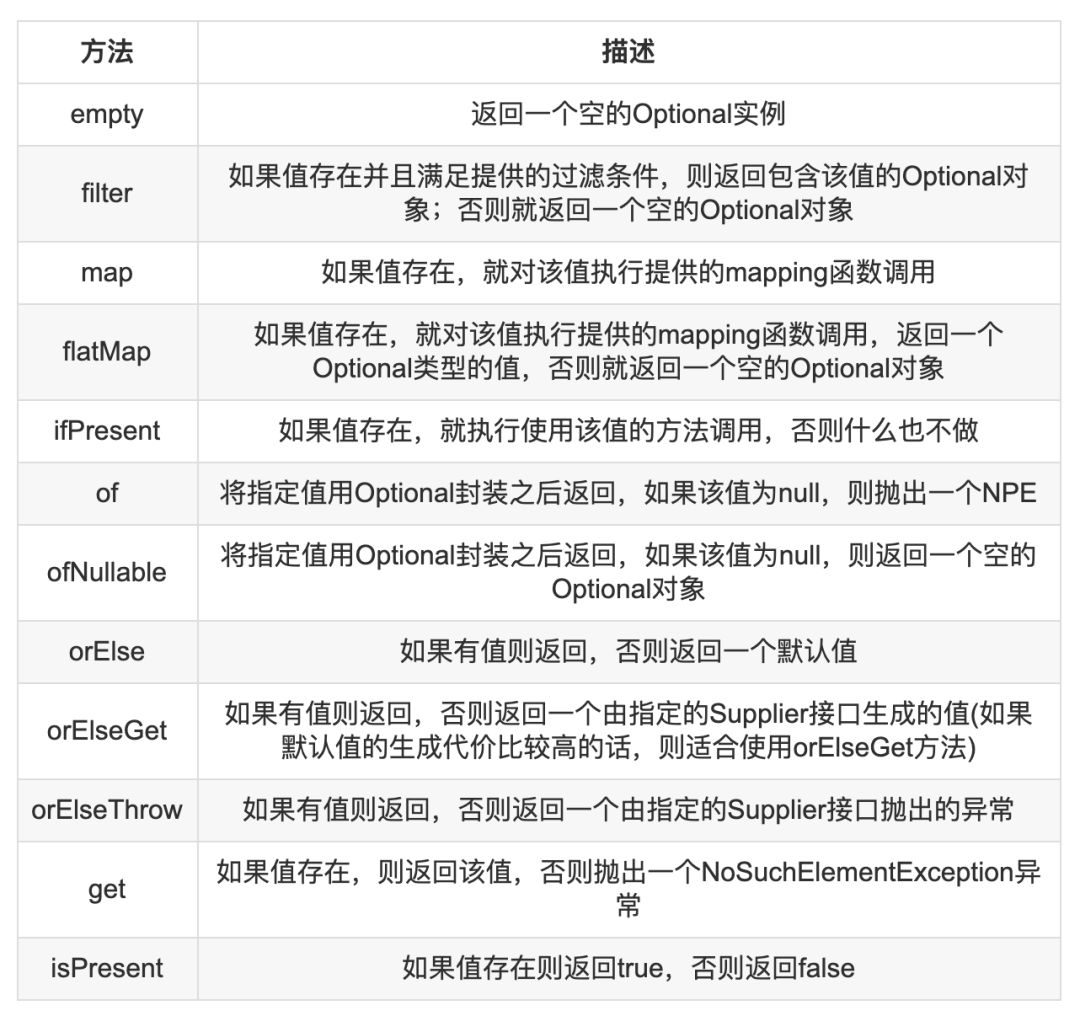
动态规划问题的一般形式就是求最值。动态规划其实是运筹学的一种最优化方法,只不过在计算机问题上应用比较多,比如说求最长递增子序列呀,最小编辑距离呀等等。
既然是要求最值,核心问题是什么呢?求解动态规划的核心问题是穷举。因为要求最值,肯定要把所有可行的答案穷举出来,然后在其中找最值呗。
一个模型三个特征
什么样的问题适合用动态规划来解决呢?换句话说,动态规划能解决的问题有什么规律可循呢?这部分理论可以总结为“一个模型三个特征”。
一个模型
首先,我们来看,什么是“一个模型”?它指的是动态规划适合解决的问题的模型。我把这个模型定义为多阶段决策最优解模型,我们一般是用动态规划来解决最优问题。
解决问题的过程,需要经历多个决策阶段。每个决策阶段都对应着一组状态。然后我们寻找一组决策序列,经过这组决策序列,能够产生最终期望求解的最优值。
三个特征
什么是“三个特征”?它们分别是最优子结构、无后效性和重复子问题
1 最优子结构
最优子结构指的是,问题的最优解包含子问题的最优解。反过来说就是,我们可以通过子问题的最优解,推导出问题的最优解。如果我们把最优子结构,对应到我们前面定义的动态规划问题模型上,那我们也可以理解为,后面阶段的状态可以通过前面阶段的状态推导出来。最优子结构,就是目前的最优解可以由以前的最优解推导出来,也就是存在状态转移公式
2 无后效性
无后效性有两层含义,第一层含义是,在推导后面阶段的状态的时候,我们只关心前面阶段的状态值,不关心这个状态是怎么一步一步推导出来的。第二层含义是,某阶段状态一旦确定,就不受之后阶段的决策影响。无后效性是一个非常“宽松”的要求。