目录
一、事件风暴
二、系统用例
三、领域上下文
四、架构设计
(一)六边形架构
(二)系统分层
五、系统实现
(一)项目结构
(二)提交订单功能实现
(三)领域层实现
聚合
聚合根、实体、值对象
(四)Repository层实现
CQRS模式
缓存实现
Unit Of Work模式
数据并发更新控制
(五)领域事件实现
针对项目源码roc-emall进行的一些总结。
一、事件风暴
事件风暴(Event Storming)是一种系统分析方法,由 Alberto Brandolini 开发,旨在帮助团队理解和识别系统中的事件、业务功能和边界。它通常与领域驱动设计(DDD)概念结合使用,以加速系统设计和开发的过程。 详细的解释可以参考它的官方网站: Event Storming。
事件风暴的核心思想是通过协作的方式,将参与者集合在一起,共同探讨和记录系统中发生的事件。以下是事件风暴的一些关键要点:
-
事件驱动:事件风暴强调事件作为系统的关键组成部分。事件是用户操作或系统状态更改的结果,这些事件可以帮助理解系统中的业务流程。
-
合作工作坊:事件风暴通常作为一个工作坊进行,邀请各种利益相关者参与,包括业务分析师、开发人员、设计师等。这有助于促进跨职能团队的合作和理解。
-
大白纸:事件风暴使用大型纸张或墙壁来记录事件和相关信息。参与者可以使用便利贴、标记笔等工具来记录事件,定义业务流程,绘制关系图等。
-
时间线:事件风暴通常将事件按照时间线的方式排列,以帮助理清事件发生的顺序和逻辑。
-
聚焦领域:事件风暴有助于识别领域中的限界上下文(bounded context),这是DDD中的一个重要概念,用于定义业务功能的边界。
-
快速迭代:事件风暴是一个迭代过程,可以多次进行,以不断完善对系统的理解,发现潜在的业务问题和机会。
事件风暴的目标是促进对系统的共享理解,减少误解,发现潜在问题,以及为设计和开发提供清晰的指导。它是一种轻量级、可视化的方法,有助于团队在项目早期阶段快速建立共识,加速开发过程,提高项目成功的机会。
所谓“事件”,即系统中一系列的行为(用户操作)导致系统状态更改的结果。例如,用户“提交订单”这一行为导致系统生成了新订单,发生了“订单已提交”事件;仓库发货员将包果交给快递员后,在系统“填写了快递单号”后,导致系统状态发生更改,触发了“已发货”事件。
通过分析系统中发生的“事件”,能够挖掘和识别出系统的业务功能,梳理出业务边界。下图展示了E-Mall系统的事件风暴
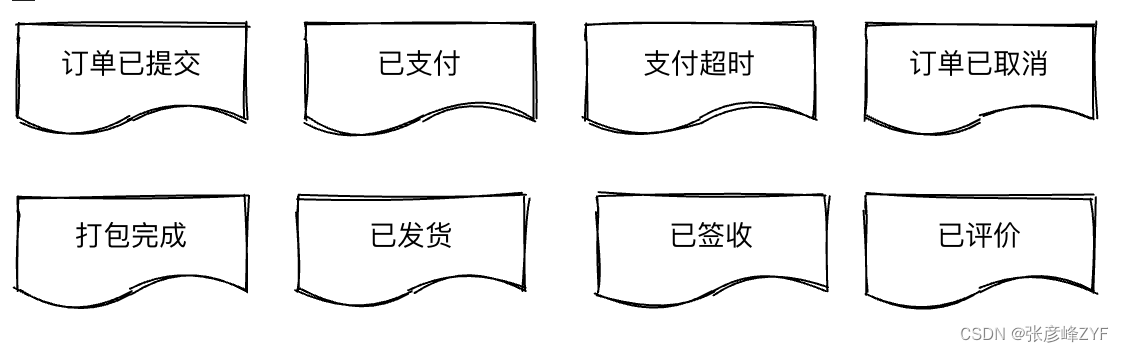
二、系统用例
系统用例是用户与系统交互的一种表示形式,它们有助于识别和记录系统的功能需求,并可用于用户需求分析、系统设计和软件开发的各个阶段。以下是有关系统用例的一些关键要点:
-
用户需求分析: 通过系统用例,分析人员可以捕捉用户与系统之间的交互,以了解用户期望系统执行的各种操作。这有助于确保系统开发满足用户需求。
-
功能识别: 用例图用于识别系统的各种功能或操作。每个用例代表一个特定的功能或行为,而用例之间的关系描述了它们之间的依赖性和交互。
-
可视化: 用例图提供了一种可视化方式,以便项目团队、利益相关者和开发人员更容易理解系统功能和交互。
-
系统边界: 用例图通常包括一个系统边界,用于明确界定系统与外部实体之间的交互,帮助确定哪些操作属于系统的范围。
-
用例描述: 每个用例通常附带用例描述,其中包括用例的名称、目标、前提条件、主要流程和可能的替代流程。这些描述提供了对用例的详细说明。
-
角色: 用例图还包括与系统交互的各种角色,这些角色代表用户、外部系统或其他实体。
-
交互关系: 用例图展示了各个用例之间的关系,如包含关系、扩展关系和依赖关系。这有助于理解用例之间的交互方式。
-
迭代和演化: 用例图是一个灵活的工具,可以在项目的不同阶段进行更新和演化,以反映新的需求或发现的变化。
总之,系统用例图是一种强大的工具,用于捕捉、可视化和分析系统的功能需求,有助于确保开发团队理解用户期望的系统行为,从而成功交付符合需求的软件系统。下图展示了E-Mall系统的用例:
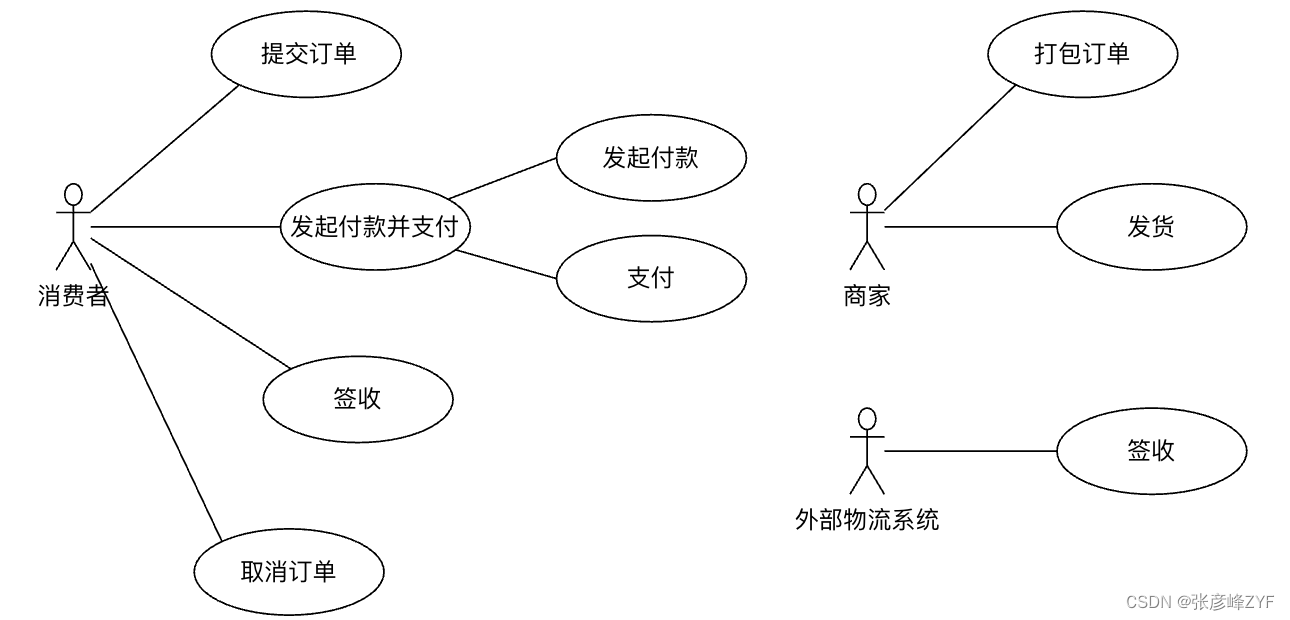
三、领域上下文
根据事件风暴推断,系统中应该包含的界限上下文有:Order、SKU、Price、Payment等。
对系统进行Context划分:
-
Order Context(订单上下文): 这是处理与订单相关的所有功能的上下文,包括提交订单、取消订单和查询订单等操作。它在业务中负责订单的生命周期管理。
-
SKU Context(SKU上下文): 这个上下文主要涉及商品(Stock Keeping Unit)的管理,包括库存管理、商品数量校验以及订单的商品处理。此外,SKU上下文还涉及订单的打包和发货等操作,以确保订单的正确处理。
-
Price Context(价格上下文): 价格上下文负责管理商品的价格,计算订单金额以及维护价格计算策略。它为订单上下文提供了订单金额计算所需的功能。
-
Payment Context(支付上下文): 这个上下文主要关注支付功能,包括维护交易记录等。它确保订单支付的安全性和可追踪性。

四、架构设计
(一)六边形架构

六边形架构是一种用于构建可扩展和灵活的应用程序的架构风格,强调了分离关注点和对外部系统和客户的透明性。以下是一些关键要点:
-
六边形的对称性: 在六边形架构中,系统被视为一个多边形,其边界上有各种端口(Port),而系统的核心是领域层。这个多边形的对称性意味着客户和外部系统可以以一种对等的方式与系统交互,而系统核心不受特定的客户或外部技术的依赖。
-
输入端口: 输入端口用于接受外部客户系统的请求或输入,并将其转化为内部可理解的请求。这可以是系统提供的服务接口,用于接受来自外部的命令或查询。
-
输出端口: 输出端口用于与外部系统进行通信,如数据库、消息队列、远程服务等。它负责将系统内部的状态或数据发送到外部系统或进行持久化。
-
应用层: 应用层是系统的服务层,定义了系统可以执行的工作。它协调领域对象和领域服务,处理业务逻辑,并通过输入端口接受请求并使用输出端口与外部系统通信。应用层通常非常薄,不包含业务逻辑,而是将请求委托给领域层处理。
-
领域层: 领域层包含系统的核心业务逻辑,它负责表示业务概念、规则和状态。领域层的模型是应用程序的核心,通常包括实体、值对象、聚合根等领域对象。
-
适配器: 适配器在输入和输出端口之间进行数据转换和交互。输入适配器将来自客户的请求转化为系统可理解的形式,输出适配器将系统的响应转化为外部系统或客户可理解的形式。这使得系统能够与各种客户和外部系统进行无缝的交互。
六边形架构的优点包括良好的可扩展性、可维护性和适应性,因为它使不同部分之间的关注点清晰分离。它也使系统更容易进行单元测试,因为领域逻辑可以在不涉及外部系统的情况下进行测试。这种架构风格对于构建复杂应用程序和微服务架构非常有用。
(二)系统分层

领域驱动设计(DDD)架构常见的四层架构:
-
基础设施层(Infrastructure Layer): 这一层提供与业务逻辑无关的功能和工具,通常包括实用程序类、工具类、数据库连接、日志记录、缓存、消息队列等。在这一层中,你还可以找到仓储(Repository)接口和数据库访问的实现,用于与持久化存储交互。基础设施层通常是技术相关的,但它们需要被领域层和应用层所依赖。
-
领域层(Domain Layer): 领域层包含了系统的核心业务逻辑。这是应用程序的灵魂,它包括领域模型、实体、值对象、聚合根、领域服务等。这一层与特定的业务领域密切相关,它不包含技术相关的内容,而是关注如何解决业务问题。领域层通常不依赖于其他层,而其他层依赖于领域层。
-
