今天我用图解的方式讲解pandas的用法,内容较长建议收藏,梳理不易,点赞支持。
学习 Python 编程,给我的经验就是:技术要学会分享、交流,不建议闭门造车。一个人可能走的很快、但一堆人可以走的更远。如果你希望技术交流,可以关注我(或者私信)
整理不易,关注一下吧ღ( ´・ᴗ・` )比心🤔
第一部分:初识Hadoop
1.Hadoop介绍
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
- 主要解决海量数据的存储和海量数据的分析计算的问题。
- 广义上来说,Hadoop 通常是指一个更广泛的概念——Hadoop 生态圈。
2.Hadoop的版本
hadoop的三大发行版本:Apache、Cloudera、Hortonworks。
- Apache版本最原始(最基础),对入门学习最好。
- Cloudera内部集成了很多大数据框架,对应产品CDH。
- Hortonworks文档较好,对应产品HDP 。
- Hortonwork和Cloudera合并
3.Hadoop的特点
高可靠性:Hadoop底层维护多个数据副本,即使某个计算单元存储出现故障,也不会导致数据丢失。

- 高拓展性:在集群之间分配任务数据,可方便的扩展数以万计节点。
- 高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处理速度。
- 高容错性:能够自动将失败的任务重新分配。
4.Hadoop的组成
Hadoop1.X版本的组成,MapReduce负责计算和计算所需的cpu、内存等资源的调度

Hadoop2.X版本的组成,增加了Yarn进行资源调度,原来的MapReduce只负责计算。

Hadoop3.X版本的组成没啥区别,在细节上还是有区别的。
5.HDFS
HDFS(Hadoop Distributed File System)是一个分布式文件系统。
大致是这样的:将一个很大的文件拆成很多部分,然后存储在一个个DataNode中,而NameNode中只存储DataNode的位置信息,2NN对NameNode进行备份(害怕NameNode挂掉,然后丢失所有信息。)
- NameNode(nn):存储文件的元数据,如文件名、文件目录结构、文件属性,以及每个文件的块列表和块所在的DataNode等。
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
- Secondary NameNode(2nn):每隔一段时间对NameNode进行备份。

6.YARN
YARN(Yet Another Resource Negotiator),是一种资源协调者,是Hadpood的资源管理器。
- ResourceManager(RM):整个集群资源(内存、CPU)的老大。
- NodeManager(NM):单个节点服务器资源老大。
- ApplicationMaster(AM):单个任务运行的老大。
- client:客户端
- Container:容器,相当于一台独立的服务器,里面封装了运行所需的资源,如内存、CPU、磁盘、网络等。
- 客户端可有多个、集群上可有运行多个ApplicationMaster、每个NodeManager上可以有多个Container.

7.MapReduce
MapReduce将计算过程划分为两个阶段:MAP和Reduce
1.Map阶段并行处理输入数据。
2.Reduce阶段对Map结果进行汇总。
100T的数据已经被分被存储到很多台服务器上,如果需要找寻某个资料,我们就可以要求各个服务器并行寻找自己的电脑上有没有对应的内容,然后把结果告诉汇总服务器。

8.HDFS、YARN和MapReduce三者的关系

9.大数据处理的过程

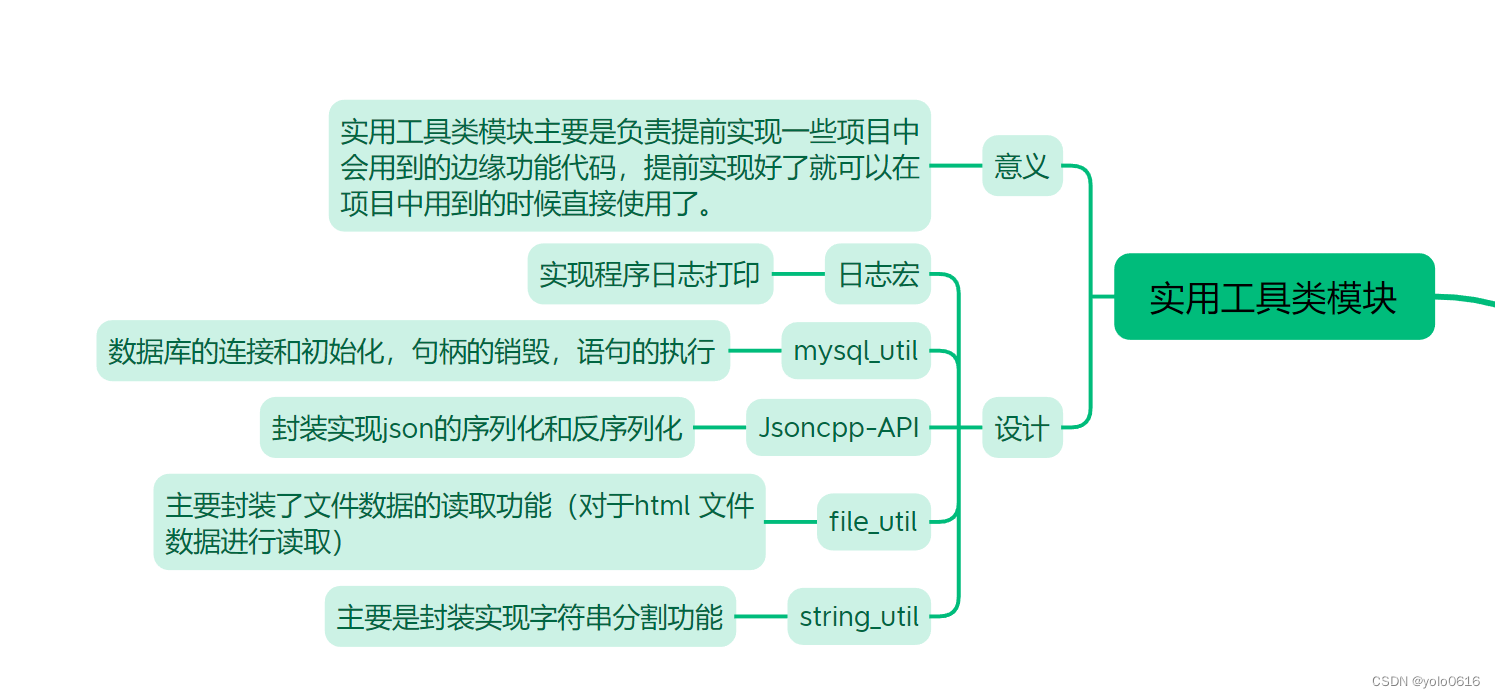
第二部分:Hadoop之配置java与hadoop环境
我们学习hapood,需要在系统中配置JAVA和Hadoop环境,今天我们就来使用Xshell配置对应环境。一个hadoop服务器需要这些东西,我们今天的文章只配置java和hadoop环境。

1.打开虚拟机连接xshell
我这里有三台hadoop虚拟机,我们来配置其中一台的环境,其他2台利用复制的手段就能够安装完成。我们先来配置hadoop103的环境。

打开Xshell连接上hadoop103.

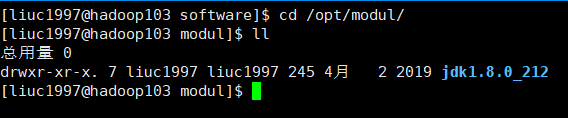
2.进入到我们安装软件的文件夹
这里的文件夹可以自己设置,只要记得自己东西在哪就行,我一般放在/opt/software目录下。

3.将文件复制到该目录下
我们这里使用Xftp将文件从window下拷贝进来,点击Xftp,

把java压缩包和hadoop压缩包拖过来。


传输完成后我们看看linux中有这俩包吗?

4.解压缩文件安装java的JDK
将JDK解压到 /opt/modul/文件夹下
tar - zxvf jdk-8u212-linux-x64.tar.gz -c/opt/modul/
然后就会出来解压过程,等他完成就行。
我们来到解压缩的文件夹下,看到文件已经复制成功。
cd/opt/moudl/
5.配置java的JDK的环境变量
使用命令进入环境变量文件夹
cd jdk1.8.0_212/
sudo cd /etc/profile.d/
11
这个样子:

我们在这里创建一个.sh结尾的文件,将它放在这里,然后系统启动时就会加载这个文件,从而加载环境变量。
sudo vim my_env.sh
在文件里输入以下内容:
#JAVA_HOME
JAVA_HOME=/opt/moudl/jdk1.8.0_212
exprot PATH:$JAVA_HOME/bin
输入完之后保存关闭

保存完毕重启服务
source /etc/profile
java
重启后输入java就行。

出现以下内容说明成功!

