什么是类别不平衡问题
分类学习方法都有一个共同的基本假设,即不同类别的训练样例数目相当。如果不同类别的训练样例数目稍有差别,通常影响不大,但若差别很大,则会对学习过程造成困扰。例如有998个反例,但正例只有2个,那么学习方法只需返回一个永远将新样本预测为反例的学习器,就能达到99.8%的精度;然而这样的学习器往往没有价值,因为它不能预测出任何正例。
数学解释
以下是分类策略:
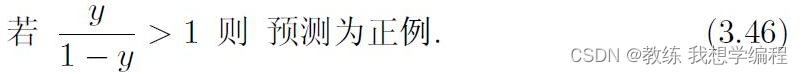
然而,当训练集中正、反例的数目不同时,令m+表示正例数目,m-表示反例数目,此时分类策略应该是:

如何解释呢?可以反方向解释,如果m+大于m-,那么学习到的模型就会偏向于预测正例,这对反例不公平,因此,只有当以上左边式子大于右边式子也就是大于1时,预测为正例才公平,这就是对训练集正例较多的惩罚。
然后可以稍作调整,这就是再平衡,也就是再缩放策略:
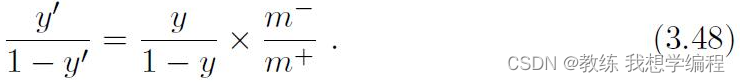
如何解释呢?和上面的解释类似,如果m+大于m-,那么学习到的模型就会偏向于预测正例,这对反例不公平,因此右式乘以了m-/m+,相当于将 y/1-y缩放了,这样要大于1就更加困难了,也相当于对正例的惩罚。
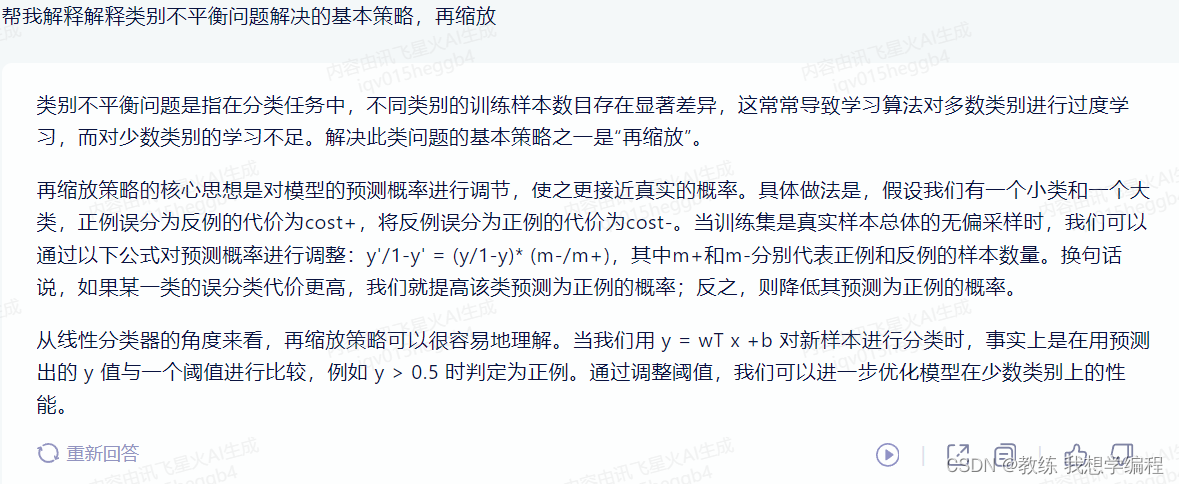
最后看一下人工智能的回答: