周报
读论文
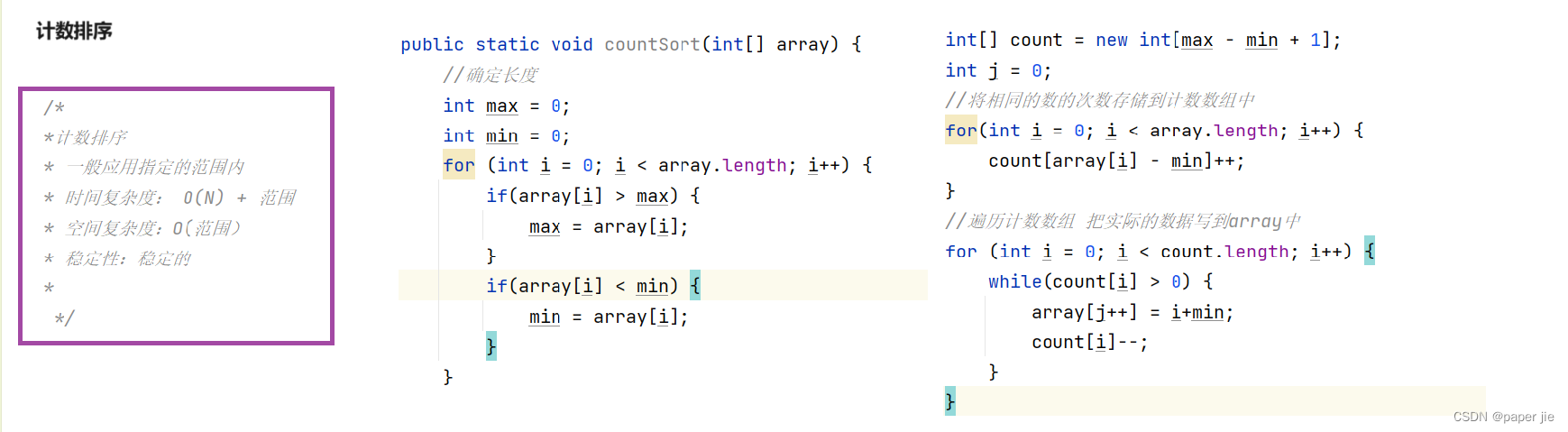
投机采样
为什么大语言模型(LLM)的推理过程文本生成这么慢?
因为运行大型模型的前向传递很慢,你可能需要依次执行数百次迭代。那么为什么前向传递速度慢?前向传递通常以矩阵乘法为主。内存带宽是此操作的限制 (例如,从 GPU RAM 到 GPU 计算核心)。换句话说,前向传递的瓶颈来自将模型权重加载到设备的计算核心中,而不是来自执行计算本身。
每个模型前向传递都会产生下一个 token 的概率,这实际上是一个不完整的描述。在文本生成期间,典型的迭代包括模型接收最新生成的 token 作为输入,加上所有其他先前输入的缓存内部计算,再返回下一个 token 得概率。缓存用于避免冗余计算,从而实现更快的前向传递,但它不是强制性的 (并且可以设置部分使用)。
禁用缓存时:
- 输入包含到目前为止生成的整个 token 序列
- 输出包含所有位置的下一个 token 对应的概率分布!
如果输入由前 N 个 token 组成,则第 N 个位置的输出对应于其下一个 token 的概率分布,并且该概率分布忽略了序列中的所有后续 token。在贪心解码的特殊情况下,如果你将生成的序列作为输入传递并将 argmax 运算符应用于生成的概率,你将获得生成的序列。
通俗的讲:解码器 的输入是一个长为N的序列,输出也是长为N的序列,只不过每一位错开一个

这意味着你可以将模型前向传递用于不同的目的: 除了提供一些 token 来预测下一个标记外,你还可以将序列传递给模型并检查模型是否会生成相同的序列 (或部分相同序列)。
所以我们可以用草稿模型生成token然后大语言模型去验证。步骤如下
- 使用贪心解码与草稿模型生成一定数量的候选 token。当第一次调用草稿生成时,生成的候选 token 的数量被初始化为 5。
- 使用我们的模型,对候选 token 进行前向计算,获得每个 token 对应的概率。
- 使用 token 选择方法 (使用.argmax() 进行贪心搜索或使用 .multinomial() 用于采样方法) 来从概率中选取 next_tokens。
- 比较步骤 3 中选择的 next_tokens 和 候选 token 中相同的 token 数量。请注意,我们需要从左到右进行比较, 在第一次不匹配后,后续所有 候选 token都无效。
- 使用步骤 4 得到的匹配数量将候选 token 分割。也就是,将输入 tokens 加上刚刚验证得到的正确的 tokens。
- 调整下一次迭代中生成的候选 token 的数量 —— 使用启发式方法,如果步骤 3 中所有 token 都匹配,则候选 token 的长度增加 2,否则减少 1。
疑问:所以LLM模型用来验证token的时候只用的是Transformer的解码器?也是前项推理过程的话,其本身和在没有草稿模型的情况下直接进行前向推理在效率上有区别吗?
思考:效率上确实有区别,之前是LLM推理5次,现在是草稿模型推出5次,LLM去验证。直觉上是后面这种效率高一些
草稿模型会弄错一些候选 token。由于任务的自回归性质,一旦草稿模型得到一个错误的 token,所有后续候选 token 都必须无效。但是,你可以使用模型更正错误 token 并反复重复此过程后再次查询草稿模型。即使草稿模型失败了几个 token,文本生成的延迟也会比原始形式小得多。
上面的视频中,LLM把草稿模型预测的 into 更正成了 over 后面的 token 删掉,草稿模型重新预测。
最后讨论一下采样方法
贪心解码适用于以输入为基础的任务 (自动语音识别、翻译、摘要……) 。对于需要大量创造力的开放式任务,例如使用语言模型作为聊天机器人的大多数任务,应该改用采样方法。
超参数:Temperature
我们可以使用采样中的温度系数来控制下一个标记的概率分布有多尖锐。在一种极端情况下,当Temperature接近 0 时,采样将近似于贪心解码,有利于最有可能的 token。在另一个极端,当Temperature设置为远大于 1 的值时,采样将是混乱的,从均匀分布中抽取。因此,低Temperature对你的辅助模型更有利。因为Temperature越大,LLM改正的情况就会越多,草稿模型生成的token的可信长度就会减少。举个例子,草稿模型生成5个token,LLM说其中4个都是错的打回去重新生成,这样效率就变得很低了。
然而,投机采样并非没有挑战:
1. 寻找理想的「草稿模型」(Draft Model):找到一个「小而强大」的草稿模型,与原始模型很好地协调,说起来容易,做起来难。
2. 系统复杂性:在一个系统中托管两个不同的模型会引入多层的复杂性,不论是计算还是操作,尤其是在分布式环境中。
3. 采样效率低:使用投机解码进行采样时,需要使用一种重要性采样方案。这会带来额外的生成开销,尤其是在较高的采样温度下。
这些复杂性和权衡限制了投机解码的广泛采用。因此,虽然投机解码前景广阔,但并未被广泛采用。
于是最近有人提出了美杜莎采样(下周的任务~)
工作
写了一篇投稿的review,佛山的项目继续在跑,加了一个评价指标