文章目录
- MapReduce 编程:join操作和聚合操作
- 一、实验目标
- 二、实验要求及注意事项
- 三、实验内容及步骤
- 附:系列文章
MapReduce 编程:join操作和聚合操作
一、实验目标
- 理解MapReduce计算框架的分布式处理工作流程
- 掌握用mapreduce计算框架实现Map端的本地聚合操作
- 掌握MapReduce编程的map端join操作
二、实验要求及注意事项
- 给出每个实验的主要实验步骤、实现代码和测试效果截图。
- 对本次实验工作进行全面的总结分析。
- 所有程序需要本地测试和集群测试,给出相应截图。
- 建议工程名,类名或包名等做适当修改,显示个人学号或者姓名
三、实验内容及步骤
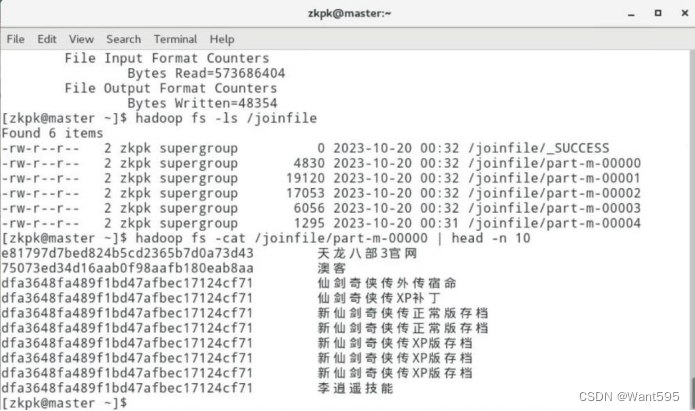
实验任务1:使用MapReduce编程,如果涉及到join操作,一般使用的是reduce端的join;但如果其中一个文件较小,可以将其添加到分布式缓存当中去,在map阶段时,每一个map task开始运行前,先从分布式缓存中取出此小文件,在map方法中对数据进行join操作,即map join操作。本实验使用的输入文件分别是uid-list和sogou,uid-lis保存着搜索过“电影”的用户的UID(比较小),sogou是日志文件;对于处于uid-list中的用户,把他们在sogou日志文件中的uid及搜索关键词输出到HDFS。实现效果如图1和图2所示。
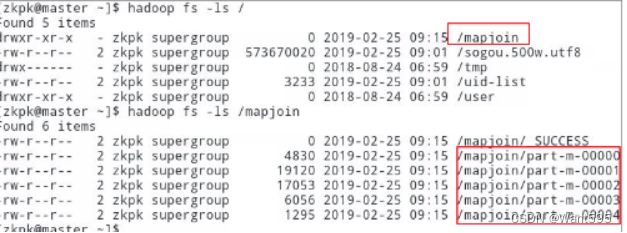
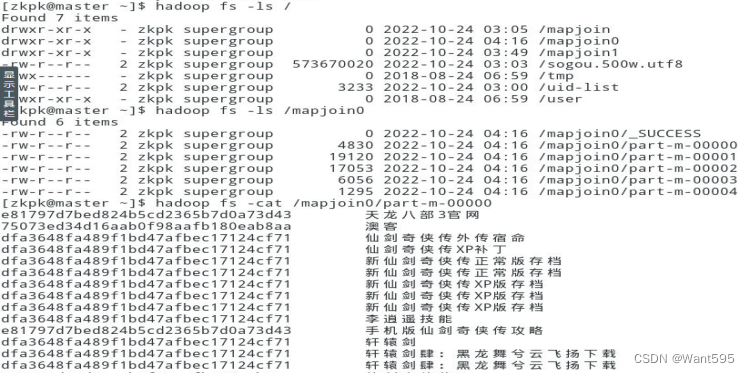
主要实现步骤和运行效果图:
(1)进入虚拟机并启动Hadoop集群,完成文件上传。
(2)启动Eclipse客户端,新建一个java工程;在该工程中创建package,导入jar包,完成环境配置,依次创建包、Mapper类,Reducer类和主类等;
(3)完成代码编写。
JoinMap
package hadoop;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.io.*;
public class WjwJoinMap extends Mapper<Object, Text, Text, Text>{
private Map<String, Integer> map = new HashMap<String, Integer>();
private Text uid = new Text();
protected void setup(Context context) throws IOException, InterruptedException{
@SuppressWarnings("resource")
BufferedReader br = new BufferedReader(new FileReader("uuid"));
String line = null;
while((line=br.readLine())!=null){
System.out.println(line);
map.put(line.trim(), 1);
}
}
protected void map(Object key, Text value, Context context) throws IOException, InterruptedException{
String[] arr = value.toString().split("\t");
String keyword = arr[2];
if(arr[1]!=null && map.get(arr[1])!=null){
uid.set(arr[1]);
context.write(uid, new Text(keyword));
}
}
}
JoinMain
package hadoop;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.*;
import org.apache.hadoop.mapreduce.lib.output.*;
public class WjwJoinMain {
public static void main(String[] args) throws IOException, URISyntaxException, ClassNotFoundException, InterruptedException{
if(args==null || args.length!=3){
System.out.println("error");
System.exit(0);
}
Job job = Job.getInstance(new Configuration(), "WjwJoinMain");
job.setJarByClass(WjwJoinMain.class);
job.setMapperClass(WjwJoinMap.class);
job.setNumReduceTasks(0);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
Path path = new Path(args[0]);
String pathLink = path.toUri().toString() + "#uuid";
job.addCacheFile(new URI(pathLink));
FileInputFormat.addInputPath(job, new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
job.waitForCompletion(true);
}
}
(4)测试程序,并查看输出结果。
