一、多表查询(面试题)
1. 介绍
多表查询是在企业中必不可少的,无论多么简单的项目里通常会出现多表查询的操作。因为只要是关系型数据库,在设计表时都需要按照范式进行设计,为了减少数据冗余,都会拆成多个表。当需要多张表中数据时,需要进行联合查询。
在MySQL学习时,知道表之间关系分为:一对一、一对多、多对多。这三种关系又细分为单向和双向。
如果学习的是Hibernate框架,必须要严格区分开表之间的关系,然后才能使用Hibernate框架。但是在MyBatis框架中只有两种情况:当前表对应另外表是一行数据还是多行数据。转换到实体类上:当前实体类包含其它实体类一个对象还是多个对象。
转换到MyBatis的映射文件上:在<resultMap>标签里面使用<association>还是<collection>标签就可以。
所以:在学习MyBatis多表查询时其实就是在学习<association>标签和<collection>标签。
-
如果一个实体类关联另一个实体类的一个对象使用
<association>。 -
如果一个实体类关联一个实体类的List集合对象,需要使用
<collection>。 -
所以分析的思路是:先分析需求->分析数据库设计对应关系->创建实体类->根据实体类关联属性类型决定使用哪个标签。
这两个标签根据编写的SQL,分为N+1查询和联合查询两种方式。
两种方式优缺点:
-
联合查询方式:
优点:一次查询。
缺点:SQL相对复杂。不支持延迟加载。
<!-- 配置SQL映射的文件 -->
<mapper namespace="com.sh.mapper.EmpMapper" >
<!-- 联合查询 使用resultMap -->
<resultMap id="a" type="Emp">
<!-- 员工映射 -->
<!-- 使用联合查询时,默认可以映射的也要进行手动映射-->
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="addr" property="addr"/>
<result column="did" property="did"/>
<!-- 部门映射 -->
<!--
property="dept" 哪个属性名
javaType 联合查询返回的类型
-->
<!-- 除了集合的引用类型使用association -->
<!-- 集合使用collection -->
<association property="dept" javaType="Dept">
<id column="dept_id" property="dept_id"/>
<result column="dname" property="dname"/>
</association>
</resultMap>
<select id="queryAll" resultMap="a">
select id,name,addr,did,dept_id,dname from emp join dept where
did = dept_id
</select>
-
业务装配
优点:手动实现,灵活度高。
缺点:代码复杂。
一般不使用
-
N+1方式:
优点:SQL简单。支持延迟加载。
缺点:多做N次查询。
<mapper namespace="com.sh.mapper.DeptMapper">
<!-- 先根据部门id查询该部门的所有员工 -->
<resultMap id="b" type="Dept">
<id column="dept_id" property="dept_id"/>
<result column="dname" property="dname"/>
</resultMap>
<select id="queryById" resultMap="b">
select * from dept where dept_id=#{id}
</select>
</mapper>
<!-- N+1 查询 -->
<!-- 那边DeptMapper要设置好-->
<!-- 再正常查询 -->
<resultMap id="c" type="Emp">
<id column="id" property="id"/>
<result column="name" property="name"/>
<result column="addr" property="addr"/>
<result column="did" property="did"/>
<!-- 再使用association -->
<!--
select 连接的mapper映射文件
column 相当于外键
其实就是将两个mapper练了起来,按顺序执行
-->
<association property="dept" javaType="Dept" select="com.sh.mapper.DeptMapper.queryById" column="did">
</association>
</resultMap>
<select id="queryAll1" resultMap="c">
select * from emp
</select>
</mapper>
