文章目录
- 创建表
- 例子
- 查看表结构
- 修改表
- 新增列属性
- 修改列属性
- 修改列名
- 修改表名
- 删除列
- 删除表
阅读前导:
一般来说,对表的操作可以分为对表结构和对表内容的操作。
- 对表结构的操作,就是用数据定义语言 DDL 来创建、修改或删除表中的对象,比如字段、索引、约束等。常用的命令有 CREATE、ALTER、DROP 等。
- 对表内容的操作,就是用数据操作语言 DML 来插入、更新或删除表中的记录,比如数据行或列。常用的命令有 INSERT、UPDATE、DELETE 等。
本文介绍对表结构的操作,在学习 MySQL 的数据类型、表的约束以后,再学习表内容的增删查改。
创建表
SQL:
CREATE TABLE [IF NOT EXISTS] table_name(
field1 datatype1 [COMMENT '注释信息'],
field2 datatype2 [COMMENT '注释信息'],
field3 datatype3 [COMMENT '注释信息']
)[CHARSET=charset_name] [COLLATE=collation_name] [ENGINE=engine_name];
其中:
- 大写单词表示关键字(使用时可以小写,MySQL 会自动优化合并),[ ] 中代表的是可选项。如果没有指定可选项,就根据配置文件选择。
- field 表示列名,datatype 表示列的类型。
- CHARSET 用于指定表所采用的编码格式,如果没有指定则以所在数据库的编码格式为准。
- COLLATE 用于指定表所采用的校验规则,如果没有指定则以所在数据库的校验规则为准。
- ENGINE 用于指定表所采用的存储引擎。
- COMMENT 用于对指定列添加注释信息。
例子
不同的存储引擎,创建表时底层的文件类型和数量有所不同。
例如下面在一个名为table_test_db1这个数据库中分别指定存储引擎为 MyISAM 和 InnoDB 创建了名为table_test1和table_test2的表,并且为它们的列属性分别添加了注释信息:
mysql> create table table_test1(
-> id int comment '用户的 ID'
-> )charset=utf8 engine=MyISAM;
mysql> create table table_test2(
-> name varchar(20)
-> )charset=gbk engine=InnoDB;
在/var/lib/mysql/table_test_db1路径下:

从结果上看,MyISAM 和 InnoDB 两个存储引擎在创建表的时候,文件类型和数量是不一样的。为什么呢?(这是一个常见的面试题,你可能需要在学习完「索引」这部分才能理解)
根本原因是,它们的索引结构和数据存储方式不同。下面简单介绍一下它们名字的含义:
- MyISAM 的名字是由 ISAM(Indexed Sequential Access Method:有索引的顺序访问方法)发展而来的,ISAM 是一种早期的数据库存储结构,它使用 B+ 树作为索引,可以快速地访问数据。MyISAM 是 ISAM 的改进版本,它增加了一些新的特性,比如全文索引、压缩、空间函数等。MyISAM 的名字中的 My 是 MySQL 的缩写,表示它是 MySQL 的专属存储引擎。
- InnoDB 的名字是由 Innobase 公司创造的,Innobase 是一家芬兰的软件公司,它开发了 InnoDB 这个支持事务和外键的存储引擎,并将其作为插件提供给 MySQL 使用。InnoDB 的名字中的 inno 是 innovation(创新)的缩写,表示它是一个创新的存储引擎。
如果用字典来类比的话:
- Myisam 的存储引擎,可以类比为一本普通的字典,它有一个目录,列出了所有的单词和它们在字典中的页码。你可以通过目录快速地找到你想要查的单词,然后翻到相应的页面,看到单词的解释。这本字典还有一个特殊的功能,就是它可以对一些单词进行全文搜索,比如你可以输入一个主题,它会给你返回所有和这个主题相关的单词和解释。这本字典的优点是查找速度快,全文搜索强大,缺点是不支持修改和删除单词,也不支持添加新的单词。
- InnoDB 的存储引擎,可以类比为一本特殊的字典,它没有目录,而是把所有的单词按照字母顺序排列在一起,形成一个长长的链表。你可以从头到尾地遍历这个链表,找到你想要查的单词,然后看到单词的解释。这本字典还有一个特殊的功能,就是它可以对一些单词进行事务处理,比如你可以修改或删除某个单词,或者添加一个新的单词,并且保证这些操作是原子性、一致性、隔离性和持久性的。这本字典的优点是支持事务处理,高并发性能好,缺点是查找速度慢,不支持全文搜索。
这是比较标准的答案:
- MyISAM 的索引和数据是分开的,索引文件只保存数据记录的地址,这种索引叫做非聚簇索引。MyISAM 支持全文索引,可以对文本类型的字段进行快速搜索。MyISAM 的表可以有多个文类型的字段,但是只能有一个全文索引。
- InnoDB 的数据和主键索引是紧密绑定的,数据文件本身就是按 B+ 树组织的一个索引结构,这种索引叫做聚簇索引。InnoDB 不支持全文索引,但是支持外键和事务。InnoDB 的表只能有一个文类型的字段,并且必须有主键。
所以,MyISAM 存储引擎将表数据和表索引拆开存储:
- MyISAM:
- .frm:表结构文件(format)。存了表的定义信息,如字段名、类型、约束等,这个文件与存储引擎无关,每个表都有一个。
- .MYD:表数据文件(MY Data)。保存了表中的记录,按照顺序存储,每条记录占用固定的字节数。
- .MYI:表索引文件(MY Index)。保存了表中的索引信息,使用 B+ 树结构组织,可以快速地定位到数据文件中的记录。
- InnoDB:
- .frm:表结构文件。作用同上。
- .ibd:表空间文件(InnoDB Data)。保存了表的数据和索引信息,使用聚集索引结构组织,把主键和数据紧密绑定在一起。
查看表结构
SQL:
desc <表名>;

