Fork/Join框架介绍
什么是Fork/Join
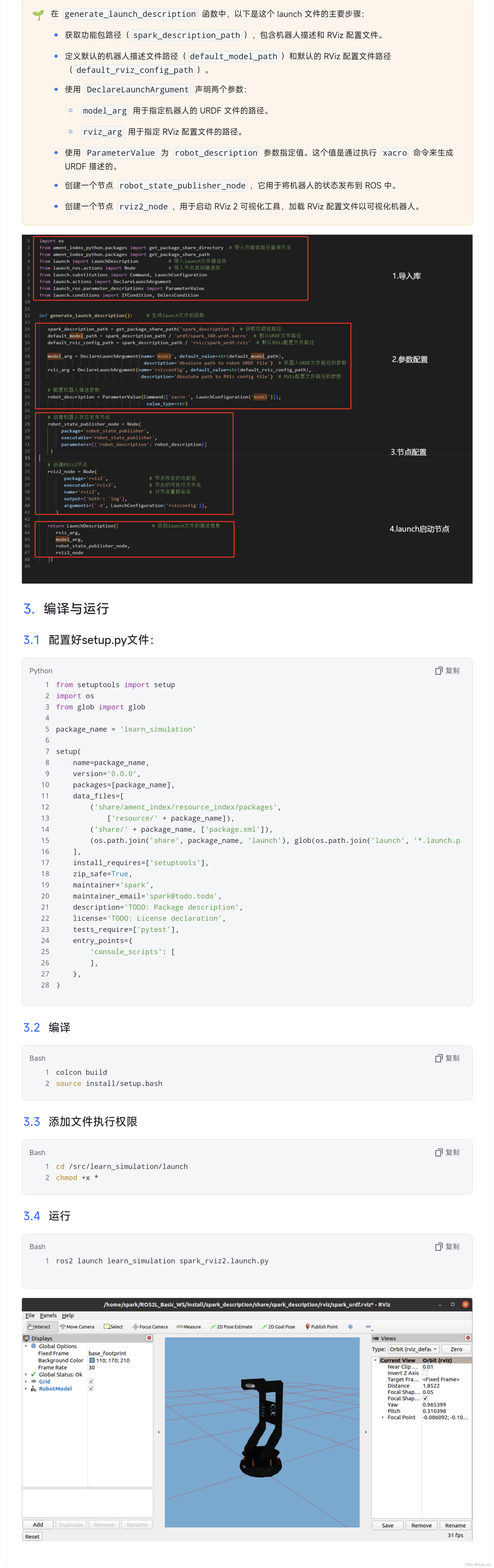
Fork/Join是一个是一个并行计算的框架,主要就是用来支持分治任务模型。
Fork 对应的是分治任务模型里的任务分解,Join 对应的是结果合并。
核心思想:将一个大任务分成许多小任务,然后并行执行这些小任务,最终将它们的结果合并成一个大的结果。
应用场景
1、递归分解型任务
这类任务通常可以将大任务分解成若干子任务,每个子任务可以独立执行,并且可以归并子任务得到有序的结果
举例:排序、归并、遍历
2、数组处理
处理大型数组时,可以将大数组分解成若干子数组,子数组并行处理,最后归并子数组的结果
举例:数组的排序、统计、查找
3、并行化算法
将问题分解成若干子问题,并行解决每个子问题,最后合并子问题得到最终解决方案
举例:并行化图像处理算法、并行化机器学习算法
4、大数据处理
将数据分成若干分片,并行处理每个分片,最后将处理后的分片合并成完整结果
举例:大型日志文件处理、大型数据库的查询
Fork/Join使用
Fork/Join框架的主要组成部分是ForkJoinPool、ForkJoinTask。ForkJoinPool是一个线程池,它用于管理ForkJoin任务的执行。ForkJoinTask是一个抽象类,用于表示可以被分割成更小部分的任务。
ForkJoinPool
ForkJoinPool是Fork/Join框架中的线程池类,它用于管理Fork/Join任务的线程。
方法:submit()、invoke()、shutdown()、awaitTermination()等
(提交任务、执行任务、关闭线程池、等待任务执行结果)
参数:线程池的大小、工作线程的优先级、任务队列的容量等,根据具体应用场景设置
构造器
ForkJoinPool中有四个核心参数,用于控制线程池的并行数、工作线程的创建、异常处理和模式指定等。
-
int parallelism:指定并行级别(parallelism level)。ForkJoinPool将根据这个设定,决定工作线程的数量。如果未设置的话,将使用Runtime.getRuntime().availableProcessors()来设置并行级别;
-
ForkJoinWorkerThreadFactory factory:ForkJoinPool在创建线程时,会通过factory来创建。注意,这里需要实现的是ForkJoinWorkerThreadFactory,而不是ThreadFactory。如果不指定factory,那么将由默认的DefaultForkJoinWorkerThreadFactory负责线程的创建工作;
-
UncaughtExceptionHandler handler:指定异常处理器,当任务在运行中出错时,将由设定的处理器处理;
-
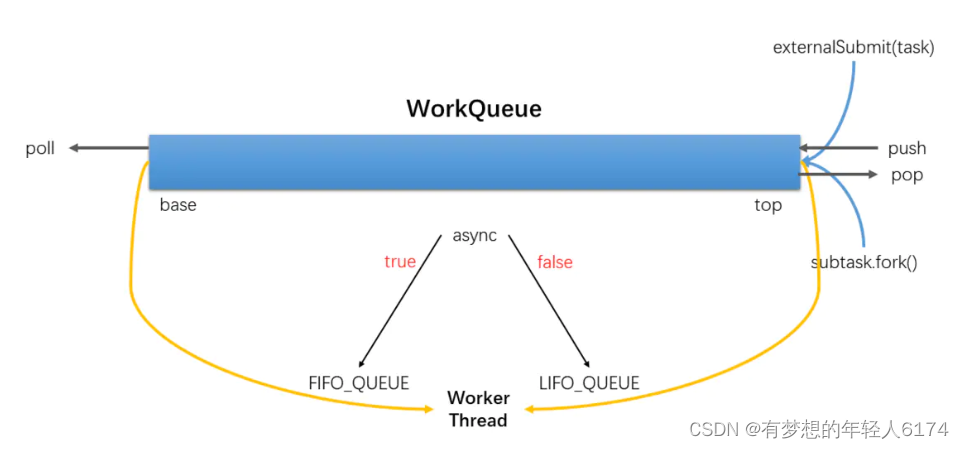
boolean asyncMode:设置队列的工作模式。当asyncMode为true时,将使用先进先出队列,而为false时则使用后进先出的模式。默认是false,后进先出
// 获取处理器数量,注意这里是逻辑核
int processors = Runtime.getRuntime().availableProcessors();
// 构建forkjoin线程池
ForkJoinPool forkJoinPool = new ForkJoinPool(processors);
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}任务提交方式(核心能力之一)
| 返回值 | 方法 | |
|---|---|---|
| 提交异步执行 | void | execute(ForkJoinTask task) execute(Runnable task) |
