有的语言会把数组用作常用的基本的数据结构,比如 JavaScript,而 Golang 中的数组(Array),更倾向定位于一种底层的数据结构,记录的是一段连续的内存空间数据。但是在 Go 语言中平时直接用数组的时候不多,大多数场景下我们都会直接选用更加灵活的切片(Slice)
1 数组
声明与初始化
# 声明
var arr [5]int
var buffer [256]byte
# 初始化方式有两种,一种是显示声明长度,另一种是[...]T推断长度,会经过编译器推导,得到数组长度
arr1 := [3]int{0,1,2}
arr2 := [...]string{"Joey","Sophie"}
Go 为不同类型不同结构的初始化方式进行了优化(不止是数组的初始化这一点上,其它一些代码同样如此),对于优化过程,可以简单概括为下面的话:
- 如果数组中元素的个数小于或者等于 4 个,那么所有的变量会直接在栈上初始化;
- 如果数组元素大于 4 个,变量就会在静态存储区初始化然后拷贝到栈上,这些转换后的代码才会继续进入中间代码生成和机器码生成两个阶段,最后生成可以执行的二进制文件。
2 slice
区别 Slice 与 Array 的首要关键是记住下面几点:
- Slice 不是 Array,它描述一个 Array
- Slice 的本质是一个 Struct这是他长度可变的根本原因
Go 源码中找到 sliceHeader 的定义:
type sliceHeader struct {
Data unsafe.Pointer // 指向的数组
Len int // 长度,即 Slice 截取 Data 的长度
Cap int // 容量,即 Data 的大小,显然不会小于 Len
}
Slice 的声明方式比较多,我们可以直接构建一个空 Slice 而不需要指定长度,我们也可以直接基于 Array 本身构建一个 Slice,亦可以基于 Slice 构建新的 Slice
var sli0 = make([]int) // make([]T, Len, Cap)
var sli1 = arr1[5:10]
var sli2 = sli1[2:]
sli1 在 arr1 的左闭右开索引区间 [5, 10) 上构建了切片,而 sli2 又在 sli1 的基础上构建了 [2, 5) 的切片,这里值得记住的一点是,切片结构体里保存的是底层数组的指针(引用),因此他们指向的是同一块底层数组
2.1 函数传递 Slice
切片作为函数参数直接传递时就是个普通的值传递,但是 Slice 这个值很特殊,他里面存有数组的指针,又包含了 Slice 的 Len 和数组的 Cap,即又包含指针又包含普通值,因此:
- 直接传递 Slice 进函数时,传递的是 Slice 的 copy;
- 对 Slice 的元素进行修改操作,会通过指针直接修改数组,因此是可以实现的;
- 对 Slice 的长度修改,修改的是 copy 对象的 Len 字段,因此原 Slice 是长度是不会变的;
- 想要在函数内修改 Slice 的长度,最好的方式是传递 Slice 的指针;
2.2 容量与 append
append 返回的是一个新的 slice,直接 append 而不赋值给原 slice 的话,原 slice 长度是不会改变的
names = append(names, "Joey")
# 移除逻辑
ages = append(ages[:5], ages[6:])
