GPU是一种新硬件,相比较于CPU,有较高的读写带宽和更强的并行能力,在很多领域都有非常好的应用。今天我们以LSM-tree上的compaction和scan为例,介绍GPU如何在加速数据库的操作中发挥作用。
一、GPU的发展历程
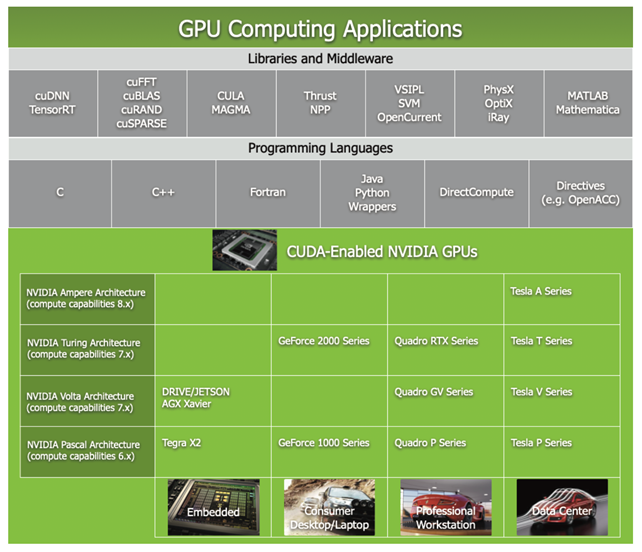
图1:GPU的发展
GPU发展之初,是作为集成单元与其他硬件聚合在一起,也就是我们所熟知的显卡。1999年,NVIDIA发布Geforce256,正式提出GPU概念;2006年,NVIDIA发布GeForce8800,发布CUDA,一种后面得到广泛使用的GPU编程语言;2011年,NVIDIA发布Tesla系列,形成计算产品线,GPU开始更多地应用于科学计算领域。2011年至今,GPU快速发展,主要被NVIDIA和AMD所垄断,一些国产公司也开始研发一些替代品。
现在,GPU在CUDA语言的基础上,提供了对于多种语言如C++、python的支持,并且有很多现成的算法库用来进行深度学习,矩阵乘法,通用计算等等。这些很大程度上降低了GPU编程的门槛,使得GPU的进一步广泛应用成为了可能。
目前GPU的主要应用有三个领域:
1) 通用高性能计算,例如自动驾驶、智慧医疗、生命科学、云计算、数据处理、金融等方面。
2) 人工智能计算。
3) 图形计算。
2021图灵奖于近日揭晓,高性能计算先驱Jack Dongarra获奖,以表彰他在高性能计算领域所做出的突出贡献。他曾经说“未来的计算结构会是CPU和GPU的结合。”可见GPU正越来越受到大家的关注和认可。
提到GPU的发展,我们就不得不提NVIDIA一年一度的技术大会(GTC),每次都会发布最近的技术或产品。GTC 2022于3月22日召开,发布了NVIDIA的最新一代GPU H100。它采用的是台积电4nm工艺, 拥有800亿晶体管;对比A100,有300%~600%的性能提升;一块 H100 的 IO 带宽就是 40 terabyte 每秒。