应用层(Application Layer): 应用层位于领域层之上,它是系统的服务层,负责协调领域逻辑的执行。应用层包括应用服务(Application Services),这些服务定义了系统可以执行的各种用例或操作,它们接受来自展示层的请求,协调领域层的操作,处理事务管理,发布领域事件等。应用层通常依赖于基础设施层和领域层。
-
展示层(Presentation Layer): 这是系统与用户或外部系统进行交互的接口层。展示层可以是用户界面(UI)层,如Web界面或移动应用,也可以是API层,用于提供外部系统访问应用程序的接口。展示层通常不直接与领域层交互,而是通过应用层来协调和处理请求。
这种四层架构的分层方法有助于实现领域驱动设计的原则,如分离关注点、保持业务逻辑的纯洁性以及提高系统的可维护性和可扩展性。通过将不同关注点分离到不同的层级,可以更容易地管理和扩展应用程序,同时也使系统的架构更清晰和可维护。
五、系统实现
(一)项目结构

-
Roc.EMall.Infra,即DDD分层中的“基础设施层”,提供一些业务无关的扩展或帮助方法。
-
Roc.EMall.Repository,仓储层(属于基础设施层)负责与数据库交互,通过Dapper和MySql.Data库读取和写入数据到MySQL数据库中。对外仅暴露IRepository及其子接口,隐藏具体实现。
-
Roc.EMall.Domain,领域层包含所有的核心业务,通过充血模型实现业务逻辑。
贫血模型
贫血模型:是指领域对象里只有get和set方法,或者包含少量的CRUD方法,所有的业务逻辑都不包含在内而是放在Business Logic层。
优点是系统的层次结构清楚,各层之间单向依赖,Client->(Business Facade)->Business Logic->Data Access(ADO.NET)。当然Business Logic是依赖Domain Object的。似乎现在流行的架构就是这样,当然层次还可以细分。
该模型的缺点是不够面向对象,领域对象只是作为保存状态或者传递状态使用,所以就说只有数据没有行为的对象不是真正的对象。在Business Logic里面处理所有的业务逻辑,在POEAA(企业应用架构模式)一书中被称为Transaction Script模式。
充血模型
充血模型: 层次结构和上面的差不多,不过大多业务逻辑和持久化放在Domain Object里面,Business Logic只是简单封装部分业务逻辑以及控制事务、权限等,这样层次结构就变成Client->(Business Facade)->Business Logic->Domain Object->Data Access。
