文章目录
- 📚Plotly
- 🐇堆叠柱状图
- 🐇环形图
- 🐇散点图
- 🐇漏斗图
- 🐇桑基图
- 🐇金字塔图
- 🐇气泡图
- 🐇面积图
- ⭐️快速作图工具:plotly.express
- 🐇树形图
- 🐇旭日图
- 📚Pandas
- 📚Matplotlib
- 📚Seaborn
- 📚Pyecharts
📚Plotly
-
Plotly官网
-
各种可视化的官方例子
-
《Python 数据分析:基于 Plotly 的动态可视化绘图》 源代码
-
安装
# Windows 系统 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple plotly==4.14.2 # MacOS 系统 pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple plotly==4.14.2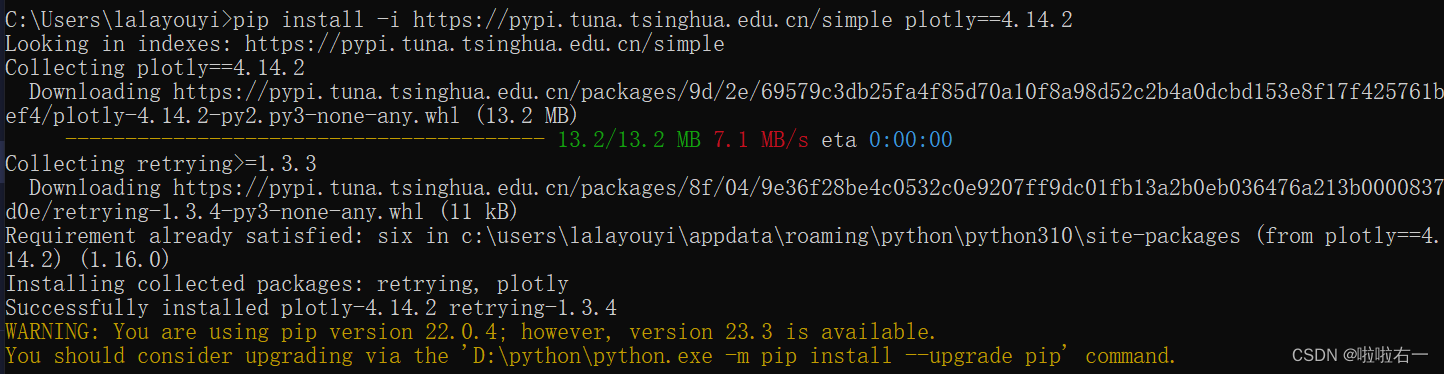
🐇堆叠柱状图
-
普通柱状图
# Spyder 编辑器加上下面两行代码 # import plotly.io as pio # pio.renderers.default = 'browser' from plotly.graph_objects import Figure from plotly.graph_objects import Bar months = ['1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月'] old_members = [1859, 3087, 3472, 2886, 2912, 2973, 3208, 3366, 3173, 2413, 2278, 2062] new_members = [420, 1141, 1256, 755, 743, 702, 730, 709, 711, 623, 560, 559] # 实例化一个空图表 figure = Figure() # 预览空图表 # figure.show() # 实例化柱形 trace trace1 = Bar(x=months, y=old_members, name='老会员') # 将 trace1 添加进空图表 figure 中 figure.add_trace(trace1) # 预览图表 figure.show()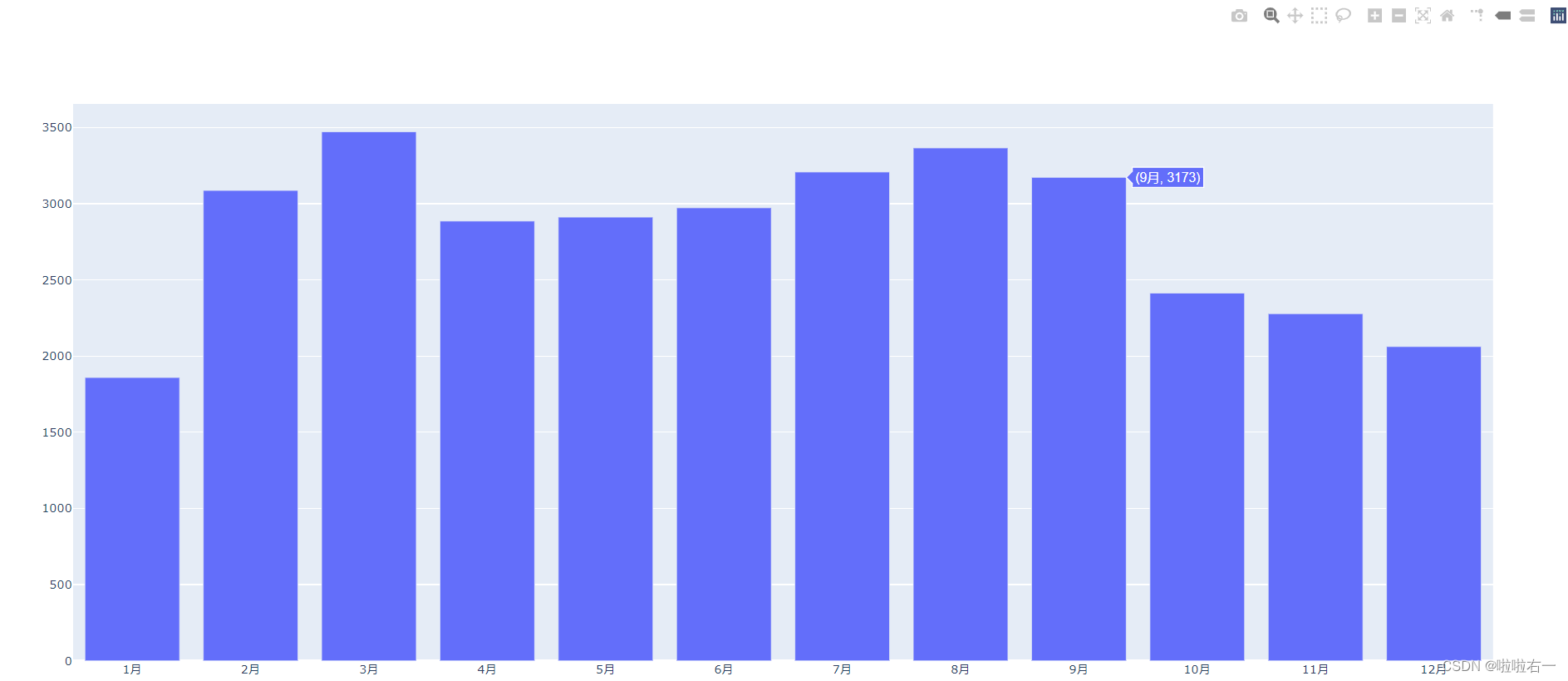

-
第一个是保存图像
- 如果要保存动态图,直接保存网页——另存为

- 如果要保存动态图,直接保存网页——另存为
-
第三个是拖动按钮
-
第四个选中可以局部放大
-
多列柱状图
# Spyder 编辑器加上下面两行代码 # import plotly.io as pio # pio.renderers.default = 'browser' from plotly.graph_objects import Figure from plotly.graph_objects import Bar months = ['1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月'] old_members = [1859, 3087, 3472, 2886, 2912, 2973, 3208, 3366, 3173, 2413, 2278, 2062] new_members = [420, 1141, 1256, 755, 743, 702, 730, 709, 711, 623, 560, 559] # 实例化一个空图表 figure = Figure() # 预览空图表 # figure.show() # 实例化柱形 trace trace1 = Bar(x=months, y=old_members, name='老会员') # 将 trace1 添加进空图表 figure 中 figure.add_trace(trace1) # 实例化柱形 trace trace2 = Bar(x=months, y=new_members, name='新会员') # 将 trace2 添加进 figure 中 figure.add_trace(trace2) # 预览图表 figure.show()
-
堆叠柱状图
- 添加多个柱形 trace 后,默认会以平行分组 (group) 的方式排列,需要我们多一步来调整。各个 trace 之间的位置关系属于图表 布局 (layout) 管辖范围,需要调用 figure 的
update_layout()方法来调整

from plotly.graph_objects import Figure, Bar # 新老会员数据 months = ['1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月'] old_members = [1859, 3087, 3472, 2886, 2912, 2973, 3208, 3366, 3173, 2413, 2278, 2062] new_members = [420, 1141, 1256, 755, 743, 702, 730, 709, 711, 623, 560, 559] # 创建空白图表 figure = Figure() # 实例化第一个柱形 trace trace1 = Bar(x=months, y=old_members, name='老会员') # 将 trace1 添加进空图表 figure 中 figure.add_trace(trace1) # 实例化第二个柱形 trace trace2 = Bar(x=months, y=new_members, name='新会员') # 将 trace2 添加进 figure 中 figure.add_trace(trace2) # 调整柱形 trace 之间的排列方式 figure.update_layout(barmode="stack") # 预览图表 figure.show()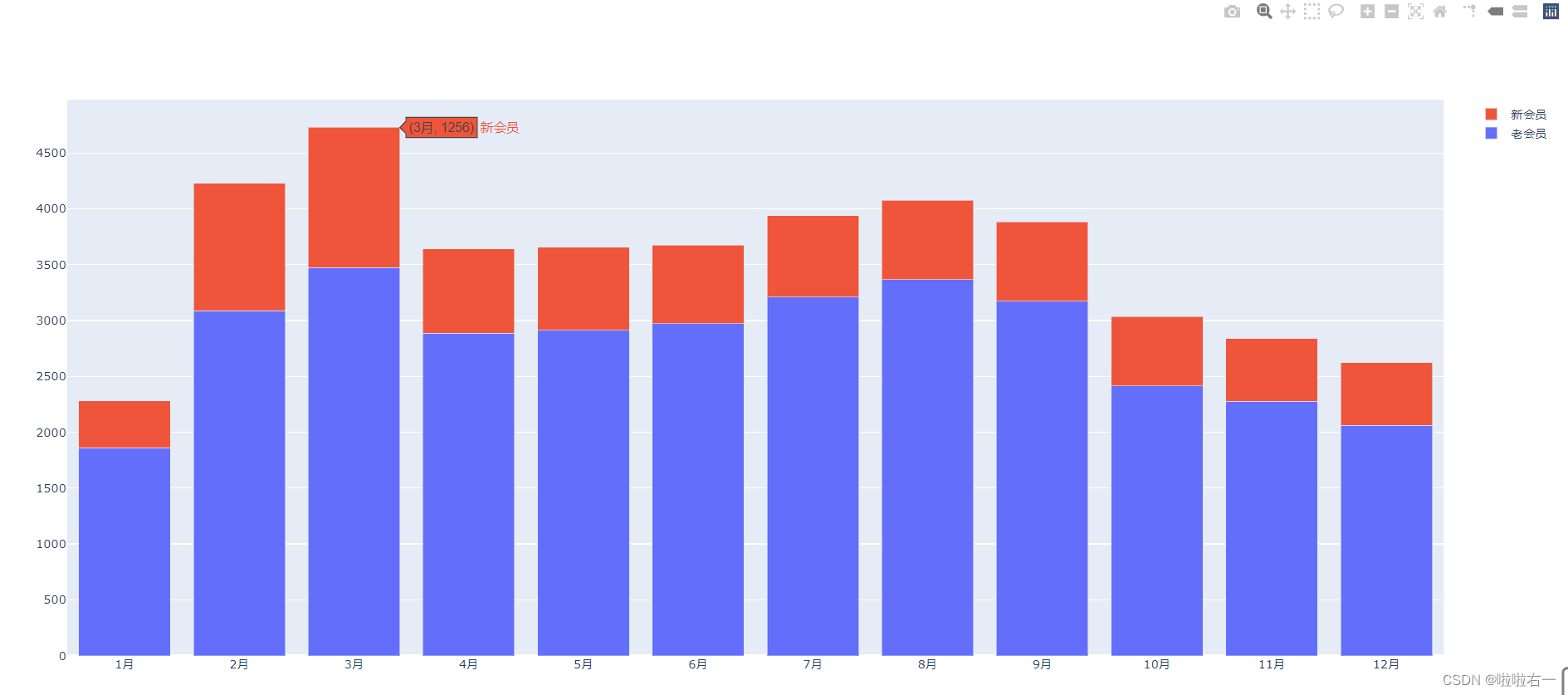
- 添加多个柱形 trace 后,默认会以平行分组 (group) 的方式排列,需要我们多一步来调整。各个 trace 之间的位置关系属于图表 布局 (layout) 管辖范围,需要调用 figure 的
- 柱形宽度:
figure.update_traces(width=0.4)
- 修改颜色,CSS颜色
# 更新老会员的 trace 的颜色 figure.update_traces(selector={'name': '老会员'}, marker_color='CadetBlue') # 更新新会员的 trace 的颜色 figure.update_traces(selector={'name': '新会员'}, marker_color='MediumAquamarine')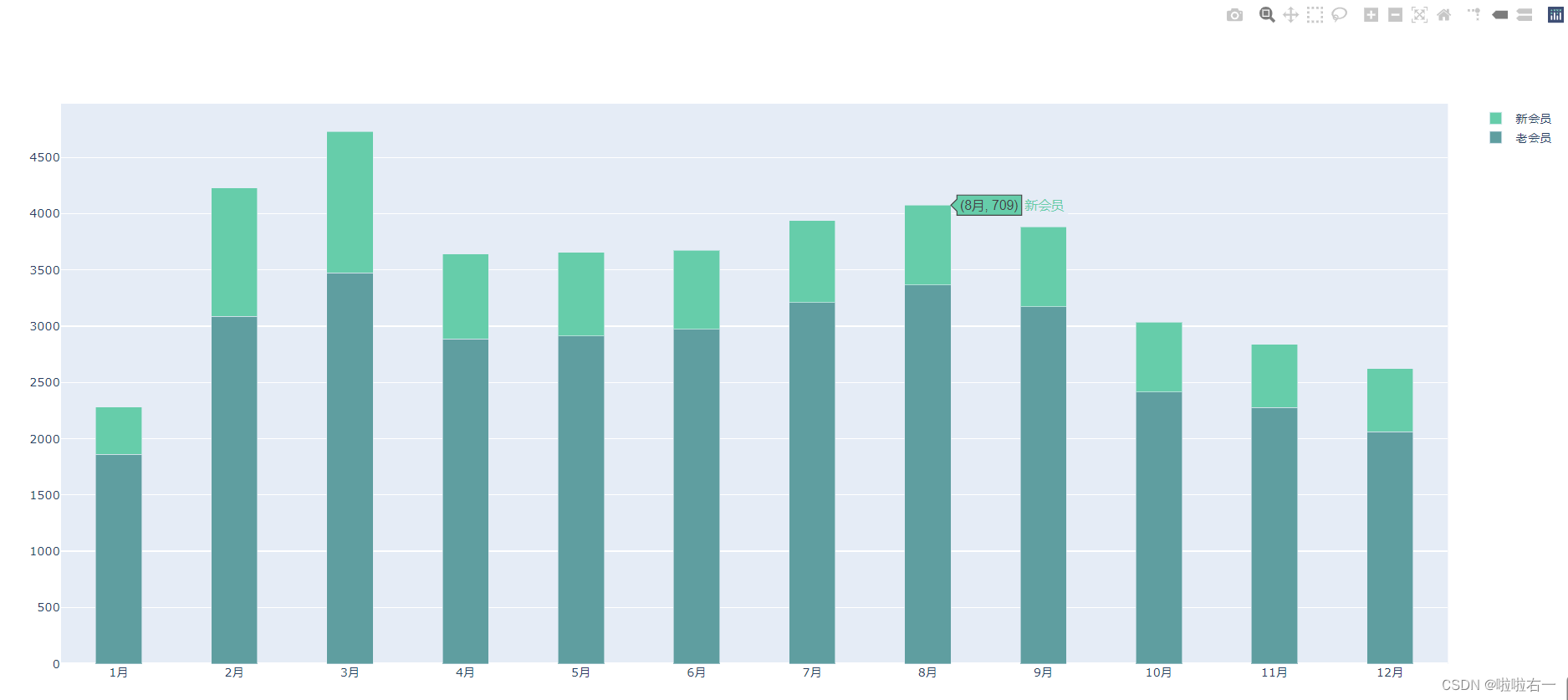
-
调整布局:在模块
plotly.graph_objects里,还有一个子模块layout,专门提供布局需要的组件类,包括 标题 (Title)、图例 (Legend)、x 轴 (XAxis)、y 轴 (YAxis) 等,这些组件都可以在实例化后用在update_layout()方法中。
# 引入 layout 子模块 from plotly.graph_objects import layout # x=0.5以水平居中 fig_title = layout.Title(text='健身俱乐部每月客流人数', font=dict(size=20,color='CadetBlue'), x=0.5) # 应用 figure.update_layout(title=fig_title)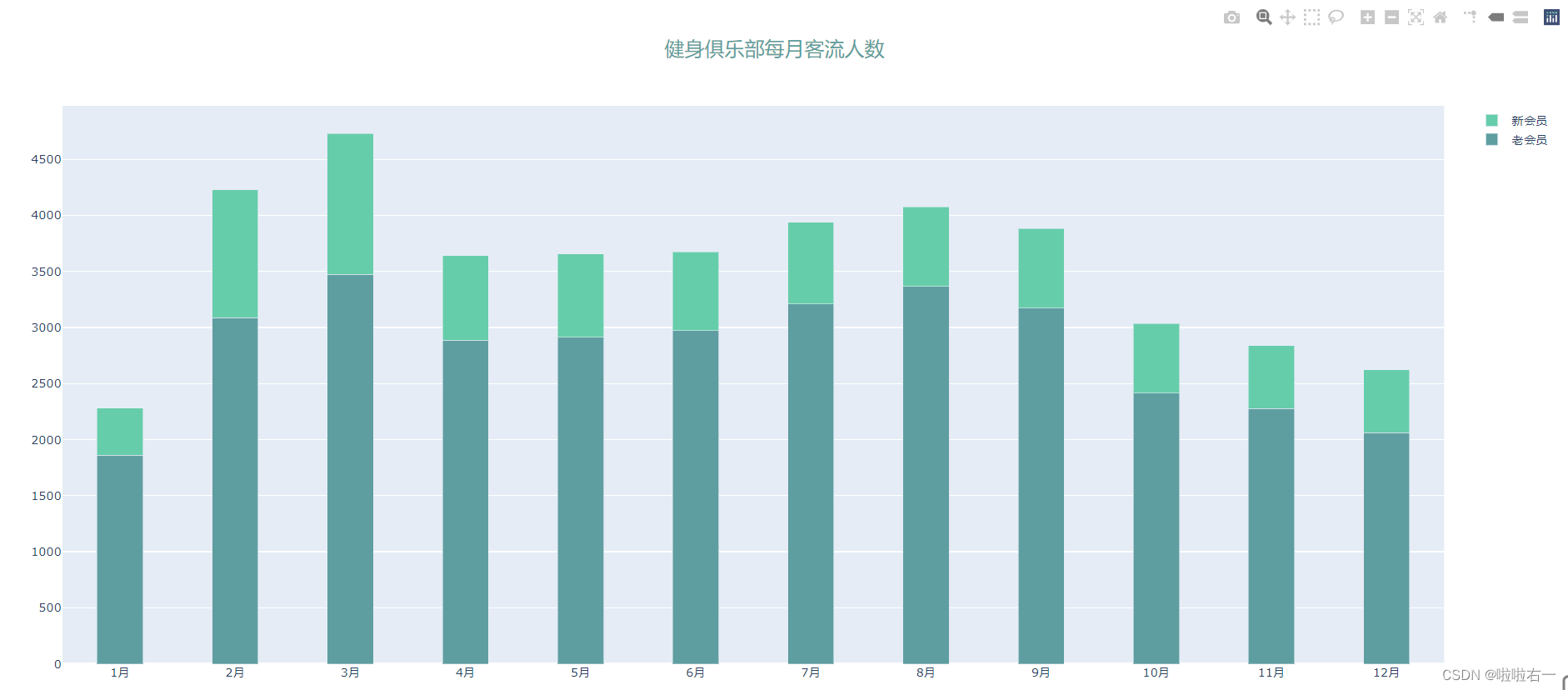
-
最终代码梳理
- 准备数据;
- 将数据转化为 trace 加入图表;
- 调整 trace 样式;
- 调整整体布局
# 导入必要的模块 from plotly.graph_objects import Bar, Figure, layout # 准备数据 months = ['1月', '2月', '3月', '4月', '5月', '6月', '7月', '8月', '9月', '10月', '11月', '12月'] old_members = [1859, 3087, 3472, 2886, 2912, 2973, 3208, 3366, 3173, 2413, 2278, 2062] new_members = [420, 1141, 1256, 755, 743, 702, 730, 709, 711, 623, 560, 559] # 生成空图表 figure = Figure() # 实例化老会员的柱形 trace trace1 = Bar(x=months, y=old_members, name='老会员') # 实例化新会员的柱形 trace trace2 = Bar(x=months, y=new_members, name='新会员') # 将两个 trace 添加进 figure 中 figure.add_trace(trace1) figure.add_trace(trace2) # 调整 trace 的宽度和颜色 figure.update_traces(width=0.4) figure.update_traces(selector=dict(name='老会员'), marker_color='CadetBlue') figure.update_traces(selector=dict(name='新会员'), marker_color='MediumAquamarine') # 实例化一个图表标题 fig_title = layout.Title(text='健身俱乐部每月客流人数', font=dict(size=20, color='CadetBlue'), x=0.5) # 将柱形 trace 排列方式和标题应用到布局中 figure.update_layout(barmode='stack', title=fig_title) figure.show()
- plotly动态功能补充:点击图例,就能隐藏对应数据
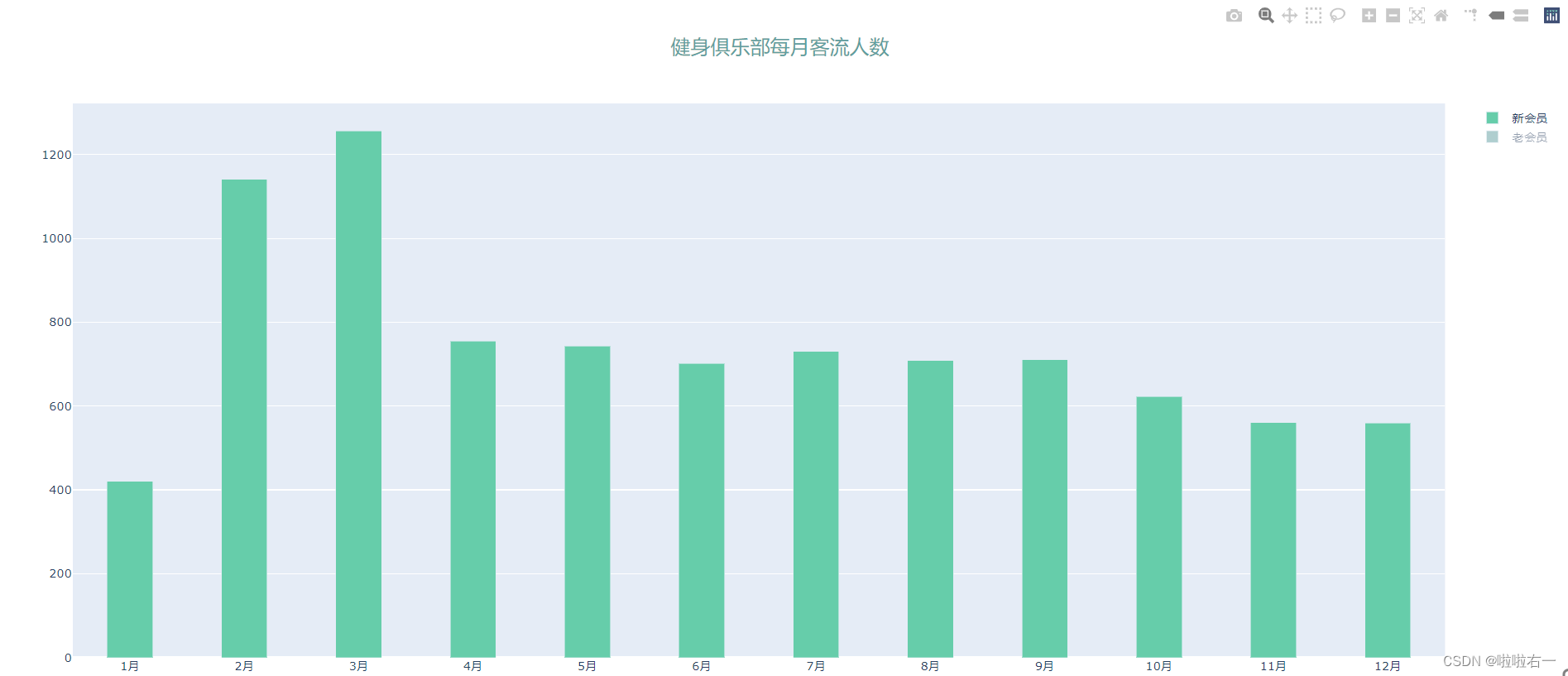
- 堆叠柱状图用途扩展
- 堆叠柱状图在对比不同类别数据的数值大小的同时,也能对比每一类别数据中,子类别的构成及大小。
- 历时性分析,查看波动及结构的变化
- 堆叠柱状图在对比不同类别数据的数值大小的同时,也能对比每一类别数据中,子类别的构成及大小。
🐇环形图
-
一个基本的饼图
from plotly.graph_objects import Pie, Figure, layout # 用于绘图的源数据 industry = ['互联网', '学生', '教育', '金融', '其他'] number = [10281, 5811, 4871, 3305, 2227] # 初始化一个空白图表 fig = Figure() # 将源数据转换为数据图形 trace_pie = Pie(labels=industry, values=number) # 将数据图形添加到图表中 fig.add_trace(trace_pie) # 添加图表标题 fig.update_layout(title=layout.Title(text='用户行业分布')) # 展示生成的图表 fig.show()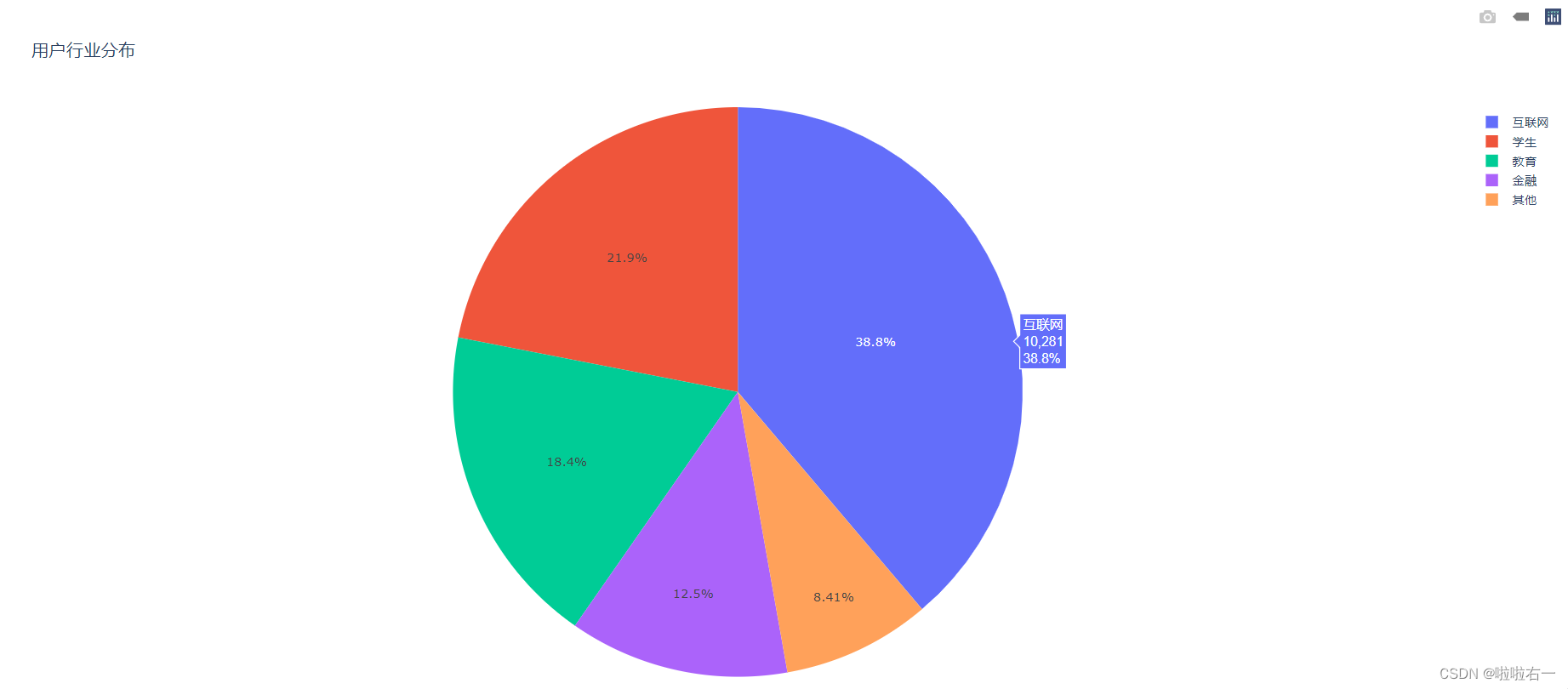
-
饼转圆环 :
hole参数定为 0 到 1 之间的数字,默认为 0,也就是不挖洞。 hole 的值为 1 表示全部挖空,0.5 就是挖一半。from plotly.graph_objects import Pie, Figure, layout # 用于绘图的源数据 industry = ['互联网', '学生', '教育', '金融', '其他'] number = [10281, 5811, 4871, 3305, 2227] # 初始化一个空白图表 fig = Figure() # 将源数据转换为数据图形 trace_pie = Pie(labels=industry, values=number, hole=0.5) # 将数据图形添加到图表中 fig.add_trace(trace_pie) # 添加图表标题 fig.update_layout(title=layout.Title(text='用户行业分布')) # 展示生成的图表 fig.show()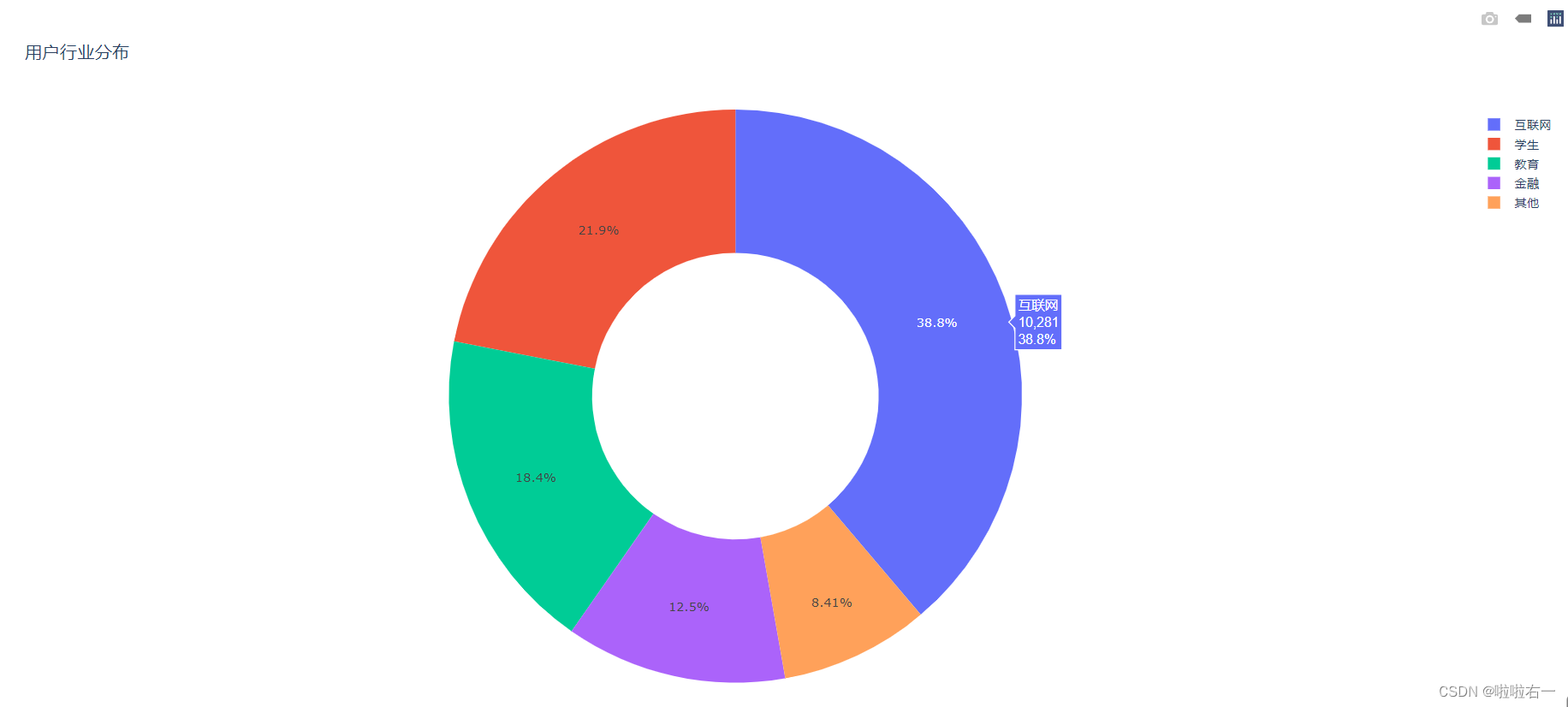
-
圆弧突出展示
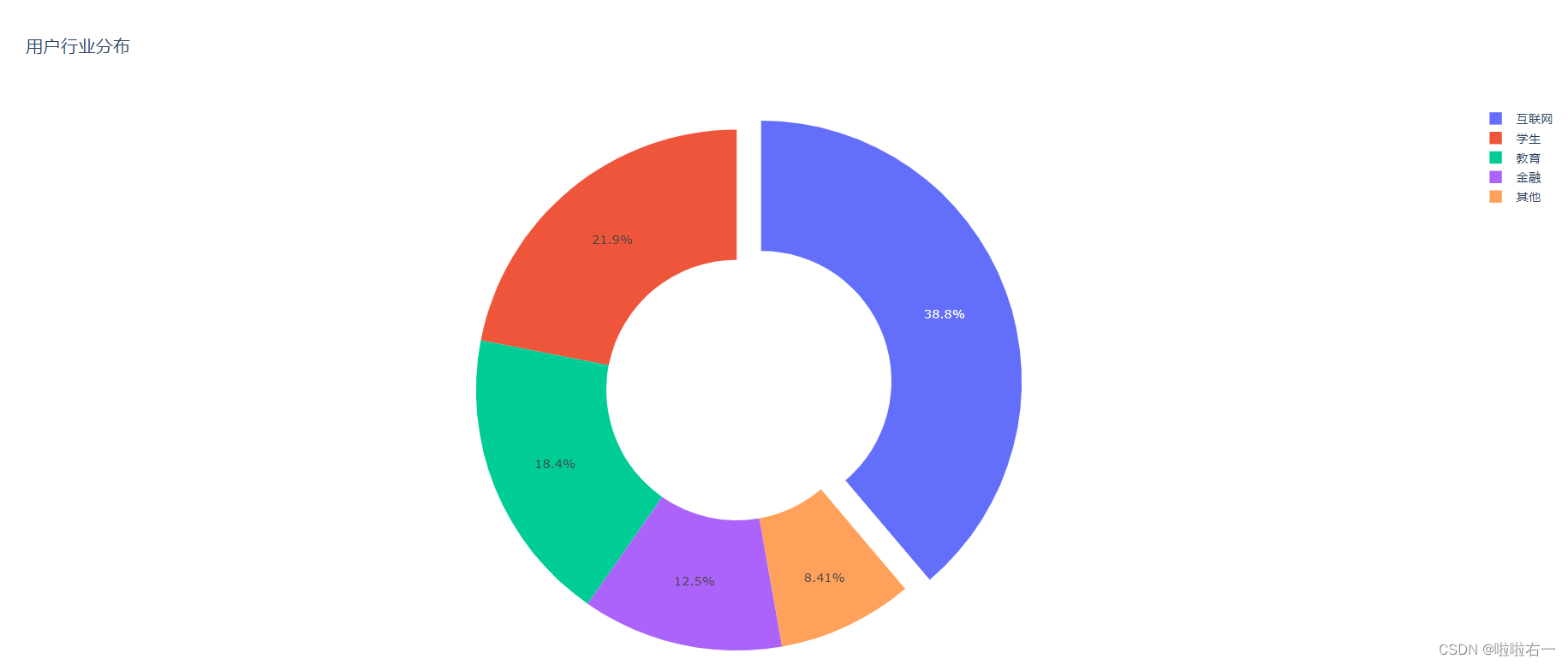
- 创建 trace 时,将参数 pull 的值设为列表 [0.1, 0, 0],意思就是,将 labels 中的第一个扇区向外拖曳 0.1 倍半径的距离。
- pull 参数要求的值是一个列表,且列表元素大于等于 0,小于等于 1。这个列表与标签 labels 获得的列表对应。修改列表中的元素,使之不为 0,就能拖出对应位置的扇区。
- 列表的长度可以比 labels 列表长,Plotly 会将长于 labels 的元素自动切割;也可以更短,Plotly 会按照值为 0 自动补全,简单概括,“多退少补”。
- 上文代码添加:
fig.update_traces(pull=[0.1])
-
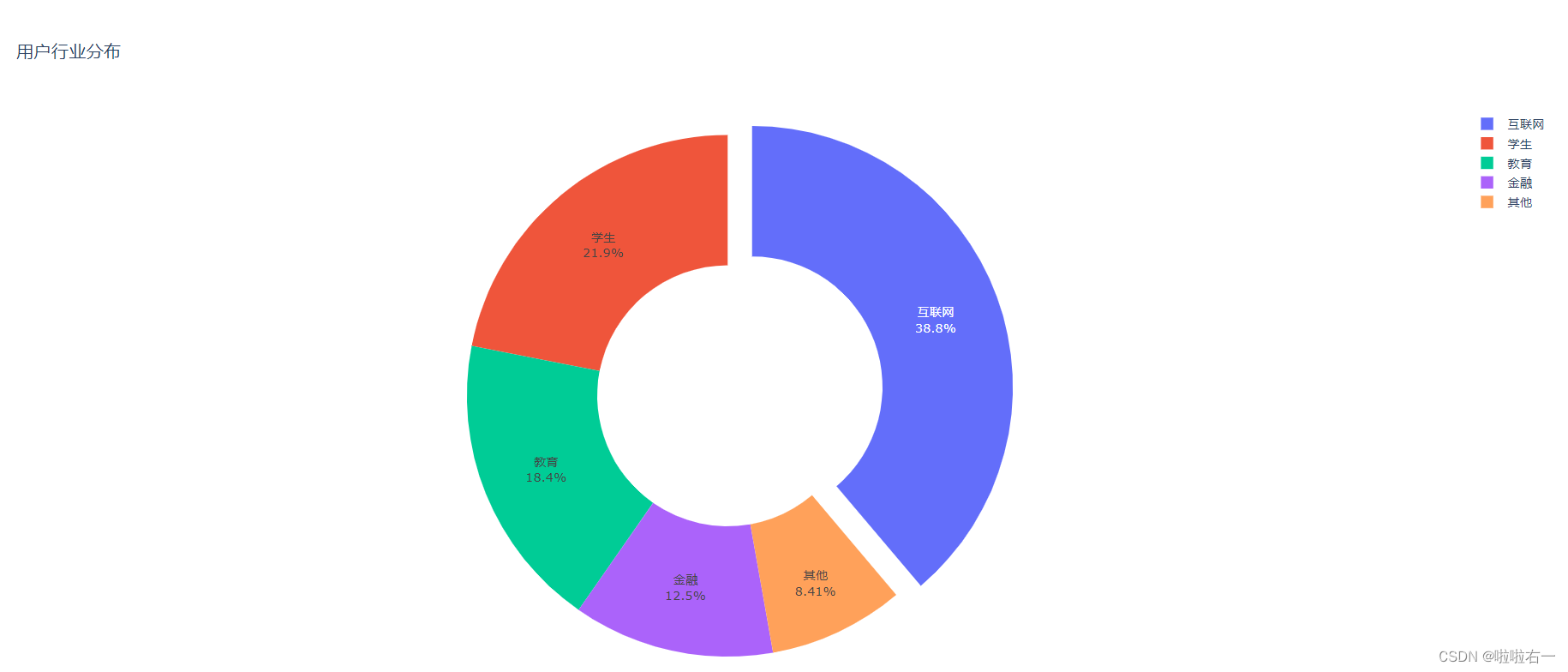
设置文本信息
- textinfo 参数可以指定显示的文本信息包含哪些内容。
- textinfo 要求的值是一个字符串。这个字符串可以是
label(标签),text(附加文本),value(值)和percent(百分比)的任意组合,用加号 + 连接。 - 和 pull 参数一样,text 参数对获得的列表同样是“多退少补”的。
- 以上代码加上:
fig.update_traces(textinfo='label+percent')
-
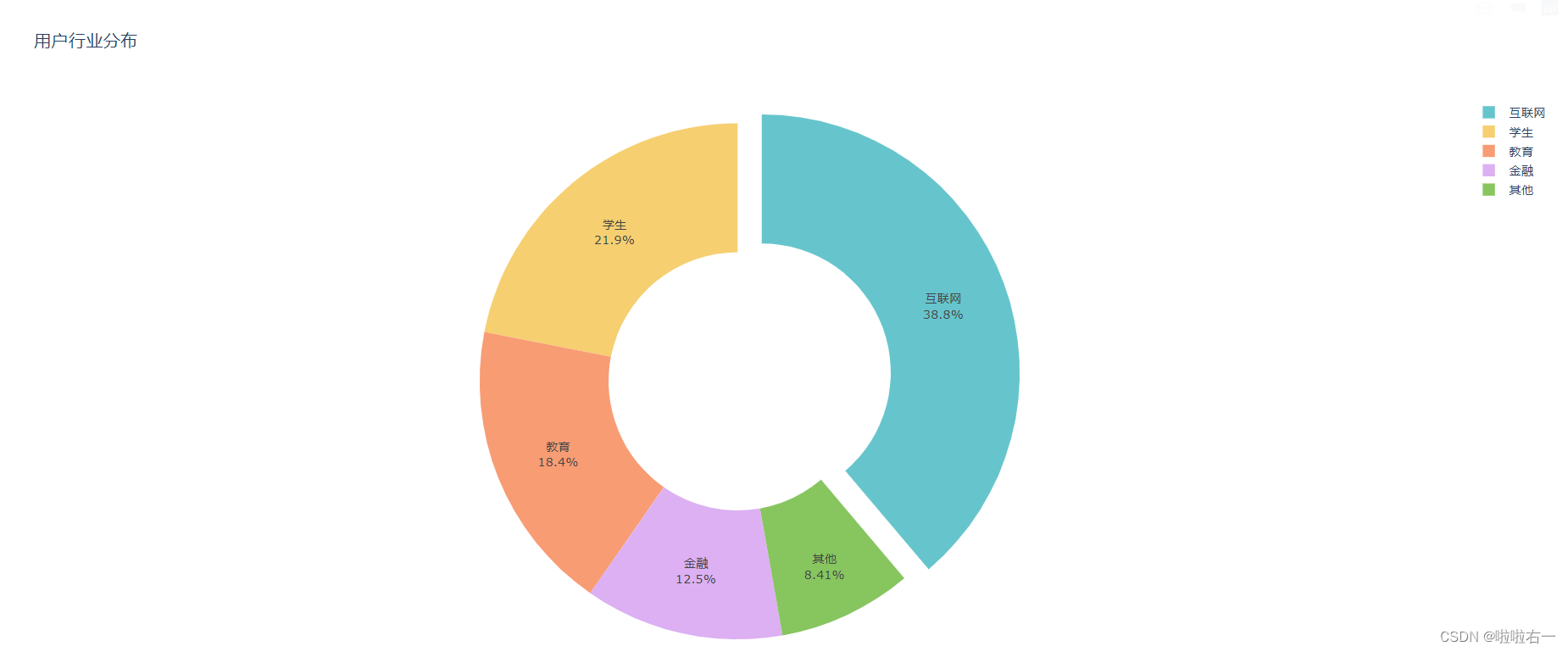
调整trace配色
- marker_colors 要求的值是一个颜色值列表,该列表会自动与标签 labels 一一对应,原理和 pull 参数以及 text 参数类似。
- Plotly 内置了配色方案,保存在 qualitative 和 sequential 这两个子模块里。qualitative 模块中保存的是 撞色方案,sequential 模块中是 渐变色方案。

- 导入库后,以上代码加上:
fig.update_traces(marker_colors=qualitative.Pastel)
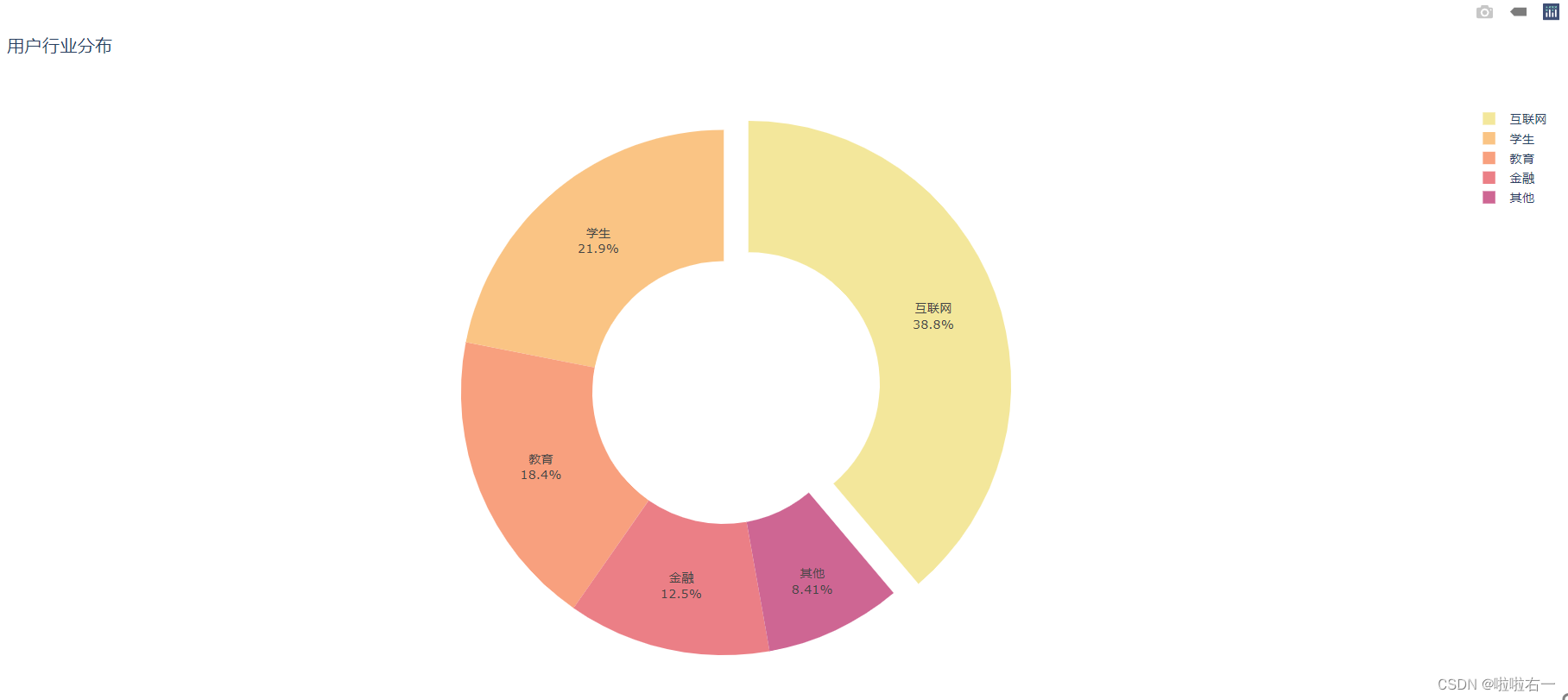
- 渐变色:
fig.update_traces(marker_colors=sequential.Sunset)
-
更改背景颜色:在 update_layout() 方法中,将 paper_bgcolor 的值指定为某个 CSS 颜色名称,即可设置图表的背景色。以上代码加上:
fig.update_layout(paper_bgcolor = 'rgb(229,249,229)')
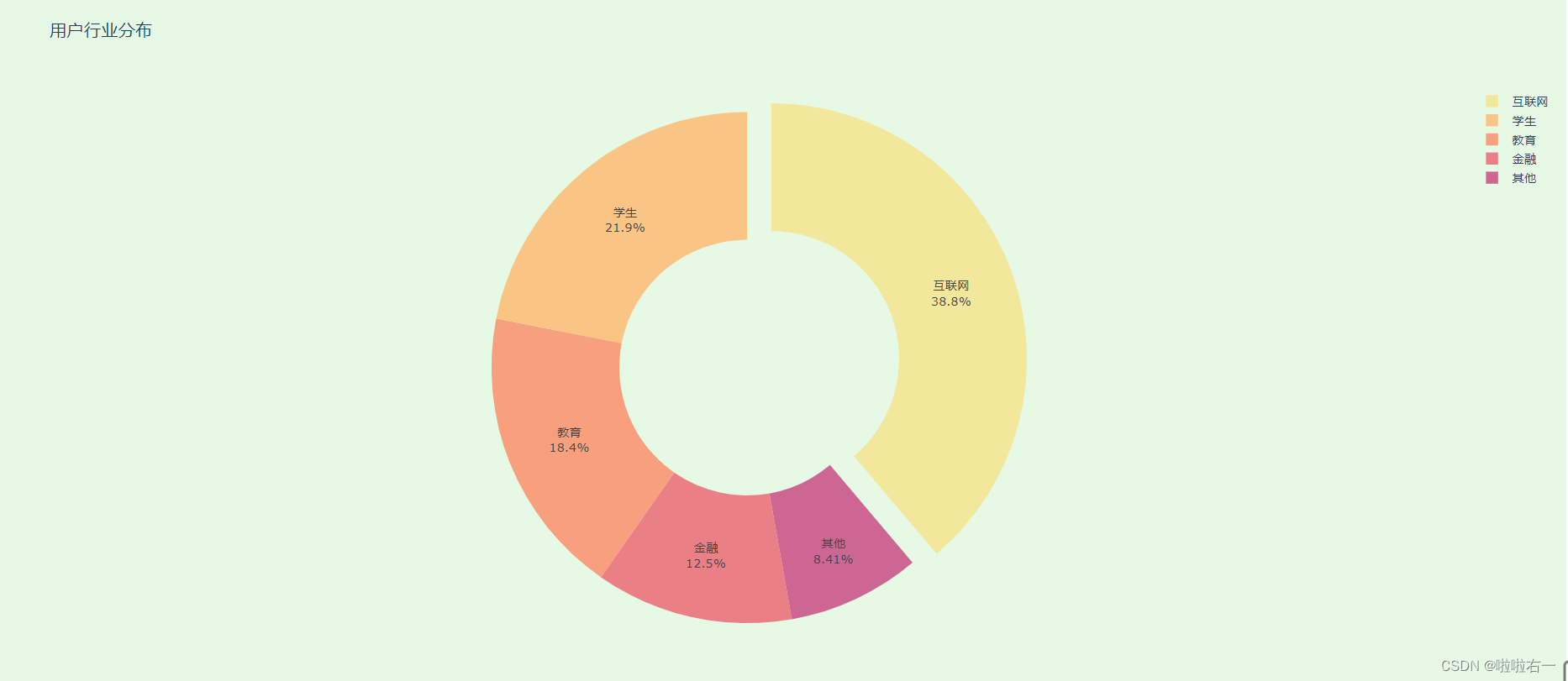
- 最终代码梳理
from plotly.graph_objects import Pie, Figure, layout from plotly.colors import qualitative # 用于绘图的源数据 industry = ['互联网', '学生', '教育', '金融', '其他'] number = [10281, 5811, 4871, 3305, 2227] # 初始化一个空白图表 fig_donut = Figure() # 创建环形图形式的数据图形 trace_donut = Pie(labels=industry, values=number, hole=0.5, pull=[0.1], textinfo='label+percent', marker_colors=qualitative.Pastel) # 将数据图形添加到图表中 fig_donut.add_trace(trace_donut) # 调整图表布局 fig_donut.update_layout(paper_bgcolor='rgb(229,249,229)', title=layout.Title(text='用户行业分布')) # 展示生成的图表 fig_donut.show()
🐇散点图
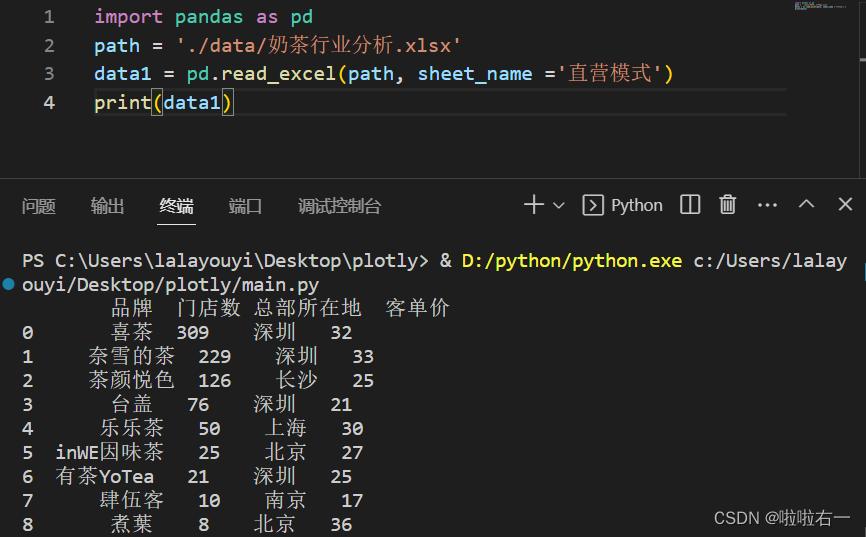
所用数据集存本地
-
导入数据
import pandas as pd path = './data/奶茶行业分析.xlsx' data1 = pd.read_excel(path, sheet_name ='直营模式') data2 = pd.read_excel(path, sheet_name ='加盟模式') brand1 = data1['品牌'] shop_number1 = data1['门店数'] avrg_price1 = data1['客单价'] brand2 = data2['品牌'] shop_number2 = data2['门店数'] avrg_price2 = data2['客单价'] -
散点 trace,从 plotly.graph_objects 中导入 Scatter 类。必要参数和柱形 trace 类似:x,y 和 name,另外还有一个特有的 mode 参数,用来说明特定的模式。

from plotly.graph_objects import Figure, Scatter figure_demo = Figure() # 设定散点模式的 trace trace_m = Scatter(x=[1, 2, 3, 4, 5], y=[6, 7, 6, 7, 6], name='散点模式', mode='markers') # 设定折线模式的 trace trace_l = Scatter(x=[1, 2, 3, 4, 5], y=[4, 5, 4, 5, 4], name='折线模式', mode='lines') # 设定点线模式的 trace trace_ml = Scatter(x=[1, 2, 3, 4, 5], y=[2, 3, 2, 3, 2], name='点线模式', mode='markers+lines') # 将三个不同模式的 trace 加入图表 figure_demo.add_traces(trace_m) figure_demo.add_traces(trace_l) figure_demo.add_traces(trace_ml) figure_demo.show()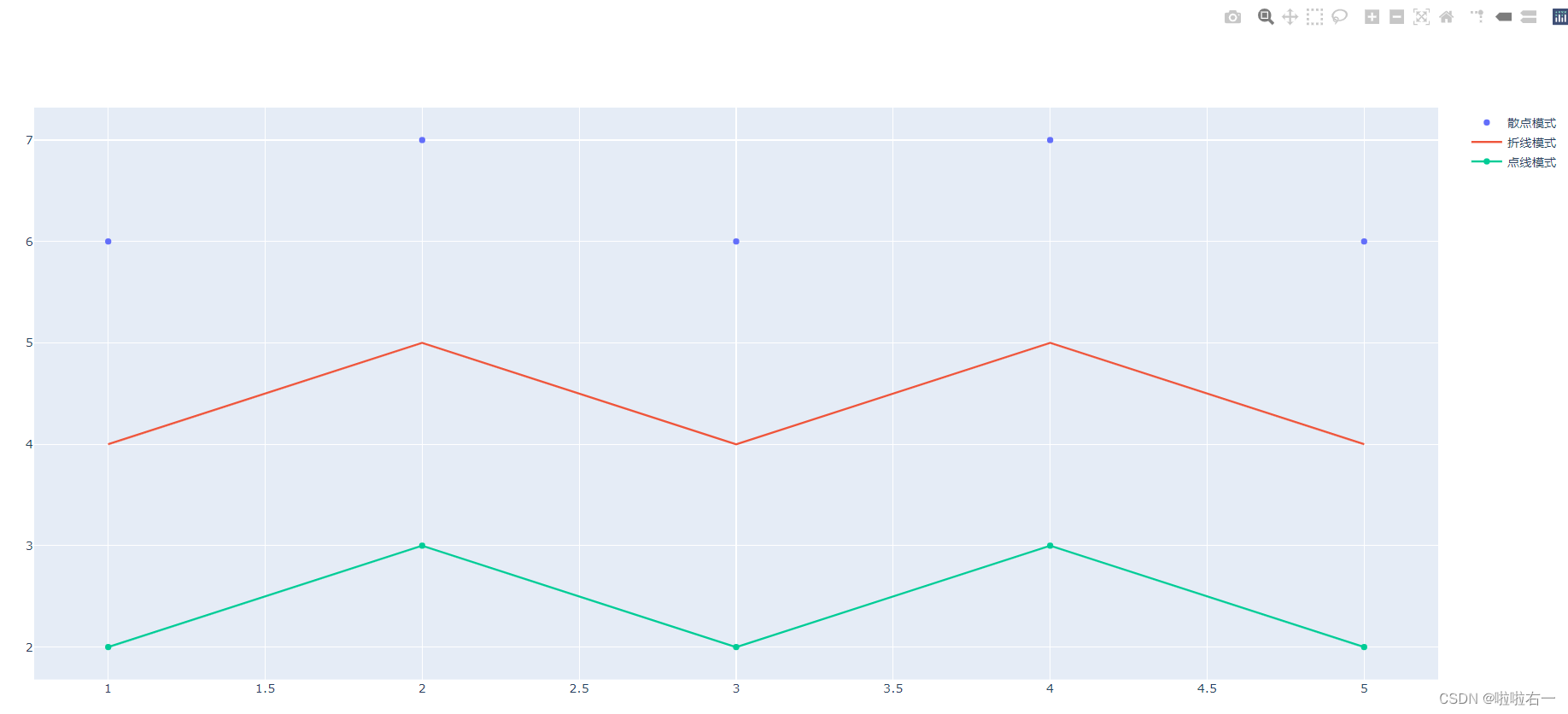
-
本地数据散点图
import pandas as pd from plotly.graph_objects import Figure,Scatter path = './data/奶茶行业分析.xlsx' data1 = pd.read_excel(path, sheet_name ='直营模式') data2 = pd.read_excel(path, sheet_name ='加盟模式') brand1 = data1['品牌'] shop_number1 = data1['门店数'] avrg_price1 = data1['客单价'] brand2 = data2['品牌'] shop_number2 = data2['门店数'] avrg_price2 = data2['客单价'] # 生成空图表 fig_bubbletea = Figure() # 生成直营模式的散点 trace trace1 = Scatter(x=shop_number1, y=avrg_price1, name='直营模式', mode='markers', # 设置散点颜色 marker_color='Chocolate', # 设置散点大小 marker_size=8, # 设置附加文本 text=brand1) # 生成加盟模式的散点 trace trace2 = Scatter(x=shop_number2, y=avrg_price2, name='加盟模式', mode='markers', # 设置散点颜色 marker_color='DarkCyan', # 设置散点大小 marker_size=8, # 设置附加文本 text=brand2) # 将两个 trace 加入图表 fig_bubbletea.add_traces(trace1) fig_bubbletea.add_traces(trace2) fig_bubbletea.update_traces(hoverinfo='x+y+text') fig_bubbletea.show()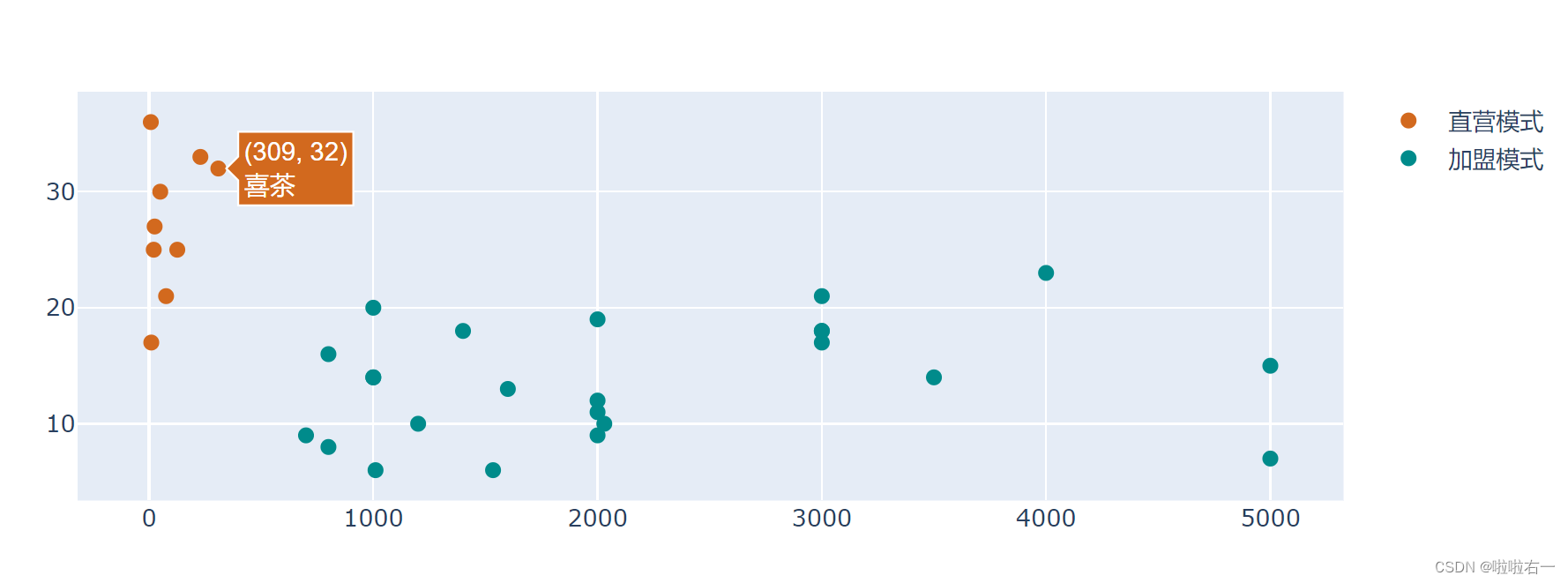
-
布局调整
import pandas as pd from plotly.graph_objects import Figure,Scatter,layout path = './data/奶茶行业分析.xlsx' data1 = pd.read_excel(path, sheet_name ='直营模式') data2 = pd.read_excel(path, sheet_name ='加盟模式') brand1 = data1['品牌'] shop_number1 = data1['门店数'] avrg_price1 = data1['客单价'] brand2 = data2['品牌'] shop_number2 = data2['门店数'] avrg_price2 = data2['客单价'] # 生成空图表 fig_bubbletea = Figure() # 生成直营模式的散点 trace trace1 = Scatter(x=shop_number1, y=avrg_price1, name='直营模式', mode='markers', # 设置散点颜色 marker_color='Chocolate', # 设置散点大小 marker_size=8, # 设置附加文本 text=brand1) # 生成加盟模式的散点 trace trace2 = Scatter(x=shop_number2, y=avrg_price2, name='加盟模式', mode='markers', # 设置散点颜色 marker_color='DarkCyan', # 设置散点大小 marker_size=8, # 设置附加文本 text=brand2) # 将两个 trace 加入图表 fig_bubbletea.add_traces(trace1) fig_bubbletea.add_traces(trace2) # 改变悬浮标签显示内容 fig_bubbletea.update_traces(hoverinfo='x+y+text') fig_title = layout.Title(text='全国奶茶品牌概览', font=dict(size=20), x=0.5) fig_xaxis = layout.XAxis(title=dict(text='门店数', font=dict(size=15))) fig_yaxis = layout.YAxis(title=dict(text='客单价(元)', font=dict(size=15))) fig_bubbletea.update_layout(title=fig_title, xaxis=fig_xaxis, yaxis=fig_yaxis) fig_bubbletea.show()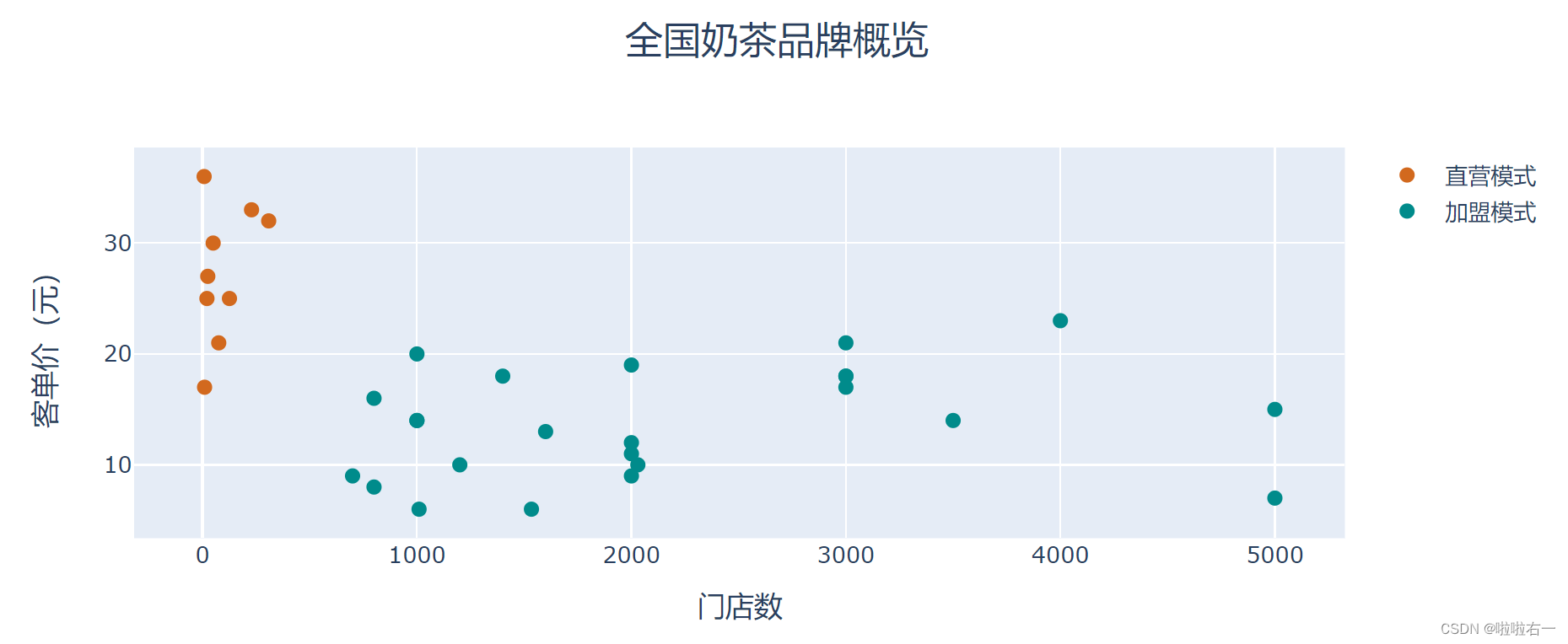
-
最终代码梳理
import pandas as pd from plotly.graph_objects import Figure,Scatter,layout path = './data/奶茶行业分析.xlsx' data1 = pd.read_excel(path, sheet_name ='直营模式') data2 = pd.read_excel(path, sheet_name ='加盟模式') # 构造直营模式数据:品牌、门店数和客单价 brand1 = data1['品牌'] shop_number1 = data1['门店数'] avrg_price1 = data1['客单价'] # 构造加盟模式数据:品牌、门店数和客单价 brand2 = data2['品牌'] shop_number2 = data2['门店数'] avrg_price2 = data2['客单价'] # 生成空图表 fig_bubbletea = Figure() # 生成直营模式的散点 trace trace1 = Scatter(x=shop_number1, y=avrg_price1, name='直营模式', mode='markers', # 设置散点颜色 marker_color='Pink', # 设置散点大小 marker_size=6, # 设置附加文本 text=brand1) # 生成加盟模式的散点 trace trace2 = Scatter(x=shop_number2, y=avrg_price2, name='加盟模式', mode='markers', # 设置散点颜色 marker_color='SkyBlue', # 设置散点大小 marker_size=6, # 设置附加文本 text=brand2) # 将两个 trace 加入图表 fig_bubbletea.add_traces(trace1) fig_bubbletea.add_traces(trace2) # 改变悬浮标签显示内容 fig_bubbletea.update_traces(hoverinfo='x+y+text') # 实例化一个标题,设置内容和字体,以及水平居中 fig_title = layout.Title(text='全国奶茶品牌概览', font=dict(size=20), x=0.5) # 实例化一个 x 轴,设置轴标题内容和字体 fig_xaxis = layout.XAxis( title=dict( text='门店数',font=dict(size=15) ) ) # 实例化一个 y 轴,设置轴标题内容和字体 fig_yaxis = layout.YAxis( title=dict( text='客单价(元)', font=dict(size=15) ) ) # 将三个实例化的组件添加进布局中 fig_bubbletea.update_layout(title=fig_title, xaxis=fig_xaxis, yaxis=fig_yaxis) fig_bubbletea.show()
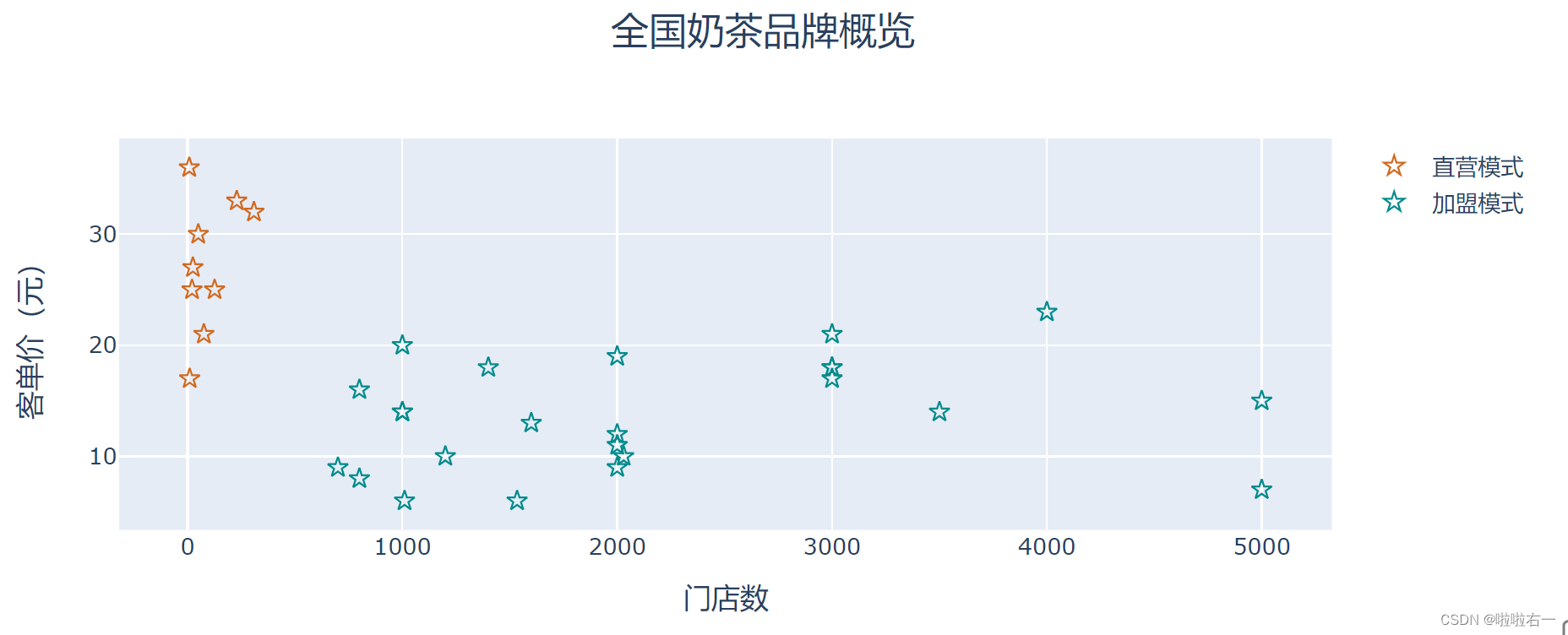
- 我们可以定制散点的形状,在实例化散点 trace 时,多传入一个参数
marker_symbol='star-open'(散点形状),其中 ‘star-open’ 代表的就是空心五角星。
🐇漏斗图
某售房广告从曝光到购买——漏斗图:关注转化率
- 访问率(访问人数/曝光人数):看到广告的消费者中,有百分之多少访问了商品详情页;
- 咨询率(咨询人数/访问人数):访问商品详情页的消费者中,有百分之多少发起咨询;
- 留电率(留电人数/咨询人数):咨询客服的消费者中,有百分之多少留下了联系方式;
- 成单率(购买人数/留电人数):留电的消费者中,有百分之多少完成购买。
- 一个基本的漏斗图
from plotly.graph_objects import Figure, Funnel, layout link = ['曝光', '访问', '咨询', '留电', '购买'] number = [15000, 3150, 1890, 945, 142] # 初始化一个空白图表 fig_funnel = Figure() # 创建漏斗图形式的数据图形 trace_funnel = Funnel(x=number, y=link) # 将数据图形添加到空白图表 fig_funnel.add_trace(trace_funnel) # 添加图表标题 fig_funnel.update_layout(title=layout.Title(text='营销转化漏斗')) # 展示生成的图表 fig_funnel.show()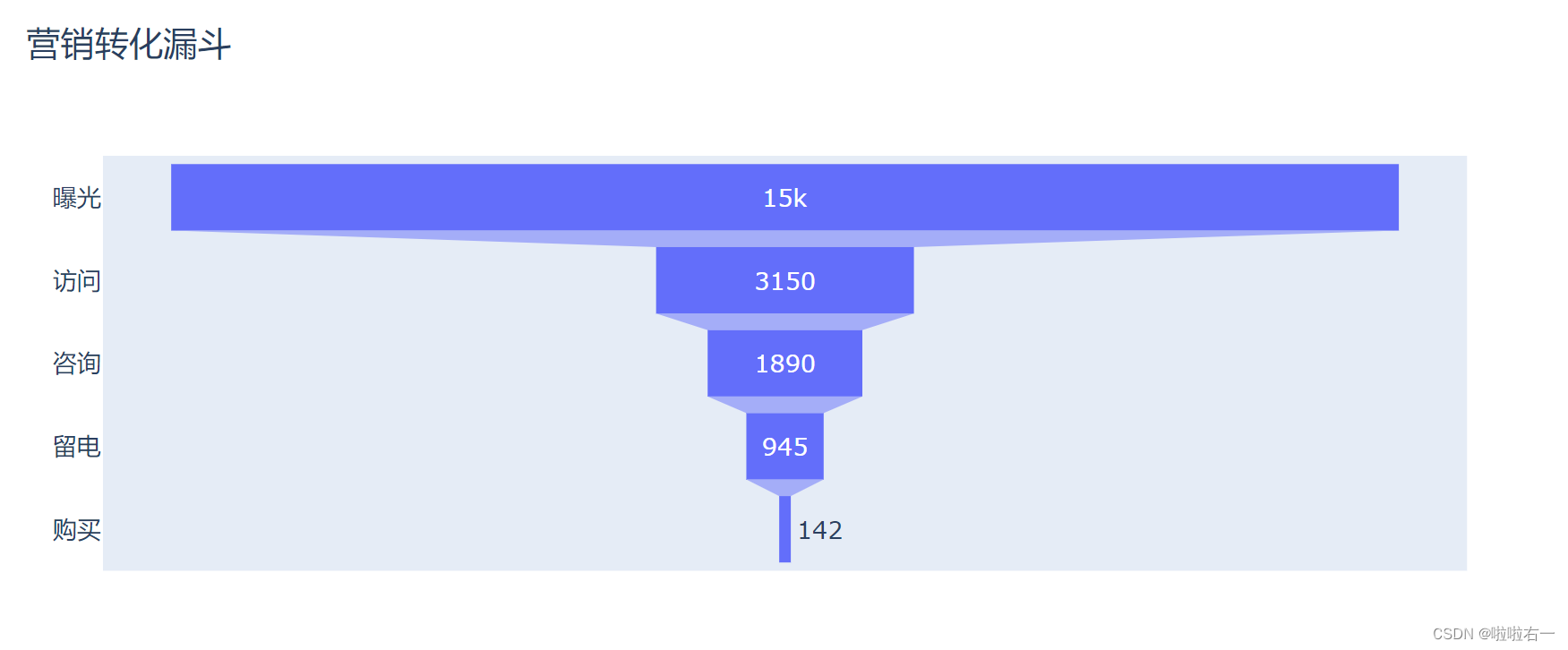
- 优化:
- 在漏斗的文本信息中,展示到这一步为止总共转化了百分之多少的用户;
- 在悬浮标签中,展示从上一环节到当前环节的转化率,鼠标移动到某一区块上即可看到这一步的详细信息。
-
文本信息设置:漏斗图的文本信息比较特别,除了支持添加 ‘label’(环节名称),‘text’(附加文本)和 ‘value’(数值)等预设信息的组合,还支持三种不同的百分比。
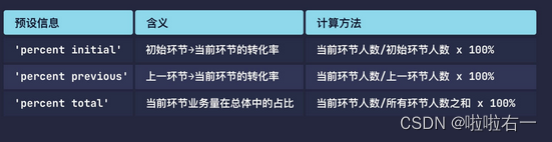
from plotly.graph_objects import Figure, Funnel, layout link = ['曝光', '访问', '咨询', '留电', '购买'] number = [15000, 3150, 1890, 945, 142] # 初始化一个空白图表 fig_funnel = Figure() # 创建漏斗图形式的数据图形 trace_funnel = Funnel(x=number, y=link) # 将数据图形添加到空白图表 fig_funnel.add_trace(trace_funnel) # 添加图表标题 fig_funnel.update_layout(title=layout.Title(text='营销转化漏斗')) # 文本信息设置 fig_funnel.update_traces(textinfo='value+percent initial') # 展示生成的图表 fig_funnel.show()
-
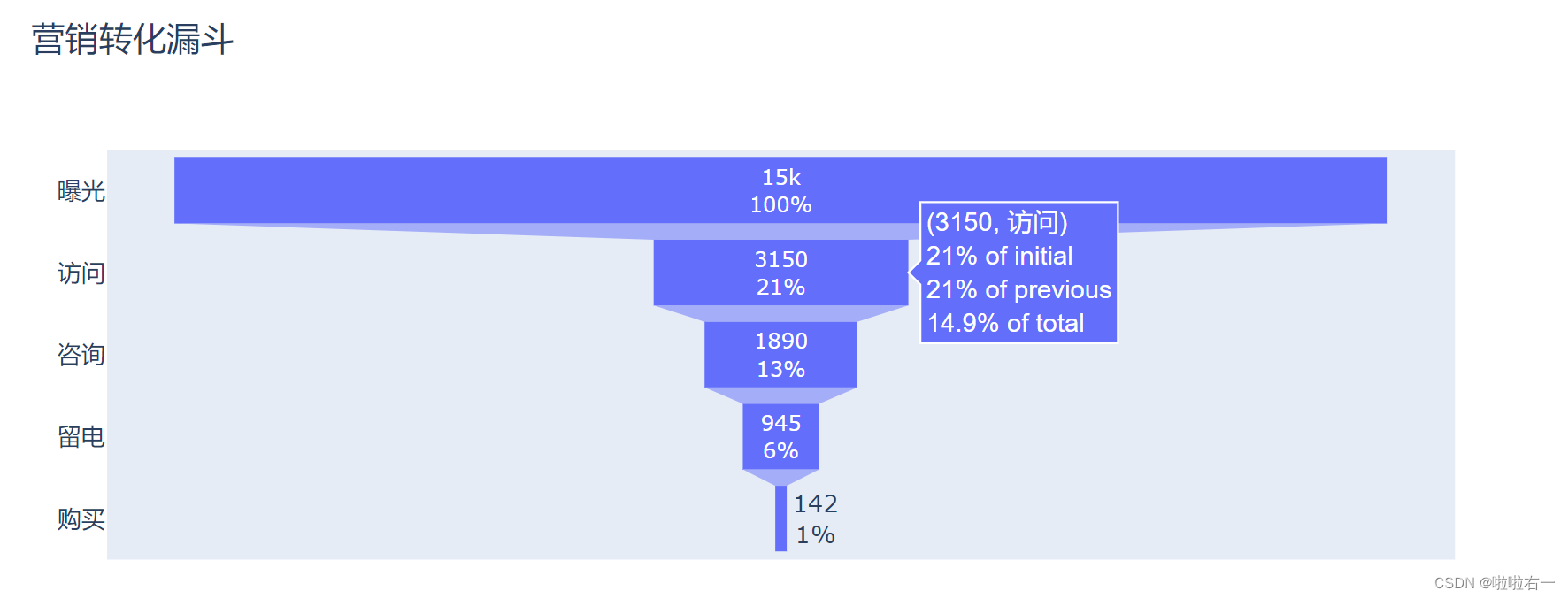
悬浮标签设置
from plotly.graph_objects import Figure, Funnel, layout link = ['曝光', '访问', '咨询', '留电', '购买'] number = [15000, 3150, 1890, 945, 142] # 初始化一个空白图表 fig_funnel = Figure() # 创建漏斗图形式的数据图形 trace_funnel = Funnel(x=number, y=link) # 将数据图形添加到空白图表 fig_funnel.add_trace(trace_funnel) # 添加图表标题 fig_funnel.update_layout(title=layout.Title(text='营销转化漏斗')) # 文本信息设置 fig_funnel.update_traces(textinfo='value+percent initial') # 悬浮标签设置 fig_funnel.update_traces(text=['总体', '访问率', '咨询率', '留电率', '成单率'], hoverinfo='text+percent previous') # 展示生成的图表 fig_funnel.show()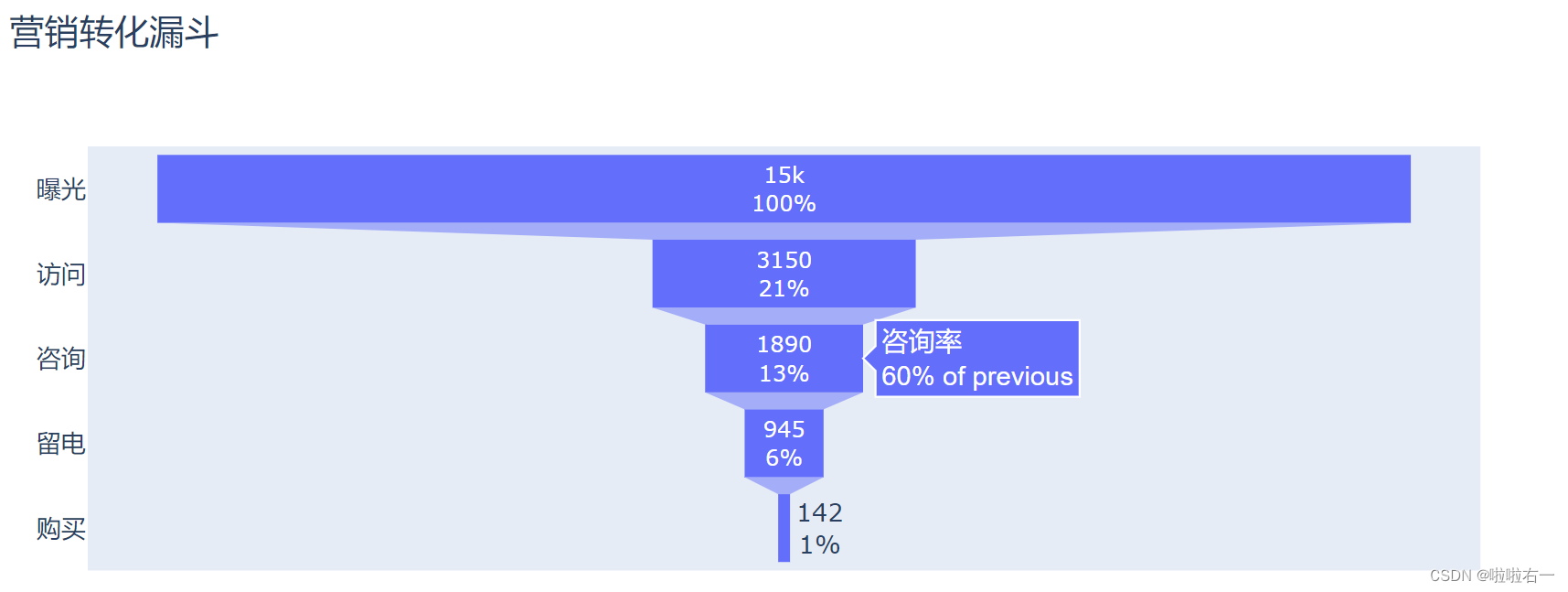
-
图表美化
from plotly.graph_objects import Figure, Funnel, layout from plotly.colors import qualitative link = ['曝光', '访问', '咨询', '留电', '购买'] number = [15000, 3150, 1890, 945, 142] # 初始化一个空白图表 fig_funnel = Figure() # 创建漏斗图形式的数据图形 trace_funnel = Funnel(x=number, y=link) # 将数据图形添加到空白图表 fig_funnel.add_trace(trace_funnel) # 添加图表标题 fig_funnel.update_layout(title=layout.Title(text='营销转化漏斗')) # 文本信息设置 fig_funnel.update_traces(textinfo='value+percent initial') # 悬浮标签设置 fig_funnel.update_traces(text=['总体', '访问率', '咨询率', '留电率', '成单率'], hoverinfo='text+percent previous') # 颜色 fig_funnel.update_traces(marker_color=qualitative.G10) # 展示生成的图表 fig_funnel.show()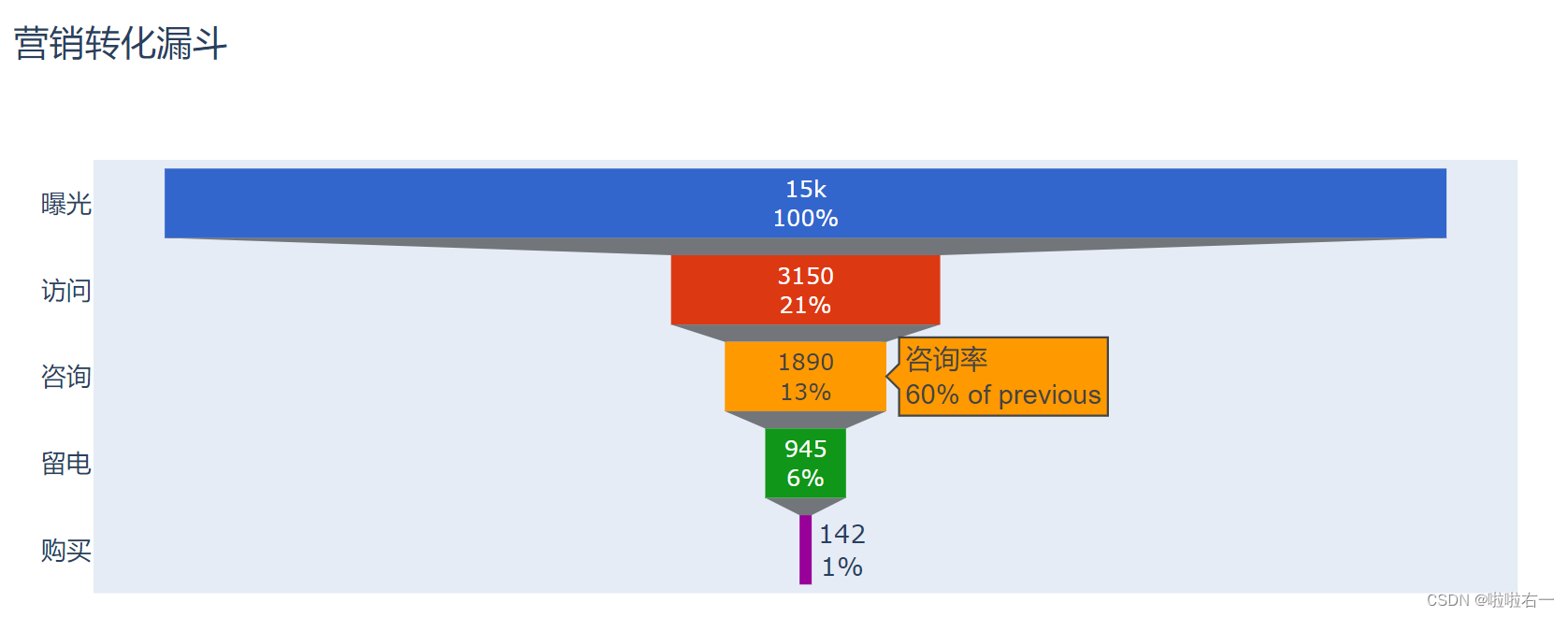
-
设置连接头
-
连接头的设置通过 connector 参数来完成,connector 参数的值是一个字典,字典中有 3 个键 ‘fillcolor’,‘line’ 和 ‘visible’,分别用于设置连接头的填充颜色、两侧框线,以及连接头是否可见。
-
因为连接头属于数据图形的一部分,所以,我们需要通过 update_traces() 方法来更新字典中各个键对应的值。
-
dash参数:设置线型

-
以上代码添加:
fig_funnel.update_traces( connector=dict( fillcolor='Gainsboro', line=dict( color='RoyalBlue', width=1.5, dash='dot') ) )
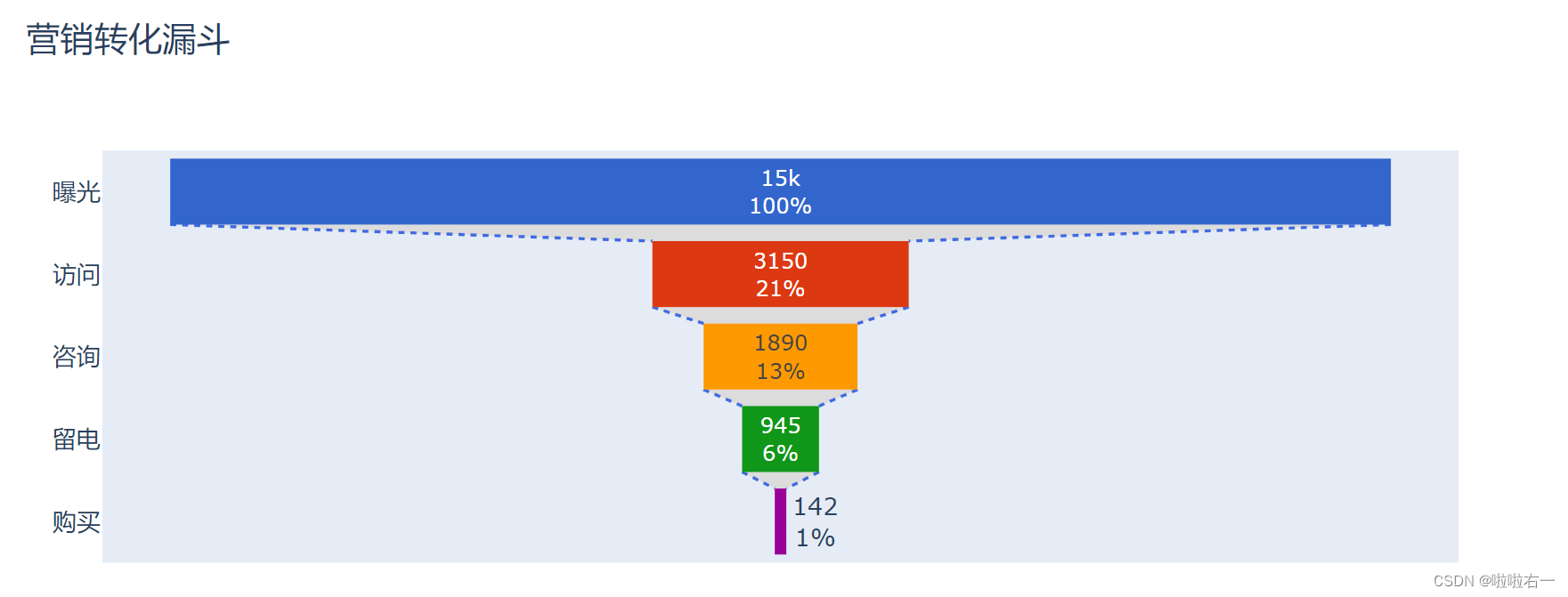
-
-
调整不透明度:以上代码加上
fig_funnel.update_traces(opacity=0.8)
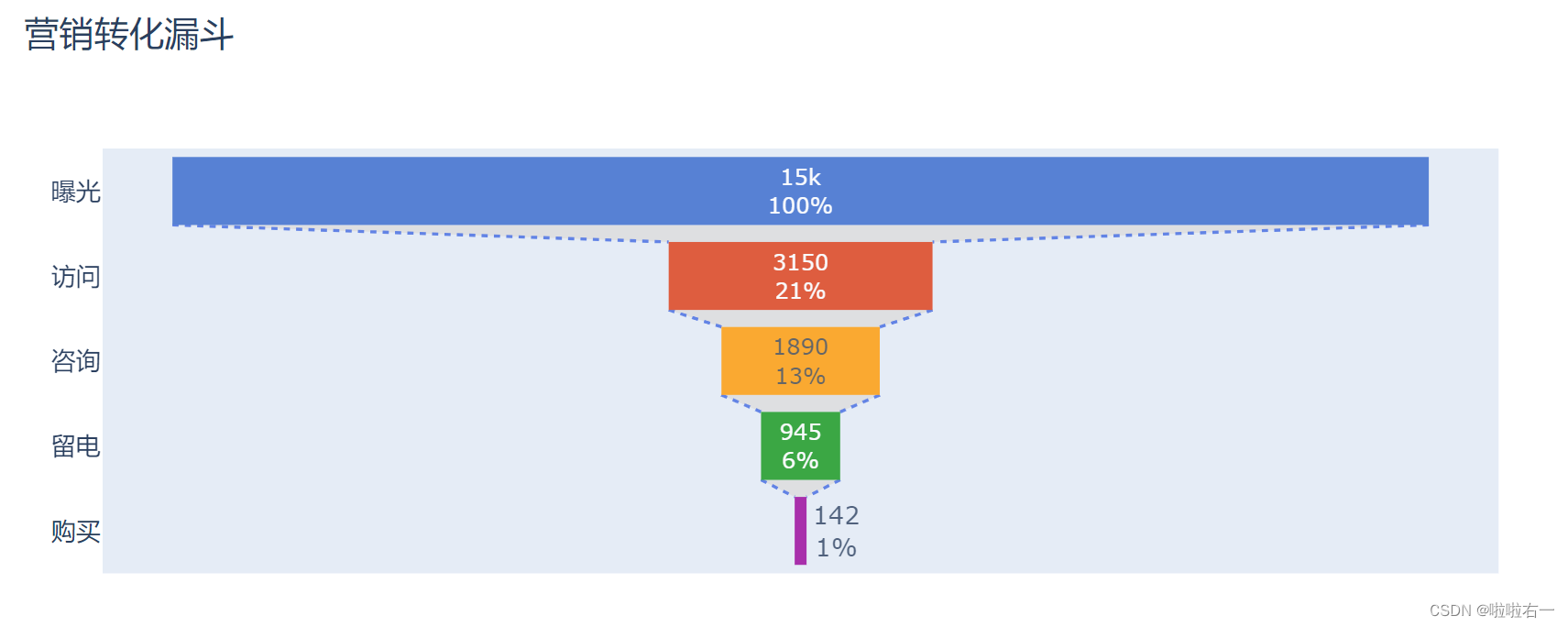
通观整张漏斗图,很容易发现,第二步访问以及最后一步购买的转化率是最低的。一般来说,在提升相同比率的情况下,转化越低的环节提升后的总体收益就越大。后续工作中,需要对这两步多花心思啦。
- 最终代码梳理
from plotly.graph_objects import Figure, Funnel, layout from plotly.colors import qualitative number = [15000, 3150, 1890, 945, 142] link = ['曝光', '访问', '咨询', '留电', '购买'] fig_funnel = Figure() trace_funnel = Funnel( x=number, y=link, # 在文本标签上显示值和当前环节对初始环节的转化率 textinfo="value+percent initial", # 在悬浮标签上显示数据指标和实际值 text=['总体', '访问率', '咨询率', '留电率', '成单率'], hoverinfo='text+percent previous', # 套用 G10 配色方案 marker_color=qualitative.G10, # 设置连接头 connector=dict( fillcolor='Gainsboro', line=dict( color='SlateBlue', width=1.5, dash='dot' ) ), # 调整 trace_funnel 的不透明度 opacity=0.8 ) fig_funnel.add_trace(trace_funnel) fig_funnel.update_layout(title=layout.Title(text='营销转化漏斗')) fig_funnel.show()
- 漏斗图展示的数据,彼此之间应当有逻辑上的顺序关系,阶段最好大于 3 个。如果数据不构成“流程”,那就不能使用漏斗图;
- 漏斗图的所有环节的流量都应该使用同一个度量,比如,曝光人数→点击次数→购买次数 这样的流程就不能用漏斗图展示,应当统一使用人数或次数作为度量,改为 曝光人数→点击人数→购买人数 或 曝光次数→点击次数→购买次数;
- 漏斗图展示的应是“消耗性”的流程,比如在电商领域,注册用户一定是经过层层消耗,才到达下单环节;在人力领域,收到的简历一定经过多轮筛选,才进入终面。
🐇桑基图
- 一个完整的桑基图分为两个必要部分:节点 (node) 和 连接 (link)。节点就是代表每个阶段的蓝色方块儿,连接就是节点间表示数量流动的灰色长条,长条左边是 流出节点,右边是 流入节点,长条的宽度代表具体的数量。
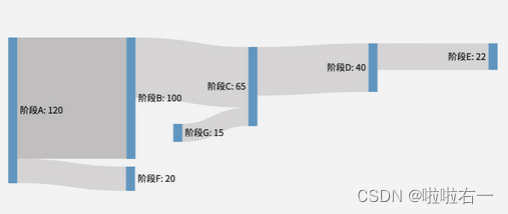
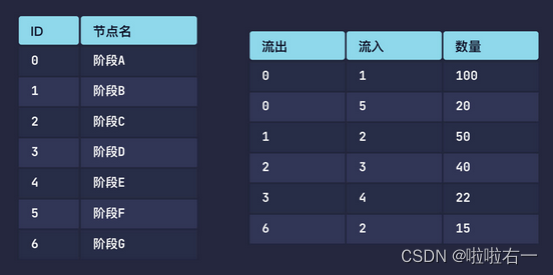