只要满足前面提到的动态规划问题模型,其实基本上都会满足无后效性。无后效性 其实就是当前状态与路径无关、当前的决定不受后面的影响,子问题的最优决策只与子问题自己相关,与原始问题无关,解决子问题时候不用考虑原始问题,就和递归只要考虑当前层状态和处理一样
3 重复子问题
不同的决策序列,到达某个相同的阶段时,可能会产生重复的状态
解题框架
虽然动态规划的核心思想就是穷举求最值,但是问题可以千变万化,穷举所有可行解其实并不是一件容易的事:
- 需要熟练掌握递归思维,只有列出正确的「状态转移方程」,才能正确地穷举。
- 需要判断算法问题是否具备「最优子结构」,是否能够通过子问题的最值得到原问题的最值。
- 动态规划问题存在「重叠子问题」,如果暴力穷举的话效率会很低,所以需要使用「备忘录」或者「DP table」来优化穷举过程,避免不必要的计算
以上最难的是写出状态转移方程,给出一个思维框架
明确 base case -> 明确「状态」-> 明确「选择」 -> 定义 dp 数组/函数的含义,按上面的套路走,最后的解法代码就会是如下的框架
# 自顶向下递归的动态规划
def dp(状态1, 状态2, ...):
for 选择 in 所有可能的选择:
# 此时的状态已经因为做了选择而改变
result = 求最值(result, dp(状态1, 状态2, ...))
return result
# 自底向上迭代的动态规划
# 初始化 base case
dp[0][0][...] = base case
# 进行状态转移
for 状态1 in 状态1的所有取值:
for 状态2 in 状态2的所有取值:
for ...
dp[状态1][状态2][...] = 求最值(选择1,选择2...)
