深度学习概述
决定要怎么连接这些neuron的时候
就已经确定了function set
相比于之前做logistic regression,linear regression的时候,换一个方式来决定function set
比较大,包含了logistic regression,linear regression没法包含的function
全连接,full connect
feedforward,前馈,正反馈
input,hidden,output layer
deep = many hidden layers
neural network
special structural 搞定这么深的network
Matrix Operation 矩阵运算
激活函数,sigmoid function
GPU没有对neural network做什么特化,相比于cpu,加速了矩阵运算
把output layer之前的部分,看作feature extractor :特征提取
抽出一组特别好的 separable 可分的的特征
这段是在介绍深度学习是怎么一层层计算的,和隐藏层合起来叫做什么
sigmoid适用于二分类,softmax适用于多分类,输出的都是概率,可以把sigmoid看作softmax的特例
根据不同参数形成不同函数,放到一起就是个函数集
回答一下,output是任意纬度都是可行的,取决于你的网络设计
因为输出本质上是和你想要变量有关的某种概率分布
然后你的隐藏层最后一层是30纬度,输出层10纬度
如果是二分类问题那output输出两个 多分类问题output取决于你打算分几类就有几个输出
石头汤里的那个石头
怎么决定layer的数码,每个layer中neuron的数目
常识,需要一些domain knowledge
过去做影像辨识的时候需要对影像抽取一些人定的feature,feature transform,有了deep learning之后,可以直接丢pixels硬做
但是有个新的问题,需要design network的structure
deep learning还是feature engineering看哪种情况下更容易
影像辨识上deep learning比feature engineering要容易,人去识别太过潜意识了,离意识层次太远
case by case:就事论事,具体问题具体分析;
deep learning在nlp上performance没那么好,不那么work,人对文字处理 比较强,rule detect,一篇document是正面情绪还是负面
layer连接的方法可以不这么相邻规律地连接吗?特殊接法,1连3,2连4,可以的
convolutional neural network卷积神经网络
cross entropy:交叉熵!!!!
所有data的cross entropy求和,total loss
在function set找一组function,或者说一组parameters,minimize total loss
gradient decent!!!!
几年前需要自己 implement back propagation,实现反向传播,现在有太多toolkit
back propagation是算微分的比较有效的方式
误差逆传播算法
为什么要deep learning
够多的training data去控制它的variance
deep的必要何在?
有个理论,任何连续的function,都可以用一个hidden layer的network来表示,只要这个hidden layer的neuron足够多,可以表示成任何的function
deep learning?噱头?只是变宽就是fat network
反向传播back propagation

反向传播算法是怎么让人工神经网络的训练更有效率的
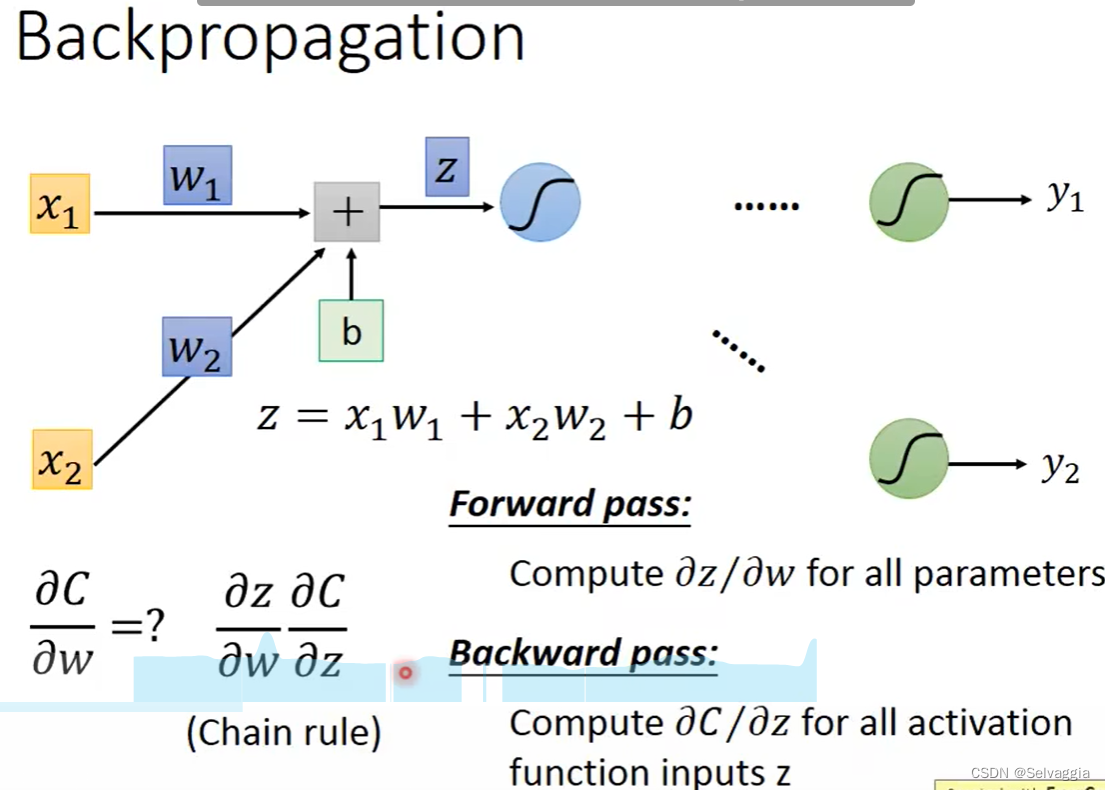
链式求导!!!!