二、延迟加载(面试题)
延迟加载只能出现在多表联合查询的N+1方式中。
表示当执行当前方法时,是否立即执行关联方法的SQL。
1. 测试默认情况下效果
以EmpMapper接口的queryAllN1()方法进行举例:当前方法的作用是查询全部Emp信息,并且调用DeptMapper的queryById方法,同时查询Dept的内容。
2. 启用延迟加载
配置延迟加载有两种方式:
全局配置。整个项目所有N+1位置都生效。
局部配置。只配置某个N+1位置。
两种方式需要选择其中一种,如果两种方式都使用了,局部配置方式生效。
2.1 全局配置方式
官方文档全局设置属性说明:
| 属性名 | 解释说明 | 可取值 | 默认值 |
|---|---|---|---|
| lazyLoadingEnabled | 延迟加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置 fetchType 属性来覆盖该项的开关状态。 | true | false | false |
全局设置:
<settings>
<!-- 开启驼峰转换 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
<!--
全局方式设置延迟加载
全局设置后所有的能延迟加载的都会延迟加载
即所有的N+1都会使用延迟加载
局部设置就是指定哪些不使用延迟加载
-->
<setting name="lazyLoadingEnabled" value="true"/>
</settings>局部设置:
局部配置方式需要在collection或association标签中配置fetchType属性。fetchType可取值:lazy(延迟加载)和earge(立即加载)。
当配置了fetchType属性后,全局settings的配置被覆盖,对于当前标签以fetchType属性值为准。
<resultMap id="empMap2" type="Emp">
<id column="e_id" property="id"/>
<result column="e_name" property="name"/>
<association property="dept" javaType="Dept"
select="com.sh.mapper.DeptMapper.selectById" column="e_d_id"
fetchType="lazy"></association>
</resultMap>
<select id="selectAllN1" resultMap="empMap2">
select e_id,e_name,e_d_id from emp
</select>三、缓存(面试题)
1. 缓存介绍
缓存是一种临时存储少量数据至内存或者是磁盘的一种技术。减少数据的加载次数,可以降低工作量,提高程序响应速度,缓存的重要性是不言而喻的。
MyBatis的缓存将相同查询条件的SQL语句执行一遍后所得到的结果存在内存或者某种缓存介质当中,当下次遇到一模一样的查询SQL时候不在执行SQL与数据库交互,而是直接从缓存中获取结果,不再查询数据库,提升了性能;尤其是在查询多、缓存命中率越高的情况下,使用缓存对性能的提高更明显。
MyBatis分为一级缓存和二级缓存,同时也可配置关于缓存设置。
-
一级存储是SqlSession上的缓存。
-
二级缓存是在SqlSessionFactory(namespace)上的缓存。
-
默认情况下,MyBatis开启一级缓存,没有开启二级缓存。当数据量大的时候可以借助一些第三方缓存框架或Redis缓存来协助保存Mybatis的二级缓存数据。
2. 一级缓存
一级缓存是SqlSession级缓存。只要是同一个SqlSession对象(必须是同一个)调用同一个<select>标签相同参数值时(不同<select>完全相同的SQL不会走同一个缓存),将直接使用缓存数据,而不会访问数据库。
重要提示:
一级缓存想要生效,必须同时满足3个条件:
1. 同一个SqlSession对象。
2. 同一个select标签。本质为底层同一个JDBC的Statemen对象。
3. 完全相同的SQL,包含SQL的参数值也必须相同。
4. insert、delete、update操作会清空一级缓存数据。
5. close(),commit也会清空一级缓存。
2.1 一级缓存流程图
命中缓存:从Map中查询是否存在指定key。如果存在表示命中缓存,如果不存在这个key,需要访问数据库。
更新到缓存:把查询结果put到map中。
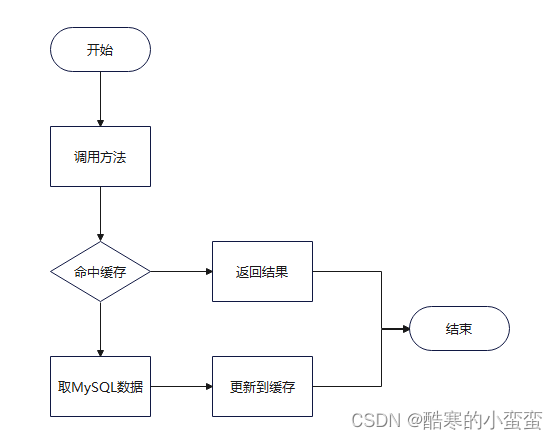
MyBatis中的缓存机制:
一级缓存执行流程: 默认开启
1.根据调用的接口中的方法 + select语句 + ... + 建立了缓存的key
2.从一级缓存(localCache的集合)中获取key对应的数据
如果
没有:从数据库中查询,将查询结果存储到一级缓存中
(key,数据),返回查询到的数据
有:直接返回一级缓存中获取到的数据
3.一级缓存基于SqlSession,使用同一个SqlSession一级缓存生效