示例:暴力递归
首先看一个斐波那契数列的暴力递归方法:
int fib(int N) {
if (N == 1 || N == 2) return 1;
return fib(N - 1) + fib(N - 2);
}
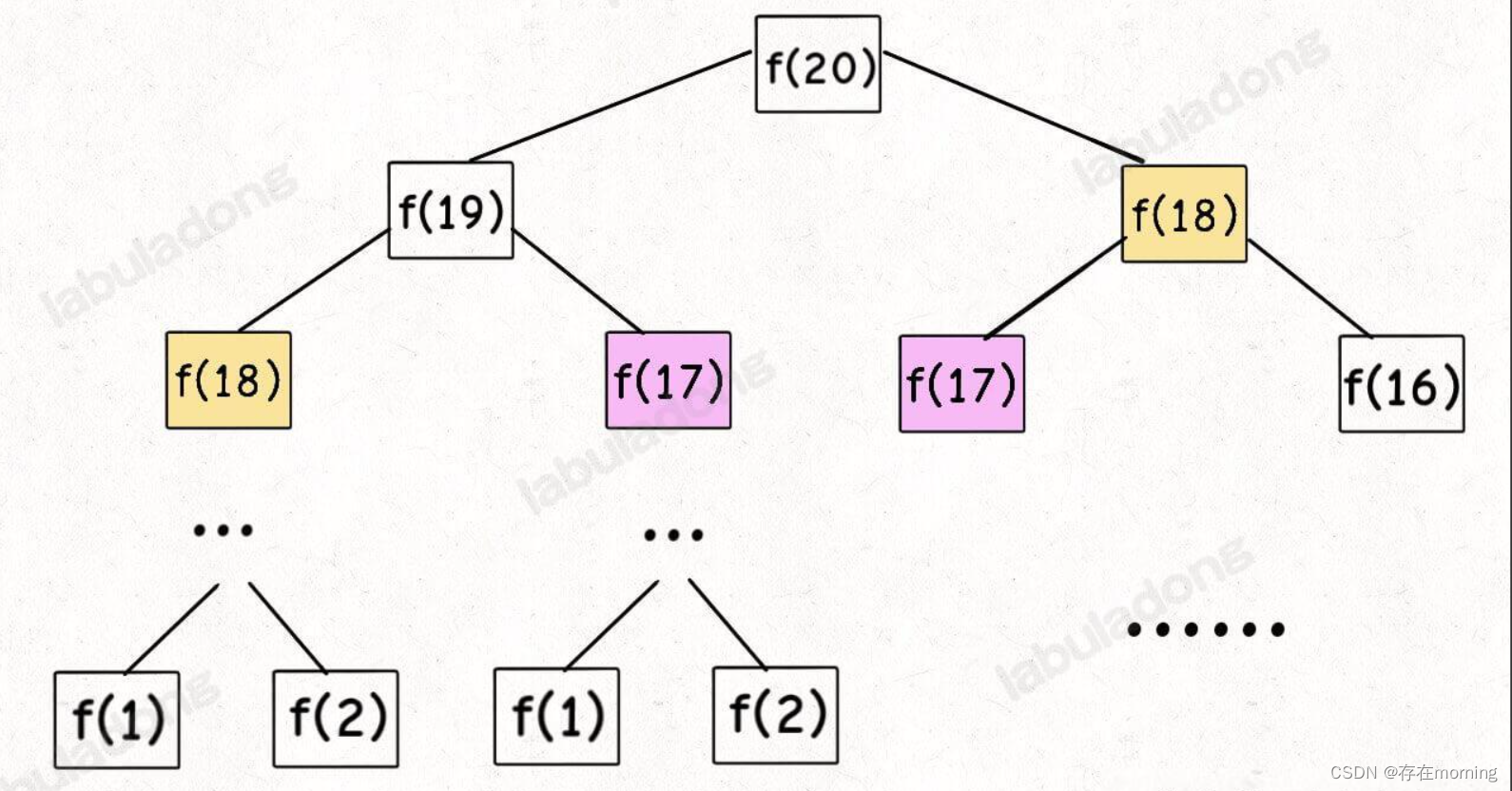
这个递归树怎么理解?就是说想要计算原问题 f(20),我就得先计算出子问题 f(19) 和 f(18),然后要计算 f(19),我就要先算出子问题 f(18) 和 f(17),以此类推。最后遇到 f(1) 或者 f(2) 的时候,结果已知,就能直接返回结果,递归树不再向下生长了
递归算法的时间复杂度怎么计算?就是用子问题个数乘以解决一个子问题需要的时间
首先计算子问题个数,即递归树中节点的总数。显然二叉树节点总数为指数级别,所以子问题个数为 O(2^n)。然后计算解决一个子问题的时间,在本算法中,没有循环,只有 f(n - 1) + f(n - 2) 一个加法操作,时间为 O(1)。
所以,这个算法的时间复杂度为二者相乘,即 O(2^n),指数级别,爆炸,观察递归树,很明显发现了算法低效的原因:存在大量重复计算,比如 f(18) 被计算了两次,而且你可以看到,以 f(18) 为根的这个递归树体量巨大,多算一遍,会耗费巨大的时间。更何况,还不止 f(18) 这一个节点被重复计算,所以这个算法及其低效。
这就是动态规划问题的第一个性质:重叠子问题
自顶向下:递归+备忘录