优点是面向对象,Business Logic符合单一职责,不像在贫血模型里面那样包含所有的业务逻辑太过沉重。
参考:充血模型和贫血模型 - 简书
-
Roc.EMall.Application,应用层负责向展示层(WebApi)提供应用服务,调用领域层完成业务功能,协调多个领域对象,调用Repository层完成数据的读取和保存,调用外部接口完成相关验证,发布领域事件。
-
Roc.EMall.WebApi,展示层负责接收用户请求,调用应用层,并返回相关数据给用户。
(二)提交订单功能实现
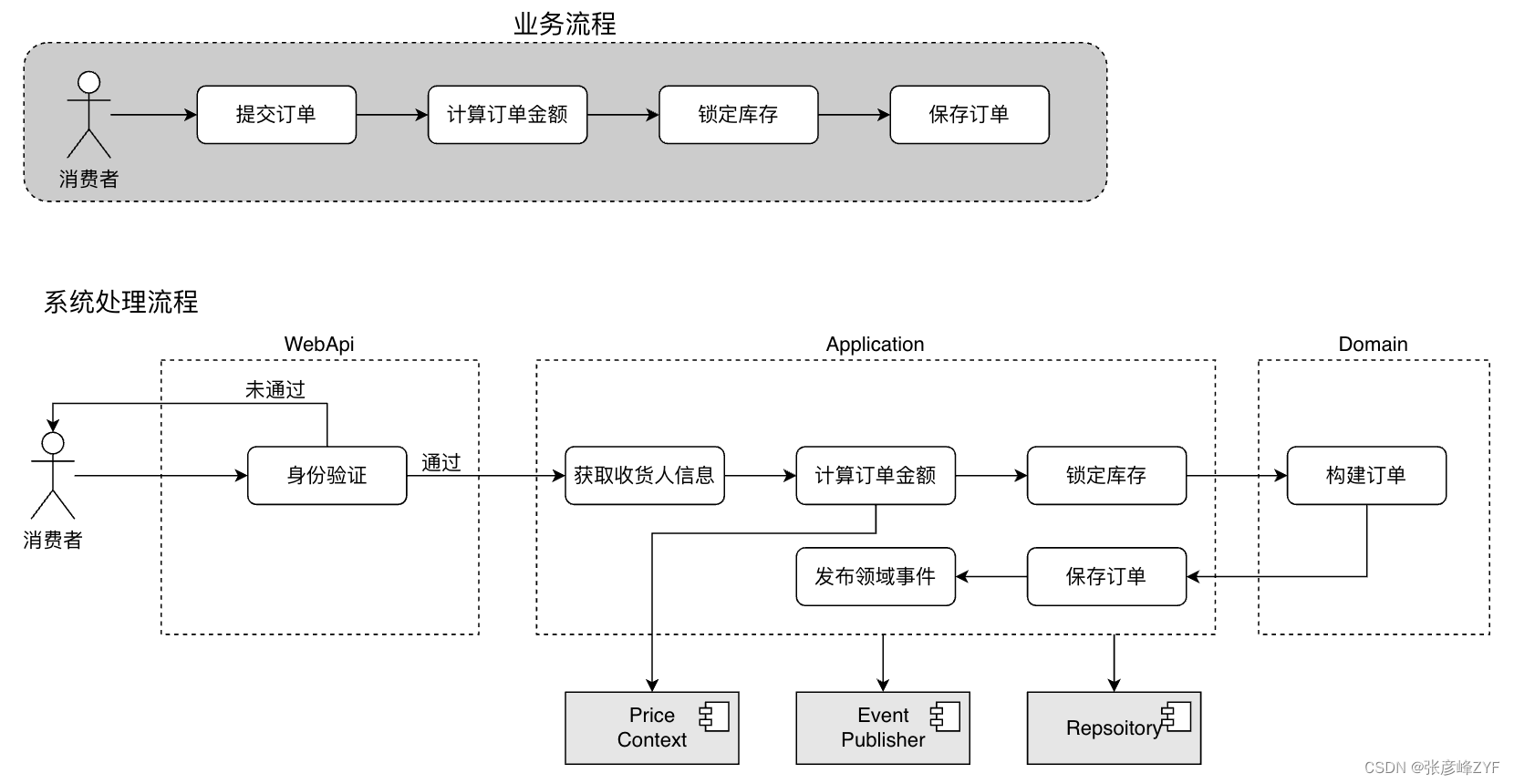
(三)领域层实现
聚合
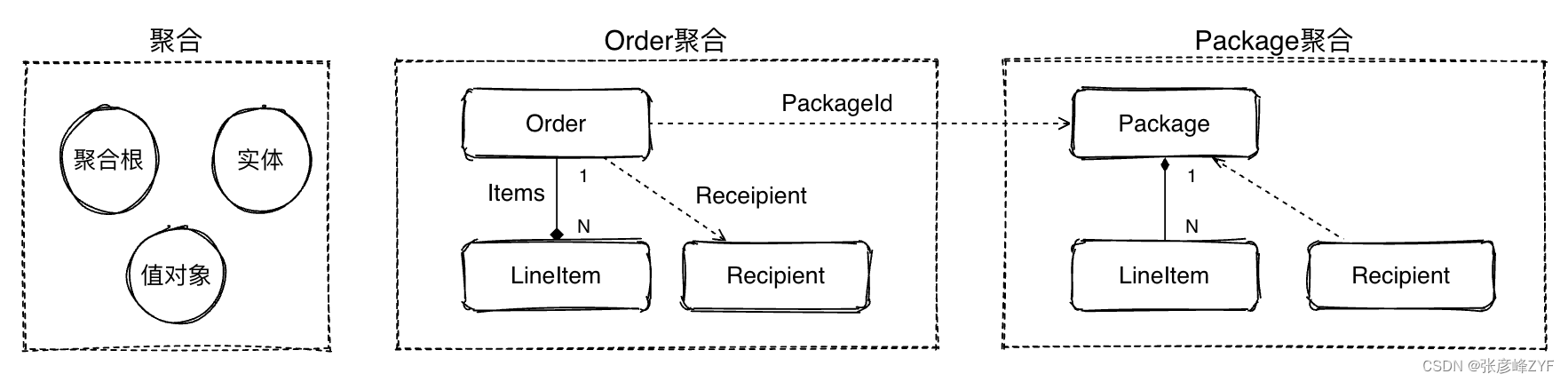
聚合Aggregate就是一组相关对象的集合,我们把它作为数据修改和访问的单元。一个聚合包含聚合根、实体和值对象。
每个聚合都会有一个聚合根和聚合的边界Boundary,边界定义了在一个聚合里面内部应该有哪些实体,哪些子实体对象。定义边界的原因是,我们期望对一个聚合的访问是通过聚合根来进行的,聚合里面的子实体对外界是完全封闭的。对于外部对象不应该去访问到一个聚合边界里面的子实体。
按实际对象分析思路,在领域模型中的领域对象分析应该按照从顶向下的思路进行展开,如果这样的话首先识别到的就是聚合根对象,然后再考虑对聚合根对象进行展开,在聚合根对象的展开过程中进一步细化子实体之间的关联和依赖关系。
聚合根、实体、值对象
聚合的特点:高内聚低耦合,是领域模型中最底层的边界,可以作为拆分限界上文的最小单位,一个限界上文可以包含多个聚合,聚合之间的边界是逻辑最天然的边界,有了这个逻辑边界,就可以在微服务拆分的时候作为拆分和组合的依据,推动系统服务化演进。
实体:具有唯一标识(ID),通过ID进行相等性比较,依附于聚合根,生命周期由聚合根来管理。实体和聚合根存在依赖或聚合关系。例如,在Order聚合中,Order类是聚合根,LineItem是实体;
聚合根:聚合根是实体,具备唯一标识,有独立的生命周期,一个聚合只有一个聚合根,聚合根在聚合之内采用引用依赖的方式对实体和值对象进行组织和协调,聚合根和聚合根之间通过唯一id进行聚合之间的协同;
值对象:没有唯一标识(ID),不可变,无生命周期,用完即失效,值对象之间通过属性值判断相等性。值对象的核心是值,是一组概念完整的属性集合,用于描述实体的特征和状态。
为什么要在实体和限界上下文之间增加聚合和聚合根,作用是什么?