也就是说多个用户访问时就不好使了
注意:
哪些操作可以清除一级缓存
防止出现脏读,幻读,可重复读的问题
1.commit() rollback()
2.insert() update() delete()
3.close()
3. 二级缓存
二级缓存是以namespace为标记的缓存,可能要借助磁盘,磁盘上的缓存,可以由一个SqlSessionFactory(单例设计模式,多个用户可以使用缓存)创建的SqlSession之间共享缓存数据,默认并不开启。下面的代码中创建了两个SqlSession,执行相同的SQL语句,尝试让第二个SqlSession使用第一个SqlSession查询后缓存的数据。
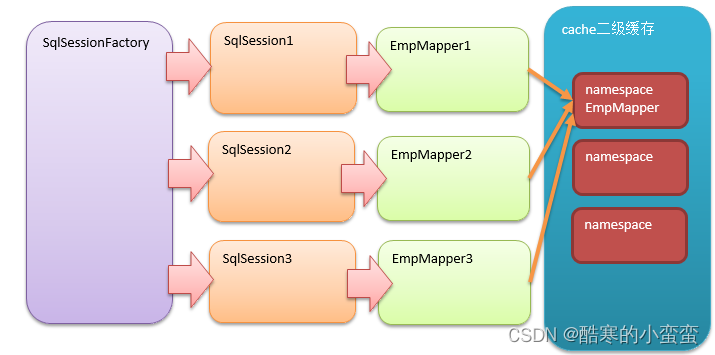
二级缓存生效条件:
-
同一个SqlSessionFactory对象。
-
同一个方法(<select>)。
-
SQL完全相同。
重要提示:
二级缓存默认不开启,需要手动开启。
只有当SqlSession执行commit或close时才会存储到二级缓存中。
下面演示配置二级缓存生效的步骤:
-
全局开关:在mybatis.xml文件中的<settings>标签配置开启二级缓存
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>2. 分开关:在要开启二级缓存的mapper文件中开启缓存
使用<cache/>配置时,注解的查询无法缓存。
<mapper namespace="com.sh.mapper.EmpMapper">
<cache/>
</mapper>3.二级缓存未必完全使用内存,有可能占用硬盘存储,缓存中存储的JavaBean对象必须实现序列化接口
二级缓存执行流程: 需要手动开启
全局设置:
在在mybatis.xml文件中的<settings>标签配置开启二级缓存
<settings>
<setting name="cacheEnabled" value="true"/>
</settings>
局部配置:
在映射文件中通过<cache/>开启
标签中设置useCache="false",设置指定select标签不使用二级缓存
每一个映射文件对应着一个映射文件的二级缓存
有效范围:同一个映射文件中的sql
1.根据调用的接口中的方法 + select语句 + ... 建立了缓存的 key
2.先从当前映射文件的二级缓存(真正存储二级缓存数据的集合:Cache接口实现类PerpetualCache的cache属性)
[本质为map集合]中根据key获取对应数据
如果
没有:
1. 从一级缓存(localCache)中获取key对应的数据
没有:从数据库查询,将查询结果放入一级缓存中,
再添加到二级缓存的临时存储缓存数据的集合:
Cache接口实现类TransactionalCache的entriesToAddOnCommit属性[本质为map集合]中,返回数据
有:返回一级缓存中的数据,并再二级缓存中添加,和上面一样
有:直接返回二级缓存中的数据
只有在执行了commit(),close() 才会将临时缓存map集合(entriesToAddOnCommit中数据存储到真正存储缓存map集合(cache)中
注意:
清除二级缓存的操作
防止出现脏读,幻读,可重复读的问题
添加,修改,删除
四、四大核心接口介绍及执行流程(面试题)
1. 四大核心接口介绍
MyBatis执行过程中涉及到非常重要的四个接口,这四个接口为MyBatis的四大核心接口:
-
Executor执行器,执行器负责整个SQL执行过程的总体控制。默认SimpleExecutor执行器。
-
StatementHandler语句处理器,语句处理器负责和JDBC层具体交互,包括prepare语句,执行语句,以及调用ParameterHandler.parameterize()。默认是PreparedStatementHandler。
-
ParameterHandler参数处理器,参数处理器,负责PreparedStatement入参的具体设置。默认使用DefaultParameterHandler。
-
ResultSetHandler结果集处理器,结果处理器负责将JDBC查询结果映射到java对象。默认使用DefaultResultSetHandler。
2. 四大核心接口对应的JDBC代码
对应的JDBC代码

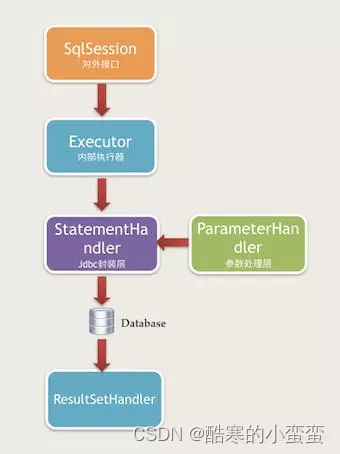
3. 四大核心接口执行顺序按照下图进行执行
4. 通过断点测试执行流程
可以通过对四大核心接口的实现类中核心方法添加断点。
SimpleExecutor -> doQuery() 方法(必须以查询作为测试,其他类型SQL使用不同方法)
DefaultParameterHandler -> setParameters
PreparedStatementHandler -> query
DefaultResultHandler -> handleResult
里面需要注意的是会在SimpleExecutor先实例化Statement对象,然后调用DefaultParameterHandler 的setParameters,再然后调用PreparedStatementHandler的query。