-
基础桑基图
# 导入必要的类:Figure 和 Sankey from plotly.graph_objects import Sankey, Figure fig = Figure() # 实例化一个桑基 trace trace = Sankey( # 用字典定义节点(node) node=dict( # 定义各节点的名称 label=['阶段A', '阶段B', '阶段C', '阶段D', '阶段E', '阶段F', '阶段G'], # 定义节点的统一颜色 color='SteelBlue' ), # 用字典定义连接(link) link=dict( # 定义所有流出节点编号 source=[0, 0, 1, 2, 3, 6], # 定义所有流入节点编号 target=[1, 5, 2, 3, 4, 2], # 定义所有流动数量 value=[100, 20, 50, 40, 22, 15] ) ) fig.add_traces(trace) fig.show()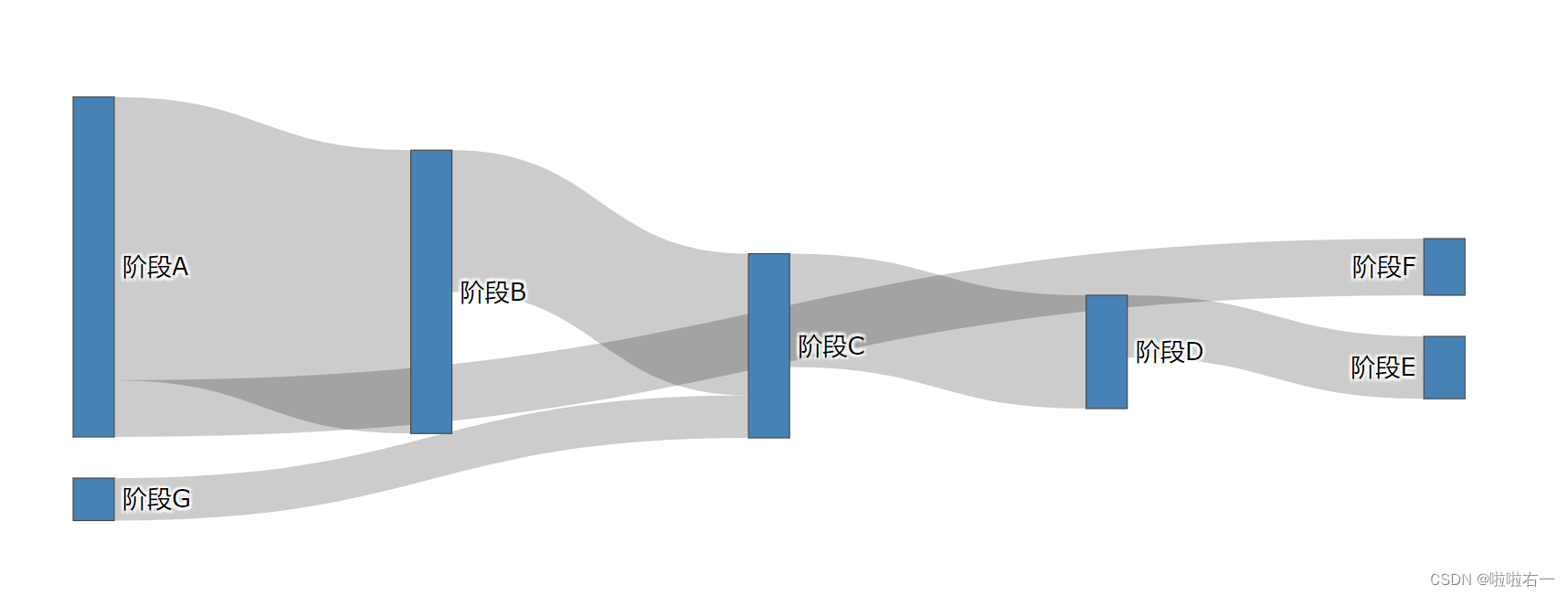
- 以上虽然节点和连接都生成了,但是位置有些乱,这是因为我们在代码中没有指定节点位置。Plotly 的动态特性可以手动拖动每个节点,让排列好看一点。
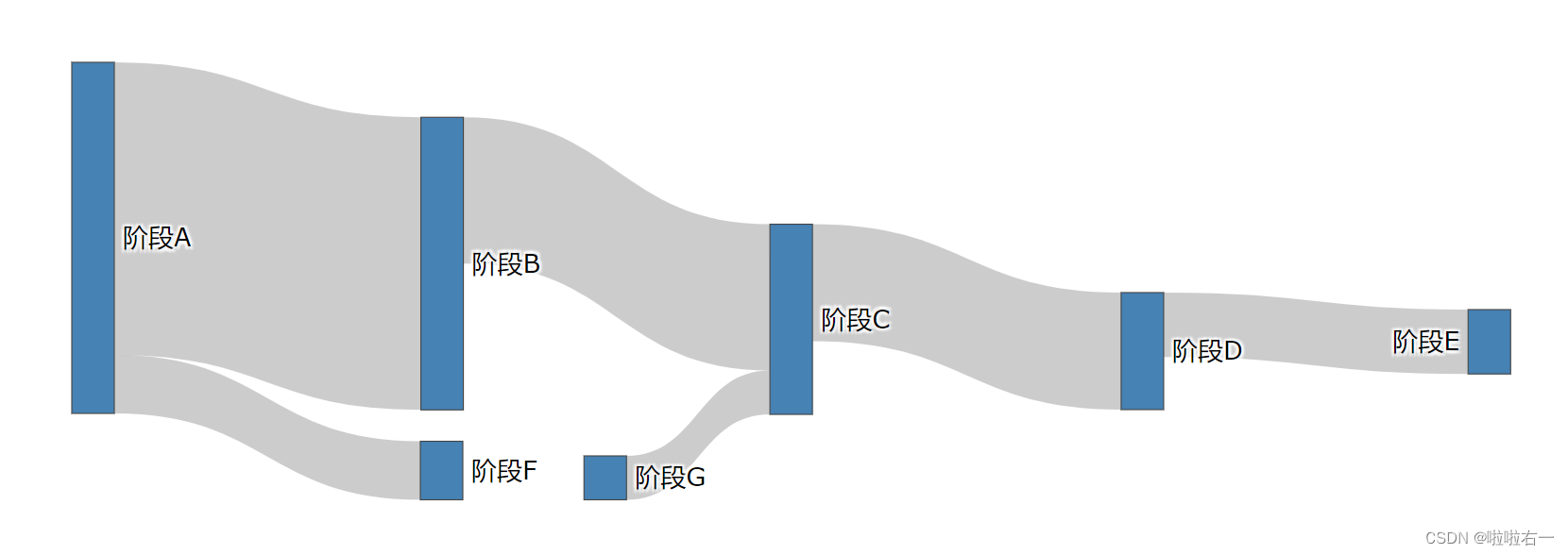
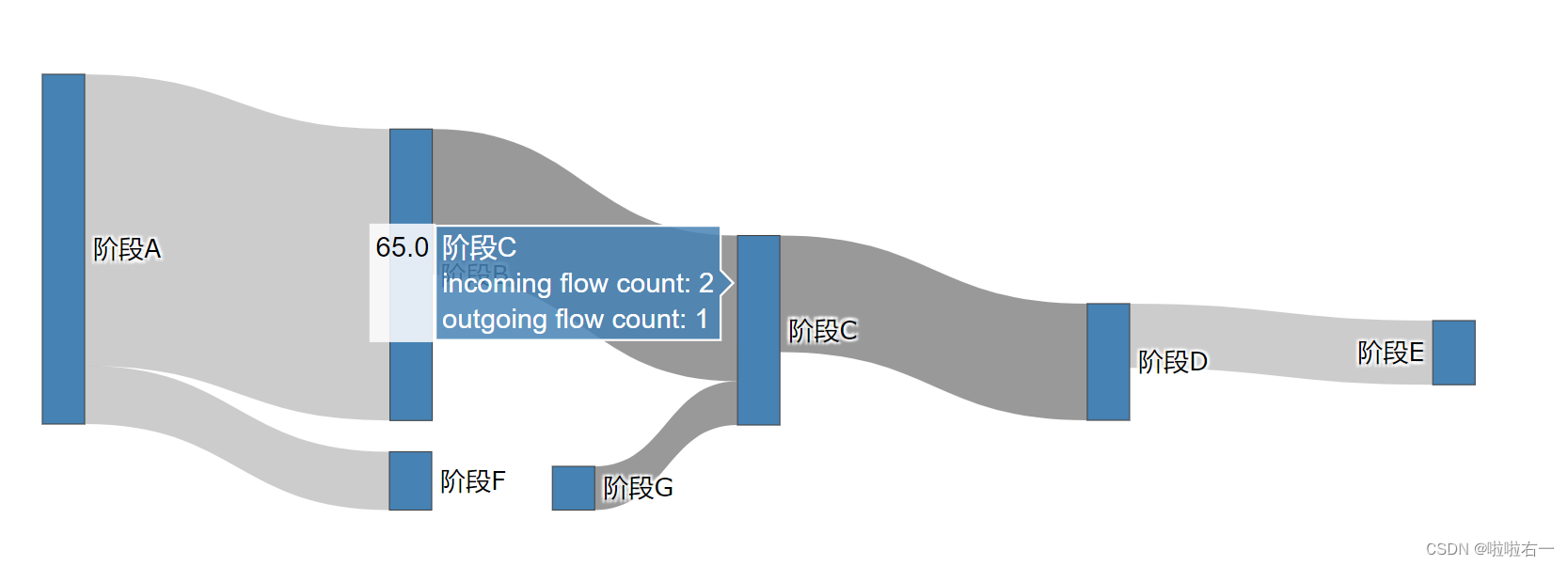
- 鼠标停留在节点上时,悬浮标签会显示当前节点的数据量,节点名,流入该节点的连接数 (incoming flow count),以及由此流出的连接数 (outcoming flow count)。
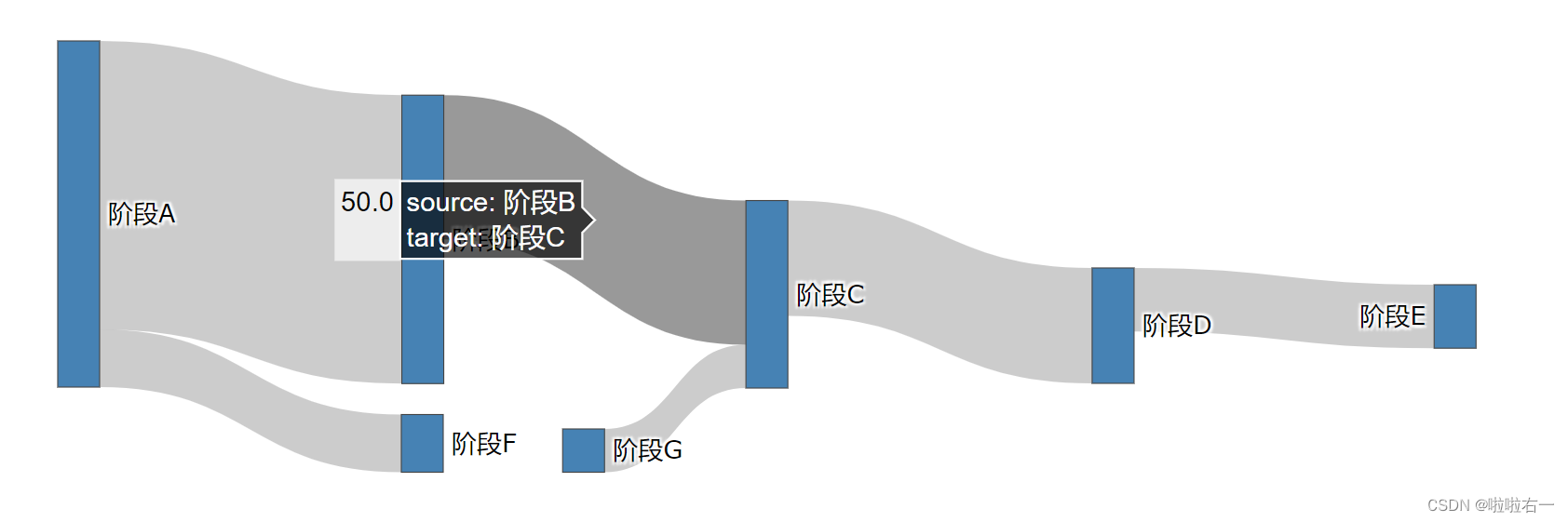
- 停留在连接上时,悬浮标签会显示当前连接的数据量,流入节点和流出节点。
- 桑基图的trace部分,node参数的常用键
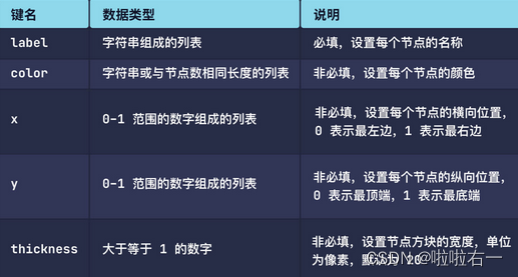
- 桑基图的trace部分,link参数的常用键

- 以上虽然节点和连接都生成了,但是位置有些乱,这是因为我们在代码中没有指定节点位置。Plotly 的动态特性可以手动拖动每个节点,让排列好看一点。
-
设置每个节点的位置,以上代码中再添加如下代码:
fig.update_traces(node=dict( # 定义节点的横向位置 x=[0.1, 0.3, 0.5, 0.7, 0.9, 0.3, 0.4], # 定义节点的纵向位置 y=[0.5, 0.4, 0.5, 0.5, 0.5, 0.9, 0.9] ))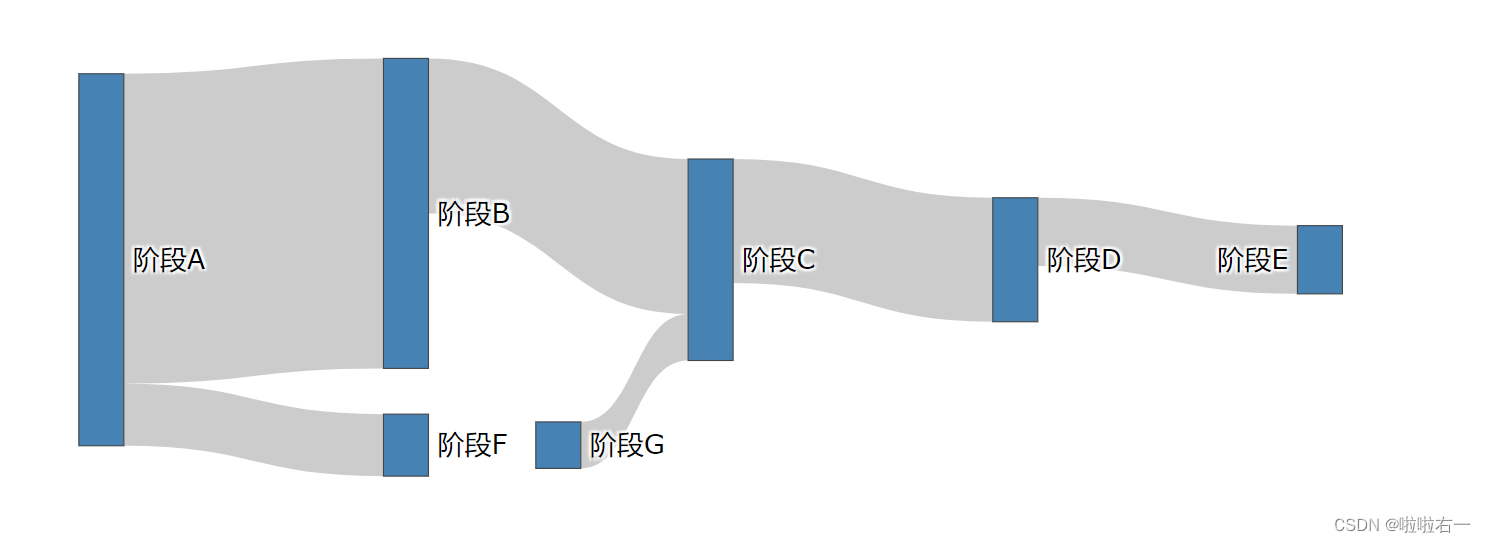
-
家庭收支案例桑基图
import pandas as pd from plotly.graph_objects import Figure, Sankey path = './data/家庭收支.xlsx' nodes = pd.read_excel(path, sheet_name ='Nodes') links = pd.read_excel(path, sheet_name ='Links') fig = Figure() trace = Sankey(node=dict(label=nodes['节点名'], color='SteelBlue', # 调整节点宽度,让节点看起来窄一些 thickness=10), link=dict(source=links['流出'], target=links['流入'], value=links['金额'])) fig.add_traces(trace) fig.show()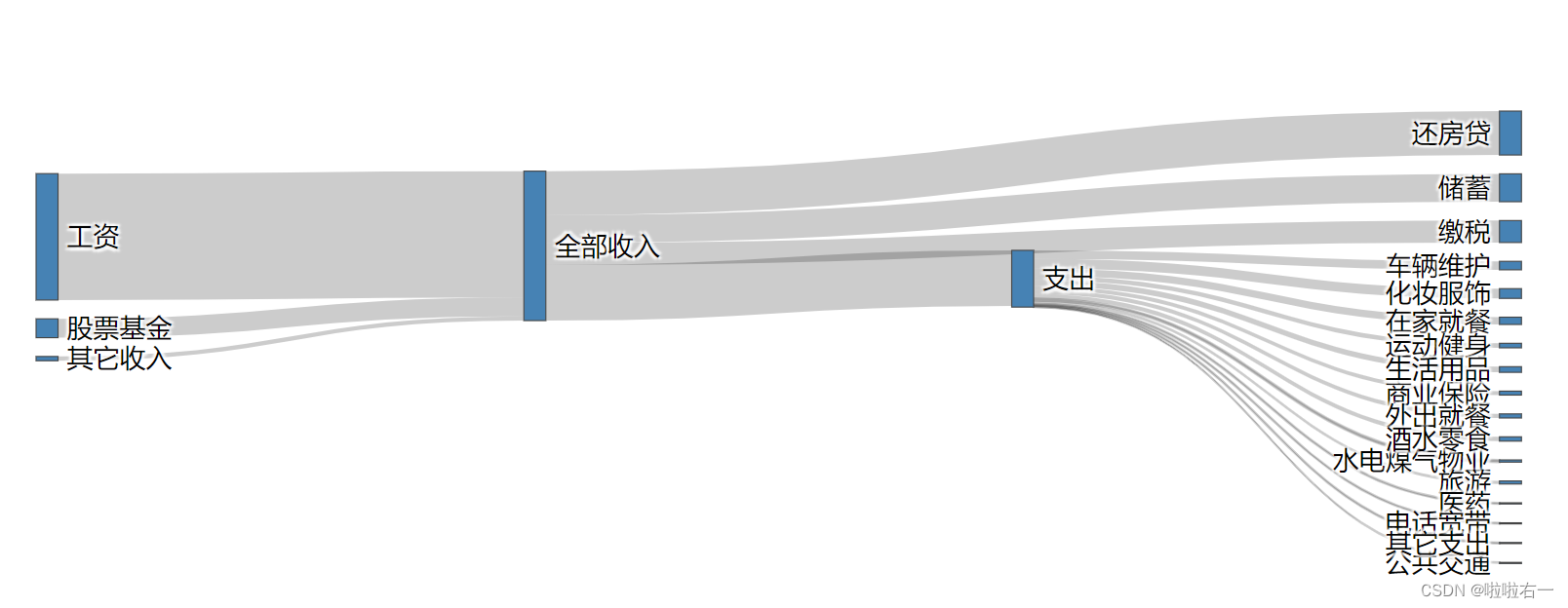
-
调整节点效果:目标效果是将“支出”、“缴税”、“还房贷”和“储蓄”调整到了同一条竖线上,并将这四个节点在纵向上铺开,将“储蓄”放到了最下面,显得不那么拥挤。
- 为要调整位置的节点建立一个字典,键为节点名,值为横向位置。
- 然后,使用字典的 get() 方法,对
nodes['节点名']进行遍历,如果其中的节点名在字典中,就返回对应的数字,不在的话,就返回 None,然后将这些返回的结果都放进列表 position_x 中。 - 纵向位置的调整思路同理。
- 最后将两个长列表传给x和y键就可以了。
-
最终完整代码
import pandas as pd from plotly.graph_objects import Figure, Sankey path = './data/家庭收支.xlsx' nodes = pd.read_excel(path, sheet_name ='Nodes') links = pd.read_excel(path, sheet_name ='Links') fig = Figure() trace = Sankey(node=dict(label=nodes['节点名'], color='SteelBlue', # 调整节点宽度,让节点看起来窄一些 thickness=10 ), link=dict(source=links['流出'], target=links['流入'], value=links['金额'])) fig.add_traces(trace) # 设置横向和纵向的位置字典 label_position_x = {'储蓄': 0.6, '缴税': 0.6, '还房贷': 0.6, '支出': 0.6} label_position_y = {'储蓄': 0.9, '缴税': 0.1, '还房贷': 0.3, '支出': 0.5} position_x = [label_position_x.get(i, None) for i in nodes['节点名']] position_y = [label_position_y.get(i, None) for i in nodes['节点名']] fig.update_traces(node=dict(x=position_x, y=position_y)) fig.show()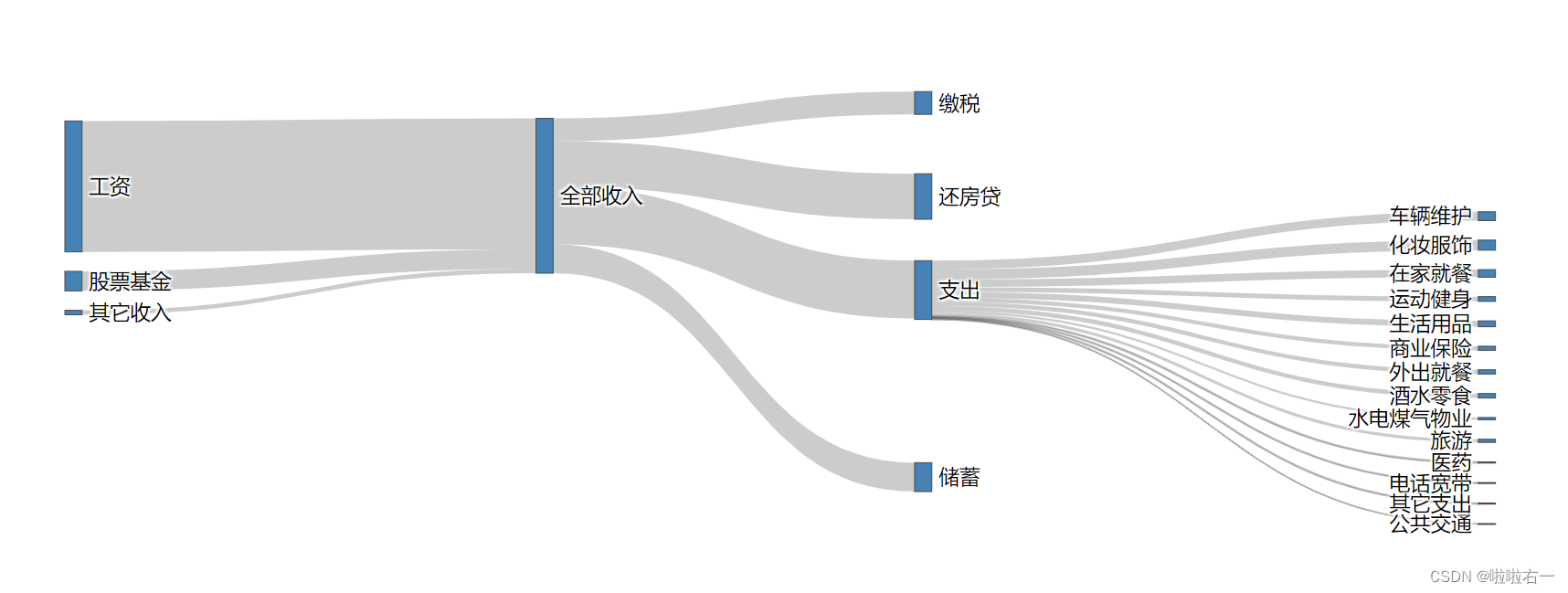
- 从图中我们可以看出,缴税和房贷是硬性的,不可以缩减,而在支出中,面积比较大的节点有“化妆服饰”、“在家就餐”、“车辆维护”、“生活用品”和“酒水零食”,要想增加储蓄,可以在“化妆服饰”、“生活用品”和“酒水零食”上适当缩减。
- 然而,由于整个的支出节点占全部收入的比例已经不大,能缩减的数额也不多,所以除了“节流”外,还要从源头想想“开源”,增加工资之外的收入。
🐇金字塔图
- 扩张型:幼龄人口在人口金字塔的比例比其他年龄层多,这批幼龄群体长大后又会带来一次生育潮,总人口数会继续扩张。
- 收缩型:幼龄人口在人口金字塔的比例比其他年龄层的少或是逐渐减少,这样就会慢慢进入老龄化社会,总人口数会逐渐变少。
- 稳定型:出生率与死亡率大致相等,幼龄人口在人口金字塔的比例与其他年龄层差不多,总人口数也会趋于稳定。
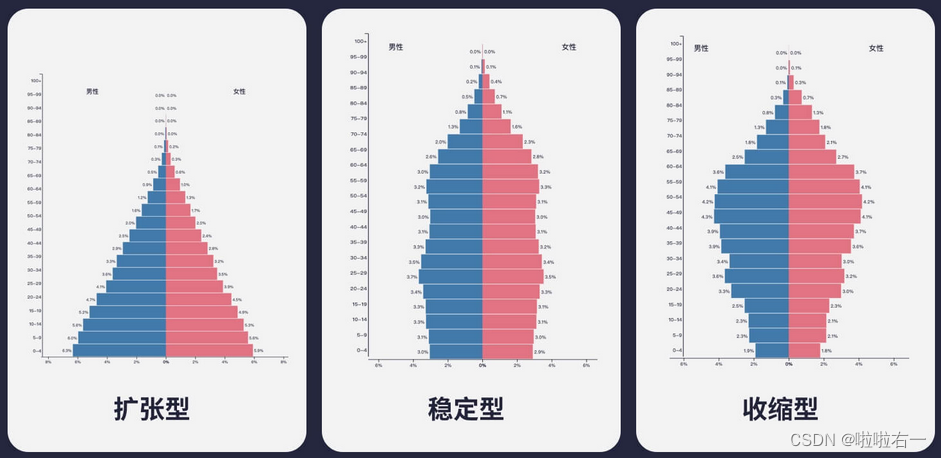
- 金字塔绘制思路
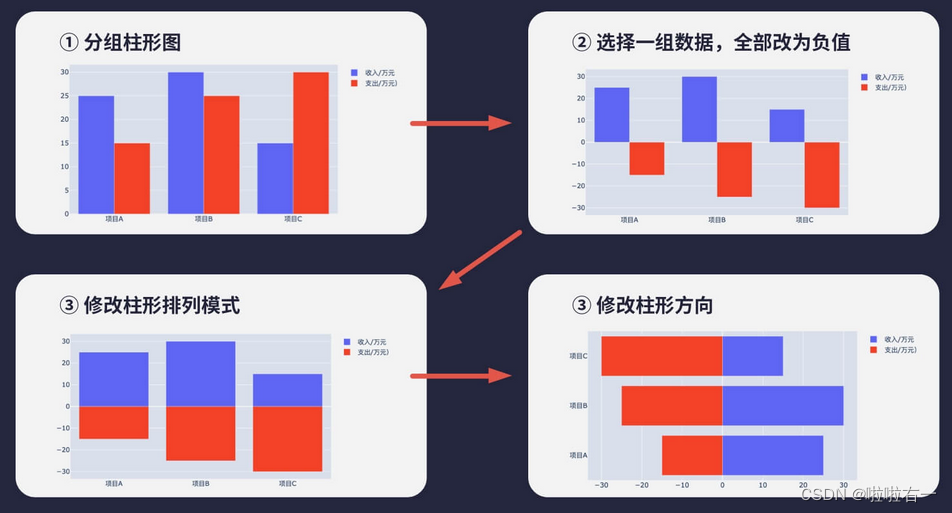
-
绘制基本柱形图
import pandas as pd from plotly.graph_objects import Figure, Bar, layout path = './data/2020年世界人口结构.xlsx' population = pd.read_excel(path, sheet_name ='世界') # 构造年龄分组数据 age_group = population['年龄段'] # 构造男性人口数据 male = population['男性人口/百万'] # 构造女性人口数据 female = population['女性人口/百万'] # 创建空图表 fig_pyramid = Figure() # 创建男性人口的 trace trace_m = Bar(name='男性人口', x=age_group, y=male) # 创建女性人口的 trace trace_f = Bar(name='女性人口', x=age_group, y=female) # 将 trace 添加到空图表 fig_pyramid.add_traces(trace_m) fig_pyramid.add_traces(trace_f) # 展示生成的图表 fig_pyramid.show()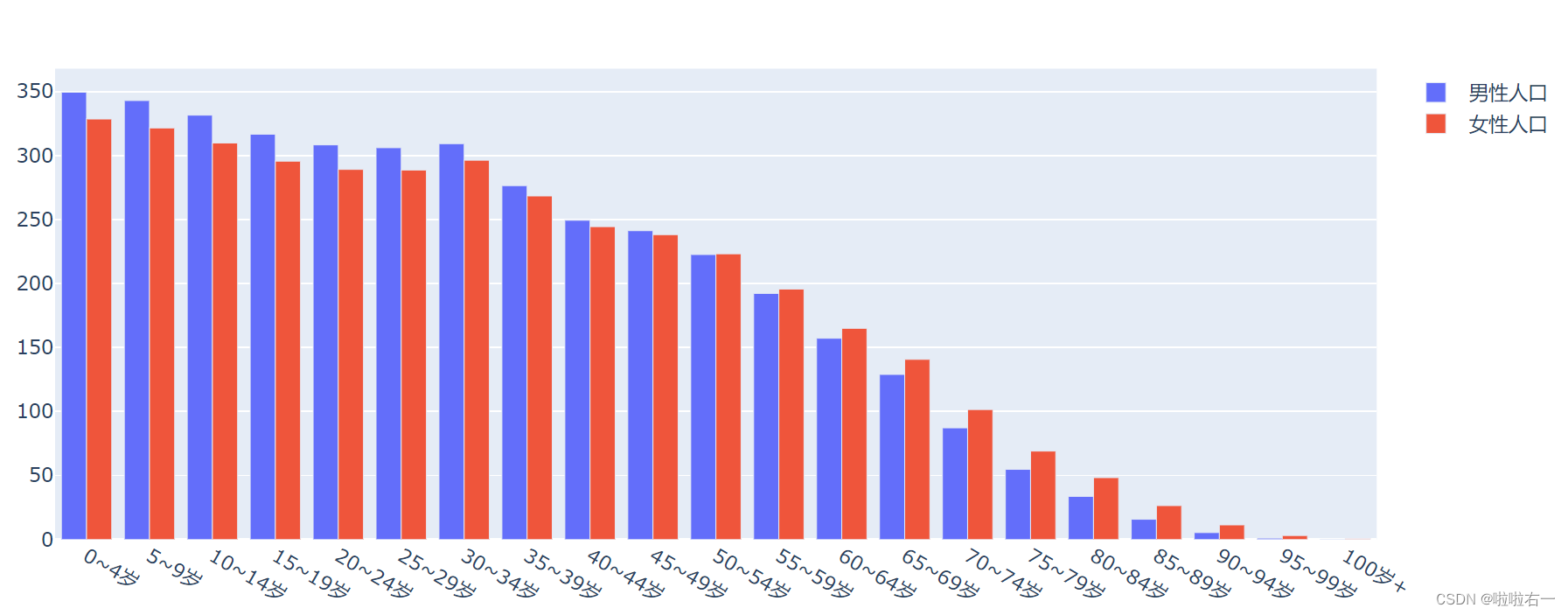
-
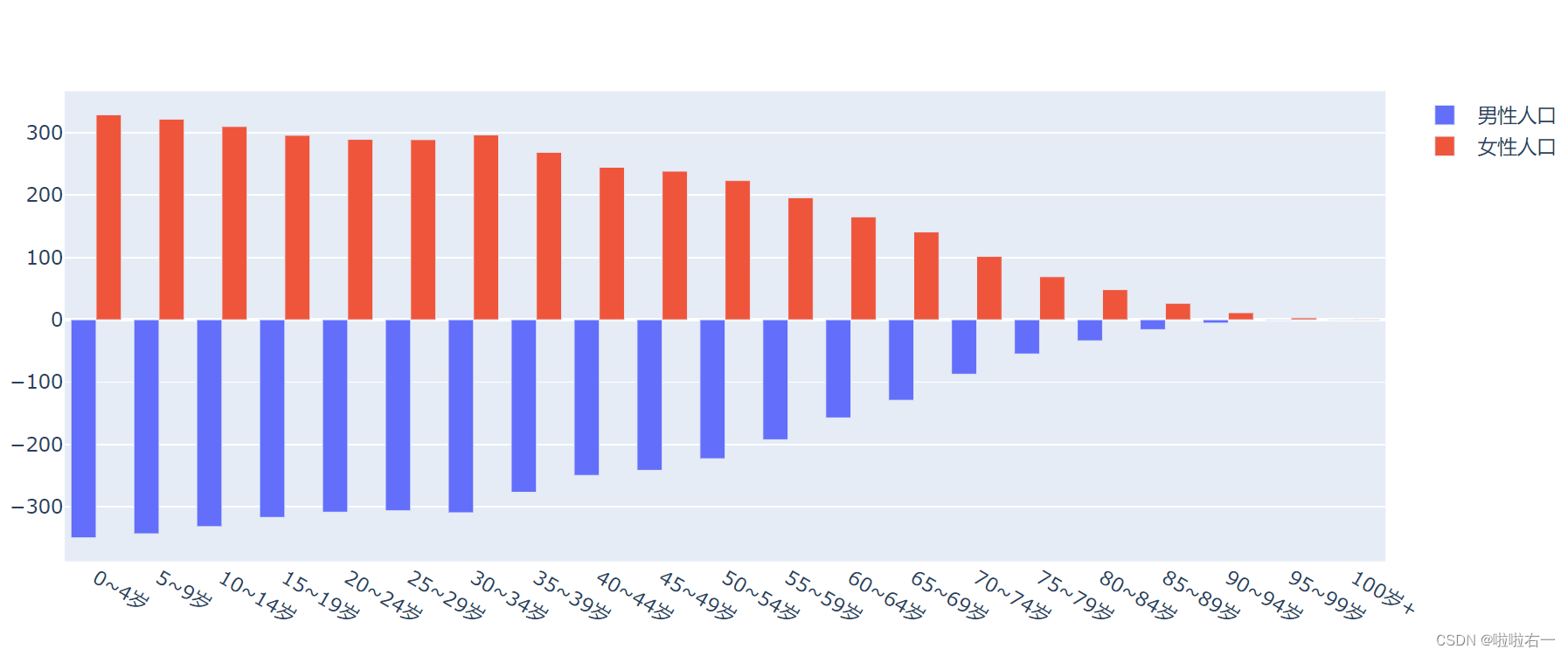
单组数据取负值:
trace_m = Bar(name='男性人口', x=age_group, y=-male)
-
柱形位置对齐:添加
fig_pyramid.update_layout(barmode='relative')
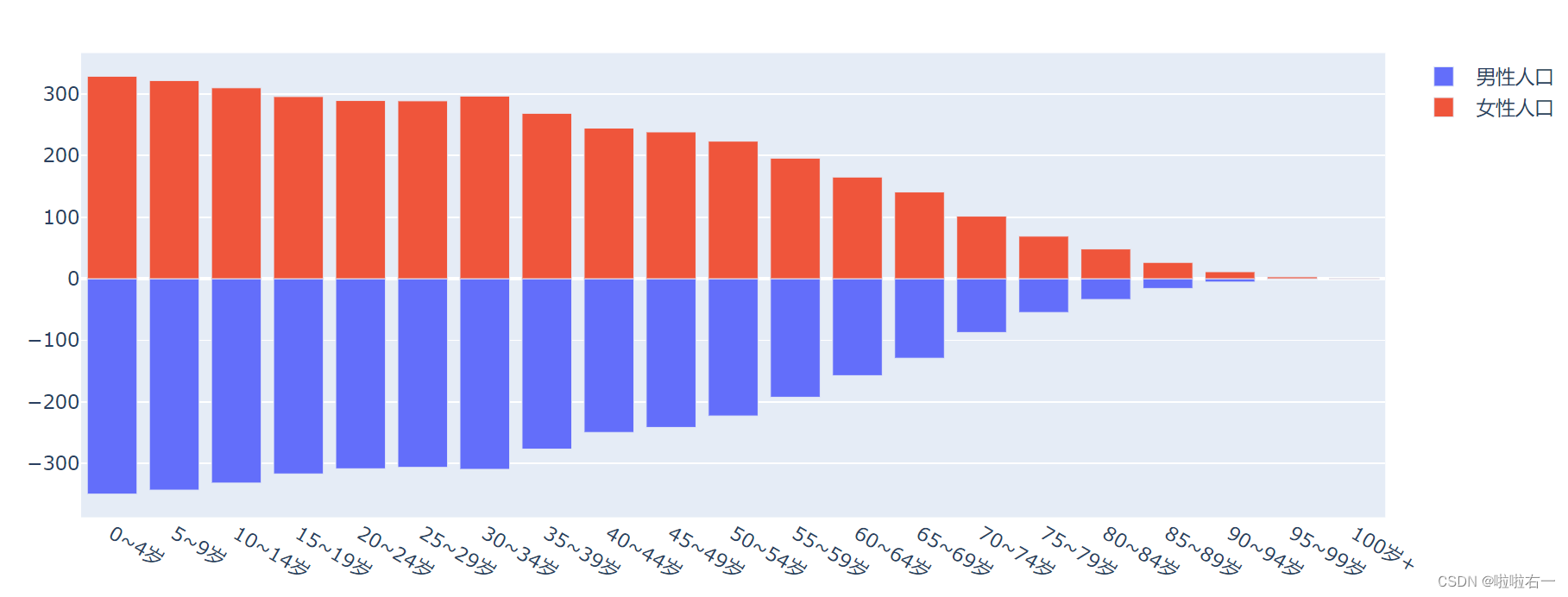
-
修改柱形方向
- 在设置 trace 时,可以用 orientation 参数控制柱形的方向,这个参数可以被设定为两个值,默认为
v(纵向模式) ,h(横向模式),h 是单词 horizontal 的缩写,意为“水平的”。 - 用 orientation 参数修改后的条形图,对应的坐标轴也会变化。
- 这就说明,生成柱形图和条形图的 trace,除了 orientation 的值不同之外,x、y 参数获得的数据也应该对调过来。
import pandas as pd from plotly.graph_objects import Figure, Bar, layout path = './data/2020年世界人口结构.xlsx' population = pd.read_excel(path, sheet_name ='世界') # 构造年龄分组数据 age_group = population['年龄段'] # 构造男性人口数据 male = population['男性人口/百万'] # 构造女性人口数据 female = population['女性人口/百万'] # 生成一个空白图表 fig_pyramid = Figure() # 使用人口数据生成 trace # 注意 x 参数获得的是人口数量,y 参数获得年龄段 trace_m = Bar(name='男性人口', y=age_group, x=-male) trace_f = Bar(name='女性人口', y=age_group, x=female) # 将 trace 添加到空图表中 fig_pyramid.add_traces(trace_m) fig_pyramid.add_traces(trace_f) # 调整两组 trace 柱形的位置为相对模式 fig_pyramid.update_layout(barmode='relative') # 调整柱形方向为水平 fig_pyramid.update_traces(orientation='h') fig_pyramid.show()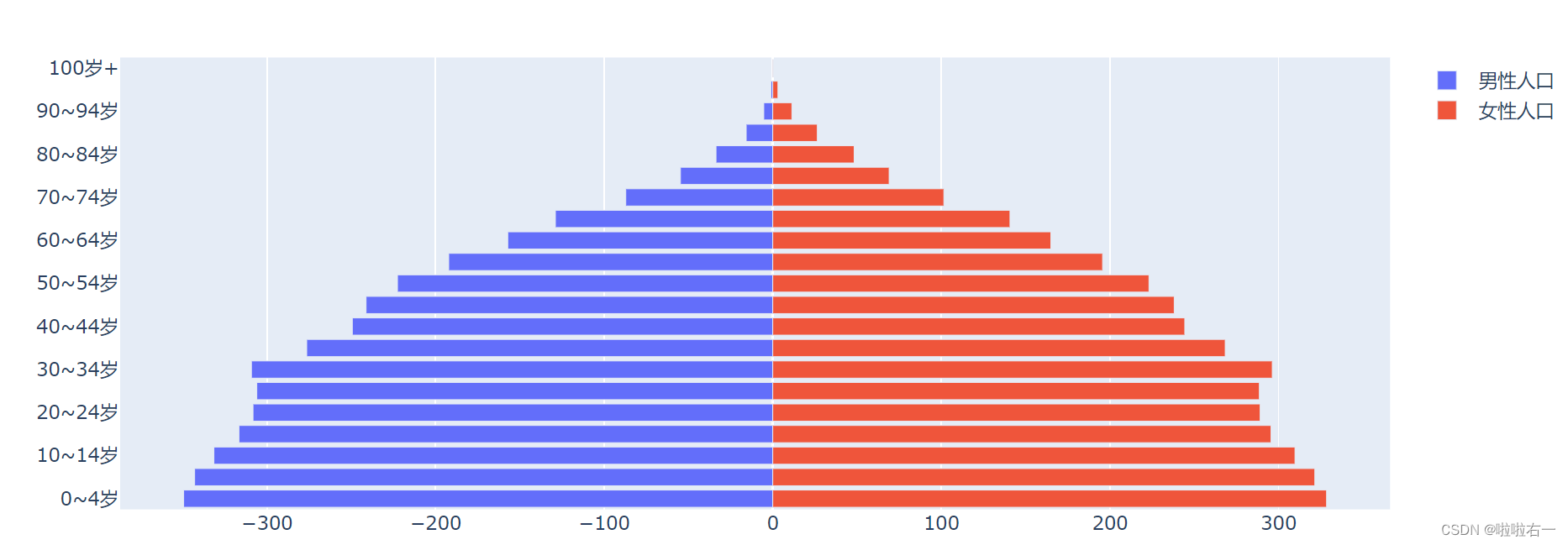
- 在设置 trace 时,可以用 orientation 参数控制柱形的方向,这个参数可以被设定为两个值,默认为
-
设置坐标轴:X 轴标题应当为 人口量(百万),Y 轴标题应为 年龄。接下来我们的任务是,分别设置 X,Y 轴,添加轴标题并设置 X 轴的刻度。
- Plotly 里的坐标轴是“表里不一”的,它有两副面孔:
tickvals是给 Plotly 看的,Plotly 内部根据tickvals确定条形在图表中显示的长短;ticktext是给看图的人准备的,它指定了坐标轴上实际显示的刻度到底是什么。 - 为了绘制出金字塔图的效果,我们将男性人口数据全部转换成了负值,所以,男性人口对应的 X 轴刻度也都是负的。这样明显不符合常理,这时 ticktext 就派上用场了。我们可以用 ticktext 配合 tickvals 参数,给坐标轴打一层补丁,把图表左侧的坐标转负为正。