即然耗时的原因是重复计算,那么我们可以造一个「备忘录」,每次算出某个子问题的答案后别急着返回,先记到「备忘录」里再返回;每次遇到一个子问题先去「备忘录」里查一查,如果发现之前已经解决过这个问题了,直接把答案拿出来用,不要再耗时去计算了。
一般使用一个数组充当这个「备忘录」,当然你也可以使用哈希表(字典),思想都是一样的
int fib(int N) {
// 备忘录全初始化为 0
int[] memo = new int[N + 1];
// 进行带备忘录的递归
return dp(memo, N);
}
// 带着备忘录进行递归
int dp(int[] memo, int n) {
// base case
if (n == 0 || n == 1) return n;
// 已经计算过,不用再计算了
if (memo[n] != 0) return memo[n];
memo[n] = dp(memo, n - 1) + dp(memo, n - 2);
return memo[n];
}
实际上,带「备忘录」的递归算法,把一棵存在巨量冗余的递归树通过「剪枝」,改造成了一幅不存在冗余的递归图,极大减少了子问题(即递归图中节点)的个数
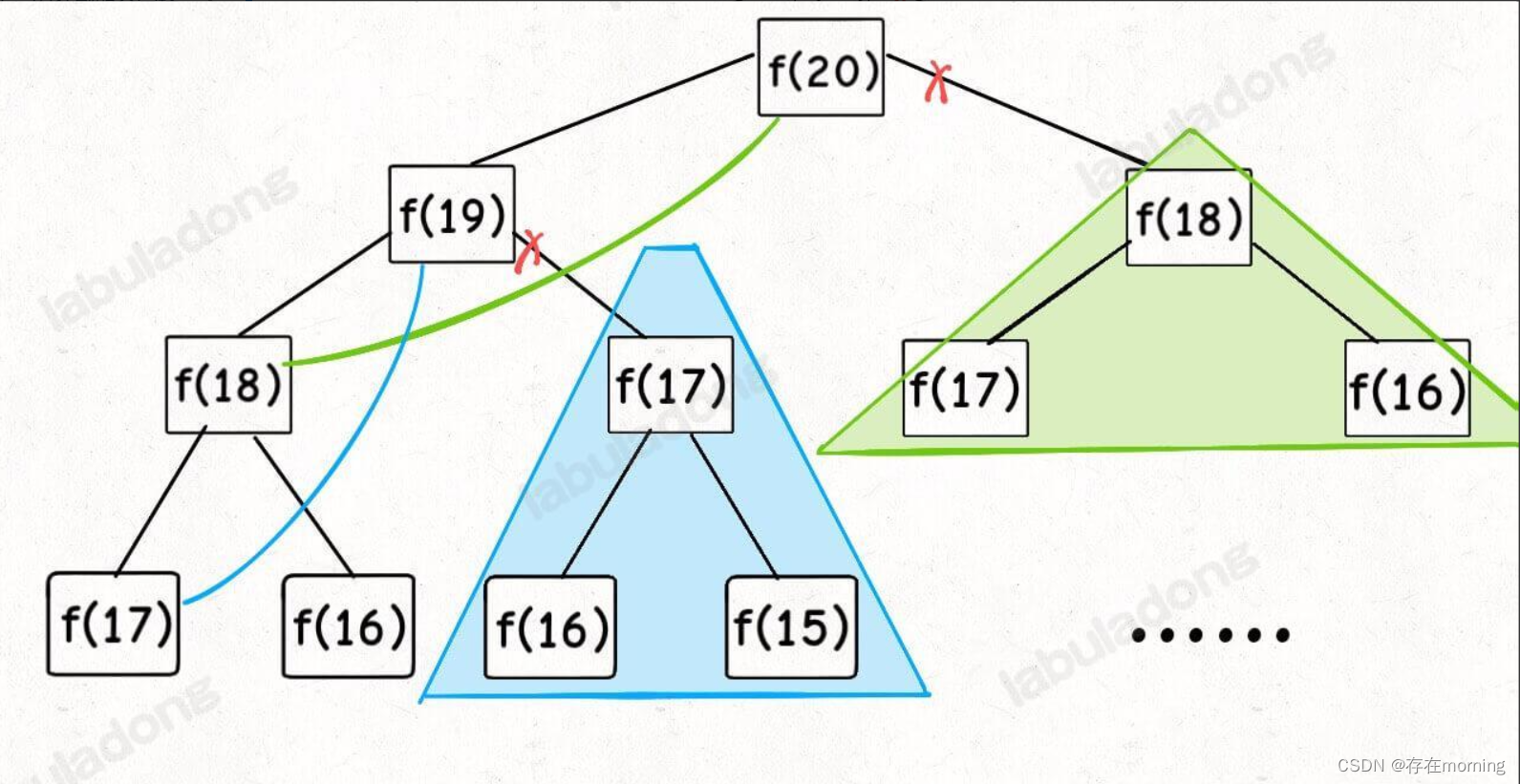
子问题个数,即图中节点的总数,由于本算法不存在冗余计算,子问题就是 f(1), f(2), f(3) … f(20),数量和输入规模 n = 20 成正比,所以子问题个数为 O(n)。解决一个子问题的时间,同上,没有什么循环,时间为 O(1),所以,本算法的时间复杂度是 O(n),比起暴力算法,是降维打击
自底向上:状态转移表法(DP Table)