5. 完整执行流程文字说明
(1)使用执行器Executor控制整个执行流程
(2)实例化StatementHandler,进行SQL预处理
(3)使用ParameterHandler设置参数
(4)使用StatementHandler执行SQL
(5)使用ResultSetHandler处理结果集
五、执行器类型(面试题)
MyBatis的执行器都实现了Executor接口。作用是控制SQL执行的流程。

-
BaseExecutor:主要是使用了模板设计模式,共性被封装在 BaseExecutor 中,容易变化的内容被分离到了子类中 。
-
SimpleExecutor:默认的执行器类型。每次执行query和update(DML)都会重新创建Statement对象。
-
ReuseExecutor:执行器会重用预处理语句。不会每一次调用都去创建一个新的 Statement 对象,而是会重复利用以前创建好的(如果SQL相同的话)。
-
BatchExecutor:用在update(DML)操作中。所有SQL一次性提交。适用于批量操作。
-
-
CachingExecutor:处理缓存的执行器。无论使用上面三种执行器中的哪个。都是会执行CachingExecutor。
在项目可以通过factory.openSession()方法参数设置执行器类型。通过枚举类型ExecutorType进行设置。
执行器主要控制的就是Statement对SQL如何进行操作。
有效范围:同一个SqlSession对象。
1. SimpleExecutor
SimpleExecutor 是MyBatis默认的执行器类型。
2. ReuseExecutor
ReuseExecutor主要用在执行时,重用预编译SQL。在同一个SqlSession对象中下次调用已经预编译的SQL直接设置参数。
3. BatchExecutor
BatchExecutor底层使用JDBC的批量操作。每一条SQL都不会立即执行,而是放到了List<Statement>中,最终统一提交。
由于底层的批量操作只支持DML操作,所以BatchExecutor也主要用在批量新增、批量删除、批量修改中。
六、MyBatis执行原理详解(较常见面试题)
对于MyBatis执行原理来说,不同的情况有不同的执行过程,大致可以分下面几种情况:
(1)接口绑定方式、使用SqlSession执行方法。
(2)是否有插件。
(3)不同的执行器。
为了演示一个较为详细的执行流程。整个讲解过程中以SimpleExecutor作为执行器,包含接口和映射文件的接口绑定方案,同时带有自定义插件。其实就是上面自定义插件的代码。
MyBatis项目不能自动运行,测试代码如下,每一行都进入源码进行观察。
public class Test {
public static void main(String[] args) throws IOException {
InputStream is = Resources.getResourceAsStream("mybatis.cfg.xml");
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(is);
SqlSession session = factory.openSession();
EmpMapper empMapper = session.getMapper(EmpMapper.class);
MyPageHelper.startPage(0,2);
List<Emp> list = empMapper.selectAllpage();
System.out.println(list);
//session.commit();
session.close();
}
}8. MyBatis执行原理文字说明
首先加载全局配置文件为输入流,交给XPathParser解析器解析为Document文档对象,然后使用DOM解析Document文档对象,把解析结果存放在Configuration配置类中。
通过DefaultSqlSessionFactory实例化工厂,实例SqlSession的对象。创建了SqlSession接口的实现类DefaultSqlSession对象,在创建过程中,会同时创建Transaction事务对象、Executor执行器对象。如果当前项目有Interceptor拦截器,创建执行器时会执行拦截器。
通过JDK提供的Proxy创建接口的动态代理对象。
可以通过接口的代理对象调用方法。在调用方法时MyBatis会根据方法的类型判断调用SqlSession的哪个方法。例如:selectList、selectOne、update、insert等。
确定好具体调用SqlSession的哪个方法后,会按照执行器类型执行MyBatis四大核心接口,执行时也会触发拦截器Interceptor。最终会返回SQL的执行结果。
执行完方法后需要提交事务,提交时清空缓存、清除存储的Statement对象。
最后关闭SqlSession对象,释放资源。
以上就是MyBatis执行原理。