目录
- Python 爬取免费小说思路
-
- 代码解析
-
- 爬取东西基本的四行代码:
-
- user-agent
- 安装模块
- 从 bs4 导入 BeautifulSoup ,
- 查询某个标签开头的数据
- 筛选
- 遍历
-
- 获取小说的章节名称
- 每章小说的链接
- 获取请求网址的响应
- 获取小说的内容
- 筛选内容
-
- 整理内容
- 爬取下载到指定文件夹
- 完整代码:
Python 爬取免费小说思路
代码解析
爬取东西基本的四行代码:

user-agent

安装模块
cmd 打开小黑窗,执行安装模块命令
模块的作用:完成具体的某一个功能
pip install bs4 -i https://mirrors.aliyun.com/pypi/simple/
pip install lxml -i https://mirrors.aliyun.com/pypi/simple/
从 bs4 导入 BeautifulSoup ,
把 res.text 解析成 ‘lxml’ , 相当于把文本原本 text的格式 整理成 lxml格式

查询某个标签开头的数据
解释这行代码的作用:
soup.find_all('x')--> 参数: 'x' --> 就能查找获取所有 <x> xxxxxx </x> 的数据
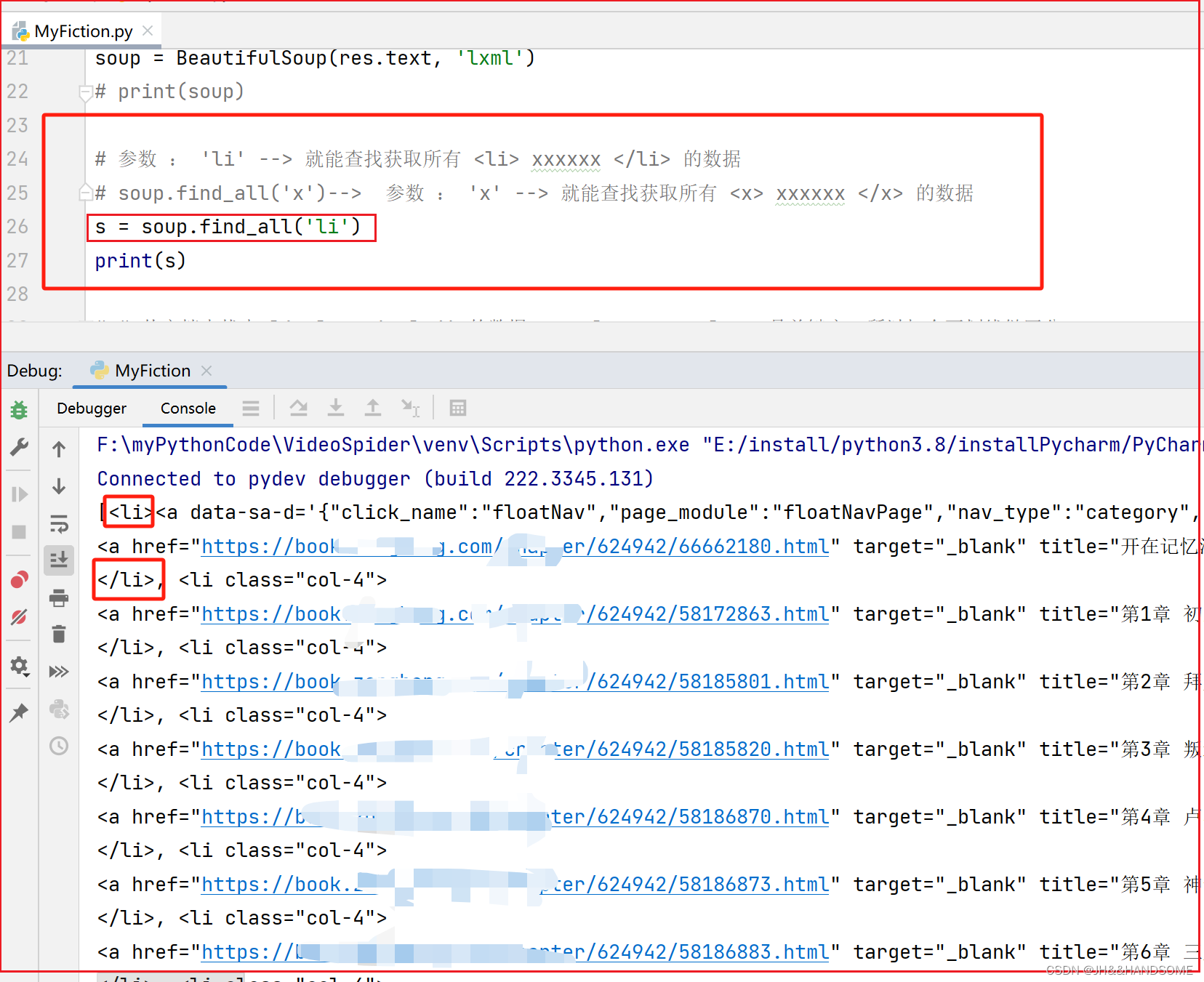
筛选
筛选小说:思路是从大到小筛选,实际先筛选小的,找不到再扩大范围筛选
<