6.解压缩Hadoop的压缩包
将hadoop解压到 /opt/moudl/文件夹下
tar -zxvf hadoop-3.1.3.tar.gz -c/opt/modul/
结果如下:

然后又出现复制的过程信息。就行了。
7.配置Hadoop的环境变量
cd/opt/modul/hadoop-3.1.3/
来到该文件夹下后

修改环境变量文件。
sudo vim /etc/profile.d/my_env.sh

添加如下内容
#HADOOP_HOOM
export HADOOP _HOOM =/opt/modul/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOOM/sbin
添加完后是这样的

保存之后重启资源
source /etc/profile
hapood
出来一大串就成功了

配置结束
第三部分:Hadoop之文件复制scp和同步rsync
众所周知,Hadoop主要有三种运行模式
- 单机模式(服务器一台,数据由linux管理)
- 伪分布式模式(服务器一台,数据由HDFS管理)
- 完全分布式模式(服务器节点很多,数据分布在多台设备HDFS管理)
目前主要学习完全分布式模式。配置完全分布式的步骤如下:

我们这一章主要是进行文件的拷贝(因为只完成了一台客户机的环境配置)
1.scp介绍命令
可以实现服务器与服务器数据之间的拷贝
scp -r $pdir/$fname $user@host:$pdir/$fname
命令 递归 要拷贝的文件名/名称 目的地用户/主机:目的的路径/名称
2.拷贝文件
2.1我们将hadoop102上的文件拷贝到hadoop103上
scp -r jdk1.8.0_212/ liuc1997@hadoop103:/opt/modul/

然后叫你输入密码,就开始复制了。来hadoop103看一下,复制成功!

2.2 我们这次在hadoop103上将hadoop102上的文件拿过来
scp -r liuc1997@hadoop102:/opt/modul/hadoop-3.1.3 ./
然后就会叫你输入hadoop102的密码。

然后就会出现复制的进程,最后结束后查看一下:

没有问题。
2.3利用hadoop103将hadoop102的数据拷贝到hadoop104上
这是两个跟自己毫无关系的服务器也可以操控他们。
scp -r liuc1997@hadoop102:/opt/modul/* liuc1997@hadoop104:/opt/modul/
依次输入hadoop102和hadoop104的密码

然后就开始了。来到hadoop104上看一下,复制成功。

2.rsync介绍命令
上面介绍的复制命令scp是指把整个文件夹都拷贝过来,而同步是指对两个文件的差异部分进行更新。 第一次同步等同于拷贝
可以实现服务器与服务器数据之间的同步
rsync -av $pdir/$fname $user@host:$pdir/$fname
命令 显示复制过程 要同步的文件名/名称 目的地用户/主机:目的的路径/名称
2.1复制差异信息
我们在hadoop102的主机上hadoop-3.1.3文件下先创建一个文件hello.txt,然后将该文件复制给hadoop104,看看效果。

将更改后的文件复制给104主句
rsync -av hadoop-3.1.3/ liuc1997@hadoop104:/opt/modul/hadoop-3.1.3/
然后飞快的运行之后,在104的主机上就能看见这个文件。

2.2制作同步脚本
我们cd~到用户目录下,创建一个bin目录
cd ~
mkdir bin
cd bin
vim xsync
将下面内容粘过去,我们就创建了一个文件同步工具
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#遍历所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ___________________host_________________
#3.遍历所有目录,挨个发送
for file in $@
do
#4.判断文件是否存在
if [ -e $file ]
then
#5.获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#获取文件夹名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
然后我们cd ~ 输入
同步三台机器的bin目录
xsync bin/
第四部分:Hadoop之SSH免密登录
我们使用大数据技术时,经常需要访问成百上千台其他服务器,每次都需要输入密码,很繁琐,于是需要配制SSH免密登录提高效率。
1. SSH原理
SSH的原理就是服务器A将自己的公钥给另一台服务器B,代表我俩可以进行访问,然后服务器A用自己的私钥]进行加密数据然后发送给B,B接受后利用A的公钥解密数据知道了A要什么,然后B把A所要的数据利用A的公钥加密传输给A。这就完成了数据传输的流程。

2. 配置SSH
先转到自己的用户目录下
cd ~
然后查看所有文件包括隐藏文件。
ls-al
查看是否存在.ssh/的文件,如果没有就输入
ssh-keygen -t rsa
三次回车。出现以下结果,说明成功了。

然后再查看
ls -al
就会发现存在.ssh/文件,我们cd进去发现多了两个文件,这两个文件就是SSH的公钥和私钥,我们需要将公钥复制给我们需要访问的服务器。

复制公钥给服务器hadoop102:
ssh-copy-id hadoop102
配置完后给再给hadoop103
ssh-copy-id hadoop103
完成之后就可以通过SSH命令免密访问其他服务器了.
ssh hadoop102