# 实例化一个 X 轴,设置轴标题和刻度值 fig_xaxis = layout.XAxis(title=dict(text='人口量(百万)'), tickvals=[-300, -200, -100, 0, 100, 200, 300], ticktext=[300, 200, 100, 0, 200, 300]) # 实例化一个 Y 轴,设置轴标题 fig_yaxis = layout.YAxis(title=dict(text='年龄')) # 将坐标轴组件添加到布局中 fig_pyramid.update_layout(xaxis=fig_xaxis,yaxis=fig_yaxis)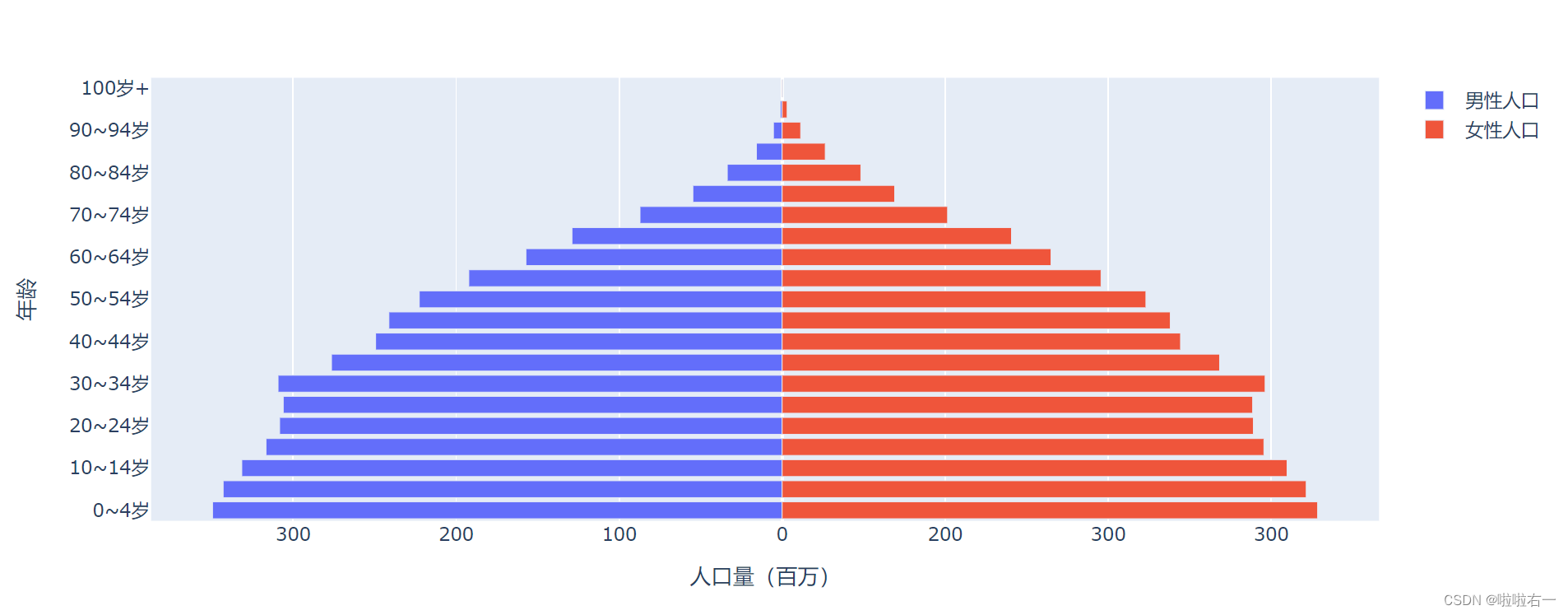
- Plotly 里的坐标轴是“表里不一”的,它有两副面孔:
-
设置条形内部文本
text参数设置图表上的附加文本。柱形和条形上的详细数据,也可以写到列表里,用附加文本的形式传入,这样就能按照指定的格式显示详细数据了。- 此外,要想让
text参数获得的信息展示在图表上,我们还需要用textposition参数额外说明本内容显示在什么位置,内部 (‘inside’),外部 (‘outside’) 或是自动 (‘auto’)。 - 注意:只有在设置
textposition后,text获得的文本内容才会在柱形和条形上显示哦。不然 Plotly 就会认为你这一步是在设置用于hoverinfo附加文本,而不是在条形内部一直显示的信息。
fig_pyramid.update_traces(selector={'name': '男性人口'}, text=["%s百万"% i for i in male], textposition='inside') fig_pyramid.update_traces(selector={'name': '女性人口'}, text=["%s百万"% i for i in female], textposition='inside')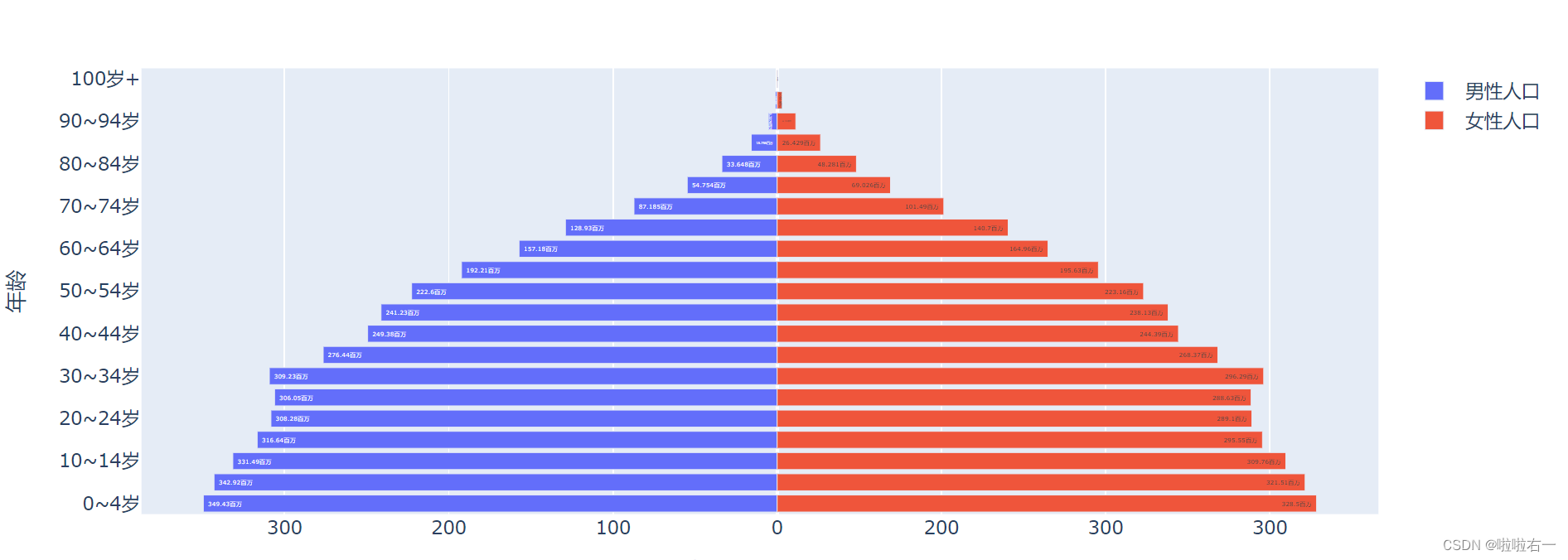
-
设置悬浮标签:
fig_pyramid.update_traces(hoverinfo='y+name+text')
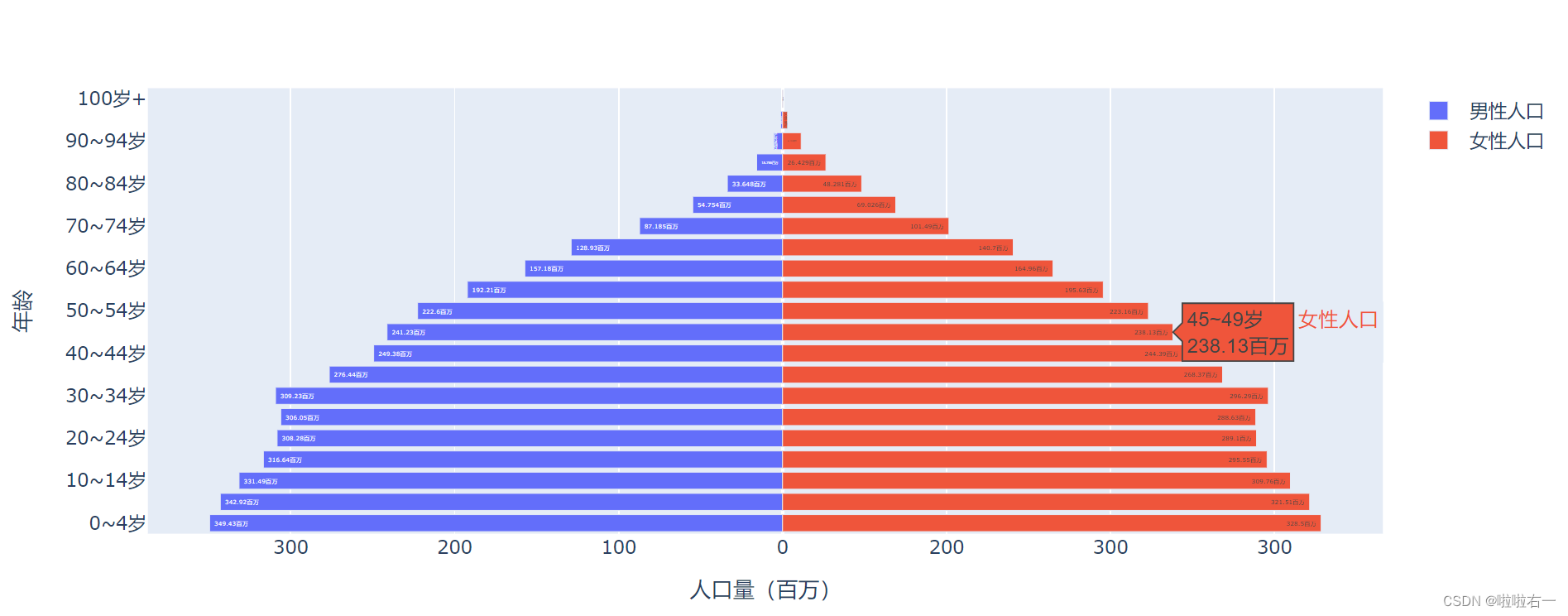
-
添加标题,修改颜色
# 将男性人口 trace 的颜色设为 MidnightBlue(午夜蓝) fig_pyramid.update_traces(selector={'name': '男性人口'}, marker_color='MidnightBlue') # 将女性人口 trace 的颜色设为 FireBrick(砖红) fig_pyramid.update_traces(selector={'name': '女性人口'}, marker_color='FireBrick') # 为图表添加标题并设为水平居中 fig_title = layout.Title(text='2020世界人口金字塔', x=0.5) fig_pyramid.update_layout(title=fig_title)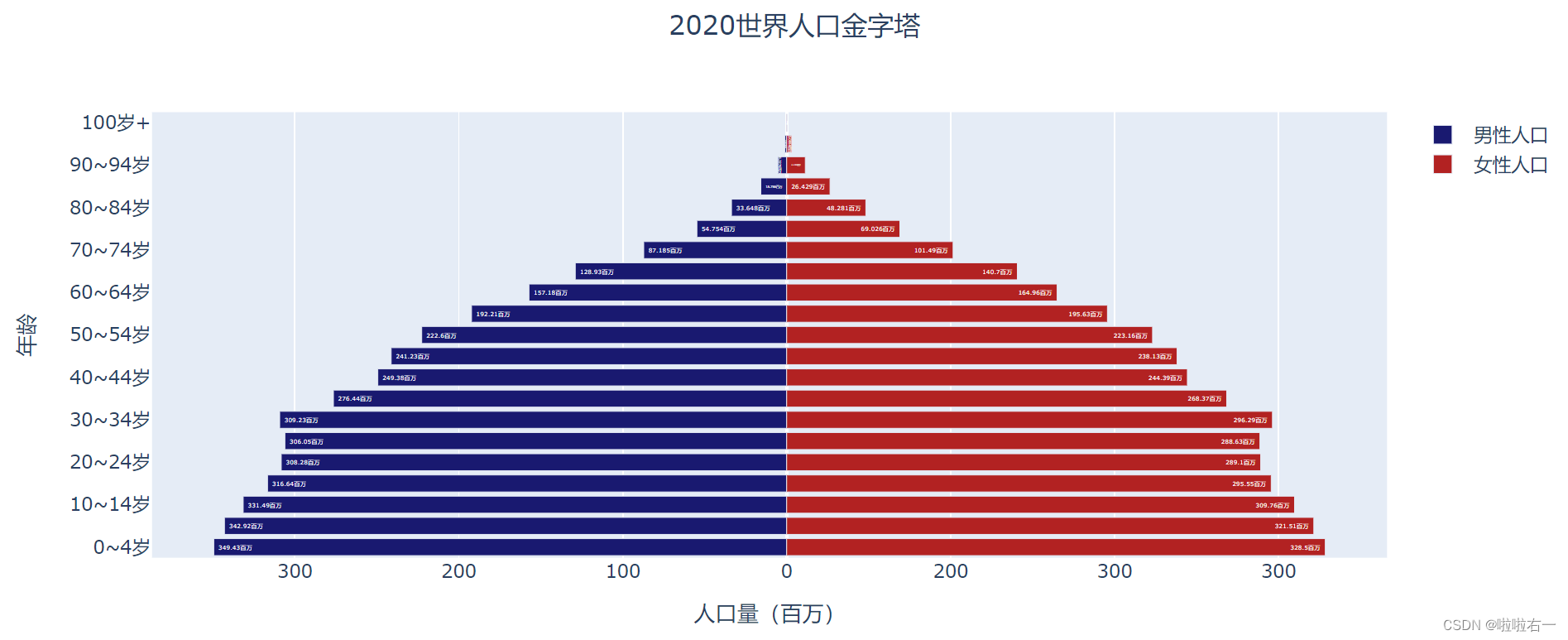
- 最终代码梳理
import pandas as pd from plotly.graph_objects import Figure, Bar, layout # 从 Excel 工作表中读取数据 path = './data/2020年世界人口结构.xlsx' population = pd.read_excel(path, sheet_name ='世界') # 构造年龄分组数据 age_group = population['年龄段'] # 构造男性人口数据 male = population['男性人口/百万'] # 构造女性人口数据 female = population['女性人口/百万'] # 生成空图表 fig_pyramid = Figure() # 生成男性人口的 trace trace_m = Bar(y=age_group, x=-male, name='男性人口', marker_color='MidnightBlue', text=["%s百万" % i for i in male], textposition='inside') # 生成女性人口的 trace trace_f = Bar(y=age_group, x=female, name='女性人口', marker_color='FireBrick', text=["%s百万" % i for i in female], textposition='inside') # 将两个 trace 加入图表 fig_pyramid.add_traces(trace_m) fig_pyramid.add_traces(trace_f) # 设置悬浮标签显示内容,包括性别、年龄段和详细人口量 fig_pyramid.update_traces(hoverinfo='y+text+name', orientation='h') # 实例化图表标题,并设为水平居中 fig_title = layout.Title(text='2020世界人口金字塔', x=0.5) # 实例化 X 轴,设置轴标题和坐标轴刻度 fig_xaxis = layout.XAxis(title=dict(text='人口量(百万)'), tickvals=[-300, -200, -100, 0, 100, 200, 300], ticktext=[300, 200, 100, 0, 200, 300]) # 实例化 Y 轴,设置轴标题 fig_yaxis = layout.YAxis(title=dict(text='年龄')) # 将标题、X 轴和 Y 轴添加到布局,设置柱形排列模式 fig_pyramid.update_layout(title=fig_title, xaxis=fig_xaxis, yaxis=fig_yaxis, barmode='relative') fig_pyramid.show()
- 金字塔图又叫对比条形图,除了人口结构外,它还非常适合用来展示具有 对立关系 的数据。
- 比如出口与内销、收入与支出、入职与离职、赞同与反对等等,两组具有对立关系的数据,都可以用金字塔图来展示。
- 金字塔图不仅能展示出两组数据的数值差异,还能让我们直观地对比两边数据的结构或趋势。
拓展:
-
构造两性人口的差值数据;
-
在女性人口 trace 外侧,显示男性人口多于女性人口的部分;
-
在男性人口 trace 外侧,显示女性人口多于男性人口的部分。
import pandas as pd from plotly.graph_objects import Figure, Bar, layout # 从 Excel 工作表中读取人口数据 path = './data/1970年世界人口结构.xlsx' population = pd.read_excel(path, sheet_name ='世界') # 构造年龄分组数据 age_group = population['年龄段'] # 构造男性人口数据:各年龄段人数 male = population['男性人口/百万'] # 构造女性人口数据:各年龄段人数 female = population['女性人口/百万'] # 构造男性人口-女性人口的差值数据 delta_m = [i if i > 0 else 0 for i in male - female] # 构造女性人口-男性人口的差值数据 delta_f = [-i if i > 0 else 0 for i in female - male] # 生成空图表 fig_pyramid = Figure() # 生成男性人口的柱形 trace trace_m = Bar(y=age_group, x=-male, name='男性人口', text=['%.2f百万' % i for i in male], marker_color='SkyBlue') # 生成女性人口的柱形 trace trace_f = Bar(y=age_group, x=female, name='女性人口', text=['%.2f百万' % i for i in female], marker_color='Salmon') # 生成女性人口多于男性人口的差值 trace trace_df = Bar(y=age_group, x=delta_f, name='女性人口-男性人口', text=['%.2f百万' % abs(i) for i in delta_f], marker_color='MidnightBlue') # 生成男性人口多于女性人口的差值 trace trace_dm = Bar(y=age_group, x=delta_m, name='男性人口-女性人口', text=['%.2f百万' % i for i in delta_m], marker_color='FireBrick') # 将 trace 加入图表 fig_pyramid.add_traces(trace_m) fig_pyramid.add_traces(trace_f) fig_pyramid.add_traces(trace_dm) fig_pyramid.add_traces(trace_df) # 改变悬浮标签显示内容 fig_pyramid.update_traces(hoverinfo='name+text+y', orientation='h') # 实例化一个标题,设置内容和字体,以及水平居中 fig_title = layout.Title(text='1970世界人口金字塔', x=0.5) # 实例化一个 x 轴,设置轴标题内容和字体 fig_xaxis = layout.XAxis(title=dict(text='人口量(百万)'), tickvals=[-300, -200, -100, 0, 100, 200, 300], ticktext=[300, 200, 100, 0, 200, 300]) # 实例化一个 y 轴,设置轴标题内容和字体 fig_yaxis = layout.YAxis(title=dict(text='年龄', font=dict(size=15))) # 将三个实例化的组件添加进布局中 fig_pyramid.update_layout(title=fig_title, xaxis=fig_xaxis, yaxis=fig_yaxis, barmode='relative') fig_pyramid.show()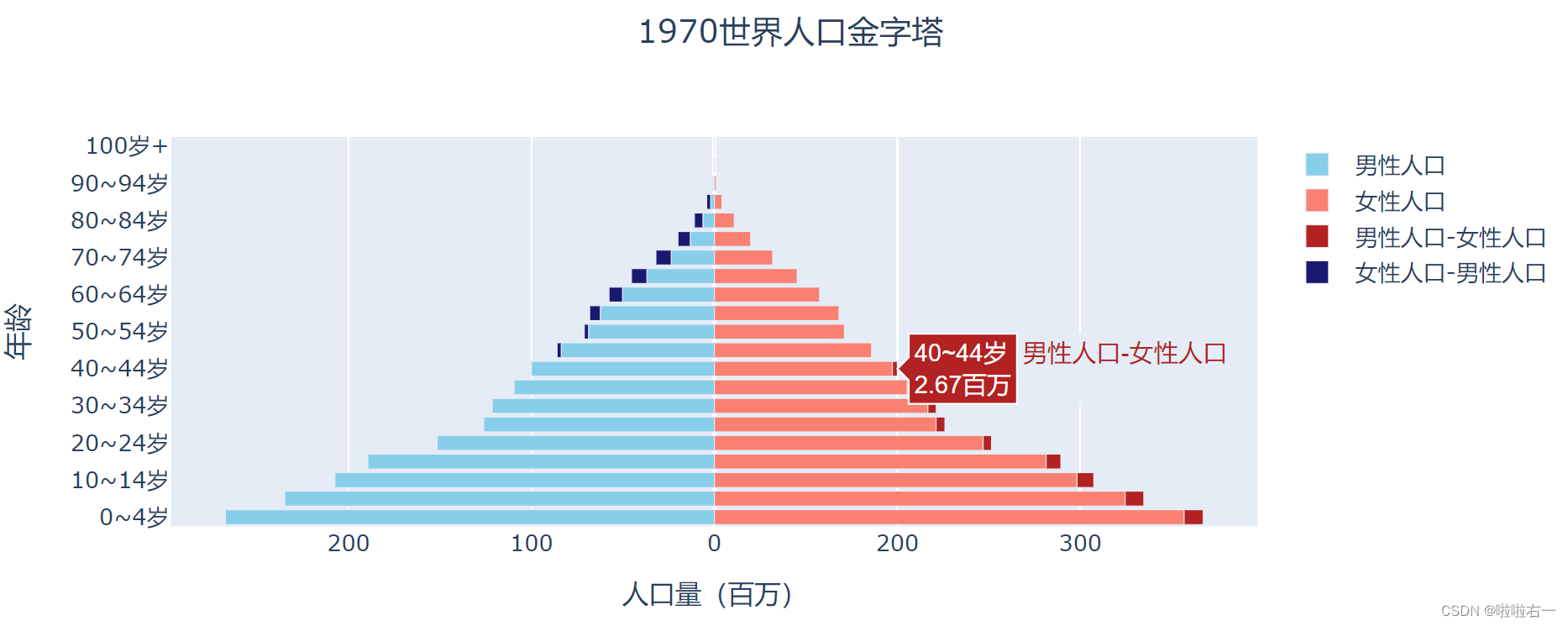
🐇气泡图
- 散点大小由数值决定——气泡图。
- 气泡图通常用于展示和比较数据之间的关系和分布,通过比较气泡位置和大小来分析数据维度之间的相关性。所以比较经济、人口等数据时,气泡图就是首选的工具之一。
- 从散点图开始
import pandas as pd from plotly.graph_objects import Figure, Scatter from plotly.colors import qualitative path = './data/全球预期寿命.xlsx' data = pd.read_excel(path, sheet_name ='2019') data_asia = data[data['continent']=='Asia'] fig = Figure() trace_asia = Scatter( x=data_asia['male'], y=data_asia['female'], name='Asia', # 设置为点模式 mode='markers', # 设置散点颜色,从自带配色方案中取色 marker_color=qualitative.Set2[0], # 设置附加文本 text=data_asia['entity'] ) fig.add_trace(trace_asia) fig.show()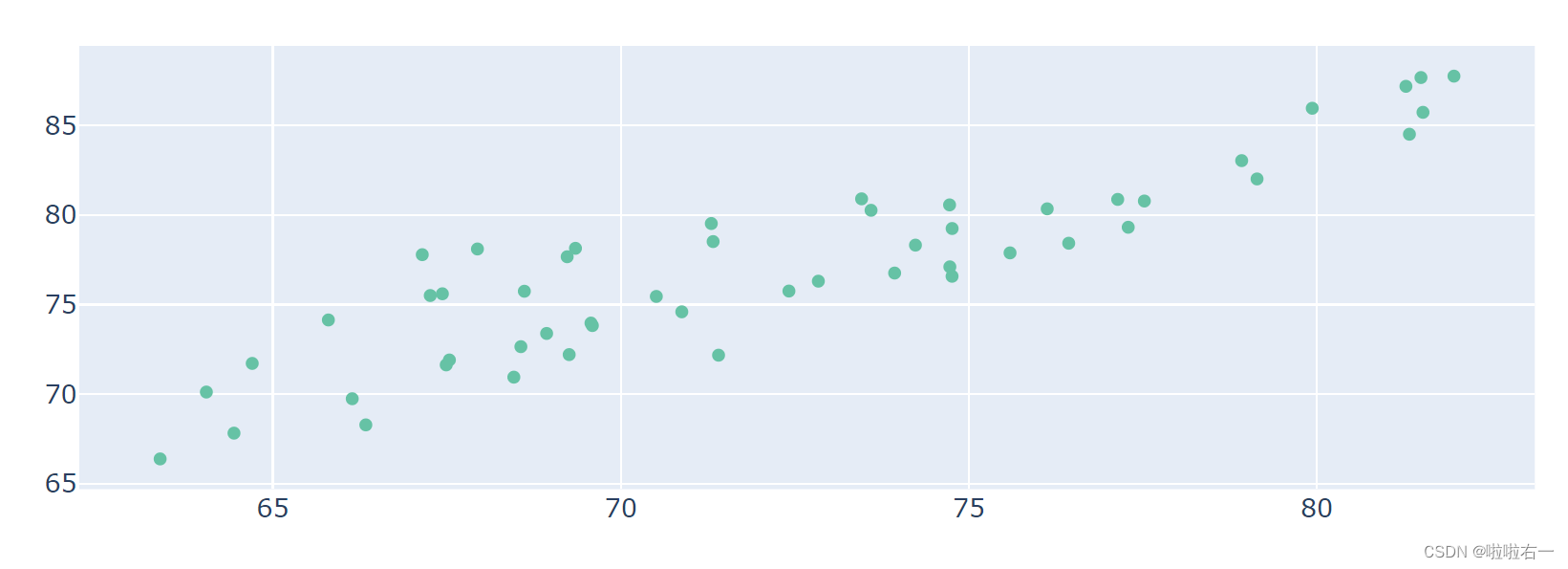
- 设置散点大小
marker_size用来规定每个散点的大小。如果要分别指定每个散点的大小,可以传入由多个数字组成的列表,保持其中的元素和 trace 中的每个点一一对应,这样,散点就会变成大小各异的“气泡”。marker_sizemode,用来规定大小对比的模式,分为'area',代表用气泡面积去体现marker_size中的数字大小关系;另一种模式是'diameter',代表用气泡半径对比。由于圆面积公式 ( S = π ∗ r ∗ r ) (S = π * r * r) (S=π∗r∗r)包含了半径的二次方,总是会把对比不适当地扩大。当倍数越大,这种视觉上的失真就越严重。所以,我们一般情况下都推荐使用气泡面积的对比去体现数据真实的大小关系。
