设 B 为 Delivery rate,D 为 Delay,将 E = B/D 作为衡量效能,所有流量的收敛状态是一个 Nash 均衡,没有任何流量有动机增加或者减少 inflight。参见:更合理的 BBR。
并不是都知道这道理,增加 inflight 能挤出吞吐是共识,但却得不到好处(E)却鲜有人理解,换句话说,吞吐并非好处的全部,除了高吞吐,还有低延时,用高延时换来的高吞吐,总效能 E 反而更低。
即便排除上述恶意,将全网节点看作一个多方博弈系统,惩罚违规者,奖励谦让者,分布式端到端处理非常难。两方博弈尚有办法,三方及以上就麻烦,总有置身事外者引入不确定,比如猜谁放的屁,两人很容易确定是谁放的,三人则不行。
回到拥塞话题,两条流情景,一条 YaBBR(Yet another BBR,参见此文) 老鼠流与一条 YaBBR 大象流共享带宽,老鼠流拥有更大的加速比,确实可以通过早期的激进发送用一点点 D 挤兑更多 B 从而提高 E,大象流由于检测到 E 的降低,尝试降低 inflight 后找到 “新的山脊”,这让带宽分配趋向公平。
但 3 条流就比较麻烦,可以比划一下,很快就会陷入三体问题。
引入一个有趣的 AQM 很高尚。它将协助端侧快速收敛到公平的 Nash 均衡状态。它不仅对 YaBBR 有用,它对所有端到端拥塞控制算法都有帮助,不依赖 ECN,一点点空间换来比 CHOKe 更加精细的控制效果。
该 AQM 之所以高尚,因为与 CHOKe 不同,它不依赖队列(so?不能叫 AQ(queue)M?),这完全适应了 BBR 不排队的特征。如果一个拥塞控制算法本身就不产生队列,基于队列的 CHOKe(以及任何别的 AQM) 岂不终成无米之炊?
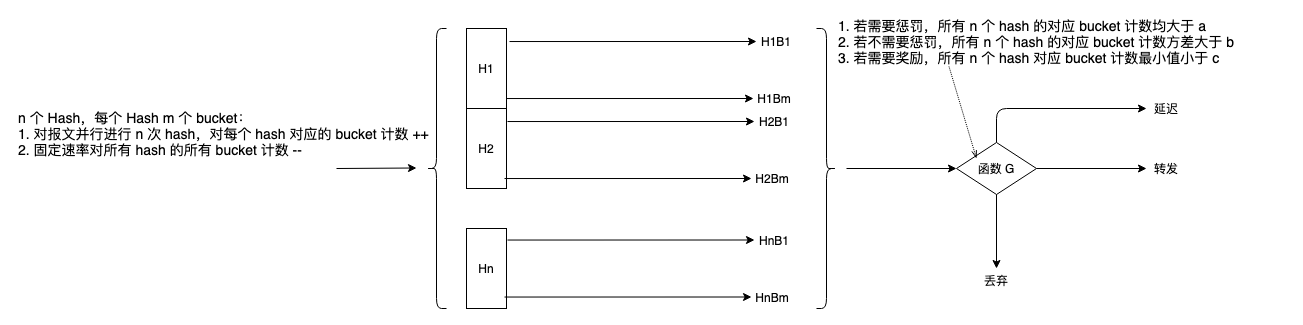
在 egress 排队前加一个 Counting Bloom filters(计数布隆过滤器):
- 每一个位组计数的定义域为 bits 允许的有符号整型。
- 以报文的五元组(或 srcIP,dstIP 二元组等不变量)计算 hash。
- 对每个报文进行 “插入” 操作,对应 k 个位组 inc 1。
- 对 “插入” 后的对应位组计数 x 1 x_1 x1, x 2 x_2 x2,… x k x_k xk,代入函数 G ( x 1 . . . x k ) G(x_1...x_k) G(x1...xk),计算丢弃概率 p p p,执行概率性丢弃。
- 以 “固定速率” 对过滤器的每个位组计数(可为负数)执行 dec 1。
将精力集中在设计一个 G G G,而不是过滤器的细节。 G G G 约束于:
- 若流 n n n 是需要被惩罚的流,则所有 k 个位组计数均不小于 α \alpha α。
- 为弱化布隆过滤器误判,若流 n n n 不需要被惩罚,k 个位组计数方差大于 β \beta β。
- 为强化反向判断,若流 n n n 需要被奖励,k 个位组最小计数需小于 γ \gamma γ。
- 如何奖励?增加突发?允许犯错?增加缓存?…
- …
将以上约束拟合成函数 G G G,对每个报文确定一个 p = G ( x 1 . . . x k ) p=G(x_1...x_k) p=G(x1...xk),以概率 p p p 决定如何对当前报文实施什么 action:
- 直接转发报文(正常行为)?
- 排队延迟报文(轻度惩罚)?
- 丢弃报文?
欲使位组计数降低,需要端侧主动识别到该装置施加的延迟或丢包从而降速,否则来几个丢几个,且误伤善者概率极低。
不基于队列,action 也不仅限于丢包,引入 “延迟action” 可改变端侧的 D 以减少它的 E,从而促使端侧的 YaBBR 降低 inflt 以爬到最佳的 “山脊”。
通过该装置调速,端侧的 YaBBR 将很快公平收敛到 E=B/D 标识的 Nash 均衡状态。
这就是全部,算不上 AQM ,只是 AQM 的前置处理。尚未引入布隆过滤器时,我的最初想法如下:
但意思差不多。
下面是形而上扯淡时间。
写这篇文章来自于 5 点思考:
- 上周的 YaBBR 未能有一个清晰的收敛模型,陷入了三体问题(以及三人猜谁放屁问题),所以这周继续思考了一下,还是要集中 AQM 去辅助。
- 我曾说 AIMD 是零存整取的 CSMA/CD,将总线冲突集中管理起来就是交换机,可总线以太网能实现分布式排队吗?Linux 争抢自旋锁可轻易转到 ticket 自旋锁,依赖原子++,-- 即可,而共享以太网原子操作代价多大?拿 ticket 及释放 ticket 的开销是否大于冲突检测和退避开销(这不就是令牌环嘛…)?关键还是时间问题,以太网线太长了,光速太慢了,仲裁时间太久了。
- 交换机 AQM 只能用丢包或 ECN 提示拥塞吗?难道不能有意延迟代替丢包,比如检测到激进流,用下凸曲线控制延迟,将该流延迟越放越大,期待其后知后觉,屡教不改再丢包,这肯定能提高全局带宽利用率,丢包少了重传必然也少了,无用功少了,总效能就高了。至于排队所需的能耗是否大于重传能耗,应该小很多,前者只是锁存,后者则必须经过高功耗光电转换。
- POC 端侧的拥塞控制机制,比如写个 cc 算法,有一台主机就行,交换节点的机制可以尝试基于 nf_conntrack 来修改。
- AQM 是管理队列的,但如果稳定点就没有队列,AQM 还管理什么呢?CHOKe 非常不错,但它依赖队列,所以要有一个不依赖队列的 just in time 算法。
浙江温州皮鞋湿,下雨进水不会胖。







![B+树 [数据结构与算法][Java]](https://img-blog.csdnimg.cn/aca3791fc1f04d0c9864886dc620b22f.png#pic_center)