实验任务2: Map端本地聚合,读取文本文件/home/zkpk/word.txt,进行单词计数,为了减少网络传输数据量,且使用本地聚合不会影响最终结果,在map端进行本地聚合。
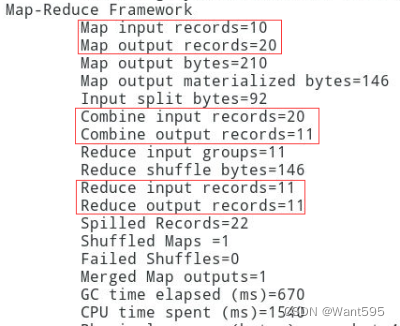
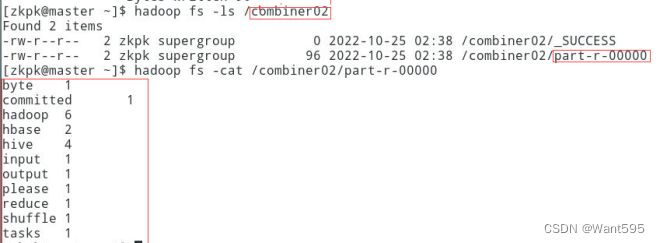
主要实现步骤和运行效果图:
(1)进入虚拟机并启动Hadoop集群,完成文件上传。
(2)启动Eclipse客户端,新建一个java工程;在该工程中创建package,导入jar包,完成环境配置,依次创建包、Mapper类,Reducer类和主类等;
(3)完成代码编写。
WordMap
package hadoop;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
import org.apache.hadoop.io.*;
public class WjwWordMap extends Mapper<Object, Text, Text, IntWritable>{
public void map(Object key, Text value, Context context) throws IOException, InterruptedException{
String arr[] = value.toString().split(" ");
for(String word:arr){
context.write(new Text(word), new IntWritable(1));
}
}
}
WordReduce
package hadoop;
import java.io.IOException;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Reducer;
public class WjwWordReduce extends Reducer<Text, IntWritable, Text, IntWritable>{
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{
int sum = 0;
for(IntWritable val:values){
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
}
WordMain
package hadoop;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
public class WjwWordMain {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
if(args==null || args.length!=2){
System.out.println("error");
}
Job job = Job.getInstance(new Configuration(), "WjwWordMain");
job.setJarByClass(WjwWordMain.class);
job.setMapperClass(WjwWordMap.class);
job.setCombinerClass(WjwWordReduce.class);
job.setReducerClass(WjwWordReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
(4)测试程序,并查看输出结果。
附:系列文章
| 实验 | 文章目录 | 直达链接 |
|---|---|---|
| 实验01 | Hadoop安装部署 | https://want595.blog.csdn.net/article/details/132767284 |
| 实验02 | HDFS常用shell命令 | https://want595.blog.csdn.net/article/details/132863345 |
| 实验03 | Hadoop读取文件 | https://want595.blog.csdn.net/article/details/132912077 |
| 实验04 | HDFS文件创建与写入 | https://want595.blog.csdn.net/article/details/133168180 |
| 实验05 | HDFS目录与文件的创建删除与查询操作 | https://want595.blog.csdn.net/article/details/133168734 |
| 实验06 | SequenceFile、元数据操作与MapReduce单词计数 | https://want595.blog.csdn.net/article/details/133926246 |
| 实验07 | MapReduce编程:数据过滤保存、UID 去重 | https://want595.blog.csdn.net/article/details/133947981 |
| 实验08 | MapReduce 编程:检索特定群体搜索记录和定义分片操作 | https://want595.blog.csdn.net/article/details/133948849 |
| 实验09 | MapReduce 编程:join操作和聚合操作 | https://want595.blog.csdn.net/article/details/133949148 |
| 实验10 | MapReduce编程:自定义分区和自定义计数器 | https://want595.blog.csdn.net/article/details/133949522 |