在实体和限界上下文之间增加聚合和聚合根的原因是:让实体和值对象协同工作,在实现公共业务逻辑的时候,可以保证数据的一致性。
如何设计聚合?
过程是:通过事件风暴(用例分析,场景分析)得到实体和值对象,然后找出聚合根,按照高内聚低耦合的设计原则,找出跟聚合根紧密关联的实体和值对象,即形成聚合,并画出聚合内的实体和值对象的引用依赖关系,最后把业务关联紧密的聚合画在同一个限界上线文中,即完成了领域建模。
聚合的设计原则: 高内聚,聚合尽量小,聚合之间通过id关联,边界之外使用最终一致性,在应用层实现跨聚合的调用。
(四)Repository层实现
Repository一般是根据领域层中的聚合根维度来划分的。例如,E-Mall系统中,在领域层中Order是聚合根,因此Repsository层中存在对应的OrderRepository,负责Order对象存储和读取工作。
CQRS模式
CQRS — Command Query Responsibility Segregation,故名思义是将 command 与 query 分离的一种模式。
CQRS 将系统中的操作分为两类,即「命令」(Command) 与「查询」(Query)。命令则是对会引起数据发生变化操作的总称,即我们常说的新增,更新,删除这些操作,都是命令。而查询则和字面意思一样,即不会对数据产生变化的操作,只是按照某些条件查找数据。使用CQRS模式,由于将读和写分成两个路径,系统天然地支持读写分离。
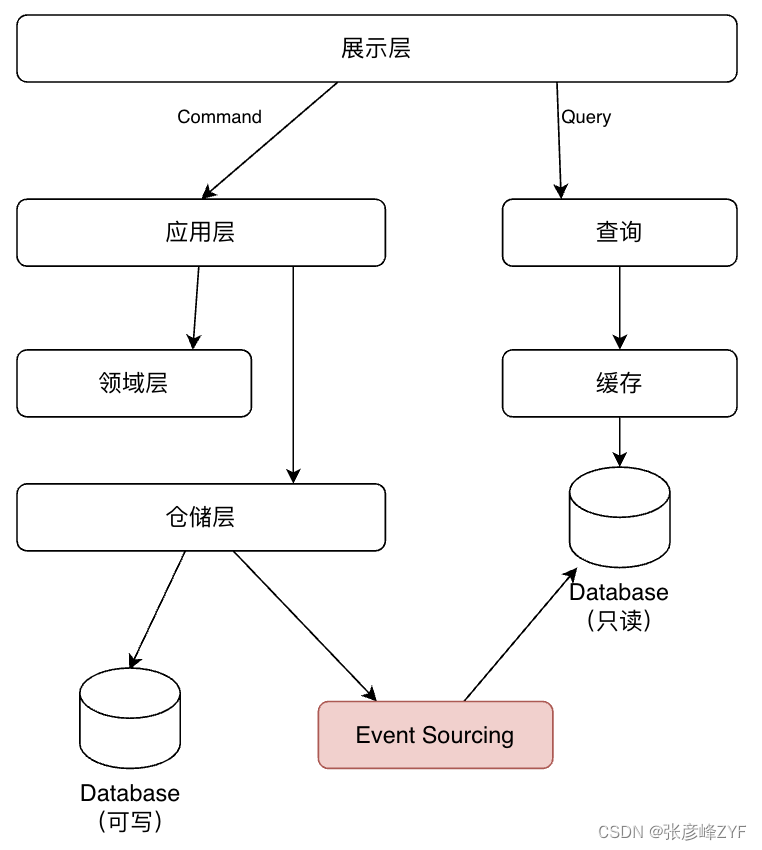
在CQRS中,Command直接将数据写入主库(可写),然后通过EventSourcing将变化的数据写入只读库。缺点是,使用EventSourcing增加了系统的复杂度,可能出主库和只读库数据不一致的情况。
在E-Mall项目中,并未采用EventSourcing对主库和只读库进行分离。项目中,在Repository层,将读和写分存两类不同的Repository: IRepository和IQueryRepository,所有Command操作均通过IRepository进行,所有Query操作均通过IQueryRepository操作。

缓存实现
由于采用了CQRS模式,Query Repository和Command Repository是相互独立。因此,缓存只需要在IQueryRepository的实现类上使用装饰者模式,对结果进行缓存即可。对于缓存数据的刷新,只要在对应的Command Repository上也使用装饰者模式即可实现。

Unit Of Work模式