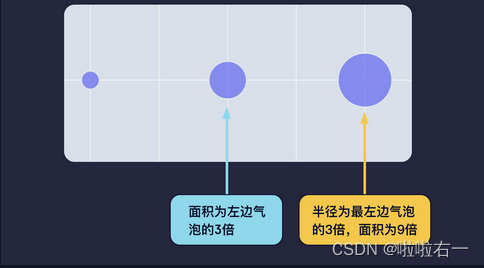
- 大国的人口是以亿为单位的!直接把人口数传进图里,气泡会大到爆炸!所以,我们要对人口数据进行“缩放”处理后,再传给 marker_size 参数。
- 先“缩小最大的”,最大的气泡不能过大,否则遮盖过多的其它气泡;再“放大最小的”,最小的气泡不能太小,否则就在图上看不见啦。我们要保证所有气泡都可以用合适的大小呈现。
大小 = 人口 / 280 万 + 6
import pandas as pd from plotly.graph_objects import Figure, Scatter from plotly.colors import qualitative path = './data/全球预期寿命.xlsx' data = pd.read_excel(path, sheet_name ='2019') data_asia = data[data['continent']=='Asia'] fig = Figure() # 定义人口缩放的函数 def pop_to_size(num): scaled_num = num/2800000 + 6 return scaled_num # 统一缩放人口数据 size = [pop_to_size(num) for num in data_asia['population']] trace_asia = Scatter( x=data_asia['male'], y=data_asia['female'], name='Asia', # 设置为点模式 mode='markers', # 设置散点颜色,从自带配色方案中取色 marker_color=qualitative.Set2[0], # 设置附加文本 text=data_asia['entity'], # 用缩放过的人口设置散点大小 marker_size=size, # 设置大小对比模式 marker_sizemode='area' ) fig.add_trace(trace_asia) fig.show()
- 加入多个trace :加入for循环
import pandas as pd from plotly.graph_objects import Figure, Scatter from plotly.colors import qualitative path = './data/全球预期寿命.xlsx' data = pd.read_excel(path, sheet_name ='2019') fig = Figure() # 定义人口缩放的函数 def pop_to_size(num): scaled_num = num/2800000 + 6 return scaled_num # 创建大洲列表 continents = ['Asia', 'Europe', 'Africa', 'North America', 'South America', 'Oceania'] # 开始 6 次循环 for i in range(6): # 通过索引获得当前洲 continent = continents[i] # 筛选出属于当前洲的数据 data_continent = data[data['continent']==continent] # 缩放当前洲各地区的人口 size = [pop_to_size(num) for num in data_continent['population']] # 生成气泡 trace trace = Scatter( # trace 名为当前的洲 name=continent, x=data_continent['male'], y=data_continent['female'], mode='markers', # 从配色方案 Set2 中以 i 作索引取色 marker_color=qualitative.Set2[i], text=data_continent['entity'], # 根据缩放值设定气泡面积大小 marker_size=size, # 设定大小对比模式为面积对比 marker_sizemode='area', ) # 将当前 trace 加入图表 fig.add_trace(trace) fig.show()
- 加入等值线
- 目前的图,还没有办法让我们快速判断,女性的寿命是不是普遍比男性高。这时候我们需要画一条 y = x 的辅助线,通过气泡和 y = x 线的相对位置,来看看所有气泡的分布情况。
- 我们在男女预期寿命气泡图中加入 y = x 辅助线后,可以观察,如果气泡位于线上方,说明 y > x,也就是该地区女性预期寿命高于男性,反之则低于男性。
trace_line = Scatter( x=[55, 85], y=[55, 85], name='男女寿命等值线', mode='lines', # 设置线段样式 line=dict( # 颜色设为灰色 color='Grey', # 宽度设为 0.5 width=0.5, # 线型设为点线 dash='dot' ) ) fig.add_traces(trace_line)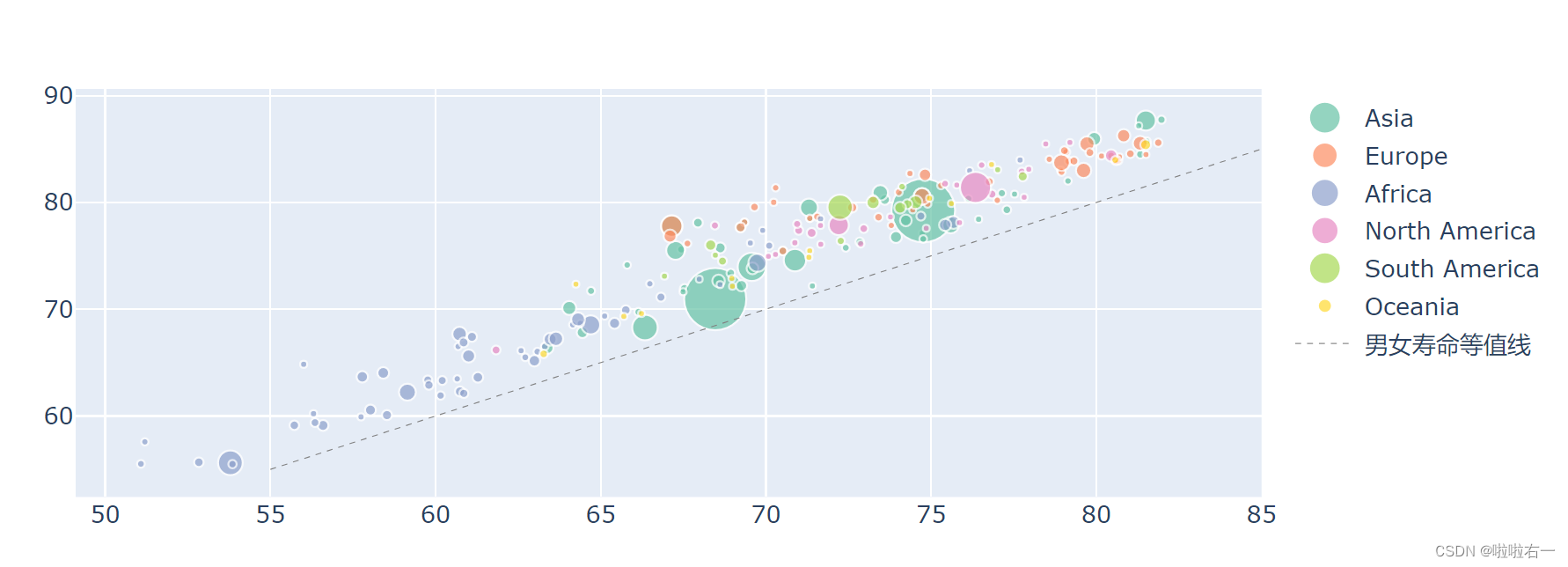
- 添加标题
fig.update_layout( # 设置图表标题,20 号字体居中 title=layout.Title( text='全球男女预期寿命对比图', x=0.5, font=dict(size=20) ), # 设置 x 轴标题 xaxis=layout.XAxis(title=dict(text='男性预期寿命')), # 设置 y 轴标题 yaxis=layout.YAxis(title=dict(text='女性预期寿命')) )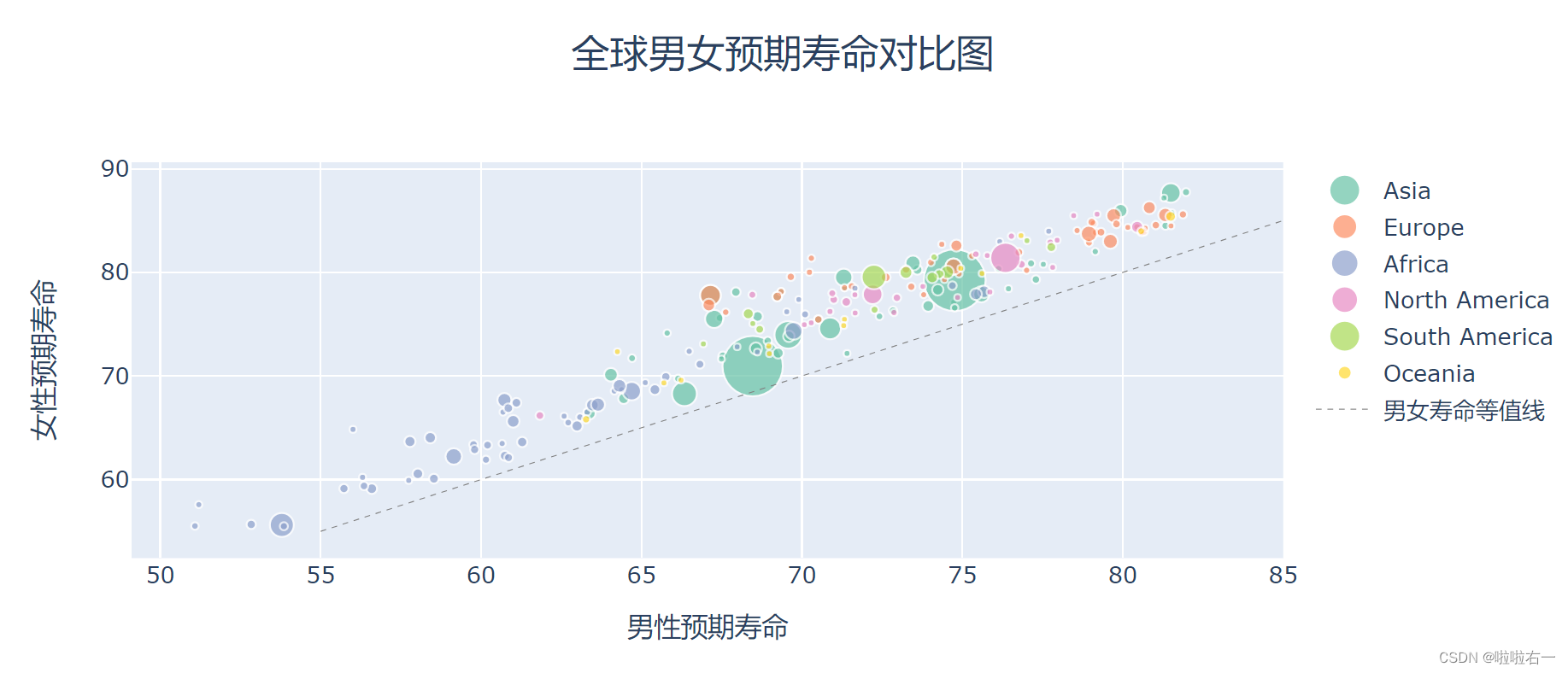
- 最终完整代码
import pandas as pd from plotly.graph_objects import Figure, Scatter,layout from plotly.colors import qualitative path = './data/全球预期寿命.xlsx' data = pd.read_excel(path, sheet_name ='2019') fig = Figure() # 定义人口缩放的函数 def pop_to_size(num): scaled_num = num/2800000 + 6 return scaled_num # 创建大洲列表 continents = ['Asia', 'Europe', 'Africa', 'North America', 'South America', 'Oceania'] # 开始 6 次循环 for i in range(6): # 通过索引获得当前洲 continent = continents[i] # 筛选出属于当前洲的数据 data_continent = data[data['continent']==continent] # 缩放当前洲各地区的人口 size = [pop_to_size(num) for num in data_continent['population']] # 生成气泡 trace trace = Scatter( # trace 名为当前的洲 name=continent, x=data_continent['male'], y=data_continent['female'], mode='markers', # 从配色方案 Set2 中以 i 作索引取色 marker_color=qualitative.Set2[i], text=data_continent['entity'], # 根据缩放值设定气泡面积大小 marker_size=size, # 设定大小对比模式为面积对比 marker_sizemode='area', ) # 将当前 trace 加入图表 fig.add_trace(trace) # 绘制男女寿命等值线加入图表 trace_line = Scatter( x=[55, 85], y=[55, 85], name='男女寿命等值线', mode='lines', # 设置线段样式 line=dict( # 颜色设为灰色 color='Grey', # 宽度设为 0.5 width=0.5, # 线型设为点线 dash='dot' ) ) fig.add_traces(trace_line) # 添加标题和轴标题 fig.update_layout( # 设置图表标题,20 号字体居中 title=layout.Title( text='全球男女预期寿命对比图', x=0.5, font=dict(size=20) ), # 设置 x 轴标题 xaxis=layout.XAxis(title=dict(text='男性预期寿命')), # 设置 y 轴标题 yaxis=layout.YAxis(title=dict(text='女性预期寿命')) ) fig.show()
-
所有的气泡都在男女寿命等值线的上方,说明全世界所有地区,女性的寿命都长于男性。
-
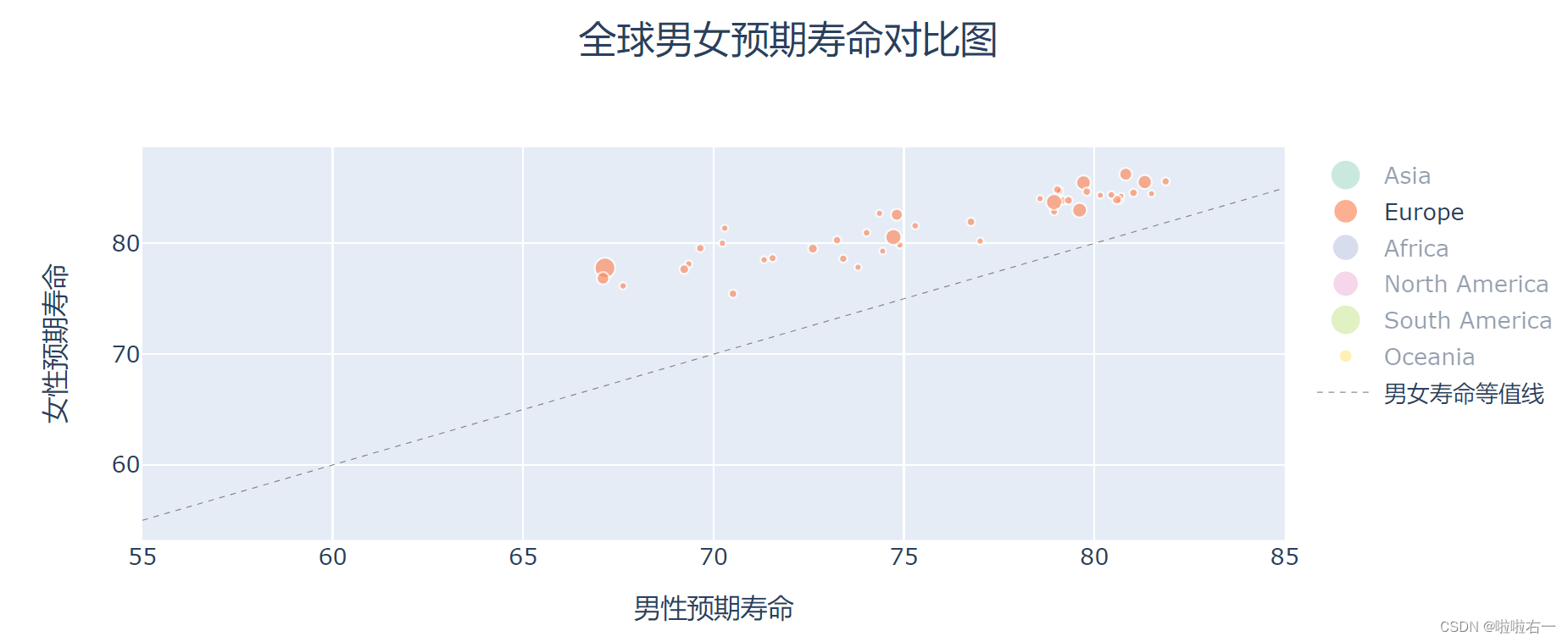
欧洲:在男性寿命 77 岁的位置,有一个明显的分界线,分界线左边基本都在 65 岁到 75 岁,右边基本都在 78 到 82 岁。鼠标停留在左边的气泡团,会发现基本都是东欧和南欧地区,而右边基本都是西欧和北欧,社会发展水平很高的地区。
-
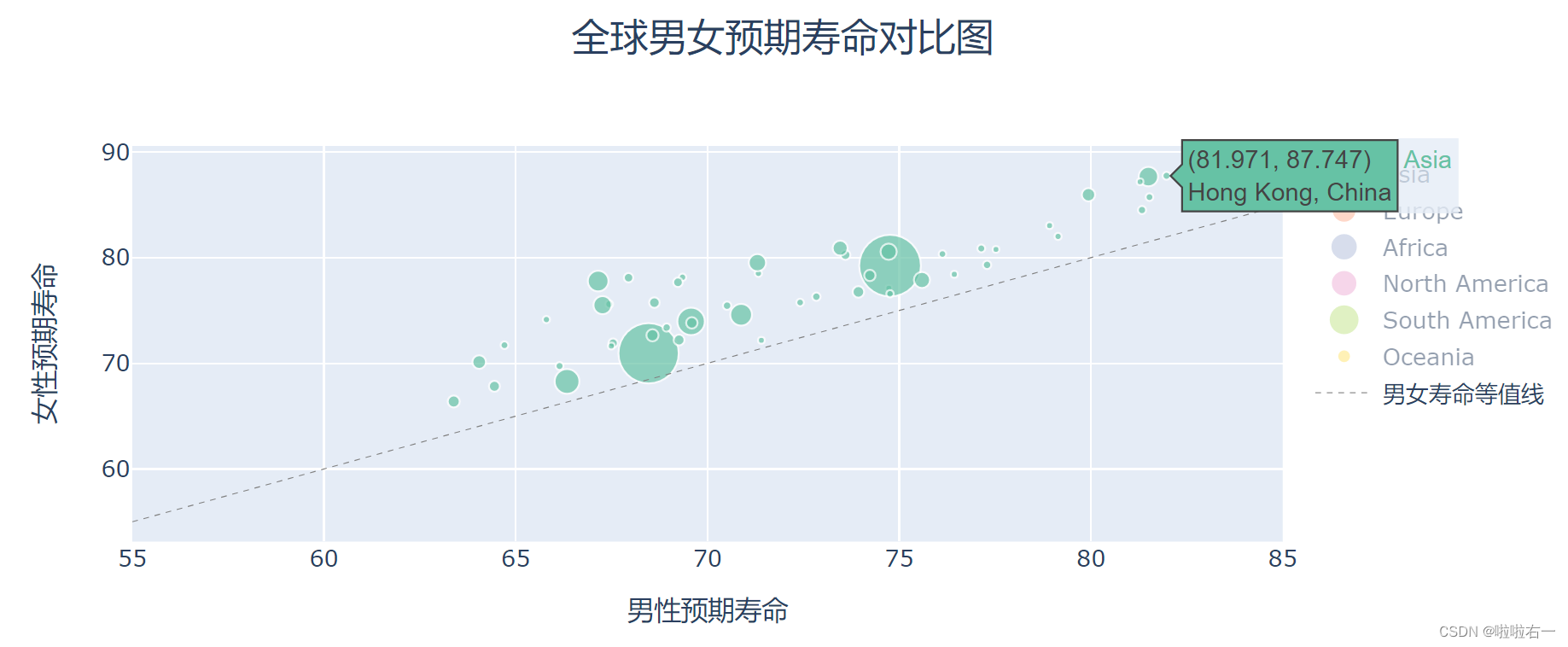
亚洲: 亚洲地区数据较多,分布广泛,可以看到,最右上角,有四个气泡特别突出:中国香港地区,中国澳门地区,新加坡和日本。这四个地区男性预期寿命在 80 岁以上,女性 85 岁以上。这也是亚洲最发达的四个地区。中国大陆地区是两个最大气泡中,靠右的那个,处于亚洲的中上水平,男性平均 74 岁,女生 79 岁。靠左的大气泡是印度,处于亚洲的中下水平。
-
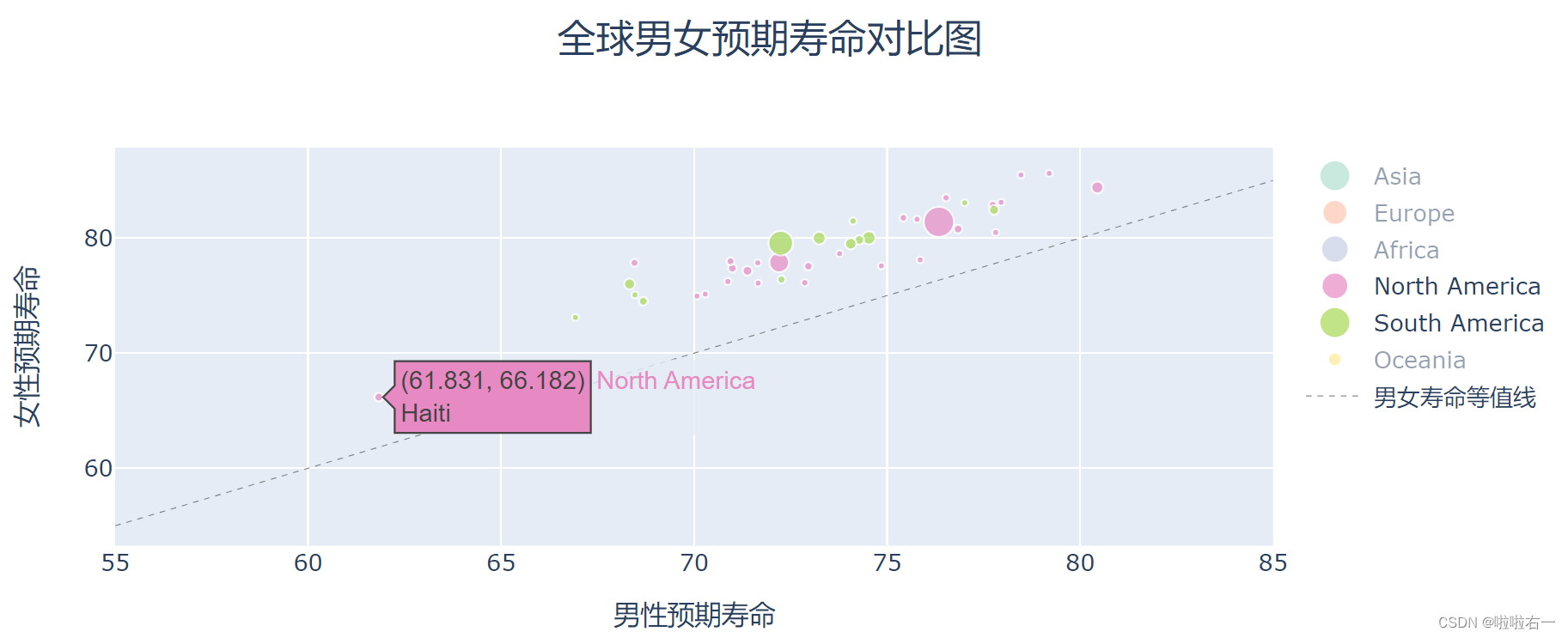
南北美:除了最左下角的海地,和最右上角的加拿大,其它地区的分布比较均匀。美国是最大的粉色气泡,其人均寿命比较意外,在美洲中不算突出。
-
非洲:在各个区间都有分布,但位于左下角的气泡尤其多,说明男性预期寿命小于 65 岁,女性小于 70 岁的地区很多。
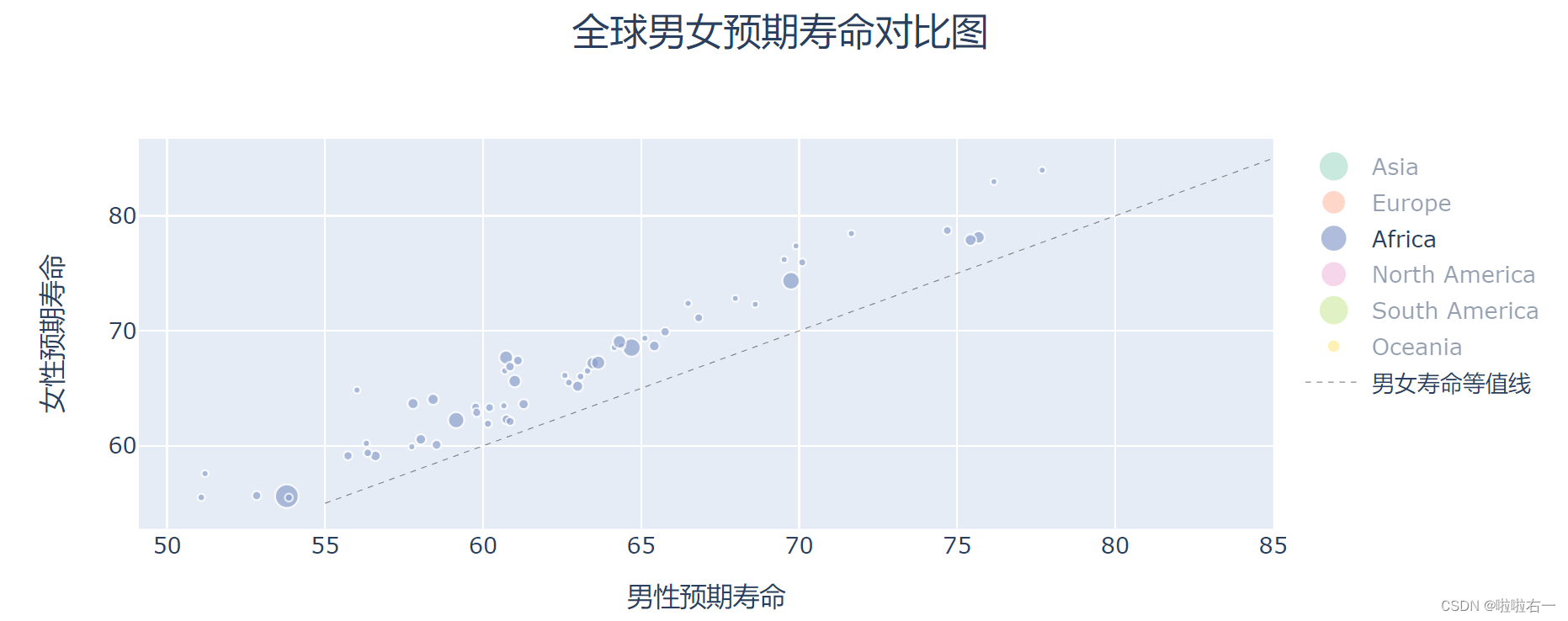
-
基本上越发达的地区,人的寿命越长。
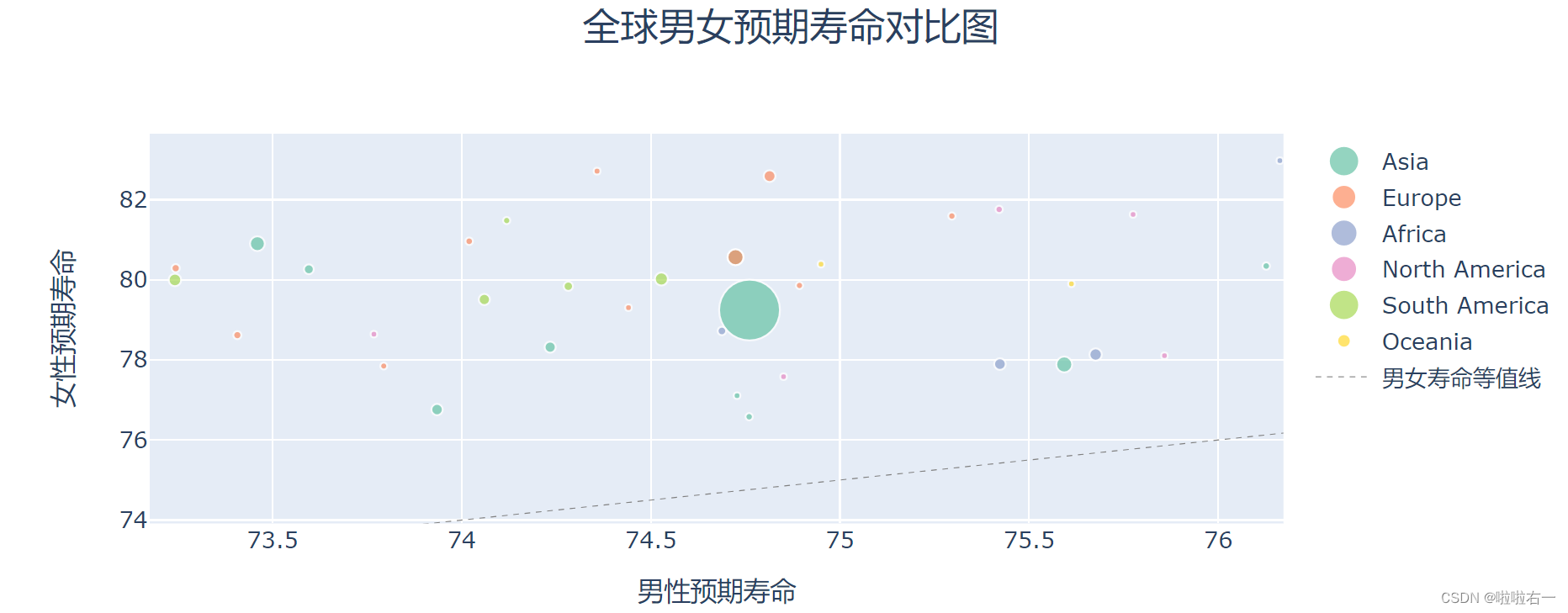
-
这个图表的信息量太充足,我们还可以继续探索,看看和中国大陆水平相近的有哪些地区。我们可以在图表上通过鼠标拖动来选中一小片区域,然后这片区域会自动放大,如果要将图表复原,双击图表就可以:
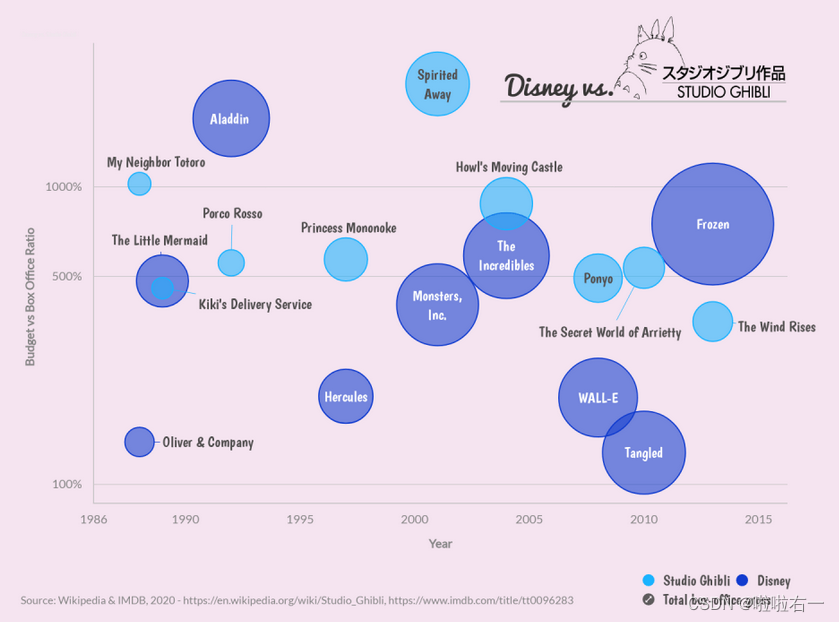
- 相比散点图,气泡图更适合去展现多维数据。如下气泡图,展现美国迪士尼公司和日本吉卜力工作室出品的动画电影的预算/票房比,气泡越大,说明电影在商业上越成功。
🐇面积图
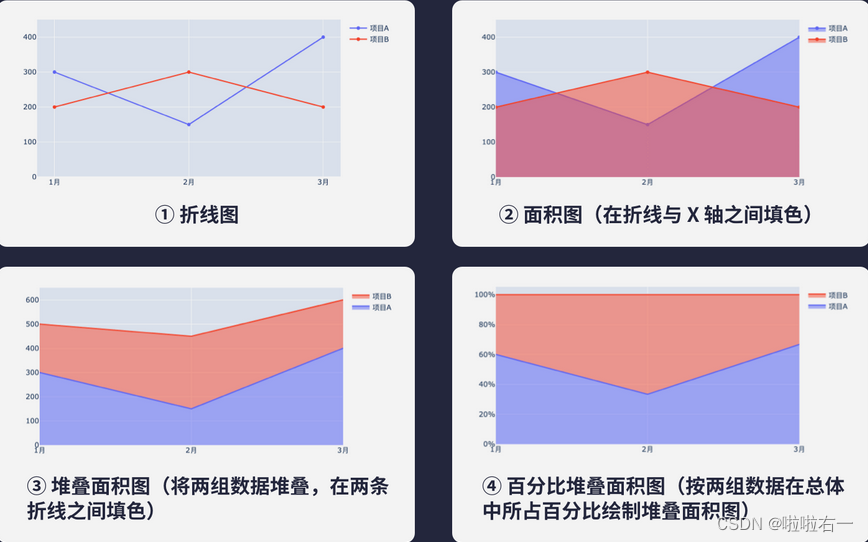
在折线图到 X 轴之间的区域填上颜色,得到的就是 面积图了
-
先从折线图开始
import pandas as pd from plotly.graph_objects import Figure, Scatter, layout path = './data/全球智能手机市场份额占比.xlsx' data = pd.read_excel(path, sheet_name ='近10年') # 创建空图表 fig_area = Figure() # 分别读取 Huawei,Xiaomi 和 Apple 这三列数据,创建折线 trace trace0 = Scatter(name='Huawei',x=data['季度'],y=data['Huawei'],mode='lines') trace1 = Scatter(name='Xiaomi',x=data['季度'],y=data['Xiaomi'],mode='lines') trace2 = Scatter(name='Apple',x=data['季度'],y=data['Apple'],mode='lines') fig_area.add_trace(trace0) fig_area.add_trace(trace1) fig_area.add_trace(trace2) fig_area.show()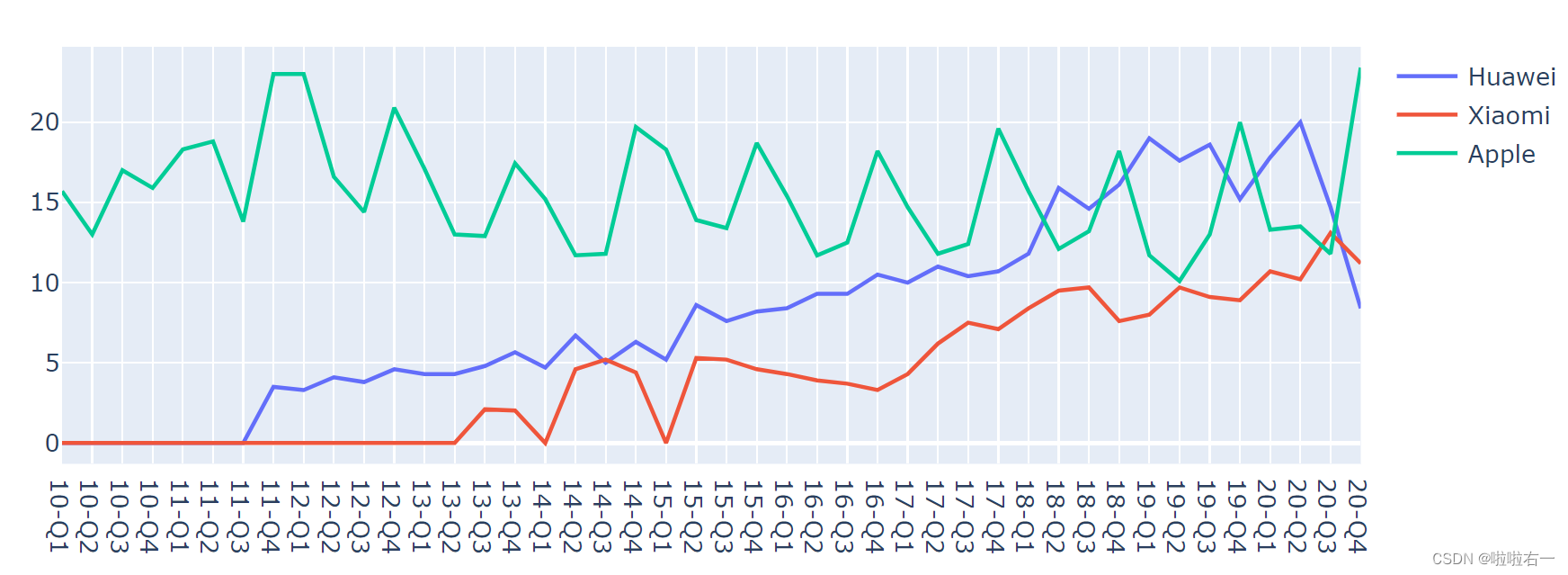