“为了形象一点说明这是个什么数字,20块英伟达 H100 带宽就相当于全球的互联网通信。”黄仁勋说道。
同时,NVIDIA宣布基于 H100 芯片即将自建一个名叫 EoS 的超级计算机,其由 18 个DGX POD 组成,一共 4608 个 H100 GPU,从 AI 计算的角度来看,EoS 输出18.4 Exaflops,是当今全球第一超算富岳的四倍。NVIDIA表示,阿里云、亚马逊AWS、谷歌云和微软Azure等大公司都将采用英伟达的新芯片。此外,戴尔和惠普企业等计算机制造商将提供基于这些新芯片的计算机。除此之外,新一代的H100也提供了许多新特性,例如支持机密计算、加速动态编程算法、新一代NVLink等等。
可以看出H100相比较于上一代的A100,有巨大的性能优势,是NVIDIA发布的又一个里程碑式的产品。
近年来,国产GPU也有了长足的发展。3月30日下午,北京GPU创企摩尔线程推出基于架构MUSA的首款GPU苏堤,以及基于苏堤的首款台式机显卡MTT S60、首款服务器产品MTT S2000。摩尔线程创始人兼CEO张建中为前英伟达全球副总裁、中国区总经理。苏堤是摩尔线程的全功能GPU,有图形、智能多媒体、AI、物理四大引擎,在此之上有各种编译工具及平台,并支持OpenCL、SYCL、CUDA、Vulkan、DirectX、OpenGL/GLES等主流编程接口,还有针对具体应用的各类行业解决方案。特别地,基于苏堤的首款台式机显卡MTT S60,据张建中介绍,是第一款能打英雄联盟游戏的国产显卡,支持所有主流国产PC操作系统。苏堤对于GPU全功能的实现,对于各种主流编程接口的支持,使得它在各种服务器或数据中心中有一席之地;而对于主流游戏的支持,也使得它出现在个人PC上成为可能。总之,这是国产GPU发展的一个重要里程碑,虽然比NVIDIA的旗舰GPU还有一些性能差距,但是国产GPU首次发布出来,并且在商业市场上有一定的竞争力。