关于容量需要记住的就是:当向 Slice 追加元素导致 Len大于 Cap 时,会触发扩容机制,创建一个Cap大于原数组的新数组(首元素地址不一致),并将值拷贝进新数组,之后再改变Slice元素值时改变的是新创建的数组(切断与原数组的引用关系)。是的,当触发扩容机制后,新的 Slice 底层数组已经不再是之前的数组了,对于 Slice 元素的修改都是基于新的底层数组进行。
因此我们如果真的关注性能这一块儿的话,一定要想办法避免频繁的触发扩容机制,比如当我们明确地知道 Slice 容量上限的时候,在声明时就应该通过 make([]T, Len, Cap) 给出明确的 cap 值
2.3 slice扩容
go1.17 及以下版本扩容机制如下:
代码的扩容策略可以简述为以下三个规则:
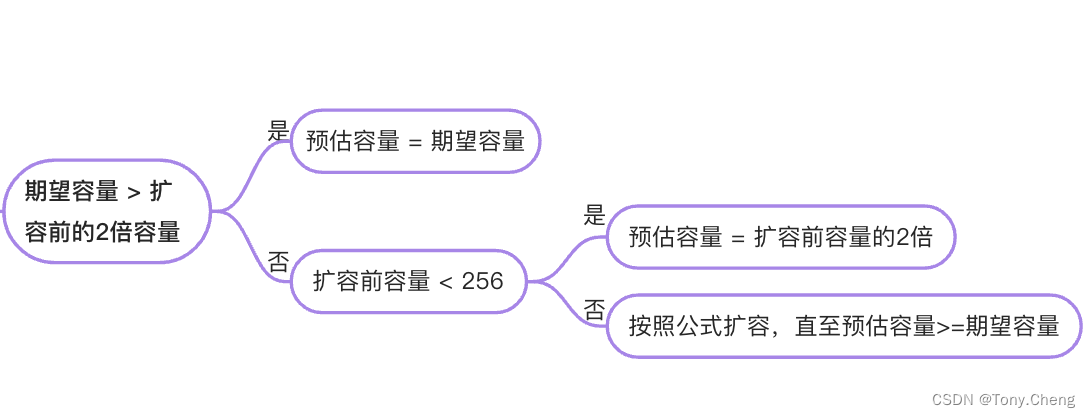
1.当期望容量 > 两倍的旧容量时,直接使用期望容量作为新切片的容量
2.如果旧容量 < 1024(注意这里单位是元素个数),那么直接翻倍旧容量
3.如果旧容量 > 1024,那么会进入一个循环,每次增加25%直到大于期望容量
可以看到,原来的go对于切片扩容后的容量判断有一个明显的magic number:1024,在1024之前,增长的系数是2,而1024之后则变为1.25。
关于为什么会这么设计,社区的相关讨论1给出了几点理由:1.如果只选择翻倍的扩容策略,那么对于较大的切片来说,现有的方法可以更好的节省内存。2.如果只选择每次系数为1.25的扩容策略,那么对于较小的切片来说扩容会很低效。3.之所以选择一个小于2的系数,在扩容时被释放的内存块会在下一次扩容时更容易被重新利用
func growslice(et *_type, old slice, cap int) slice {
...
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.cap < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
...
}
go1.18 及以上版本扩容机制如下
//1.18
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
const threshold = 256
if old.cap < threshold {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
// Transition from growing 2x for small slices
// to growing 1.25x for large slices. This formula
// gives a smooth-ish transition between the two.
newcap += (newcap + 3*threshold) / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}

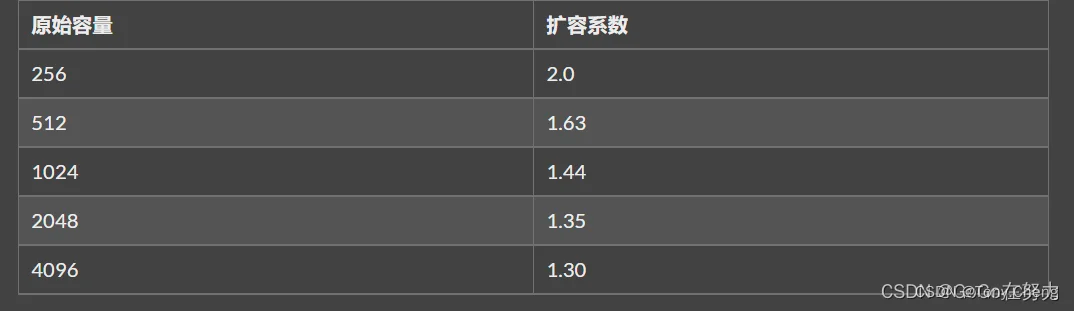
在1.18中,优化了切片扩容的策略2,让底层数组大小的增长更加平滑:通过减小阈值并固定增加一个常数,使得优化后的扩容的系数在阈值前后不再会出现从2到1.25的突变,该commit作者给出了几种原始容量下对应的“扩容系数”:
内存对齐,进一步调整newcaps
slice的扩容还与数据类型有关,当数据类型size为1字节,8字节,或者2的倍数时,会根据内存大小进行向上取整,之后返回新的扩容大小。
这是由于Go语言的内存管理模块返回给你需要的内存块,通常这些内存块都是预先申请好,并且被分为常用的规格,比如8,16, 32, 48, 64等。