带备忘录的递归和常见的动态规划解法已经差不多了,只不过这种解法是「自顶向下」进行「递归」求解,我们更常见的动态规划代码是「自底向上」进行「递推」求解
注意我们刚才画的递归树(或者说图),是从上向下延伸,都是从一个规模较大的原问题比如说 f(20),向下逐渐分解规模,直到 f(1) 和 f(2) 这两个 base case,然后逐层返回答案,这就叫「自顶向下」。
啥叫「自底向上」?反过来,我们直接从最底下、最简单、问题规模最小、已知结果的 f(1) 和 f(2)(base case)开始往上推,直到推到我们想要的答案 f(20)。这就是「递推」的思路,这也是动态规划一般都脱离了递归,而是由循环迭代完成计算的原因
有了上一步「备忘录」的启发,我们可以把这个「备忘录」独立出来成为一张表,通常叫做 DP table,在这张表上完成「自底向上」的推算
int fib(int N) {
if (N == 0) return 0;
int[] dp = new int[N + 1];
// base case
dp[0] = 0; dp[1] = 1;
// 状态转移
for (int i = 2; i <= N; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
}
return dp[N];
}
实际上,带备忘录的递归解法中的那个「备忘录」memo 数组,最终完成后就是这个解法中的 dp 数组
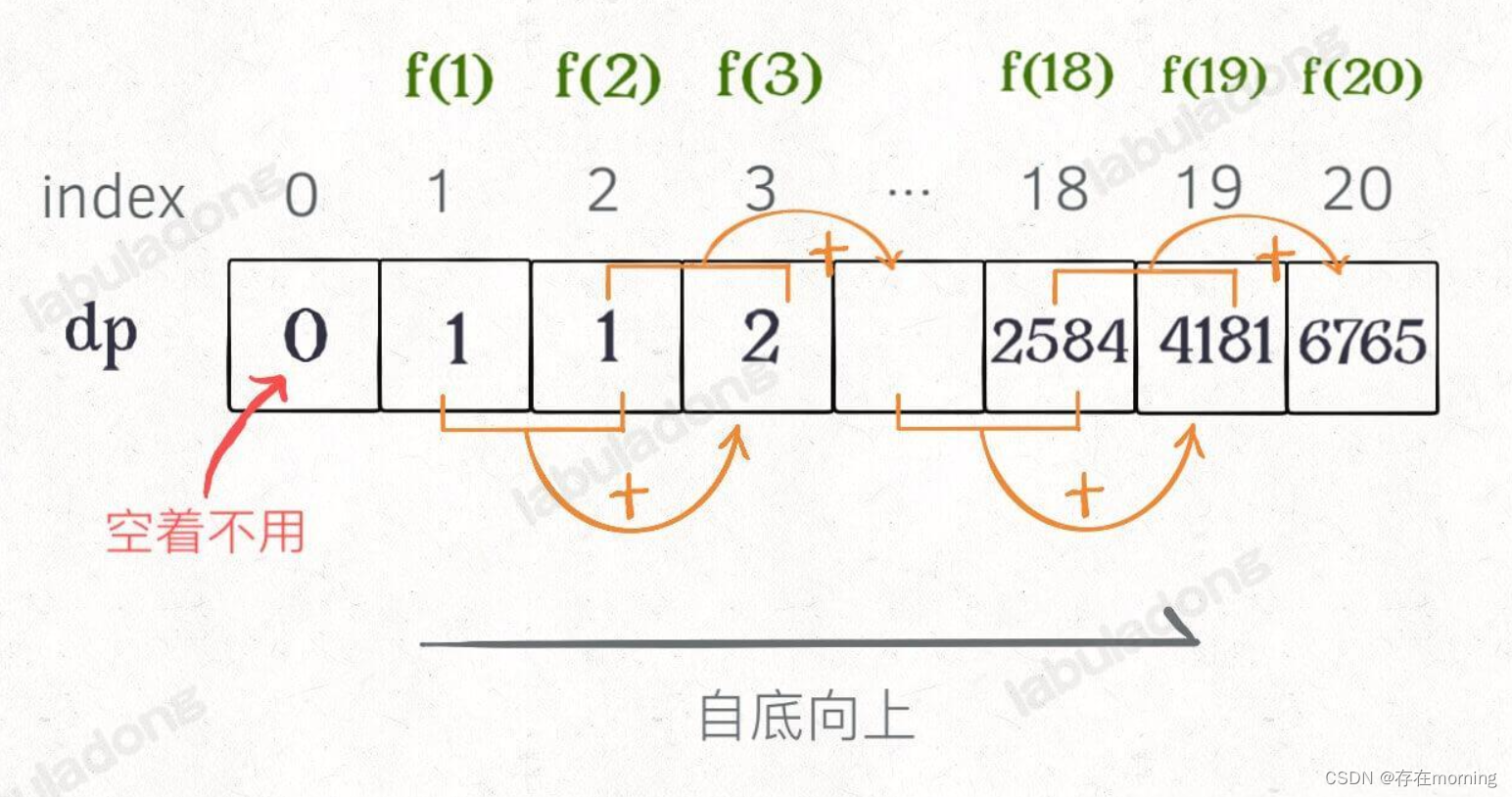