c是一笔data预测值和观测值的误差 L是把所有笔data的c加在一起
对每一个参数的偏微分
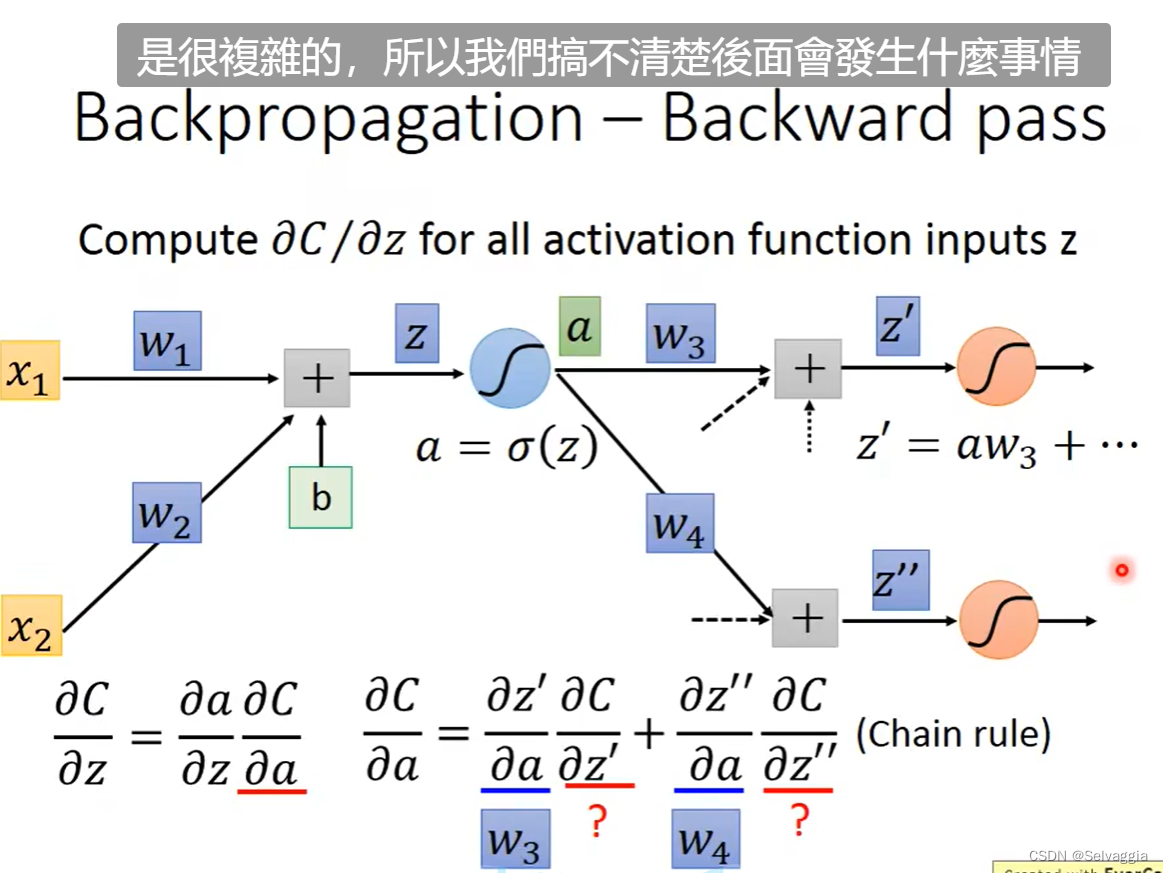
梯度下降和back propagation的本质都是计算损失函数对参数的梯度,即对每一个参数的偏微分,最后一层的参数的梯度容易表示,直接用L对参数求导表示,如果要求损失函数对前面若干层中的参数求导,就要用到链式法则了,简单来说就是,L对参数求导 倒数第2层输出 对 倒数第2层的参数求导 * 倒数第3层输出 对 倒数第3层的参数求导……*
再化简点, 倒数第 i 层输出 对 倒数第 i 层的参数求导,如 x* y=z, z对x求导就是y,是正向传播的翻转值
递归什么的说法就是bullshit!!!