图2:摩尔线程发布会现场
二.GPU架构的简单介绍
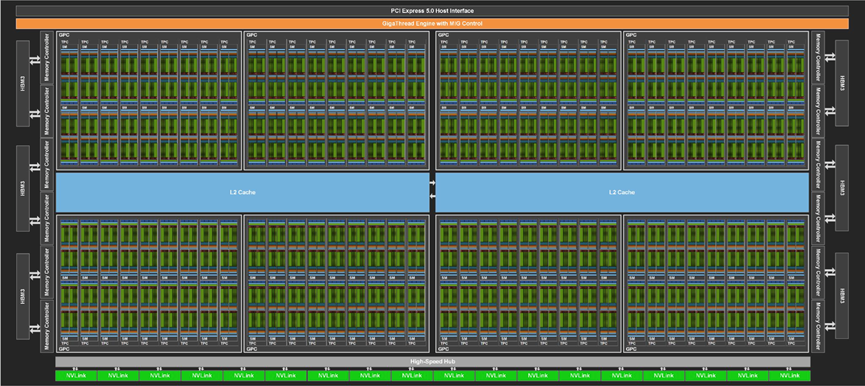
图3:H100的架构示意图
图3是H100的架构图,可以看出,GPU的架构已经非常复杂,包含了非常多的并行单元和访存控制单元。为了方便介绍,我们还是采用更加抽象和简单的架构图来进行介绍,如图4所示。
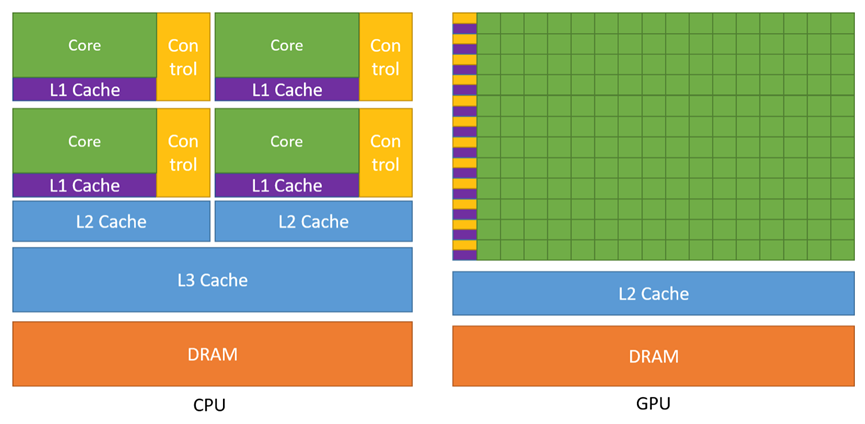
图4:GPU和CPU的架构比较
从图4中可以看出,GPU与CPU相比,有非常多的计算单元,但是每个计算单元的逻辑控制器和本地cache都比CPU少。通常这会导致一个结论:CPU适合处理逻辑复杂的任务,GPU适合处理简单但是并行度高的任务。关于这个结论,我们在后文会给出更进一步的解释。同时GPU的内存带宽也比CPU高的多,一般CPU的内存带宽在100GB/s左右,而GPU的内存带宽可以达到CPU的5~8倍。可见GPU相较于CPU,有巨大的硬件优势,但是GPU的硬件架构有自己的特性,要充分发挥出性能优势的条件也更严苛。
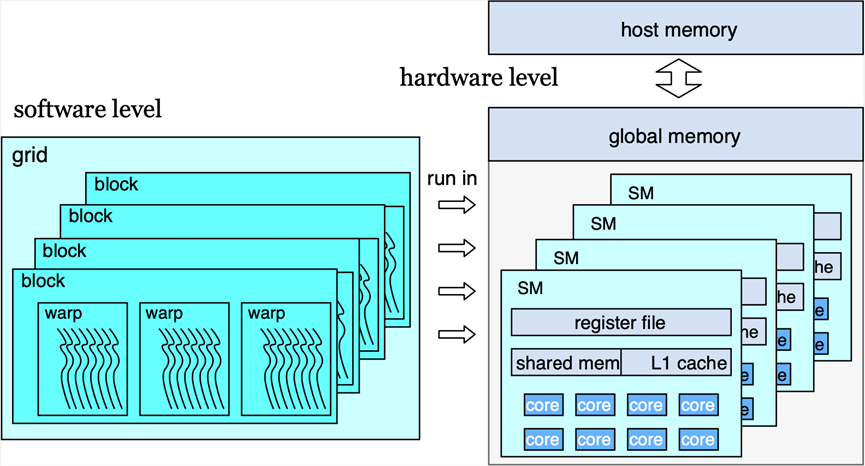
图5:硬件层面和软件层面的GPU架构
接下来我们从硬件架构和软件层面对GPU进行介绍,如图5所示。硬件上,一个GPU有多个stream multiprocessor(SM),每个SM上有许多核,并且拥有自己的cache。所有的SM都可以访问全局内存(global memory),global memory通过PCIe总线和CPU相连。