| 等待并获取结果 | T | invoke(ForkJoinTask task) |
| 提交执行获取Future结果 | ForkJoinTask | submit(ForkJoinTask task) submit(Callable task) submit(Runnable task) submit(Runnable task, T result) |
和普通线程池之间的区别
-
工作窃取算法
ForkJoinPool采用工作窃取算法来提高线程的利用率,而普通线程池则采用任务队列来管理任务。
工作窃取:一个线程完成自己的任务后,可以从其它线程的队列中获取一个任务来执行,提高线程的利用率。
-
任务的分解和合并
ForkJoinPool可以将一个大任务分解为多个小任务,并行地执行这些小任务,最终将它们的结果合并起来得到最终结果。而普通线程池只能按照提交的任务顺序一个一个地执行任务。
-
工作线程的数量
ForkJoinPool会根据当前系统的CPU核心数来自动设置工作线程的数量,以最大限度地发挥CPU的性能优势。而普通线程池需要手动设置线程池的大小,如果设置不合理,可能会导致线程过多或过少,从而影响程序的性能。
-
任务类型
ForkJoinPool适用于执行大规模任务并行化,而普通线程池适用于执行一些短小的任务,如处理请求等。
ForkJoinTask
ForkJoinTask是Fork/Join框架中的抽象类,它定义了执行任务的基本接口。用户可以通过继承ForkJoinTask类来实现自己的任务类,并重写其中的compute()方法来定义任务的执行逻辑。通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下三个子类:
-
RecursiveAction:用于递归执行但不需要返回结果的任务。
-
RecursiveTask :用于递归执行需要返回结果的任务。
-
CountedCompleter<T>:在任务完成执行后会触发执行一个自定义的钩子函数
调用方法
-
fork()——提交任务
fork()方法用于向当前任务所运行的线程池中提交任务。如果当前线程是ForkJoinWorkerThread类型,将会放入该线程的工作队列,否则放入common线程池的工作队列中。
-
join()——获取任务执行结果
join()方法用于获取任务的执行结果。调用join()时,将阻塞当前线程直到对应的子任务完成运行并返回结果。
计算斐波那契数列(处理递归任务)
斐波那契数列指的是这样一个数列:1,1,2,3,5,8,13,21,34,55,89... 这个数列从第3项 开始,每一项都等于前两项之和。
public class FibonacciDemo extends RecursiveTask<Integer>
{
final int n;
FibonacciDemo(int n)
{
this.n = n;
}
/**
* 重写RecursiveTask的compute()方法
*/
protected Integer compute()
{
if (n <= 1)
return n;
FibonacciDemo f1 = new FibonacciDemo(n - 1);
// 提交任务
f1.fork();
FibonacciDemo f2 = new FibonacciDemo(n - 2);
// 合并结果
return f2.compute() + f1.join();
}
public static void main(String[] args)
{
// 构建forkjoin线程池
ForkJoinPool pool = new ForkJoinPool();