单个Repository只负责维护单个聚合根的读写操作,当一个业务功能需要同时操作多个聚合根,且需要保证数据操作的原子性,那么单个Repository实现起来就比较困难。这时,就需要使用Unit Of Work(工作单元)模式了,Unit Of Work包装了数据库事务,保证多个聚合根操作的原子性。

Unit Of Work(工作单元)模式用来维护一个由已经被业务事物修改(增加、删除或更新)的业务对象组成的列表。Unit Of Work模式负责协调这些修改的持久化工作以及所有标记的并发问题。在数据访问层中采用Unit Of Work模式带来的好处是能够确保数据完整性。如果在持久化一系列业务对象(他们属于同一个事物)的过程中出现问题,那么应该将所有的修改回滚,以确保数据始终处于有效状态。
数据并发更新控制
通常情况,系统先通过Repository从数据库中加载现有数据并构建聚合根对象,应用层调用聚合根的方法执行业务逻辑,更改状态,最后再调用Repository保存到数据库中。
例如,用户提交订单时,应用层服务调用Repository.GetAsync方法获取Sku对象,并调用Sku.Occupy()方法锁定库存,最后再调用Repository.StoreAsync方法保存数据。

在并发较高中的业务场景中,多个用户购买同一个商品时,可能会更出并发锁定库存的现象。为了确保商品不出现“超卖”现象,必须对Sku.Occupy()方法进行并发控制。并发控制方案,一般有两种:
- 乐观并发:适用于并发冲突较少的业务场景,整体效率较高。但是,由于并发时总有一方必定失败,因此需要配合重试机制,提高系统体验。可以通过给数据行增加版本号实现。
- 悲观并发:适用于并发冲突较高的业务场景,并发请求分先后串行执行,整体效率不高。可以通过数据事务隔离级别实现。
E-Mall系统中采用乐观并发控制方案,配合并发重试机制,解决偶发并发失败场景。每个聚合根对象,在从Repository中加载后,都会带上ConVersion字段。更新数据时,将ConVersion字段作为额外的条件。
(五)领域事件实现
领域事件的发布一般放在应用层,通常在事务提交成功之后。领域事件的对象,则由应用层调用聚合根的方法获取,因为领域事件对象属于领域层职责。
在系统中,功能对系统的状态(数据)进行更改后,需要发布领域事件。相关的子系统或模块订阅相关的领域事件,对领域事件做出响应。

例如,对于用户新提交的订单,会要求在30分钟内完成付款,否则订单自动取消,并释放相应的库存。实现这样的功能,一般使用延时队列,30分钟后运行Job检查订单状态,未支付则取消订单,但是这样的逻辑不应该侵入到“提交订单”的业务逻辑中,而应该订阅“新增订单”的领域事件来实现。

![[AUTOSAR][诊断管理][$11] 复位服务](https://img-blog.csdnimg.cn/eed7d9bbfd96429d83b557a40378c172.png)