-
开始填色
stackgroup能将某几个 trace 的折线堆叠在一起,并自动为这些 trace 设置 fill 参数,得到堆叠面积图的效果。它的值可以是一个数字或一个字符串,stackgroup相同的 trace 都在同一个堆叠组内,会被堆叠到一起。- 如果某个 trace 的 stackgroup 与其它 trace 不同,那它就不会与其他 trace 堆到一起。
fig_area.update_traces(selector={'name':'Huawei'},stackgroup='Android') fig_area.update_traces(selector={'name':'Xiaomi'},stackgroup='Android') fig_area.update_traces(selector={'name':'Apple'},stackgroup='iOS')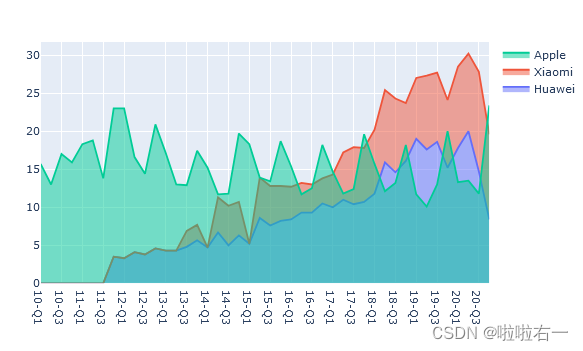
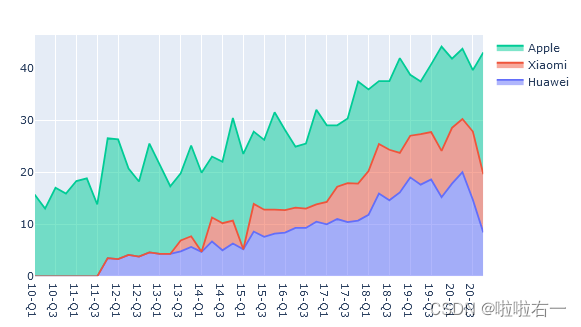
- 我们统一设置
stackgroup:fig_area.update_traces(stackgroup='brand')
-
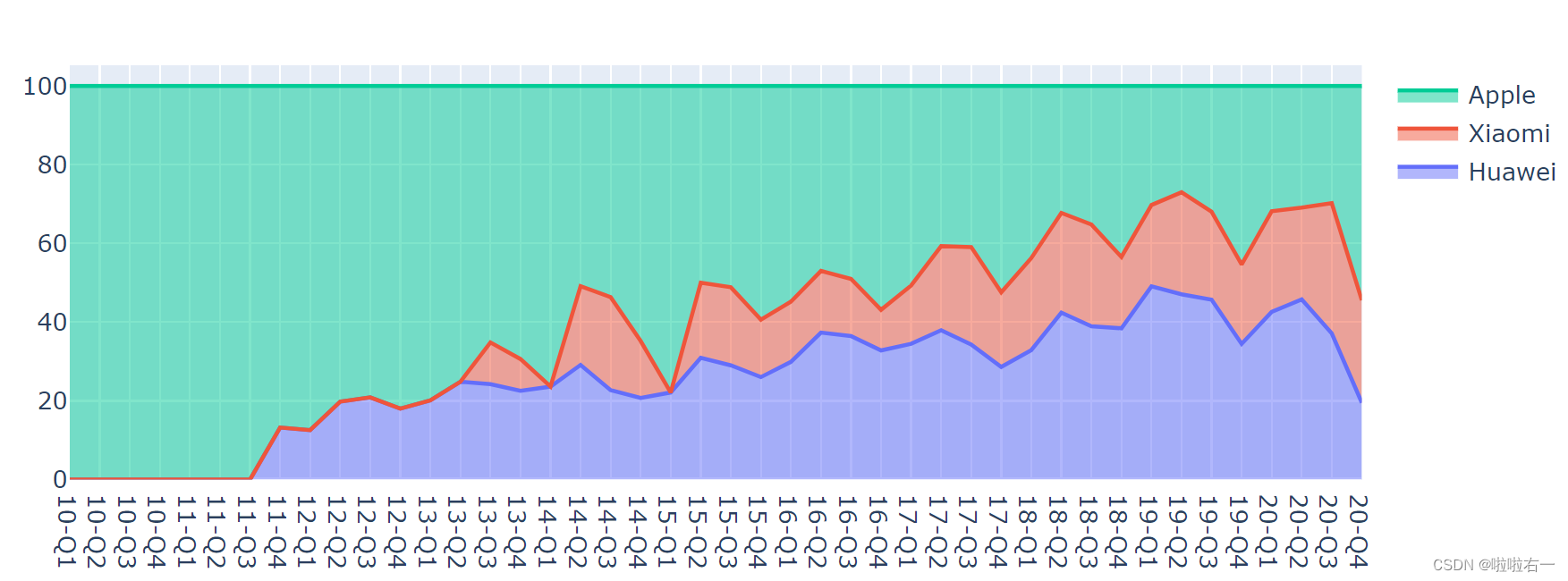
修改为百分比堆叠图:groupnorm 参数
- 普通模式 (
groupnorm = ''):最普通的堆叠面积图; - 百分比模式 (
groupnorm = 'percent'):自动计算各 trace 数据在整体中所占的百分比 (0%~100%),按百分比堆叠。 - 一旦你对图表中的某一个 trace 设置了 groupnorm 参数,那这个参数就会对整个图表生效,在这之后,对其他 trace 设置的 groupnorm 就不起作用了。
fig_area.update_traces(groupnorm='percent')
- 普通模式 (
-
循环创建多个trace
...省略读取源数据和导入模块的代码 # 生成空图表 fig_area = Figure() brands = data.columns[1:] # 读取品牌数据作为 Y 值,每读取一列添加一个 trace for i in range(len(brands)): brand = brands[i] trace = Scatter(name=brand, x=data['季度'], y=data[brand], # 设置当前 trace 的附加文本,用于生成悬浮标签 text=['当季市场份额:{}%'.format(i) for i in data[brand]]) fig_area.add_trace(trace) # 设置图表为百分比堆叠面积图 fig_area.update_traces(mode='lines', stackgroup='brand', groupnorm='percent', # 设置悬浮标签包含季度、品牌名称和当季市场份额 hoverinfo='x+text+name') fig_area.show()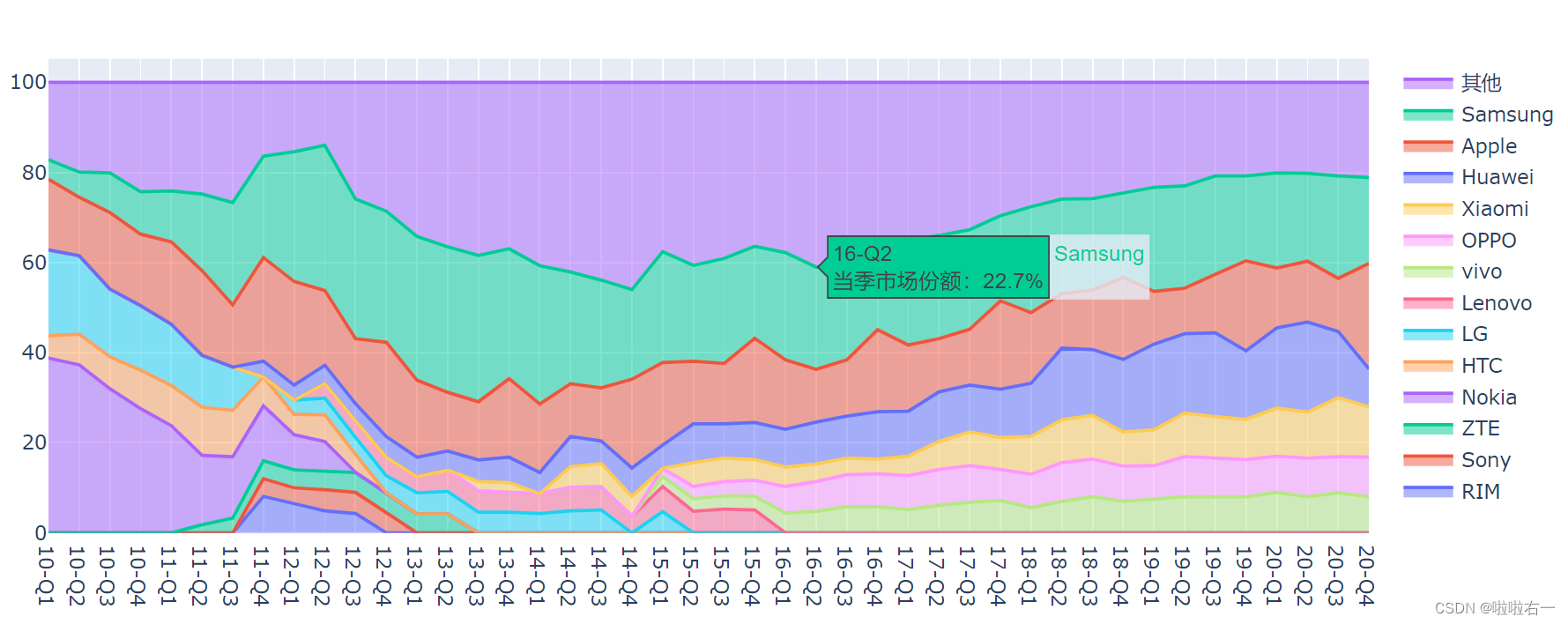
-
图表美化
-
Plotly 中,堆叠面积图会自动取折线的颜色来填充折线下方的区域。所以,设置面积图的配色,也就相当于是设置折线的配色。
-
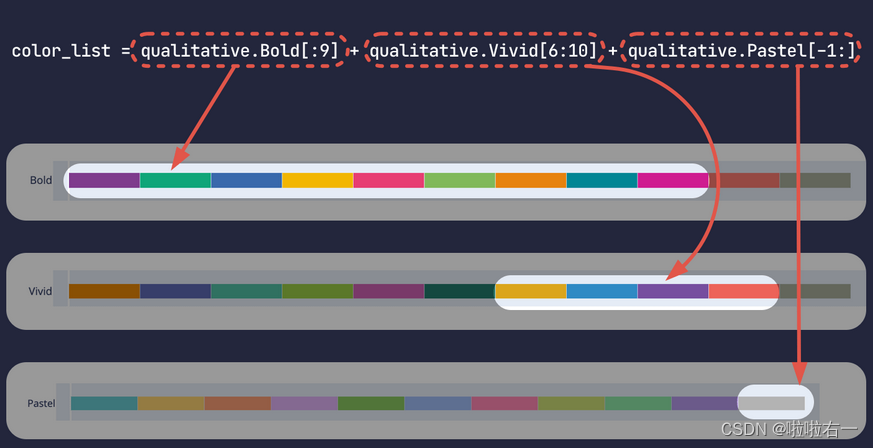
qualitative 和 sequential 模块中的配色方案,实际值都是列表。用 qualitative.配色方案名[索引] 的形式去获取配色方案中的具体颜色。
-
创建颜色列表:
color_list = qualitative.Bold[:9] + qualitative.Vivid[6:10] + qualitative.Pastel[-1:]
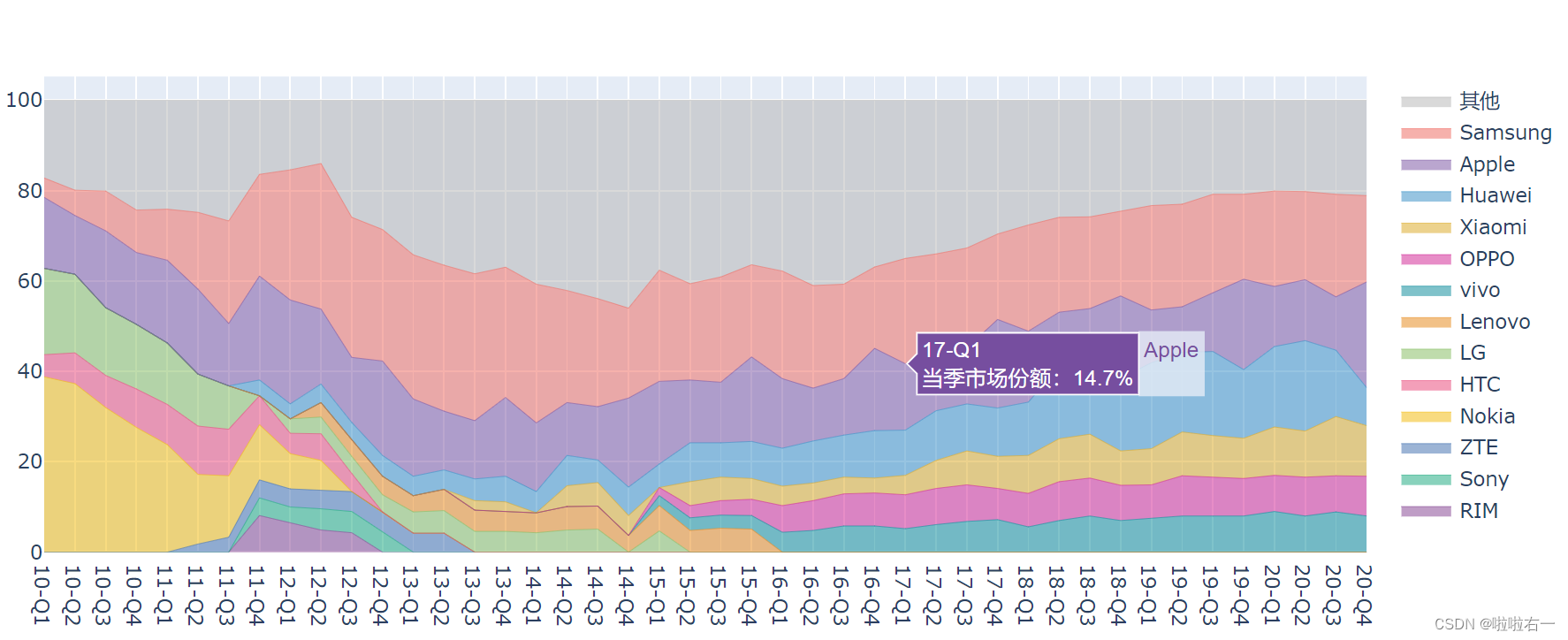
# 读取品牌数据作为 Y 值,每读取一列添加一个 trace for i in range(len(brands)): brand = brands[i] trace = Scatter( name=brand,x=data['季度'],y=data[brand], text=['当季市场份额:{}%'.format(i) for i in data[brand]], line=dict( # 修改折线宽度为 0.3px,让生成图表更美观 width=0.3, # 读取 color_list 中的颜色值设置折线颜色 color=color_list[i]) ) fig_area.add_trace(trace)
-
-
设置坐标轴:Y 轴刻度需要设为 [20%, 40%, 60%, 80%, 100%],X 轴刻度需要添加倾斜效果,图表标题为 全球智能手机市场份额占比(2010~2020)。
- Y 轴最终显示的刻度是 [20%, 40%, 60%, 80%, 100%],这可以用
ticktext去设置,刻度对应的实际值应当是 [20, 40, 60, 80, 100],可以用tickvals传入。 - 100% 对应的折线没有贴到图表的最上侧,中间多出来了一片空白:通过
range参数规定 Y 轴的范围。 - 用
tickangle属性来设置文本倾斜,横排文本默认向下旋转,竖排文本默认向右旋转,设置 tickangle=-45,在这里的意思是让文本向左旋转 45%。
# 设置 X 轴刻度向左旋转 45° fig_xaxis = layout.XAxis(tickangle=-45) # 设置 Y 轴范围和刻度值 fig_yaxis = layout.YAxis(range=[0, 100], tickvals=[20, 40, 60, 80, 100], ticktext=['20%', '40%', '60%', '80%', '100%']) # 实例化图表标题,并设为水平居中 fig_title = layout.Title(text='全球智能手机市场份额占比(2010~2020)', x=0.5) # 将 X、Y 轴和图表标题添加到图表 fig_area.update_layout(title=fig_title,xaxis=fig_xaxis,yaxis = fig_yaxis)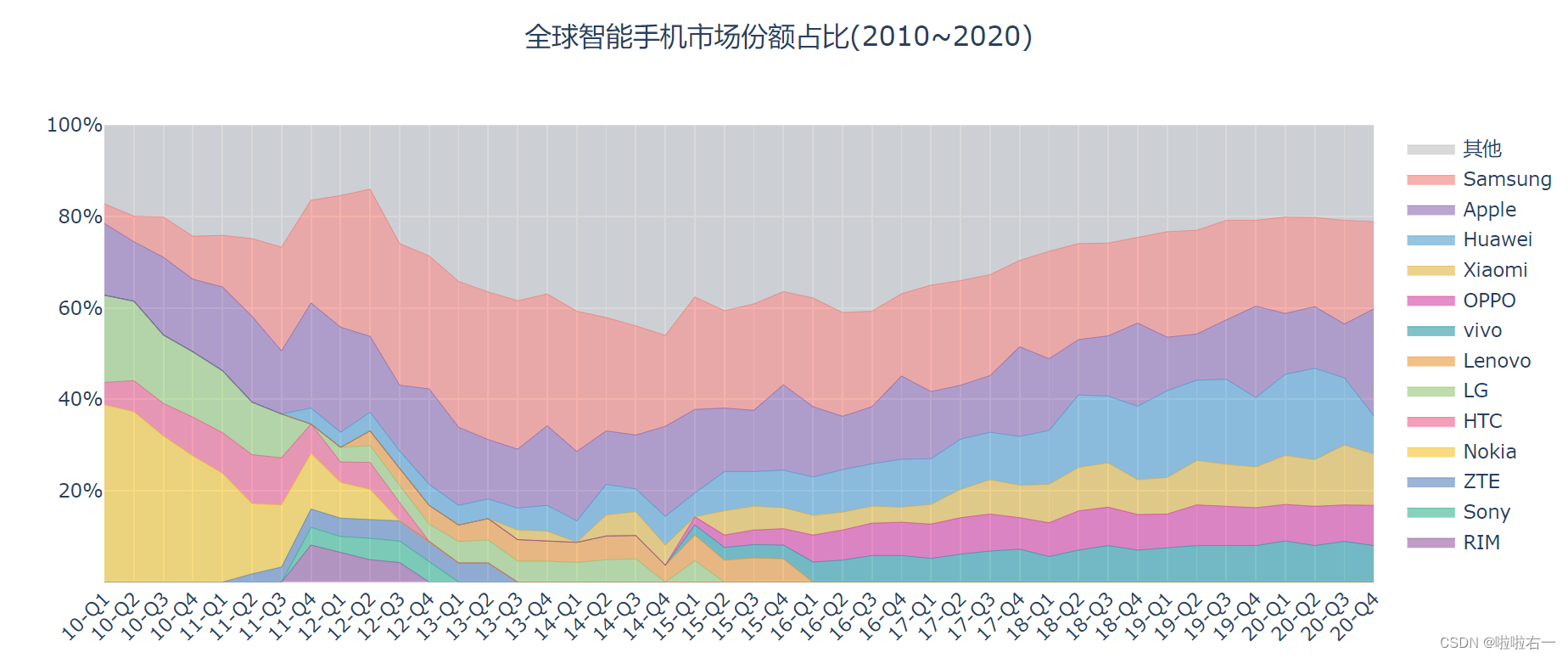
- Y 轴最终显示的刻度是 [20%, 40%, 60%, 80%, 100%],这可以用
- 最终完整代码
import pandas as pd from plotly.graph_objects import Figure, Scatter, layout from plotly.colors import qualitative path = './data/全球智能手机市场份额占比.xlsx' data = pd.read_excel(path, sheet_name ='近10年') # 生成空图表 fig_area = Figure() # 读取品牌名称 brands = data.columns[1:] # 创建颜色列表 color_list = qualitative.Bold[:9] + qualitative.Vivid[6:10] + qualitative.Pastel[-1:] # 读取品牌数据作为 Y 值,每读取一列添加一个 trace for i in range(len(brands)): brand = brands[i] trace = Scatter( name=brand,x=data['季度'],y=data[brand], text=['当季市场份额:{}%'.format(i) for i in data[brand]], line=dict( # 修改折线宽度为 0.3px,让生成图表更美观 width=0.3, # 读取 color_list 中的颜色值设置折线颜色 color=color_list[i]) ) fig_area.add_trace(trace) # 设置图表为百分比堆叠面积图 fig_area.update_traces(mode='lines', stackgroup='brand', groupnorm='percent', hoverinfo='x+text+name') # 设置 X 轴标签向左旋转 45° fig_xaxis = layout.XAxis(tickangle=-45) # 设置 Y 轴范围和刻度值 fig_yaxis = layout.YAxis(range=[0, 100], tickvals=[20, 40, 60, 80, 100], ticktext=['20%', '40%', '60%', '80%', '100%']) # 实例化图表标题,并设为水平居中 fig_title = layout.Title(text='全球智能手机市场份额占比(2010~2020)', x=0.5) # 将 X、Y 轴和图表标题添加到图表 fig_area.update_layout(title=fig_title,xaxis=fig_xaxis,yaxis = fig_yaxis) # 展示生成的图表 fig_area.show()
- 12 年左右的智能手机市场可谓“群雄逐鹿”,那时巨头还没陨落,新秀尚未崛起。请看图表中的左半部分,堆叠起来的色块相当多,这也就说明那几年间,有很多活跃在市场上的手机品牌。
- 16 年起,以 Huawei、Xiaomi 为代表的国产手机品牌逐渐在国际市场上夺得了一席之地,到 2020 年末,Huawei、Xiaomi、OPPO 以及 vivo 这四个国产品牌,市场份额总计可达 40% 左右,几乎占据了全球市场的半壁江山。
- 上图中包含的细节远不止这些,我们还能看到黑莓手机 (RIM) 和索尼手机 (Sony) 的昙花一现,老牌国产手机 HTC 的沉寂,甚至还能看出苹果手机的销量变化规律——每逢 Q4 发布新品,市场份额总要上涨一波。
-
堆叠面积图适合用来观察几组数据随着时间的变化情况,在堆叠面积图中,我们既能看到每组数据的走势,又能看到整体规模的变化趋势。这张图表展示的是 1977 年来音乐行业的利润构成。早期利润大部分都来自黑胶唱片 (vinyl),80 年代磁带 (cassette) 风靡一时,1985 开始,光盘 (compact disc) 又迅速崛起,并在之后的很长一段时间占据市场主流。
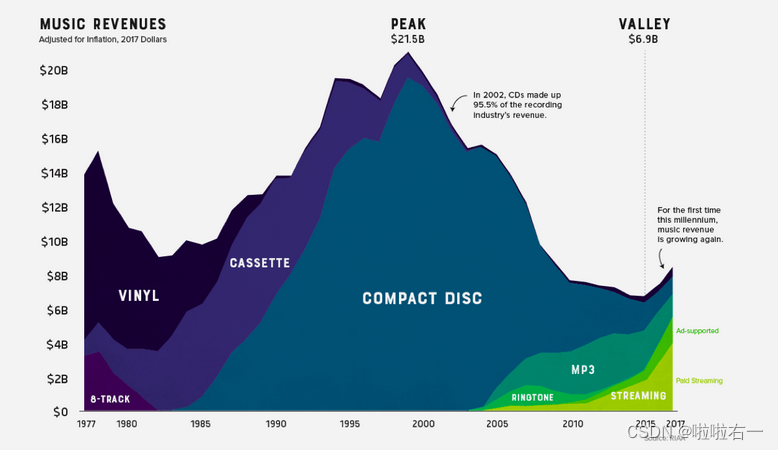
-
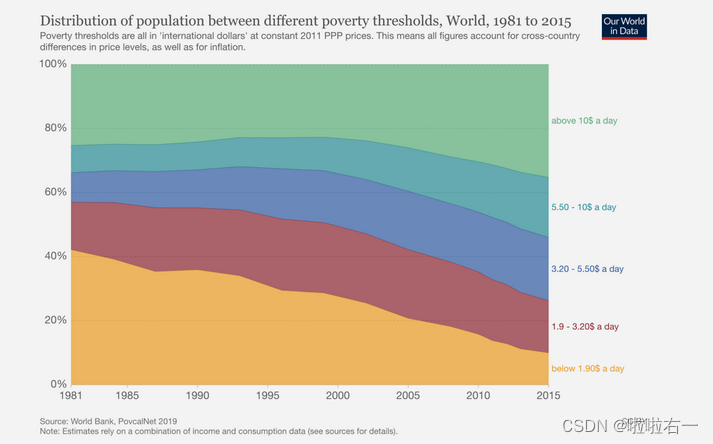
堆叠面积图能够突出整体规模的变化,百分比堆叠面积图则更侧重于各组数据占总体的比例。下面这张百分比堆叠面积图,展现了 1981 年来贫困人口占比的变化。可以看到,黄色区域代表的绝对贫困人口(每日收入不足 1.90 美元)占比已经显著下降了:
⭐️快速作图工具:plotly.express
- plotly.express(后面简称 px)是作图的快速通道。
- 之前我们都是从 plotly.graph_objects 中导入 Figure 创建空图表,导入 Bar、 Scatter 等来创建图表对应的 trace。
- 如果数据存在 Excel 表里,我们还需要用 pandas 把表格中的数据读取为 DataFrame,再按列读取数据赋值给 x 参数或 y 参数。
- px 模块封装了 plotly.graph_objects 中的类和方法,不仅如此,它还能和 pandas 无缝结合,让图表创建的过程变得更方便快捷。
import pandas as pd # from plotly.graph_objects import Figure, Bar import plotly.express as px path = './data/px模块示例.xlsx' df = pd.read_excel(path, sheet_name ='柱状图') # fig = Figure() # trace0 = Bar(x=df['产品名称'], # y=df['销量']) # fig.add_traces(trace0) fig = px.bar(df, x='产品名称', y='销量') fig.show()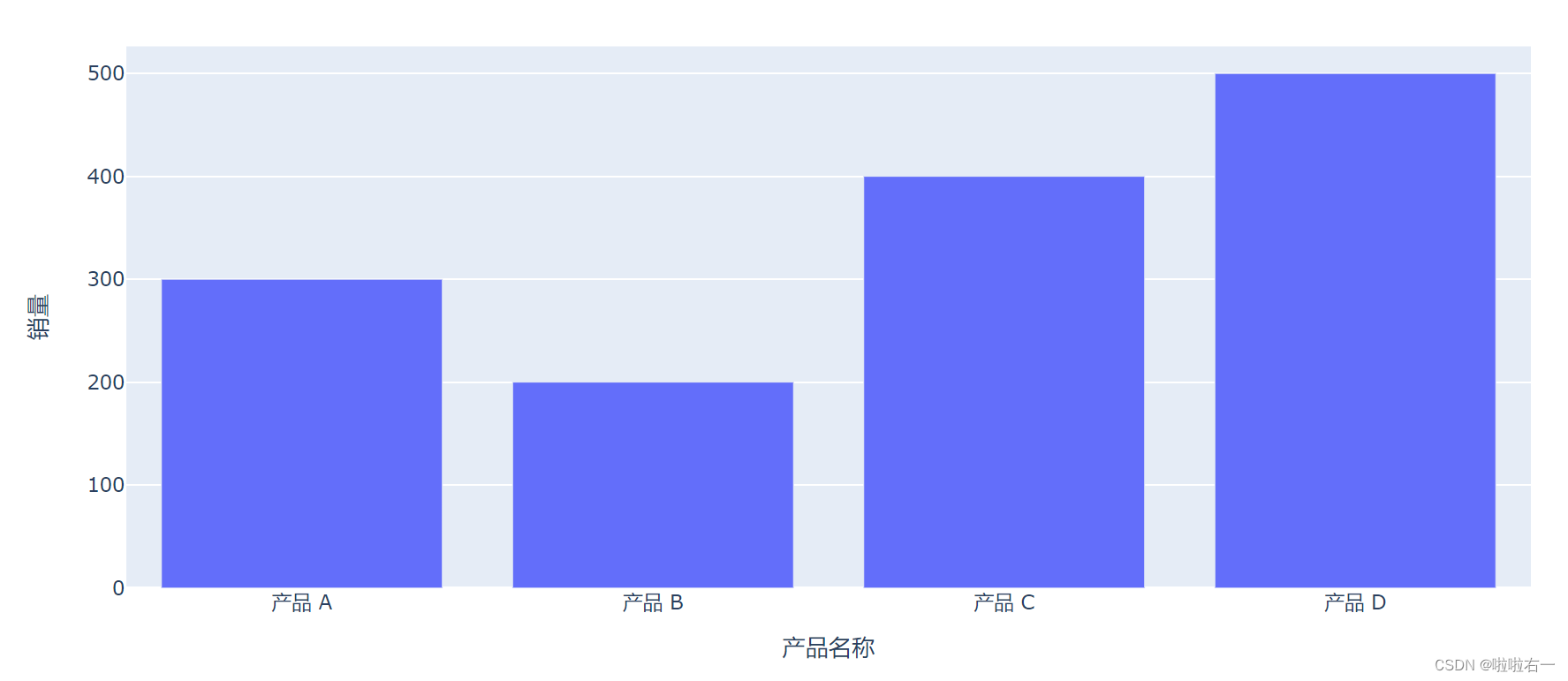