加法
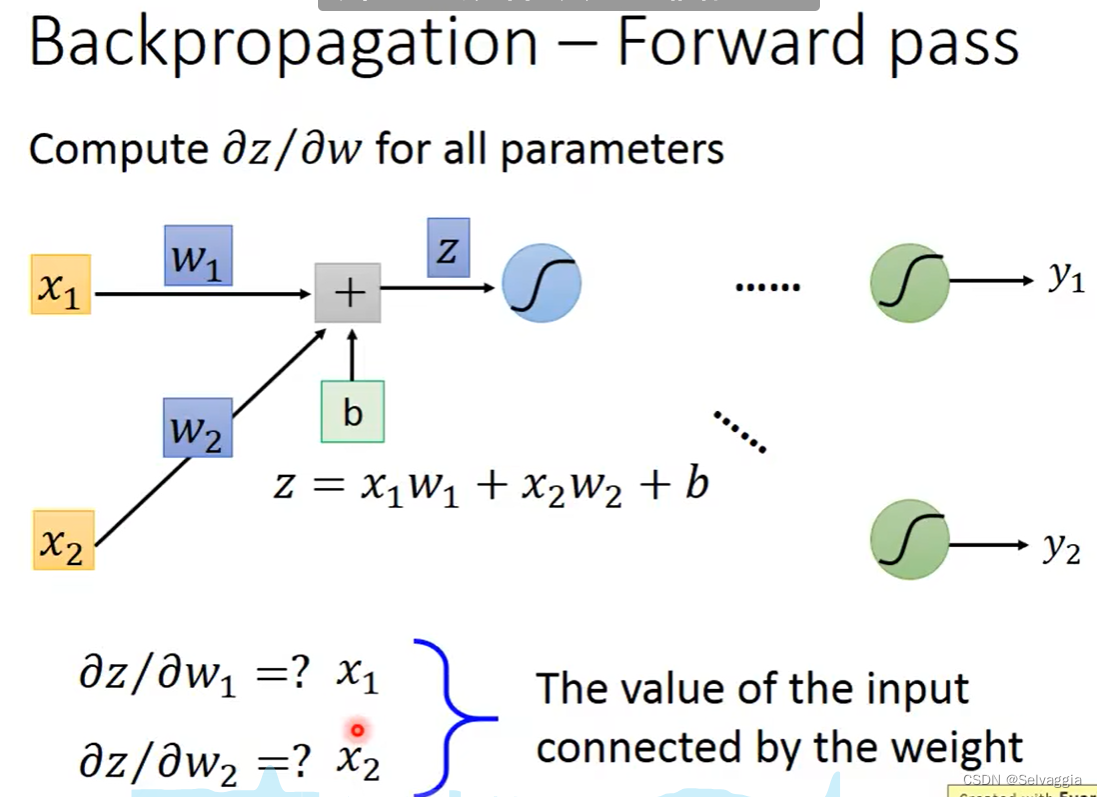
每一层是用forward pass