通过PCIe方式进行的CPU和GPU的通信带宽并不高,只有十几GB/s的速度,但是通过NVLink相连的方式,能够实现接近十倍的数据传输带宽。软件层面,程序员每次启动的GPU上的核函数称为一个grid,其中有许多的block,block可以被分派到SM上运行。每个block中又有许多warp。Warp是GPU上线程并行和访存的基本单位,其中的线程是按照单指令多线程(Single instruction multiple threads)的形式运行的,也就是说,warp内部线程的中的分支或者循环结构会导致并行度下降。同时warp也是基本的访存单元,warp里的线程的访存任务都是通过warp统一完成的。
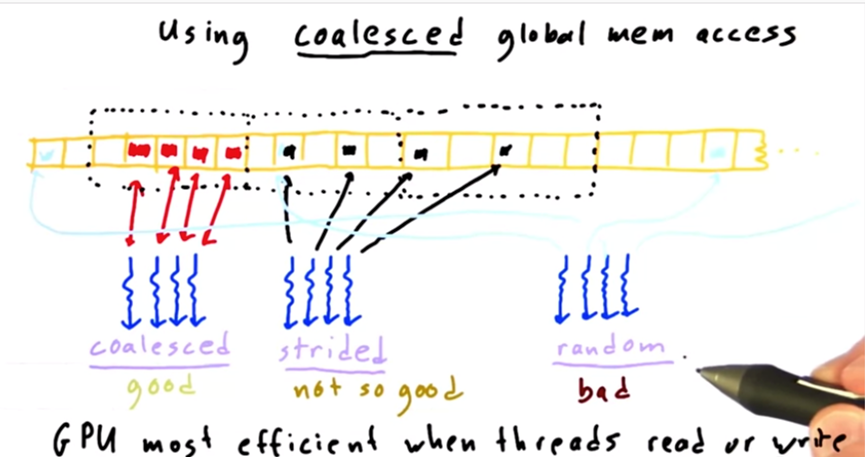
图6:warp中线程访存的几种方式
Warp每次取回一个cacheline大小的数据(通常是128Byte)。考虑图6中的访存方式,当一个warp中的四个线程访问的都是连续并且相邻的地址时,所有的访存请求都可以在一次内存访问操作中满足,称为coalesced memory access;如果线程访问的地址空间是相邻并且不连续的,就需要更多的访存操作才能将所有需要的数据取回来,也就是图中的strided memory access;最后如果所有的线程随机访问,那么需要很多次的访存操作才能满足所有的请求,并且取回来的数据中有效的数据非常少。
Warp的并行和访存特性,决定了GPU更加适合处理规则的,简单的任务,也是“GPU不适合处理复杂逻辑”的原因。因而我们在算法设计的时候,必须注意到这一点,充分考warp的特性,尽量避免线程发散,尽量让线程进行合并访存,这是GPU上进行程序设计的基本原则。
三.两个GPU上的工作