什么是状态转移方程?把参数 n 想做一个状态,这个状态 n 是由状态 n - 1 和状态 n - 2 转移(相加)而来,这就叫状态转移,仅此而已。 你会发现,上面的几种解法中的所有操作,例如 return f(n - 1) + f(n - 2),dp[i] = dp[i - 1] + dp[i - 2],以及对备忘录或 DP table 的初始化操作,都是围绕这个方程式的不同表现形式
根据斐波那契数列的状态转移方程,当前状态 n 只和之前的 n-1, n-2 两个状态有关,其实并不需要那么长的一个 DP table 来存储所有的状态,只要想办法存储之前的两个状态就行了
int fib(int n) {
if (n == 0 || n == 1) {
// base case
return n;
}
// 分别代表 dp[i - 1] 和 dp[i - 2]
int dp_i_1 = 1, dp_i_2 = 0;
for (int i = 2; i <= n; i++) {
// dp[i] = dp[i - 1] + dp[i - 2];
int dp_i = dp_i_1 + dp_i_2;
// 滚动更新
dp_i_2 = dp_i_1;
dp_i_1 = dp_i;
}
return dp_i_1;
}
所以,可以进一步优化,把空间复杂度降为 O(1)
![2023年中国预缩机产量、需求量及市场规模分析[图]](https://img-blog.csdnimg.cn/img_convert/43a48e8e0320b04113b238725c30a15c.png)