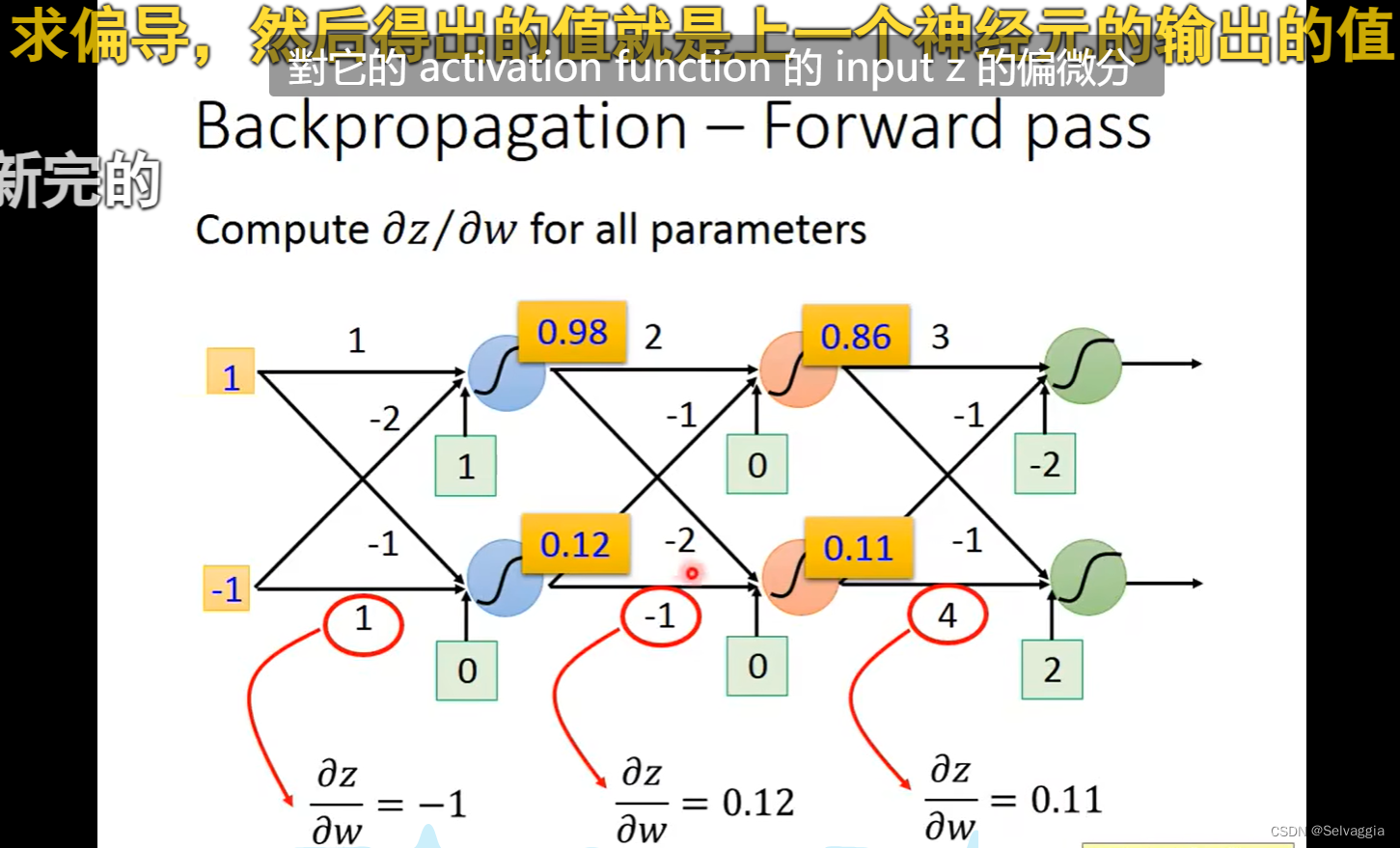
z到C要经过复杂的process,通过train rule反向传播