- 树状图,源数据层级结构复杂,用 plotly.graph_objects 从底层构造要花不少时间,还很容易出错。如果用上 px 模块,一个函数就能解决问题。
- plotly.express详解
🐇树形图
- 树状图的绘制,用的是 px 模块中的
treemap()函数。 treemap()函数有两个关键参数,path 参数意为“路径”,也就是构造层级的路径,我们用它来说明层级之间的包含关系,values 参数用于指定树状图中各个矩形的大小:fig_treemap = px.treemap(data, path=['一级类别', '二级类别', '三级类别'], values='百分比') fig_treemap.show()
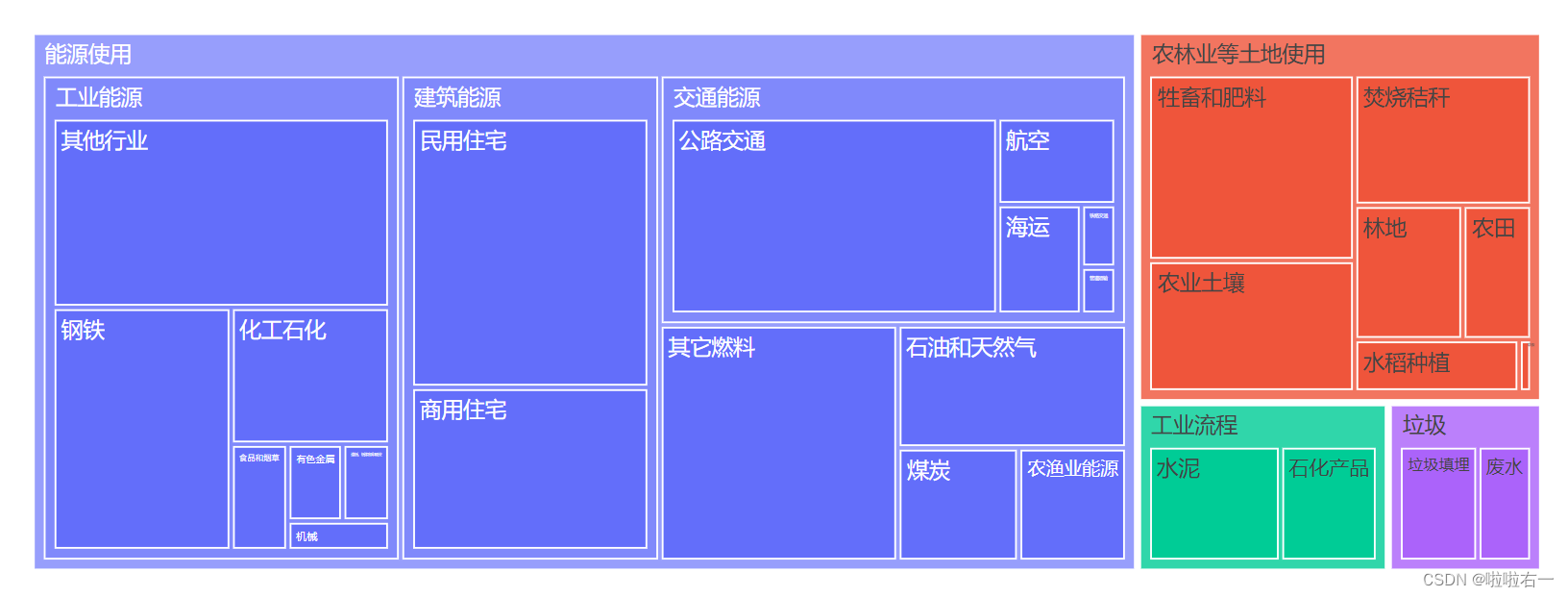
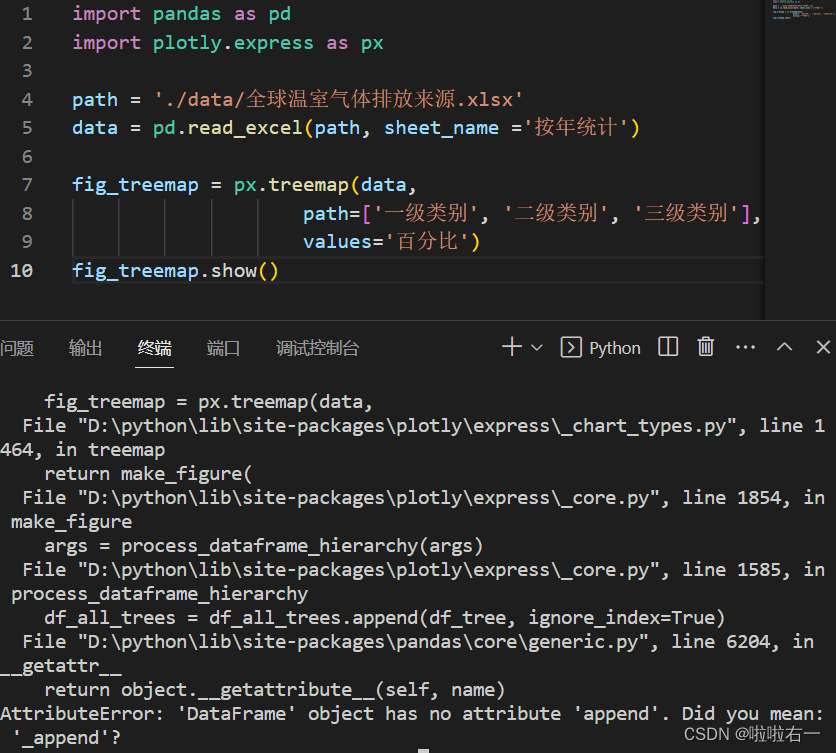
- 【异常错误】AttributeError: ‘DataFrame‘ object has no attribute ‘append‘
- 【解决办法】:pip install pandas==1.3.4
-
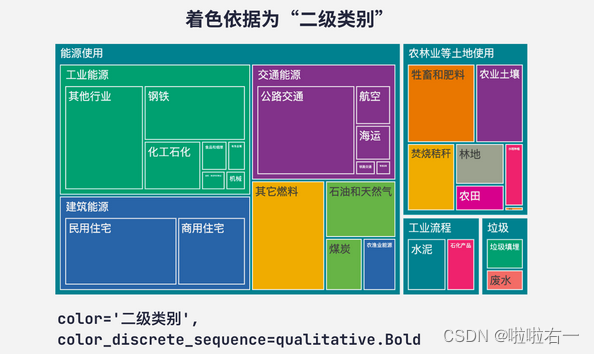
树状图的配色:
color_discrete_sequence参数配合color参数。- 比如,将
color参数设为 ‘一级类别’,那么最终图表的着色依据就是 df[‘一级类别’] 这列数据,一级类别不同的矩形会被指定为不同的颜色。 - 具体要把矩形设置成什么颜色要由
color_discrete_sequence参数来定。
fig_treemap = px.treemap( data, path=['一级类别', '二级类别', '三级类别'], values='百分比', color='一级类别', color_discrete_sequence=qualitative.Bold )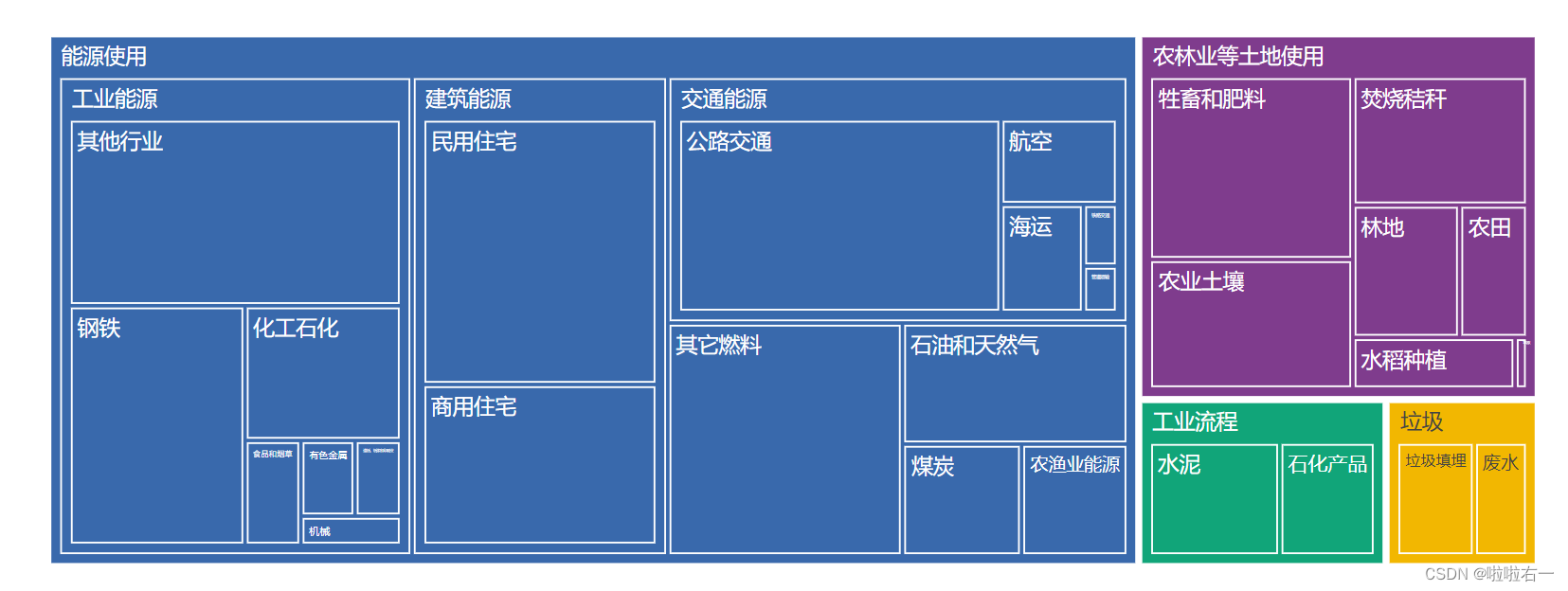
- 着色依据为“二级分类”
- 着色依据为“三级分类”
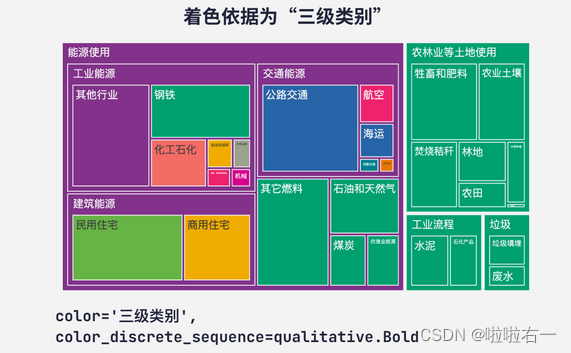
- 以二、三级类别作为着色依据时,得到的图表看起来很杂乱。我们使用树状图,就是因为它能够突出数据的层级,这样的图表显然不符合我们的初衷。所以,除非有特别的要求,否则在一般情况下,我们都推荐把树状图的着色依据设为层级最高的那组数据。
- 用
fig_treemap.update_traces(opacity=0.8)调整不透明度。
- 比如,将
-
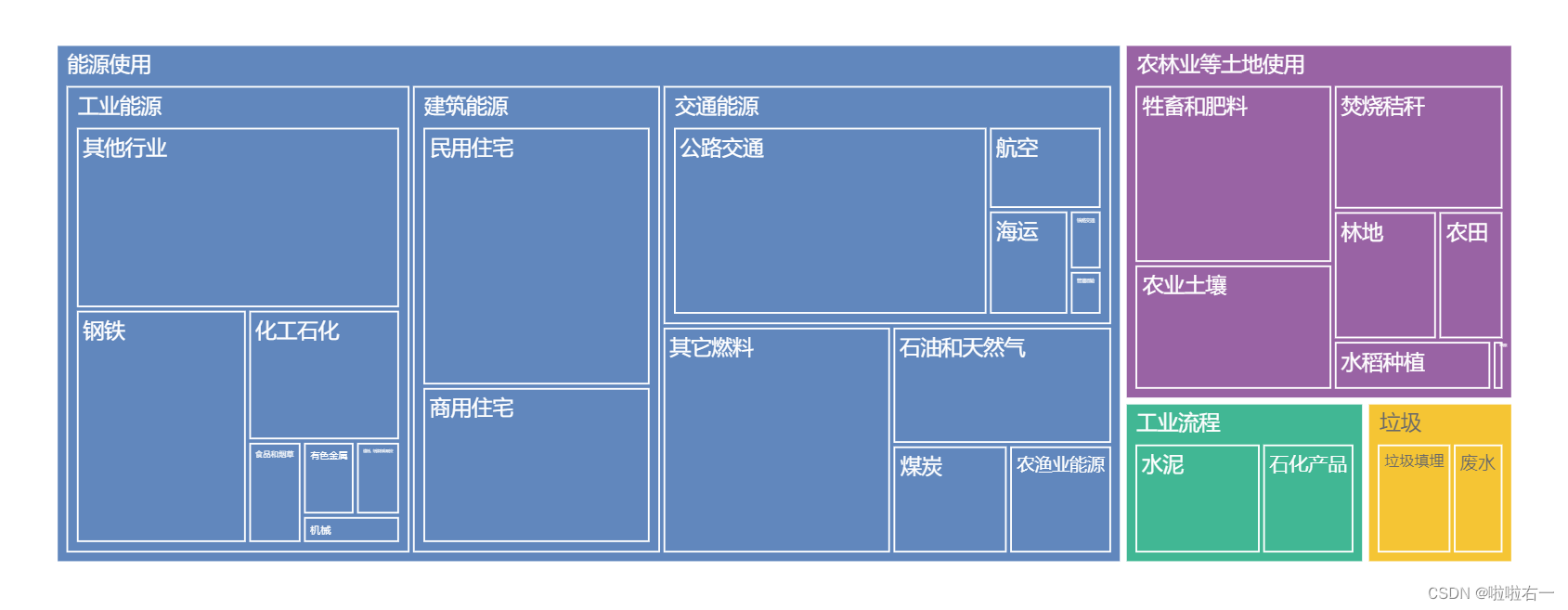
plotly动态性
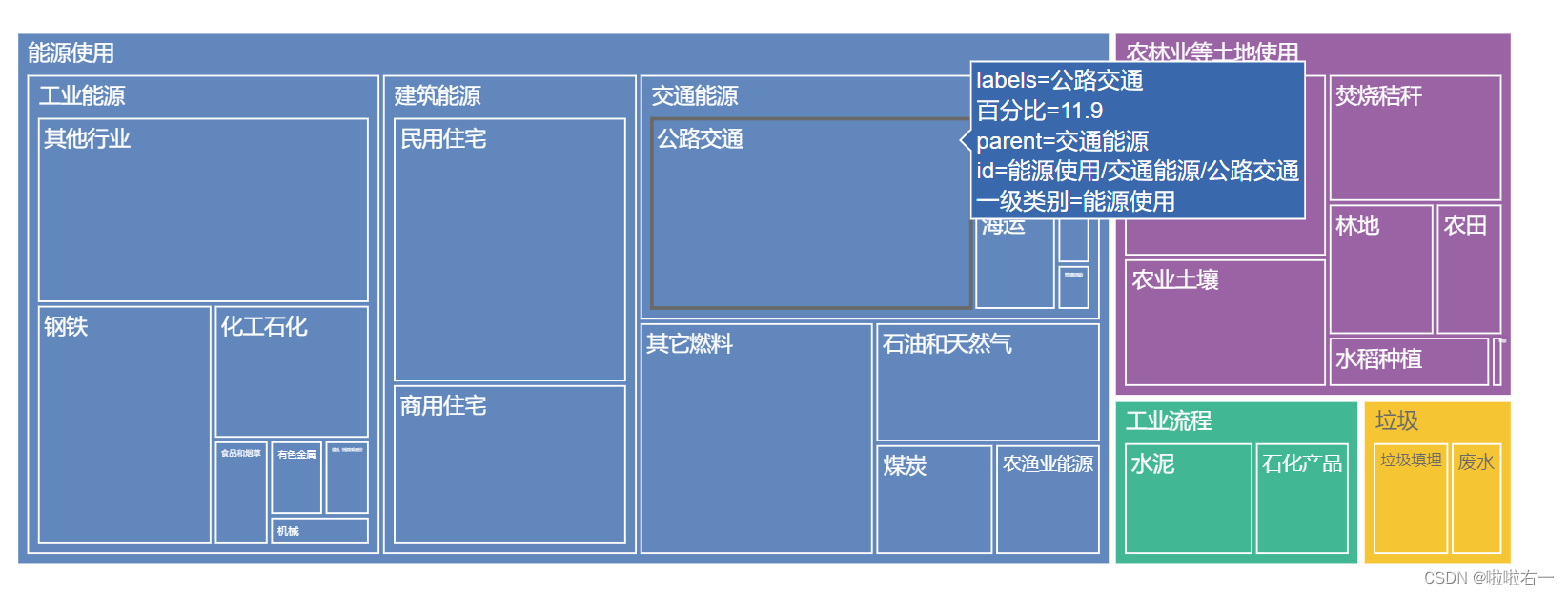
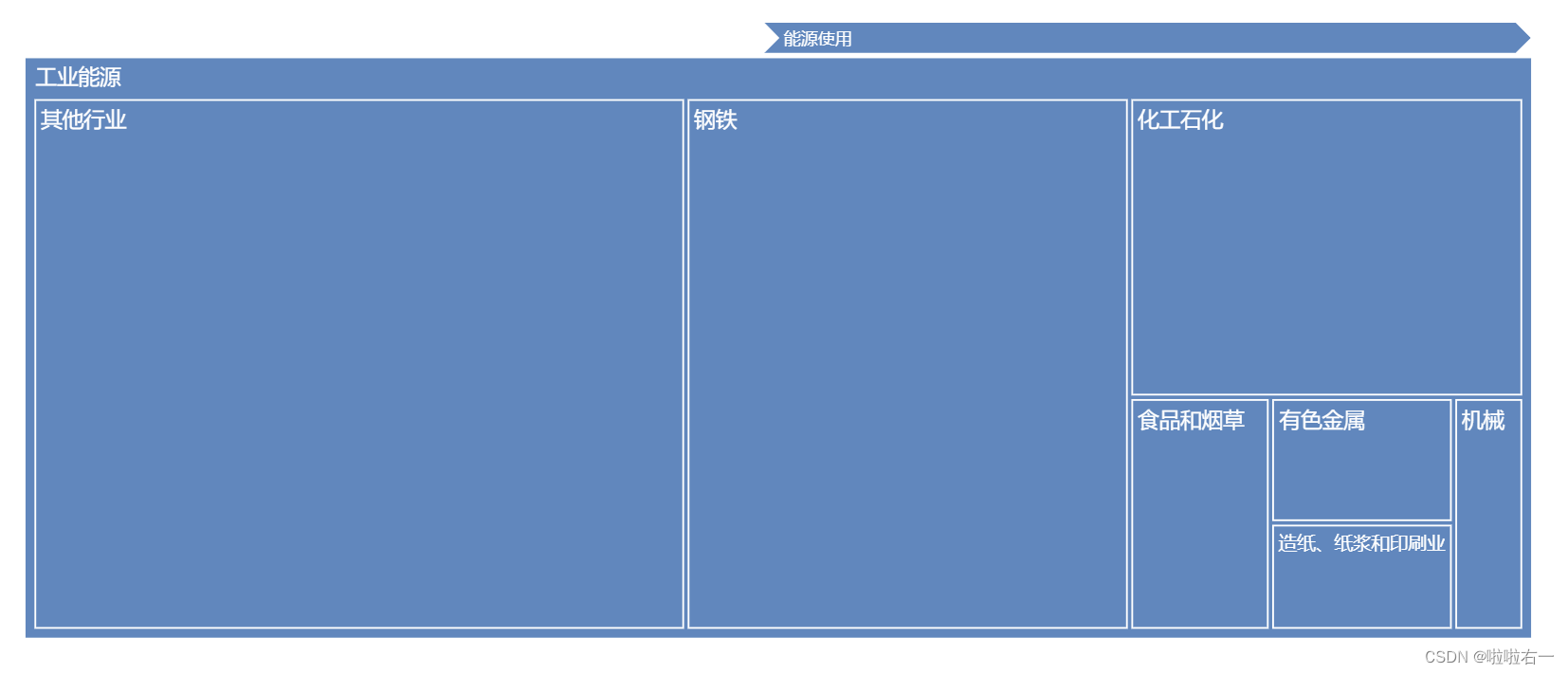
-
最终完整代码
import pandas as pd import plotly.express as px from plotly.colors import qualitative path = './data/全球温室气体排放来源.xlsx' data = pd.read_excel(path, sheet_name ='按年统计') fig_treemap = px.treemap( data, path=['一级类别', '二级类别', '三级类别'], values='百分比', color='一级类别', color_discrete_sequence=qualitative.Bold ) fig_treemap.update_traces(opacity=0.8) fig_treemap.show()
🐇旭日图
-
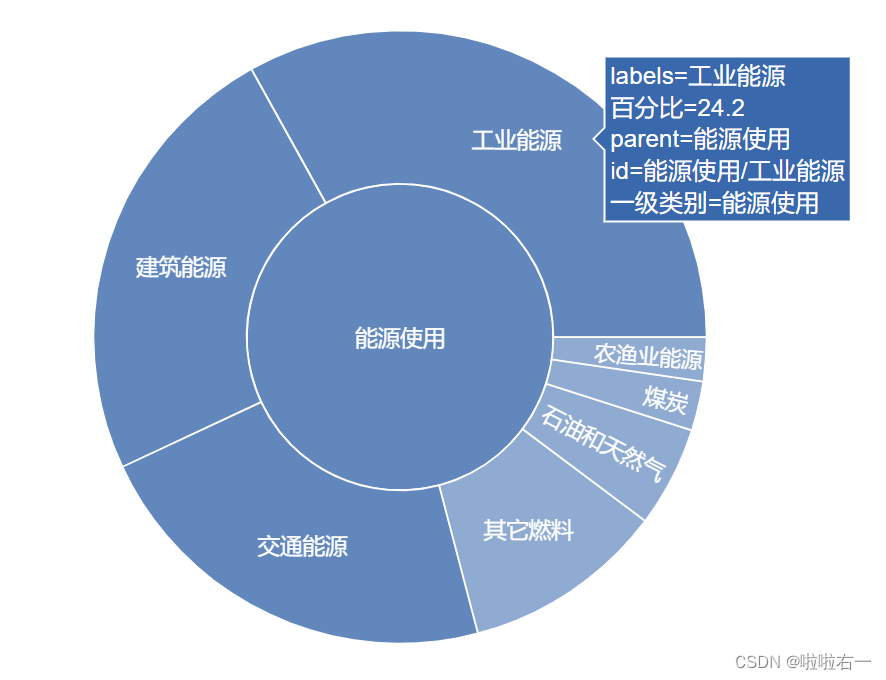
类似上述树状图,画出来的结果虽然能用但是丑丑的,,
fig_sunburst = px.sunburst( data, path=['一级类别', '二级类别', '三级类别'], values='百分比', color='一级类别', color_discrete_sequence=qualitative.Bold ) fig_sunburst.update_traces(opacity=0.8) fig_sunburst.show()
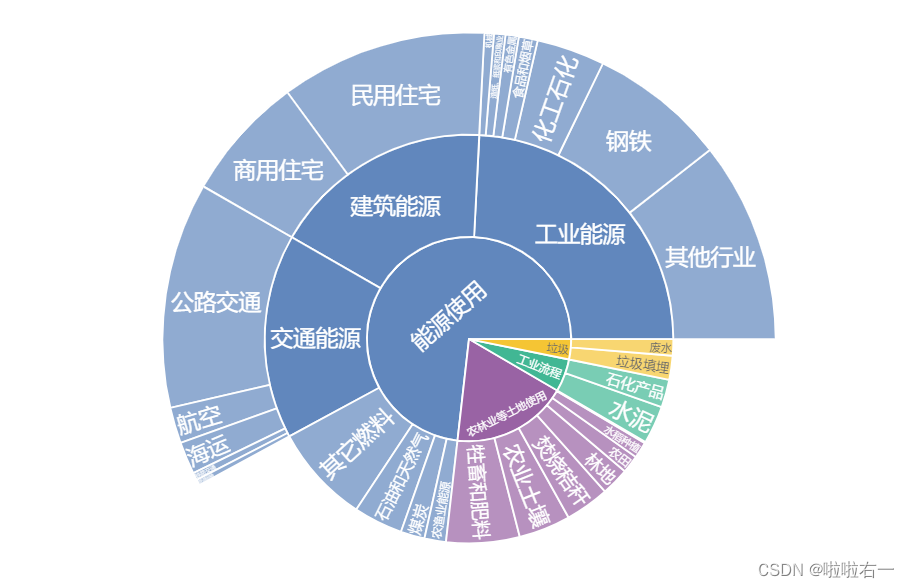
- 解决三个级别全部展示的问题:在 sunburst() 函数中可以设定 maxdepth 参数,它表示一次允许展示的最多层级,我们设定为 2 就可以。添加
maxdepth=2。
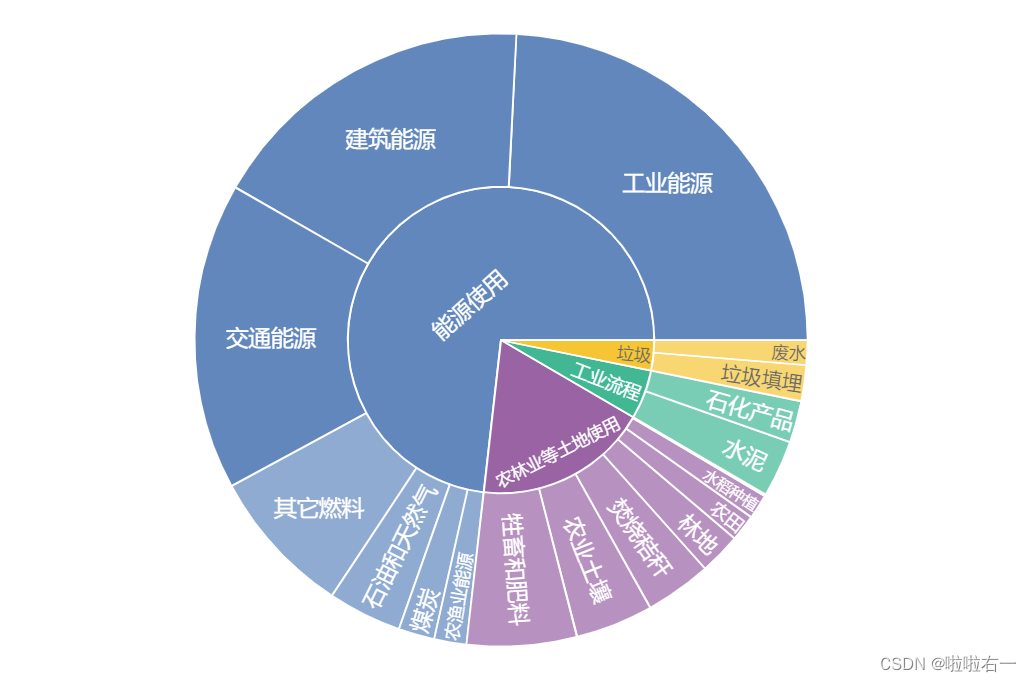
- 显示了两个级别,但如果你点击位于外层的二级类别块,它就会自动缓缓展开展开显示被隐藏的第三级类别。
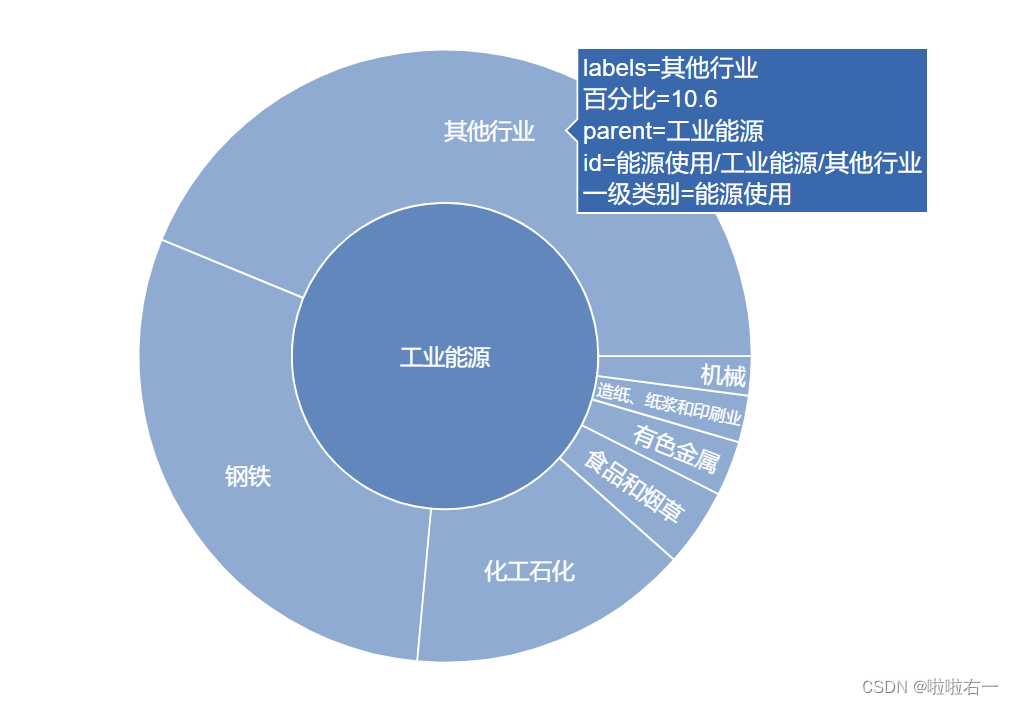
- 点击位于内层的一级类别块,也会自动展开,只展示该类别和其下的二级类别块。
- 显示了两个级别,但如果你点击位于外层的二级类别块,它就会自动缓缓展开展开显示被隐藏的第三级类别。
- 字体调整:旭日图 trace 中的字体大小设置在 px 模块中没有集成,也一样要用 update_traces() 方法来调整。字体统一变成了 10 号。不过有些层级块本身就太小,比如 废水 和 水稻种植,没法放下 10 号字体,所以其中的字体还是会压缩。但是整个图表的字体大小差异没有那么大了,视觉上会舒服一些。
fig_sunburst.update_traces( textfont=dict(size=10) )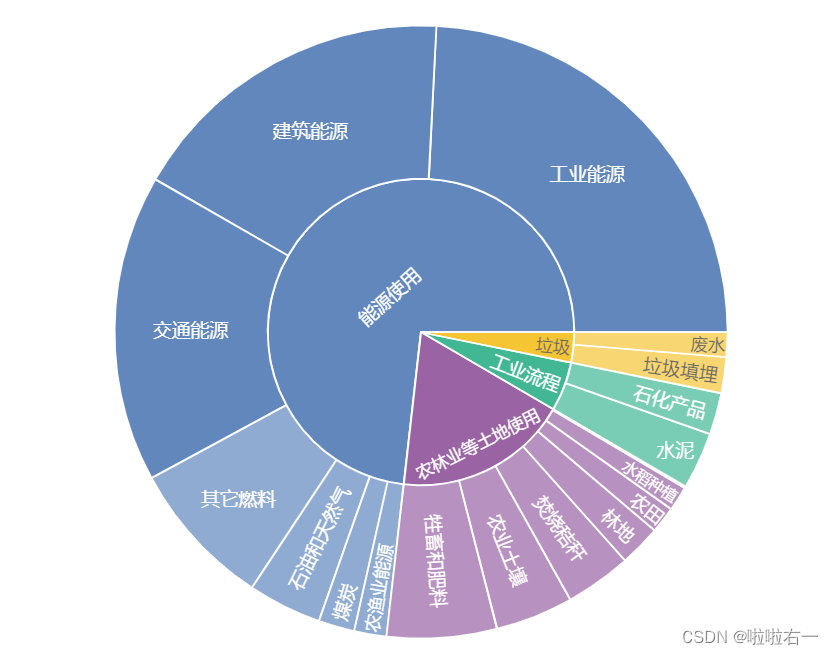
- 最终完整代码
import pandas as pd import plotly.express as px from plotly.colors import qualitative path = './data/全球温室气体排放来源.xlsx' data = pd.read_excel(path, sheet_name ='按年统计') fig_sunburst = px.sunburst( data, path=['一级类别', '二级类别', '三级类别'], values='百分比', color='一级类别', color_discrete_sequence=qualitative.Bold, maxdepth=2 ) fig_sunburst.update_traces(opacity=0.8) fig_sunburst.update_traces( textfont=dict(size=10) ) fig_sunburst.show()
📚Pandas
-
Pandas中文网
-
pandas主要是通过
pandas.DataFrame.plot()来完成绘图DataFrame.plot(data, x=None, y=None, kind='line', ax=None, subplots=False, sharex=None, sharey=False, layout=None,figsize=None, use_index=True, title=None, grid=None, legend=True, style=None, logx=False, logy=False, loglog=False, xticks=None, yticks=None, xlim=None, ylim=None, rot=None, xerr=None,secondary_y=False, sort_columns=False, include_bool=False, **kwds)data: 需要绘图的数据,可以是DataFrame、Series或数组。x: 作为x轴的数据列或索引。如果未提供,则使用DataFrame的索引。y: 作为y轴的数据列。如果未提供,则使用所有的数值数据列。kind: 绘制图形的类型,可选值有’line’(折线图,默认值),‘bar’(柱状图),‘barh’(水平柱状图),‘hist’(直方图),‘box’(箱线图),‘kde’(核密度估计图),‘density’(同kde),‘area’(面积图),‘pie’(饼图)等。ax: matplotlib 的AxesSubplot对象,如果提供,则在该子图中绘制图形。subplots: 若为True,则为每个数据列绘制单独的子图,否则所有数据列将绘制在同一个图中。sharex: 若为True,则所有子图共享一个x轴,False则每个子图有各自的x轴。默认为None,根据kind的类型进行自适应的设置。sharey: 同sharex,但针对y轴。layout: tuple (optional),指定子图布局的行数和列数。figsize: 指定绘图的尺寸大小,格式为(width, height)。use_index: 若为True,则使用DataFrame的索引作为x轴。默认为True。title: 图表的标题。grid: 是否显示网格线。legend: 是否显示图例,默认为True。style: 指定线条的风格,格式为字符串或列表。logx, logy, loglog: 是否对对应的轴进行对数变换。xticks, yticks: 指定x轴和y轴上的刻度。xlim, ylim: 指定x轴和y轴的范围。rot: 旋转x轴标签的角度。xerr: 提供x误差线(仅在kind='bar’或kind='barh’时使用)。secondary_y: 若为True,则将第二个y轴添加到图表中。sort_columns: 是否按列名对数据进行排序,默认为False。include_bool: 是否包括布尔类型的列,默认为False。**kwds: 其他关键字参数传递给底层绘图函数。
- 以下博客已经作了详细梳理:可视化之用pandas绘制简单的图形
📚Matplotlib
-
Matplotlib中文网
-
Matplotlib 这个模块很庞大,最常用的是其中一个子模块——pyplot。
-
pyplot 中最基础的作图方式是以点作图,即给出每个点的坐标,pyplot 会将这些点在坐标系中画出,并用线将这些点连起来。
import numpy as np import matplotlib.pyplot as plt # 导入模块 x = np.arange(0, 2 * np.pi, 0.1) y = np.sin(x) plt.plot(x, y) plt.show()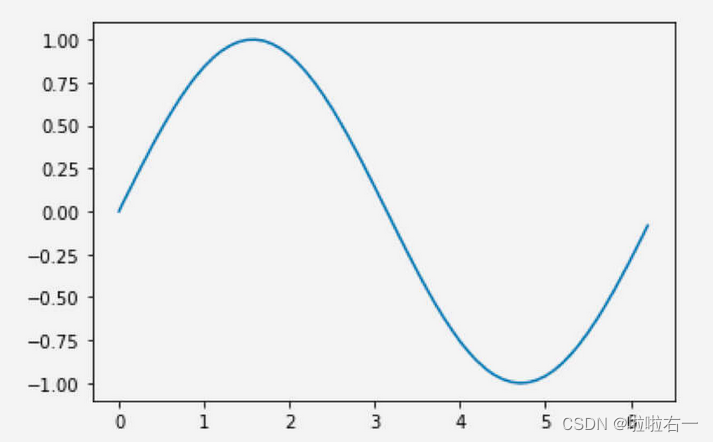
-
plt.plot()方法接收任意对数的 x 和 y,它会将这些图像在一张图上都画出来x = np.arange(0, 2 * np.pi, 0.1) y1 = np.sin(x) y2 = np.cos(x) plt.plot(x, y1, x, y2) plt.show()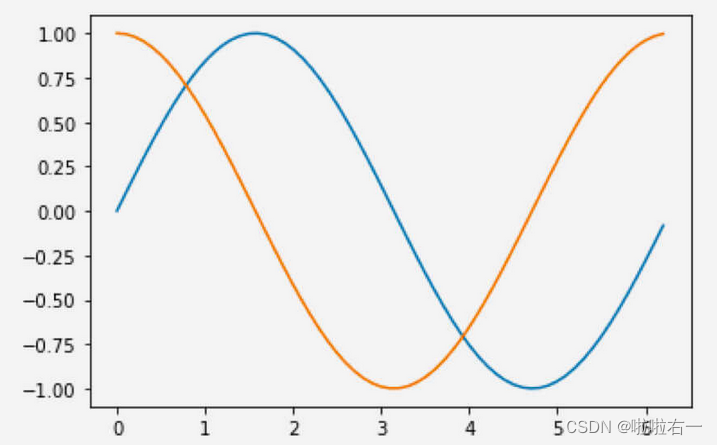
-
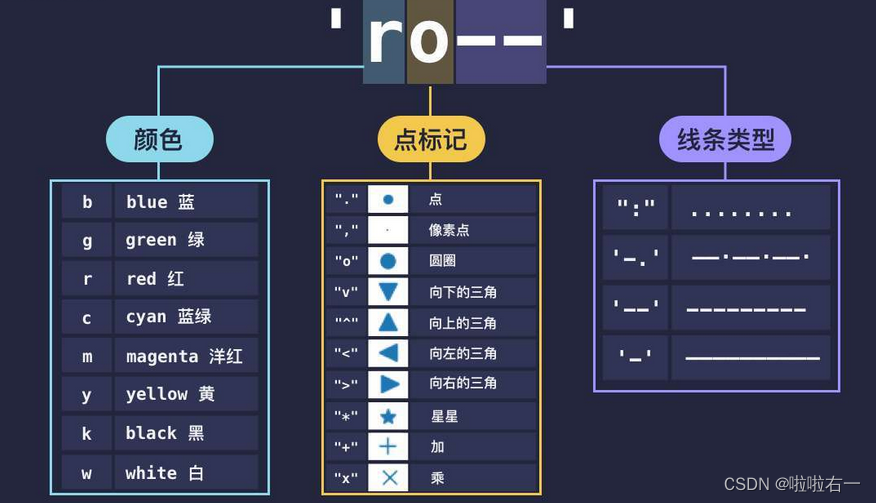
对于每一对 x 和 y,还有一个可选的格式化参数,用来指定线条的颜色、点标记和线条的类型。
plt.plot(x, y1, 'ro--')
- 此博客已经作了非常非常详细的梳理!!!⭐️
📚Seaborn
- Seaborn官网
- Seaborn 是一个基于matplotlib的 Python 数据可视化库,它建立在matplotlib之上,并与Pandas数据结构紧密集成,用于绘制有吸引力和信息丰富的统计图形的高级界面。
- 此博客已经作了非常非常详细的梳理!!!⭐️
📚Pyecharts
- pycharts官网
- pyecharts 是一个用于生成 Echarts 图表的类库。 echarts 是百度开源的一个数据可视化 JS 库,主要用于数据可视化。pyecharts 是一个用于生成 Echarts 图表的类库。实际上就是 Echarts 与 Python 的对接。
- 数据可视化利器——pyecharts详解
- 手把手教你用pycharts绘制各种图
- 配色网站