接下来我们将通过levelDB和RocksDB上的两个例子,介绍GPU在基于LSM-tree的数据库上可以做什么。
(一)LUDA--利用GPU加速LSM-tree的compaction操作[1]
1. 动机
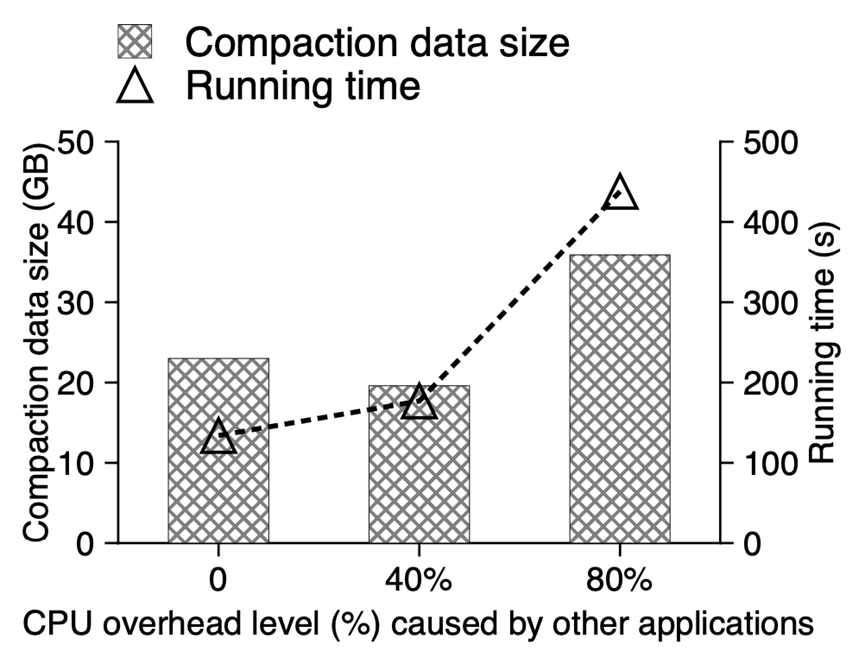
图7:rocksDB在不同CPU overhead下的性能
Compaction是RockDB中非常重要的操作,可以减少读放大;数据库系统本身对于CPU有很高的占用率,而compaction操作也是计算密集型操作,导致对于计算资源的竞争十分激烈。例如在图7中,当数据库本身对于CPU的占用比较高的时候,稍微增加一点compaction的工作负载就会导致非常所需要的时间急剧增加。我们需要一个有效的方式,减少计算资源的竞争。
2. compaction的实现
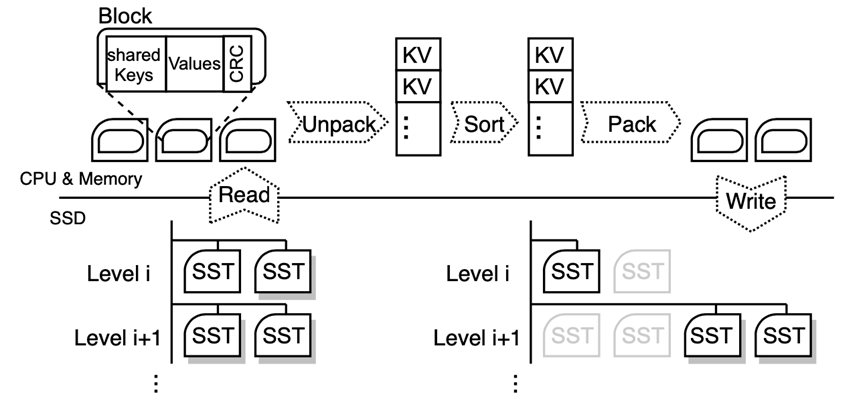
图8: CPU上的compaction操作流程
图8展示了常规compaction操作的流程图。CPU从磁盘上读取出相应的SSTable,经过解码排序编码的方式,将LSM-Tree的不同层合并,然后再写回到磁盘上。
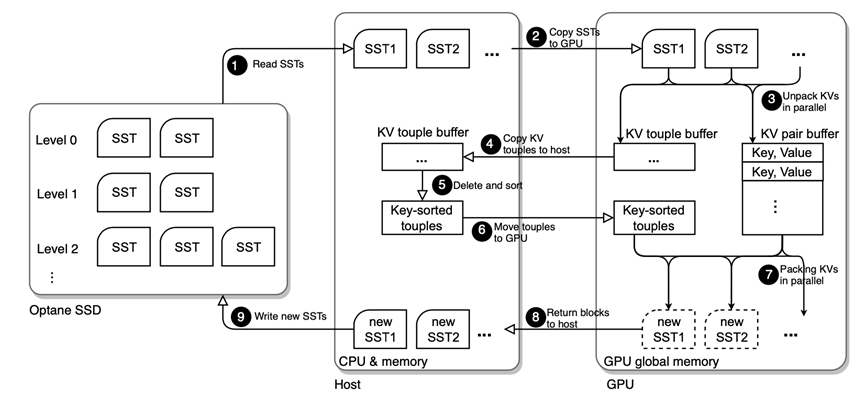
图9:使用GPU加速的compaction流程
在LUDA的设计中,将原本计算操作比较密集的部分-对于SSTable的编码和解码部分的工作交给了GPU,基本流程如上。在LUDA的设计中,GPU对于SSTable的访问需要经过CPU作为中介进行数据的传输。同时对于SSTable进行排序和多版本信息管理的操作放在了CPU上,这是因为多个SSTable之间可能存在范围交叠,这部分任务如果放在GPU上处理会导致CPU和GPU之间大量的数据传输,可能带来非常严重的性能下降。
