一、java中的容器
集合主要分为Collection和Map两大接口;Collection集合的子接口有List、Set;List集合的实现类有ArrayList底层是数组、LinkedList底层是双向非循环列表、Vector;Set集合的实现类有HashSet、TreeSet;Map集合的实现类有HashMap、TreeMap、HashTable;
(补充:HashTable与HashMap类似,线程安全,子接口有Properties接口,线程安全)
1.HashMap底层原理?
HashMap是以键值对形式存储数据的,底层由散列表组成,jdk1.8之前是数组+链表,jdk1.8之后数组+链表+红黑树组成。( 默认数组长度:16)
当添加元素时,链表的长度大于等于8,数组的长度小于64,将数组长度扩容原数组长度的2倍;当链表的长度大于等于8,并且数组的长度大于等于64时将链表转为红黑树。红黑树是平衡二叉搜索树,效率高。
当删除元素时,链表长度小于7,将红黑树转为链表。
(补充:jdk1.8之前头插法,jdk1.8及之后尾插法;1.7创建map时默认容量16,1.8创建map时默认无容量,添加后为初始化长度为16
Hash冲突:链地址法、开放地址法,再次hash法,建立公共溢出区)
2.ArrayList、LinkedList、Vector集合的区别?
ArrayList集合的底层是数组,适用于集合的遍历和随机访问某个元素的场景;添加元素时,每次扩容为原数组长度的1.5倍。(长度默认0,调用add方法后没有指定长度为10)
LinkedList集合的底层是双向非循环链表,中间插入和删除元素效率比较高,遍历效率比较低。
Vector集合与ArrayList类似,底层也是数组,线程是安全的,每个方法都由synchronized修饰,执行效率较低。(每次扩容为原数组长度2倍)
(补充:线程安全可以使用juc提供的集合CopyOnWriteArrayList写时复制)
二、为什么 HashMap 的加载因子是0.75?
为什么HashMap需要加载因子
-
解决冲突有什么方法?
-
1.开放定址法
-
2.再哈希法
-
3.建立一个公共溢出区
-
4.链地址法(拉链法)
-
-
为什么HashMap加载因子一定是0.75?而不是0.8,0.6?
-
那么为什么不可以是0.8或者0.6呢?
HashMap的底层是哈希表,是存储键值对的结构类型,它需要通过一定的计算才可以确定数据在哈希表中的存储位置:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// AbstractMap
public int hashCode() {
int h = 0;
Iterator<Entry<K,V>> i = entrySet().iterator();
while (i.hasNext())
h += i.next().hashCode();
return h;
}一般的数据结构,不是查询快就是插入快,HashMap就是一个插入慢、查询快的数据结构。
但这种数据结构容易产生两种问题:
① 如果空间利用率高,那么经过的哈希算法计算存储位置的时候,会发现很多存储位置已经有数据了(哈希冲突);
② 如果为了避免发生哈希冲突,增大数组容量,就会导致空间利用率不高。
而加载因子表示Hash表中元素的填满程度。
1. 加载因子
加载因子 = 填入表中的元素个数 / 散列表的长度
加载因子越大,填满的元素越多,空间利用率越高,但发生冲突的机会变大了;
加载因子越小,填满的元素越少,冲突发生的机会减小,但空间浪费了更多了,而且还会提高扩容rehash操作的次数。
冲突的机会越大,说明需要查找的数据还需要通过另一个途径查找,这样查找的成本就越高。因此,必须在“冲突的机会”与“空间利用率”之间,寻找一种平衡与折衷。
所以我们也能知道,影响查找效率的因素主要有这几种:
-
散列函数是否可以将哈希表中的数据均匀地散列?
-
怎么处理冲突?
-
哈希表的加载因子怎么选择?
2. 解决冲突有什么方法?
