我要移动掉桌子中间的投影仪,那要借助Segment-and-Track Anything对目标进行分割与追踪,然后每一帧都生成mask图像:

生成的mask图像:

二、Segment-and-Track Anything
1.算法简介
“Segment-and-Track Anything” 是由浙江大学 ReLER 实验室开发的一款多功能视频分割和目标跟踪模型,它深度整合了 SAM(Segment Anything Model)和视频分割技术,使其能够高效地跟踪视频中的目标,并支持多种交互方式(如点、画笔和文字输入)。
在这个基础上,SAM-Track 实现了多个传统视频分割任务的统一,使其能够一键分割和追踪任意视频中的任意目标,将传统视频分割技术推向通用视频分割领域。SAM-Track 在复杂场景下表现出卓越的性能,即使在单一GPU卡上也能高质量地稳定跟踪数百个目标。
SAM-Track 模型基于 ECCV’22 VOT Workshop 四个赛道的冠军方案 DeAOT。DeAOT 是一种高效的多目标视频对象分割模型,在提供首帧物体标注的情况下,可以对视频的其余帧中的物体进行追踪分割。DeAOT 使用一种识别机制,将一个视频中的多个目标嵌入到同一高维空间中,从而实现对多个物体的同时跟踪。DeAOT 在多物体追踪方面的速度表现媲美其他专注于单个物体追踪的 VOS 方法。此外,通过基于分层 Transformer 的传播机制,DeAOT 更好地整合了长时序和短时序信息,表现出卓越的追踪性能。然而,DeAOT 需要参考帧的标注来初始化,为了提高方便性,SAM-Track 利用了图像分割领域的明星模型 SAM,以获取高质量的参考帧标注信息。SAM 凭借出色的零样本迁移能力以及多种交互方式,使 SAM-Track 能够为 DeAOT 高效获取高质量的参考帧标注信息。
虽然 SAM 模型在图像分割领域表现出色,但它无法输出语义标签,并且文本提示也无法有效地支持 Referring Object Segmentation 以及其他依赖深层语义理解的任务。因此,SAM-Track 模型进一步集成了 Grounding DINO,实现了高精度的语言引导视频分割。Grounding DINO 是一种开放集合目标检测模型,具备出色的语言理解能力。
2.项目部署
可参考之前的博客:
Segment-and-Track Anything——通用智能视频分割、目标追踪、编辑算法解读与源码部署
三、项目整合
1.目标分割与追踪
把Segment-and-Track Anything和ProPainter整合在一起之后,实现目标分割与目标追踪。
目标分割与目标追踪:
def tracking_objects_in_video(SegTracker, input_video, input_img_seq=None, frame_num=0):
if input_video is not None:
video_name = os.path.basename(input_video).split('.')[0]
else:
return None, None
# create dir to save result
tracking_result_dir = f'{os.path.join(os.path.dirname(__file__), "output", f"{video_name}")}'
create_dir(tracking_result_dir)
io_args = {
'tracking_result_dir': tracking_result_dir,
'output_mask_dir': f'{tracking_result_dir}/{video_name}_masks',
'output_masked_frame_dir': f'{tracking_result_dir}/{video_name}_masked_frames',
'output_video': f'{tracking_result_dir}/{video_name}_seg.mp4', # keep same format as input video
# 'output_gif': f'{tracking_result_dir}/{video_name}_seg.gif',
}
return video_type_input_tracking(SegTracker, input_video, io_args, video_name, frame_num)
def video_type_input_tracking(SegTracker, input_video, io_args, video_name, frame_num=0):
pred_list = []
masked_pred_list = []
# source video to segment
cap = cv2.VideoCapture(input_video)
fps = cap.get(cv2.CAP_PROP_FPS)
if frame_num > 0:
output_mask_name = sorted([img_name for img_name in os.listdir(io_args['output_mask_dir'])])
output_masked_frame_name = sorted([img_name for img_name in os.listdir(io_args['output_masked_frame_dir'])])
for i in range(0, frame_num):
cap.read()
pred_list.append(
np.array(Image.open(os.path.join(io_args['output_mask_dir'], output_mask_name[i])).convert('P')))
masked_pred_list.append(
cv2.imread(os.path.join(io_args['output_masked_frame_dir'], output_masked_frame_name[i])))
# create dir to save predicted mask and masked frame
if frame_num == 0:
if os.path.isdir(io_args['output_mask_dir']):
# os.system(f"rm -r {io_args['output_mask_dir']}")
pass
if os.path.isdir(io_args['output_masked_frame_dir']):
# os.system(f"rm -r {io_args['output_masked_frame_dir']}")
pass
output_mask_dir = io_args['output_mask_dir']
create_dir(io_args['output_mask_dir'])
create_dir(io_args['output_masked_frame_dir'])
torch.cuda.empty_cache()
gc.collect()
sam_gap = SegTracker.sam_gap
frame_idx = 0
with torch.cuda.amp.autocast():
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
if frame_idx == 0:
pred_mask = SegTracker.first_frame_mask
torch.cuda.empty_cache()
gc.collect()
elif (frame_idx % sam_gap) == 0:
seg_mask = SegTracker.seg(frame)
torch.cuda.empty_cache()
gc.collect()
track_mask = SegTracker.track(frame)
# find new objects, and update tracker with new objects
new_obj_mask = SegTracker.find_new_objs(track_mask, seg_mask)
save_prediction(new_obj_mask, output_mask_dir, str(frame_idx + frame_num).zfill(5) + '_new.png')
pred_mask = track_mask + new_obj_mask
# segtracker.restart_tracker()
SegTracker.add_reference(frame, pred_mask)
else:
pred_mask = SegTracker.track(frame, update_memory=True)
torch.cuda.empty_cache()
gc.collect()
save_prediction(pred_mask, output_mask_dir, str(frame_idx + frame_num).zfill(5) + '.png')
pred_list.append(pred_mask)
print("processed frame {}, obj_num {}".format(frame_idx + frame_num, SegTracker.get_obj_num()), end='\r')
frame_idx += 1
cap.release()
print('\nfinished')
##################
# Visualization
##################
# draw pred mask on frame and save as a video
cap = cv2.VideoCapture(input_video)
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