第五部分:Hadoop之集群配置和启动集群(完全分布式)
在经历过前面的环境配置后,接下来我们进行Hadoop的集群配置,什么叫做集群配置,这里是指我们将每个服务器配置成功后,每台服务器的Hadoop并没有连接起来,我们需要进行配置,将Hadoop平台连接,具体内容如下:
1.集群部署

安装模块如上:但这里有几点需要注意
- NameNode和SecondaryNameNode不要放在一台服务器上,因为NameNode和SecondaryNameNode都很消耗资源。
- ResourceManager 也很消耗内存,不要和NameNode和SecondaryNameNode配置在一台服务器上。
2.配置文件
Hadoop的配置文件分为两大类,一类是默认配置文件,一类是自定义配置文件。当用户想修改某些默认配置文件时,才需要自定义配置文件。
2.1默认配置文件

2.2自定义配置文件

具体看一下所在位置:

配置core-site.xml
我们在core-site.xml插入如下语句:
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8080</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
配置hdfs-site.xml
<!--nn的web-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- nn2的web访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
配置yarn-site.xml
<!--指定MR走shuffle-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--指定resourcemanager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!--环境变量继承-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
配置mapred-site.xml
<!--指定mapreduce运行在yarn上-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.分发文件

我们将配置好的文件分发给其他服务器
xsync hadoop/

4.启动集群
4.1配置workers
启动集群之前,我们需要配置workers
vim /opt/modul/hadoop-3.1.3/etc/hadoop/workers
添加一下内容,不要有空格!

然后分发workers
xsync workers

4.2启动集群
4.2.1配置HDFS
第一次启动集群,需要在hadoop102主机上格式化NameNode(格式化NameNode会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到以往数据。如果集群在运行中报错,需要重新格式化NameNode的话,一定要先停止namenode和DataNode进程,并且要删除所有机器的data和logs目录,再进行格式化。)
#格式化HDFS
hdfs namenode -fromat
没有报错的话,就会出来这两个文件。
报错了一定要终止进程并删除掉data和logs这两个文件
##终止进程的命令
stop-all.sh

检查一下文件内容,有这些东西就是没有问题了。

接下来我们转到hadoop-3.1.3目录下进入sbin目录

这里有一个start-dfs.sh启动集群的命令。

接着输入以下命令:

#启动集群
sbin/start-dfs.sh
hadoop102启动成功:

hadoop103启动成功:

hadoop104启动成功:

访问网址,会出现以下结果
hadoop102:9870

4.2.2配置YARN
我们的yarn资源ResourceManager是需要在hadoop103上配置,一定要在hadoop103!一定要在hadoop103!一定要在hadoop103!

#启动yarn
sbin/start-yarn.sh
jps后出现以下界面
hadoop103出现:

hadoop102出现:

hadoop104出现:

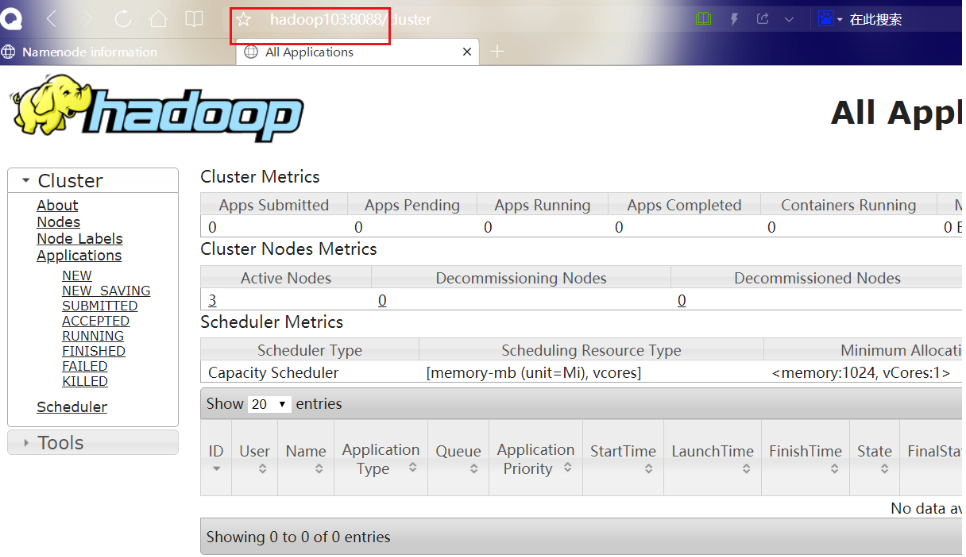
yarn的外部界面
hadoop102:8088