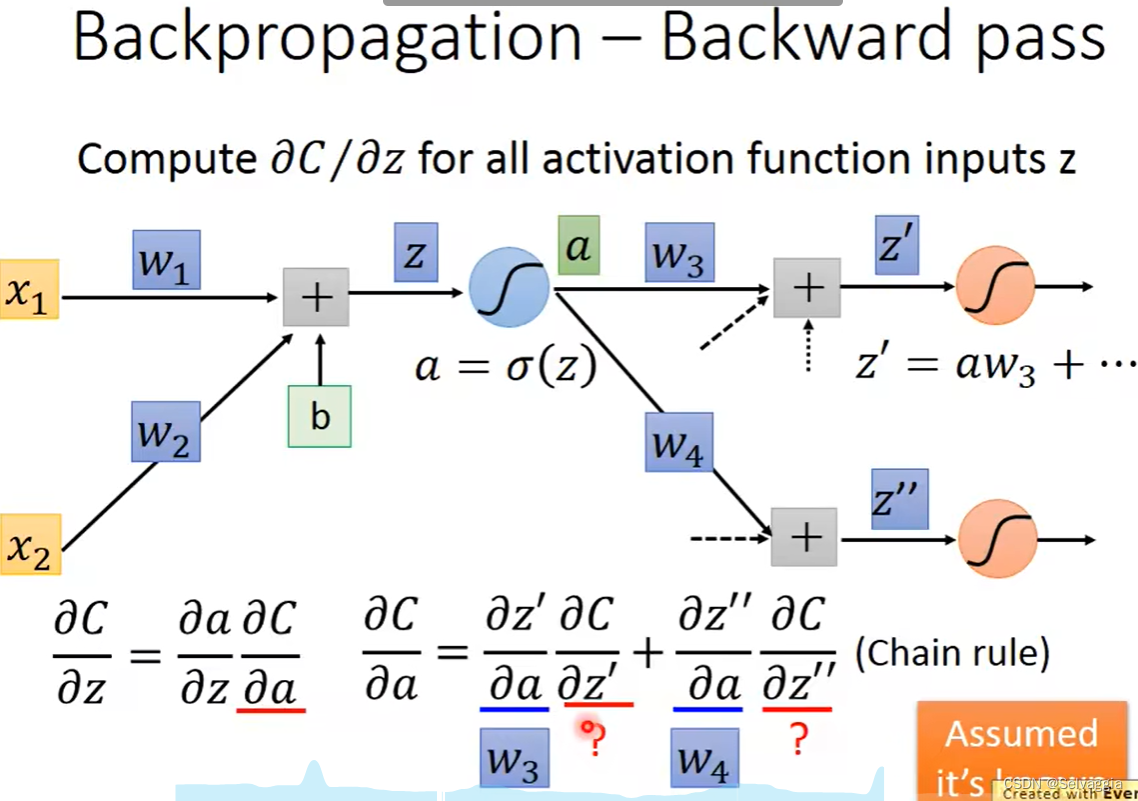
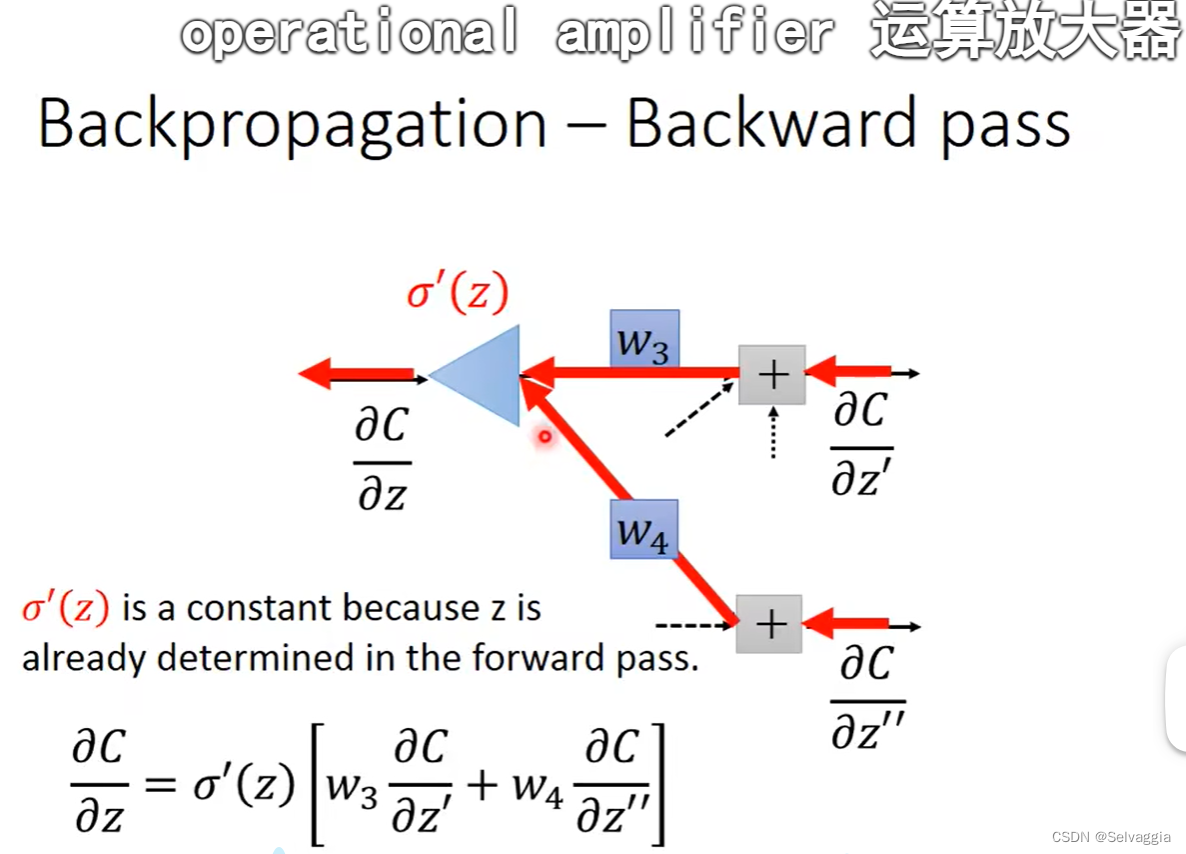
总价对各个参数的偏导