GPU在进行数据的编码和解码的同时,也会进行其他一些计算密集型的操作,例如构建bloom filter和checksum检查等等,有效地减少了GPU的工作量。
在图9中的步骤二和步骤四中,也就是GPU和CPU之间进行数据传输时,采用的是异步的数据传输,可以有效地提高计算和数据传输的并行性,掩盖数据传输延迟。
3. 实验
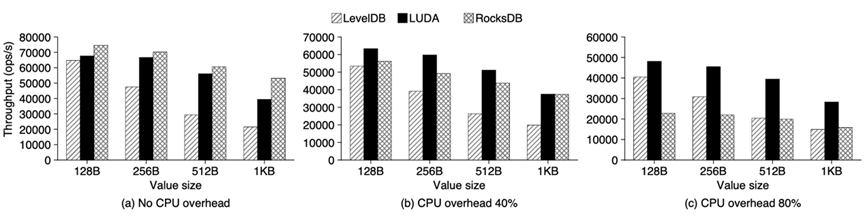
图10:不同CPU负载下的吞吐量
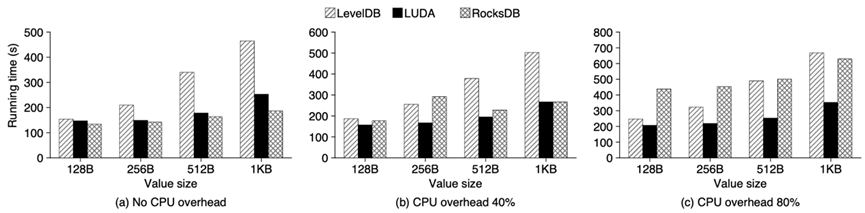
图11:不同CPU负载下的运行时间
最终LUDA实现了比较好的加速效果,相比较于单纯地使用CPU,实现了2倍以上的compaction加速和2倍以上的数据吞吐量。
(二)OurRocks:利用GPU加速LSM-tree的SCAN操作[2]
1. 动机
基于NVMe协议的SSD最高能够实现GB/s的数据传输带宽,但是目前基于CPU的LSM-tree数据库对于SSD的带宽应用非常有限,哪怕考虑上多线程技术,AVX技术,异步IO等等,如图11所示,哪怕是在8-client的环境下,在实际业务场景中SSD的真实带宽也仅仅有十几GB/s或者几十GB/s,仅仅是理论SSD最高带宽的几十分之一。
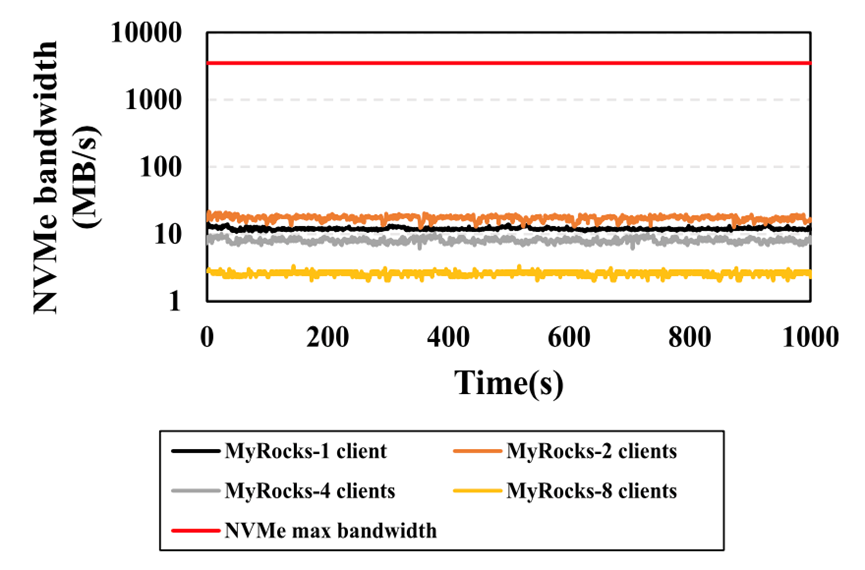
图12:MyRocks处理分析性查询时NVMe的实际带宽
同时,在数据库的扫描操作中,数据从SSD拿入CPU之后,CPU还会消耗大量的时间在计算上,如图13所示,在不同client数目下,系统空间和用户空间的CPU运行占据了绝大多数的时间,花费在系统IO上的时间是很少的。这体现了对于CPU计算任务卸载的需求,和提升SSD实际使用带宽的需求。

图13.Myrocks中处理每个分析性查询时CPU每个核的利用率