out = cv2.VideoWriter(io_args['output_video'], fourcc, fps, (width, height))
frame_idx = 0
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
pred_mask = pred_list[frame_idx]
masked_frame = draw_mask(frame, pred_mask)
cv2.imwrite(f"{io_args['output_masked_frame_dir']}/{str(frame_idx).zfill(5)}.png", masked_frame[:, :, ::-1])
masked_pred_list.append(masked_frame)
masked_frame = cv2.cvtColor(masked_frame, cv2.COLOR_RGB2BGR)
out.write(masked_frame)
print('frame {} writed'.format(frame_idx), end='\r')
frame_idx += 1
out.release()
cap.release()
print("\n{} saved".format(io_args['output_video']))
print('\nfinished')
# manually release memory (after cuda out of memory)
del SegTracker
torch.cuda.empty_cache()
gc.collect()
return io_args['output_video']
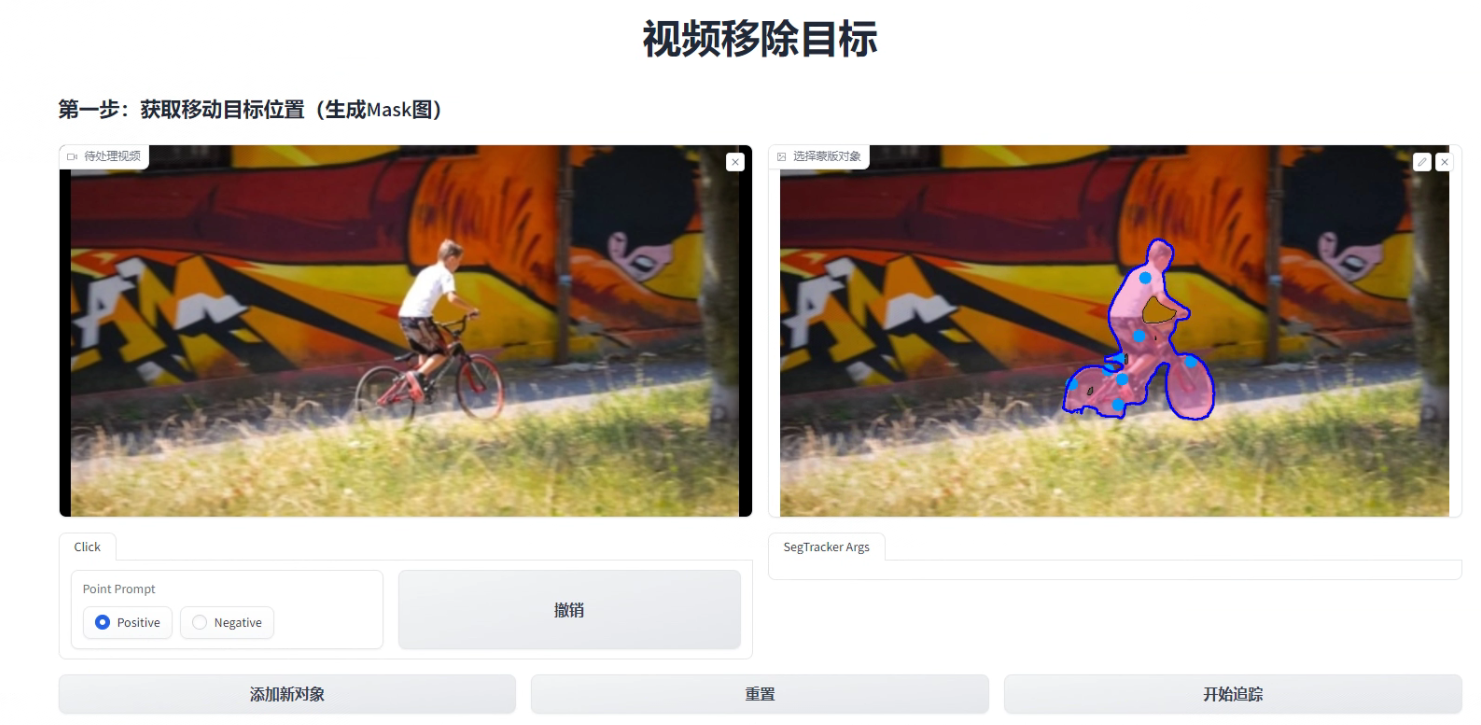
执行之后,在项目根目录的output目录下生成mask图:
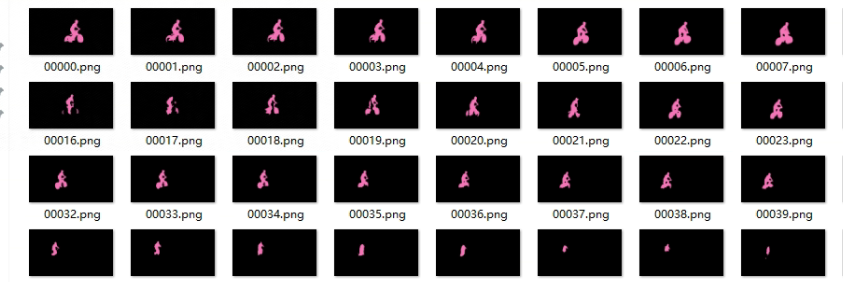
2. 目标移除
得到mask图之后就可以使用ProPainter进行视频目标移除:
def remove_watermark(input_video):
print("开始祛除目标")
# print('cwd', os.getcwd())
root_path = os.getcwd()
os.chdir(os.path.join(root_path,'ProPainter'))
python_exe = resolve_relative_path(os.path.join(root_path,'env/python.exe'))
inference = resolve_relative_path(os.path.join(root_path,'ProPainter/inference_propainter.py'))
video_name = os.path.basename(input_video).split('.')[0].split('_')[0]
output_base_path = resolve_relative_path('./output/')
output_path = f'{output_base_path}/{video_name}/'
mask = f'{output_path}/{video_name}_masks/'
command = f'{python_exe} {inference} --video {input_video} --mask {mask} --output {output_path} --fp16 --subvideo_length 50'
print(command)
result = subprocess.run(command, shell=True)
if result.returncode != 0:
error_message = result.stderr.decode('utf-8', 'ignore')
print(f"错误 {error_message}")
else:
print("成功")
file_name = input_video.split('\\')[-1].split('.')[0]
print(file_name)
os.chdir(resolve_relative_path('./'))
print('cwd', os.getcwd())
return output_path + '/' + file_name + '/' + 'inpaint_out' + '.mp4'
# return input_video

四、项目源码
1.项目配置
我使用的硬件环境是GPU是3080,在目前项目只能处理短视频,对输入视频的尺寸也有限制,输入的尺寸过大会出现GPU内存不够用的现象,输入的视频太长,超过1分钟的视频,会出现卡死的现象。
2.项目源码
为了运行方便,这里把项目打包成一个包,下载之后直接运行,不用安装任何环境,但要在GPU下使用。