FibonacciDemo task = new FibonacciDemo(100000); // 参数大,抛出StackOverflowError
// 提交任务并一直阻塞直到任务 执行完成返回合并结果。
int result = pool.invoke(task);
System.out.println(result);
}
}栈溢出如何解决
// 使用迭代方式,防止栈溢出
public class FibonacciDemo2
{
public static void main(String[] args)
{
int n = 100000;
long[] fib = new long[n + 1];
fib[0] = 0;
fib[1] = 1;
for (int i = 2; i <= n; i++)
{
fib[i] = fib[i - 1] + fib[i - 2];
}
System.out.println(fib[n]);
}
}处理递归任务注意事项
在使用Fork/Join框架处理递归任务时,需要根据实际情况来评估递归深度和任务粒度,以避免任务调度和内存消耗的问题。如果递归深度较大,可以尝试采用其他方法来优化算法,如使用迭代方式替代递归,或者限制递归深度来减少任务数量,以避免Fork/Join框架的缺点。
递归深度较大时,子任务可能被调度到不同的线程执行,线程的创建、销毁、任务调度占用大量资源。另外递归调用方法时,创建大量方法栈帧,可能导致栈内存溢出StackOverflowError
处理阻塞任务
1、防止线程饥饿:当一个线程在执行一个阻塞型任务时,它将会一直等待任务完成,没有任务窃取的情况下可能会一直阻塞下去。为防止这种情况发生,应该避免在ForkJoinPool中提交大量的阻塞型任务。
2、使用特定的线程池:为了最大程度地利用ForkJoinPool的性能,可以使用专门的线程池来处理阻塞型任务,这些线程不会被ForkJoinPool的窃取机制所影响。例如,可以使用ThreadPoolExecutor来创建一个线程池,然后将这个线程池作为ForkJoinPool的执行器,这样就可以使用ThreadPoolExecutor来处理阻塞型任务,而使用ForkJoinPool来处理非阻塞型任务。
3、不要阻塞工作线程:如果在ForkJoinPool中使用阻塞型任务,那么需要确保这些任务不会阻塞工作线程,否则会导致整个线程池的性能下降。为了避免这种情况,可以将阻塞型任务提交到一个专门的线程池中,或者使用CompletableFuture等异步编程工具来处理阻塞型任务。
// 结合CompletableFuture使用示例
public class BlockingTaskDemo
{
public static void main(String[] args)
{
// 构建一个forkjoin线程池
ForkJoinPool pool = new ForkJoinPool();
// 创建一个异步任务,并将其提交到ForkJoinPool中执行
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> {
try
{
// 模拟一个耗时的任务
TimeUnit.SECONDS.sleep(5);
return "Hello, world!";
}
catch (InterruptedException e)
{
e.printStackTrace();
return null;
}
}, pool);
try
{
// 等待任务完成,并获取结果
String result = future.get();
System.out.println(result);
}
catch (InterruptedException e)
{
e.printStackTrace();
}
catch (ExecutionException e)
{
e.printStackTrace();
}
finally
{
// 关闭ForkJoinPool,释放资源
pool.shutdown();
}
}
}ForkJoinPool工作原理
ForkJoinPool 内部有多个任务队列,当我们通过 ForkJoinPool 的 invoke() 或者 submit() 方法提交任务时,ForkJoinPool 根据一定的路由规则把任务提交到一个任务队列中,如果任务在执行过程中会创建出子任务,那么子任务会提交到工作线程对应的任务队列中。
另外,ForkJoinPool 支持一种叫 做“任务窃取”的机制,如果工作线程空闲了,那它可以“窃取”其他工作任务队列里的任务。充分利用CPU的性能。
工作任务队列是一个双端链表,窃取是从base端窃取,top端是正常执行取任务
工作线程ForkJoinWorkerThread
ForkJoinWorkerThread是ForkJoinPool中的一个专门用于执行任务的线程。
当一个ForkJoinWorkerThread被创建时,它会自动注册一个WorkQueue到ForkJoinPool中。这个WorkQueue是该线程专门用于存储自己的任务的队列,只能出现在WorkQueues[]的奇数位。在ForkJoinPool中,WorkQueues[]是一个数组,用于存储所有线程的WorkQueue。
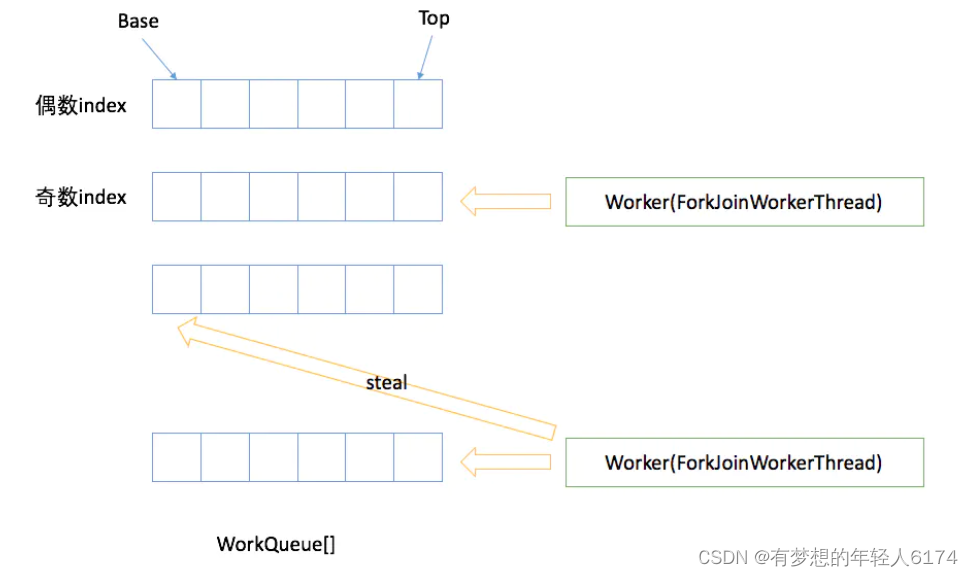
工作队列WorkQueue
WorkQueue是一个双端队列,用于存储工作线程自己的任务。每个工作线程都会维护一个本地的WorkQueue,并且优先执行本地队列中的任务。当本地队列中的任务执行完毕后,工作线程会尝试从其他线程的WorkQueue中窃取任务。
注意:在ForkJoinPool中,只有WorkQueues[]奇数位的WorkQueue是属于ForkJoinWorkerThread线程的,因此只有这些WorkQueue才能被线程本身使用和窃取任务。偶数位的WorkQueue是用于外部线程提交任务的,而且是由多个线程共享的,因此它们不能被线程窃取任务。
工作窃取
工作窃取,就是允许空闲线程从繁忙线程的双端队列中窃取任务。默认情况下,工作线程从它自己的双端队列的头部获取任务。但是,当自己的任务为空时,线程会从其他繁忙线程双端队列的尾部中获取任务。这种方法,最大限度地减少了线程竞争任务的可能性。
ForkJoinPool的大部分操作都发生在工作窃取队列(work-stealing queues ) 中,该队列由内部类WorkQueue实现。它是Deques的特殊形式,但仅支持三种操作方式:push、pop和poll(也称为窃取)。在ForkJoinPool中,队列的读取有着严格的约束,push和pop仅能从其所属线程调用,而poll则可以从其他线程调用。
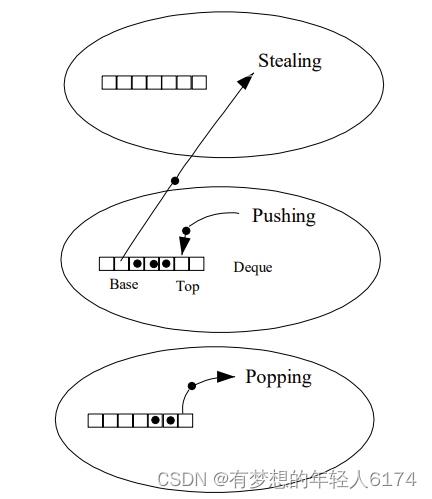
通过工作窃取,Fork/Join框架可以实现任务的自动负载均衡,以充分利用多核CPU的计算能力,同时也可以避免线程的饥饿和延迟问题
如果对 ForkJoinPool 详细的实现细节感兴趣,也可以参考Doug Lea 的论文
总结
Fork/Join是一种基于分治思想的模型,在并发处理计算型任务时有着显著的优势。
-
任务切分:将大的任务分割成更小粒度的小任务,让更多的线程参与执行;
-
任务窃取:通过任务窃取,充分地利用空闲线程,并减少竞争。
使用ForkJoinPool时,需要特别注意任务的类型是否为纯函数计算类型,也就是这些任务不应该关心状态或者外界的变化,这样才是最安全的做法。如果是阻塞类型任务,那么你需要谨慎评估技术方案。虽然ForkJoinPool也能处理阻塞类型任务,但可能会带来复杂的管理成本。
处理阻塞任务重点学习CompletableFuture,包含各种编排任务的方法