同时,利用CPU作为GPU和磁盘之间的数据传输跳板会带来很严重的性能损失,参见LUDA的实现,带来了很多不必要的数据传输开销。
所以MyRocks想利用GPU和SSD之间直接进行数据通信的特性,辅助CPU进行SCAN操作,减少CPU的访存开销和计算代价。
2. 背景知识
LSM-tree中的读操作,由于LSM-tree本身的特性,会带来额外的代价,称为读放大。
NVIDIA GPUDirect RDMA(remote direct memory access)为GPU和其他第三方设备(例如网卡,SSD等)的直接数据传输提供了可能,而不是仅仅通过PCIe总线,这大大减轻了CPU的数据传输负担。
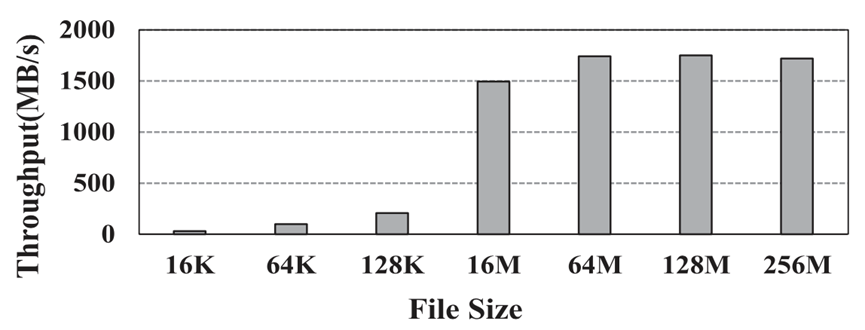
图14: DMA传输的吞吐量
如图14所示,通过对于GPU和SSD之间直接进行数据传输的带宽测试,发现当数据传输的大小达到一定水平时,数据的传输带宽可以稳定在一个水平,这远远高于数据库实际业务场景中的SSD和CPU之间的数据传输带宽。
3. 利用过滤下压使GPU进行预扫描
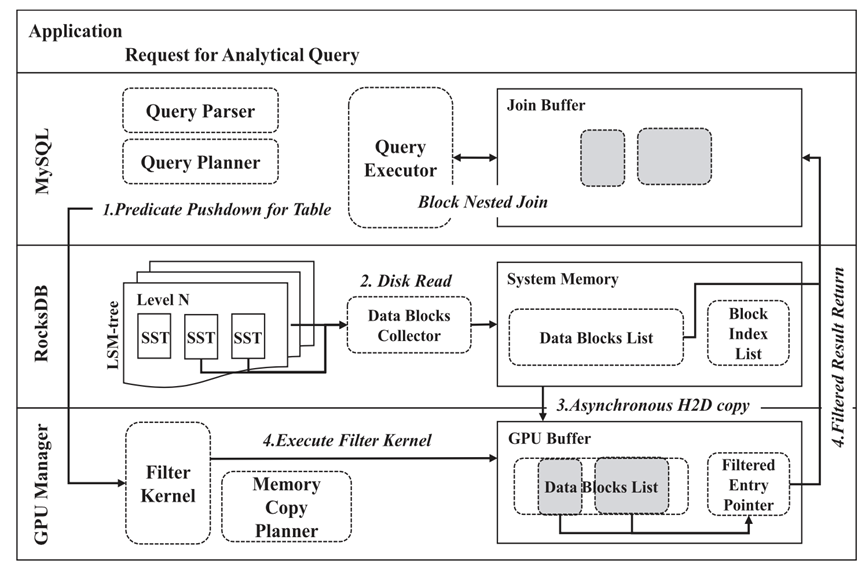
图15:考虑查询下压的架构图
原本的LSM-tree数据库包括SQL执行引擎和数据存储引擎,MyRocks增加了一个GPU manager,利用GPU进行计算任务的部分预计算。具体过程如下:SQL执行引擎首先对查询语句解析,将其中的谓词(过滤条件)传给GPU Manager;随后数据从SSD传输到CPU,再通过异步方式传输GPU;GPU有了谓词和数据,预先进行数据的筛选,将通过筛选后有用的数据块的位置记录下来,传给CPU;这样CPU就可以省去大量的SCAN操作,直接处理GPU传输上来的过滤之后的数据,大大减少了CPU的工作量。