1. 开放定址法
Hi = (H(key) + di) MOD m,其中i=1,2,…,k(k<=m-1)H(key)为哈希函数,m为哈希表表长,di为增量序列,i为已发生冲突的次数。其中,开放定址法根据步长不同可以分为3种:
1.1 线性探查法(Linear Probing):di = 1,2,3,…,m-1
简单地说,就是以当前冲突位置为起点,步长为1循环查找,直到找到一个空的位置,如果循环完了都占不到位置,就说明容器已经满了。举个栗子,就像你在饭点去街上吃饭,挨家去看是否有位置一样。
1.2 平方探测法(Quadratic Probing):di = ±12, ±22,±32,…,±k2(k≤m/2)
相对于线性探查法,这就相当于的步长为di = i2来循环查找,直到找到空的位置。以上面那个例子来看,现在你不是挨家去看有没有位置了,而是拿手机算去第i2家店,然后去问这家店有没有位置。
1.3 伪随机探测法:di = 伪随机数序列
这个就是取随机数来作为步长。还是用上面的例子,这次就是完全按心情去选一家店问有没有位置了。
但开放定址法有这些缺点:
-
这种方法建立起来的哈希表,当冲突多的时候数据容易堆集在一起,这时候对查找不友好;
-
删除结点的时候不能简单将结点的空间置空,否则将截断在它填入散列表之后的同义词结点查找路径。因此如果要删除结点,只能在被删结点上添加删除标记,而不能真正删除结点;
-
如果哈希表的空间已经满了,还需要建立一个溢出表,来存入多出来的元素。
2. 再哈希法
Hi = RHi(key), 其中i=1,2,…,kRHi()函数是不同于H()的哈希函数,用于同义词发生地址冲突时,计算出另一个哈希函数地址,直到不发生冲突位置。这种方法不容易产生堆集,但是会增加计算时间。
所以再哈希法的缺点是:增加了计算时间。
3. 建立一个公共溢出区
假设哈希函数的值域为[0, m-1],设向量HashTable[0,…,m-1]为基本表,每个分量存放一个记录,另外还设置了向量OverTable[0,…,v]为溢出表。基本表中存储的是关键字的记录,一旦发生冲突,不管他们哈希函数得到的哈希地址是什么,都填入溢出表。
但这个方法的缺点在于:查找冲突数据的时候,需要遍历溢出表才能得到数据。
4. 链地址法(拉链法)
将冲突位置的元素构造成链表。在添加数据的时候,如果哈希地址与哈希表上的元素冲突,就放在这个位置的链表上。
拉链法的优点:
-
处理冲突的方式简单,且无堆集现象,非同义词绝不会发生冲突,因此平均查找长度较短;
-
由于拉链法中各链表上的结点空间是动态申请的,所以它更适合造表前无法确定表长的情况;
-
删除结点操作易于实现,只要简单地删除链表上的相应的结点即可。
拉链法的缺点:需要额外的存储空间。
从HashMap的底层结构中我们可以看到,HashMap采用是数组+链表/红黑树的组合来作为底层结构,也就是开放地址法+链地址法的方式来实现HashMap。

3. 为什么HashMap加载因子一定是0.75?而不是0.8,0.6?
HashMap的底层其实也是哈希表(散列表),而解决冲突的方式是链地址法。HashMap的初始容量大小默认是16,为了减少冲突发生的概率,当HashMap的数组长度到达一个临界值的时候,就会触发扩容,把所有元素rehash之后再放在扩容后的容器中,这是一个相当耗时的操作。
而这个临界值就是由加载因子和当前容器的容量大小来确定的:
临界值 = DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR即默认情况下是16x0.75=12时,就会触发扩容操作。
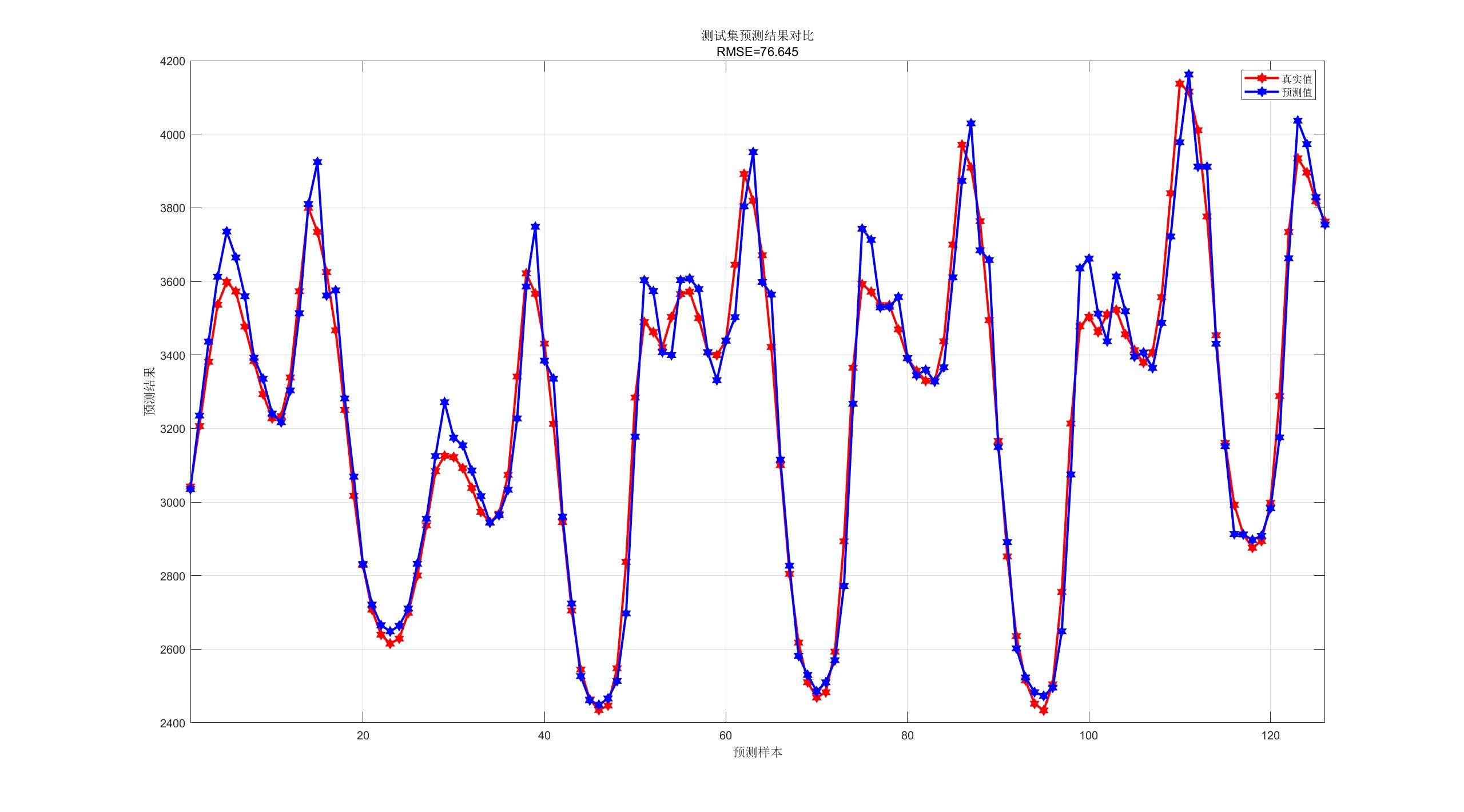
那么为什么选择了0.75作为HashMap的加载因子呢?这个跟一个统计学里很重要的原理——泊松分布有关。
泊松分布是统计学和概率学常见的离散概率分布,适用于描述单位时间内随机事件发生的次数的概率分布。有兴趣推荐:维基百科或者阮一峰老师的这篇文章:泊松分布和指数分布
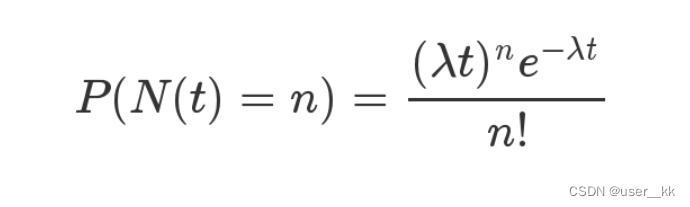
等号的左边,P 表示概率,N表示某种函数关系,t 表示时间,n 表示数量。等号的右边,λ 表示事件的频率。
在HashMap的源码中有这么一段注释:
* Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million理想情况下,使用随机哈希码,在扩容阈值(加载因子)为0.75的情况下,节点出现在频率在Hash桶(表)中遵循参数平均为0.5的泊松分布。忽略方差,即X = λt,P(λt = k),其中λt = 0.5的情况,按公式:
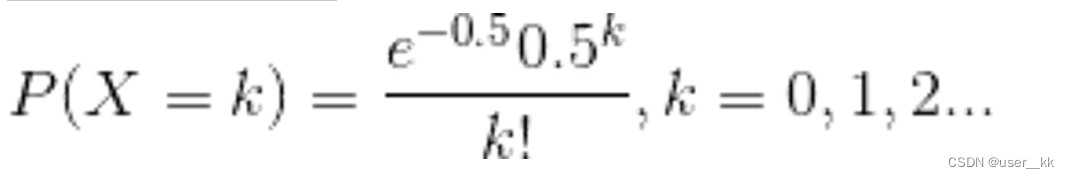
计算结果如上述的列表所示,当一个bin中的链表长度达到8个元素的时候,概率为0.00000006,几乎是一个不可能事件。
所以其实常数0.5是作为参数代入泊松分布来计算的,而加载因子0.75是作为一个条件,当HashMap长度为length/size ≥ 0.75时就扩容,在这个条件下,冲突后的拉链长度和概率结果为:
0: 0.60653066
1: 0.30326533
2: 0.07581633
3: 0.01263606
4: 0.00157952
5: 0.00015795
6: 0.00001316
7: 0.00000094
8: 0.000000064.为什么不可以是0.8或者0.6呢?
HashMap中除了哈希算法之外,有两个参数影响了性能:初始容量和加载因子。初始容量是哈希表在创建时的容量,加载因子是哈希表在其容量自动扩容之前可以达到多满的一种度量。
5. 在维基百科来描述加载因子:
对于开放定址法,加载因子是特别重要因素,应严格限制在0.7-0.8以下。超过0.8,查表时的CPU缓存不命中(cache missing)按照指数曲线上升。因此,一些采用开放定址法的hash库,如Java的系统库限制了加载因子为0.75,超过此值将resize散列表。
在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少扩容rehash操作次数,所以,一般在使用HashMap时建议根据预估值设置初始容量,以便减少扩容操作。
选择0.75作为默认的加载因子,完全是时间和空间成本上寻求的一种折衷选择。