表结构的各个列属性:
- Field 表示该字段的名字。
- Type 表示该字段的类型。
- Null 表示该字段是否允许为空。
- Key 表示索引类型,比如主键索引为 PRI。
- Default 表示该字段的默认值。
- Extra 表示该字段的额外信息说明。
这些属性的具体细节,将会在 MySQL 的数据类型中学习。
虽然这些 SQL 的关键字标准写法需要大写,但是在使用时可以用小写,这是因为 MySQL 会对用户输入的 SQL 做语法分析和优化,使用
show create table <表名> \G
show create database <数据库名> \G
来查看创建表或数据库格式化后的 SQL:

修改表
SQL:
ALTER TABLE table_name ADD 新增列名 新增列的属性;
ALTER TABLE table_name MODIFY 列名 修改后的列属性;
ALTER TABLE table_name DROP 列名;
ALTER TABLE table_name RENAME [TO] 新表名;
ALTER TABLE table_name CHANGE 列名 新列名 新列属性;
新增列属性
为刚才创建的table_test1表中增加name和adress列属性:

如果你想让新的一列插入到 name 列之后,只需在 SQL 的最后增加after name;如果要放在第一列,换成not null first。
插入两条数据:

修改列属性
修改列属性,会将这一列的所有数据的属性都修改。
例如修改adress属性为varchar(64):
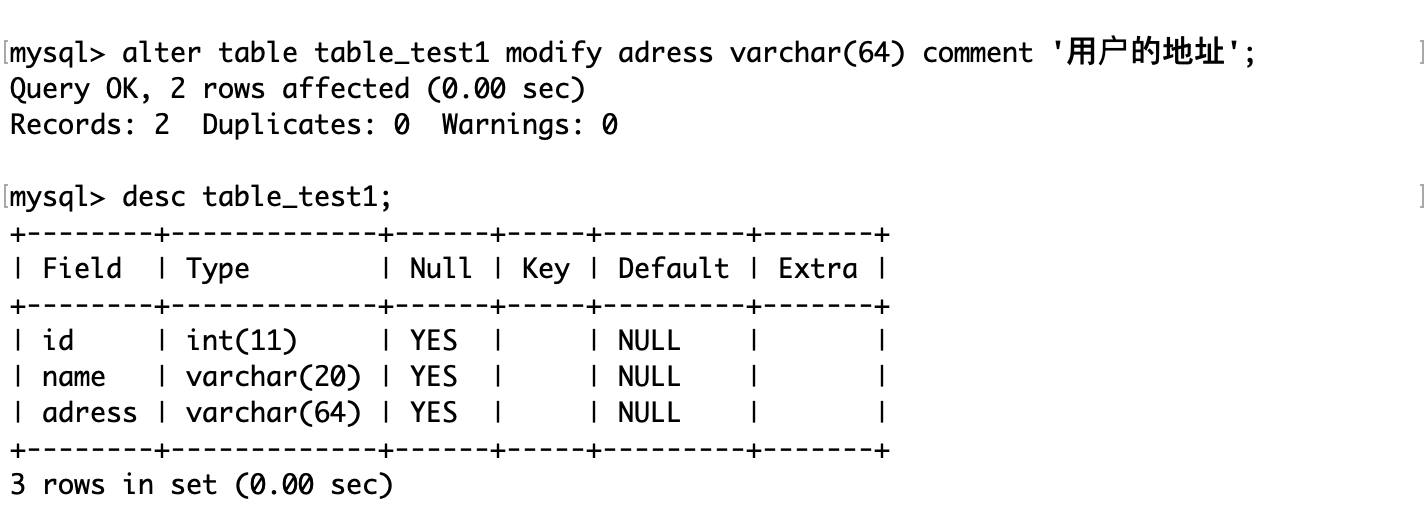
值得注意的是, MySQL 在修改时,会把原来的列定义替换为新的列定义,而不是在原有的基础上修改。所以如果想保留原来的 comment 字段,需要再修改时显式定义。
修改列名
将上表的adress改为home:

由于 MySQL 在修改列属性是是替换而不是直接修改,所以在修改列名时要指定列属性。
修改表名
将table_test1表改为test_table1:

删除列
将test_table1表中的name列删除:

删除这一列后,一整列的数据都没有了。除了备份外,MySQL 会记忆之前的所有插入的 SQL,其中包含了数据本身。
删除表
SQL:
DROP [TEMPORARY] TABLE [IF EXISTS] table_name;
其中:
- 在创建表语句中加上 TEMPORARY 关键字,那么服务器将创建出一个临时表,该表会在你与服务器的会话终止时自动消失。
- TEMPORARY 表的名字可以与某个已有的永久表相同,当有 TEMPORARY 表存在时,对应的永久表会隐藏起来(即无法访问)。
- 为了避免重新连接后(TEMPORARY 已经不存在),在未做检测的情况下调用 DROP 误删了对应永久表,因此在使用 DROP 删除临时表时需要带上 TEMPORARY 关键字。
删除table_test_db1数据库中的table_test2表:




![[代码随想录]回溯、贪心算法篇](https://img-blog.csdnimg.cn/9f09b6f7a9b24de580a8a9009d9418a5.png)