4. 利用DMA(Direct memory access)加快GPU和SSD之间的数据传输
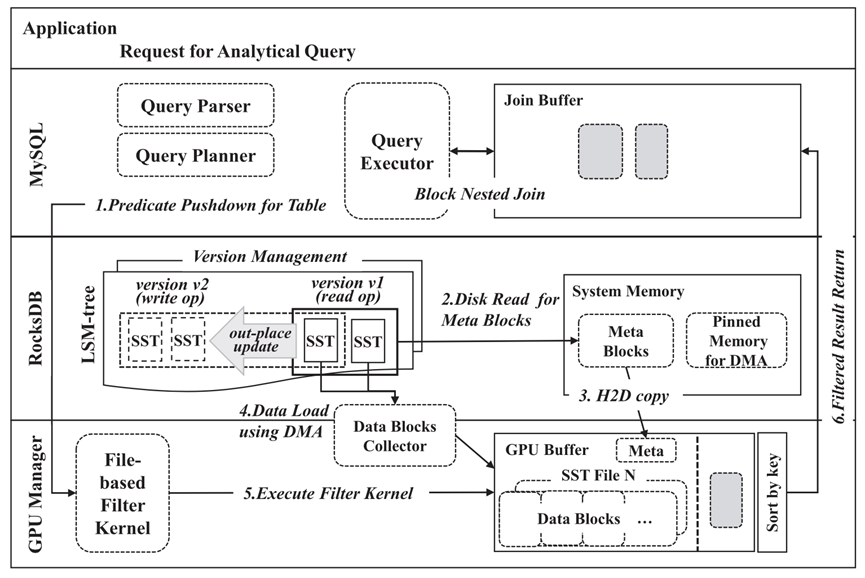
图16:考虑查询下压和GPU DMA的架构图
上一个设计中的问题是GPU仍然通过CPU获取SSD的数据,这样一方面导致不必要的数据传输延迟,另一方面也增加了CPU的负担。于是在考虑了GPU DMA的特性之后,将原来的架构修改如上。原来通过CPU传输到GPU的数据,不再是大块的数据,而是对于数据块进行描述的元数据,记录数据块的位置和大小等信息,这部分数据的大小相比较于原来数据的大小可以忽略不计。然后GPU可以直接与SSD进行数据的通信,对得到的数据进行扫描。
可以看出DMA的使用大大减少了数据传输的代价,也解放了CPU。
5. 实验
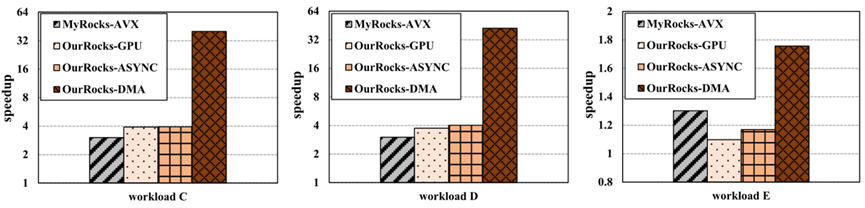
图17: 在YCSB数据集上的实验结果
在TPC-H数据集上执行带有SCAN操作的典型查询,性能比原来提升了6.2倍。
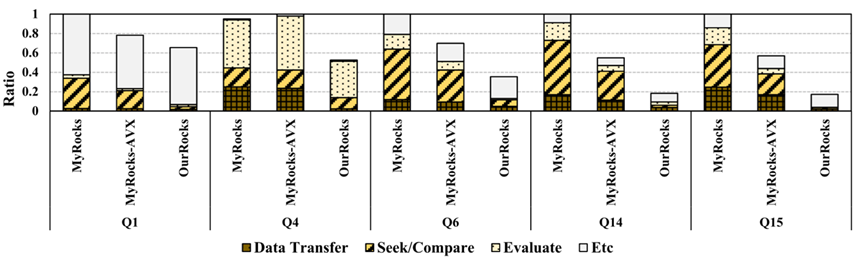
图18: TPC-H的scan操作中各个时间阶段所占据的比例
从整体运行时间中各个阶段所占据的比例来看,使用DMA技术加速的OurRocks也带来了很明显的性能提升,并且CPU的扫描时间和数据传输时间都大大降低。
四.总结与展望
我们介绍了如何利用GPU高带宽和高并行的特点,帮助减少CPU或者内存的压力,从而实现性能提升的例子。原本GPU更加适合计算密集的workload,但是GPU direct RDMA的引入,使得GPU在访存型任务上也获得了很大的发挥空间,很大程度上缓解了CPU的数据传输压力。但是,卸载给GPU的工作做好能够完全跟CPU解耦,否则任务运行过程中依赖CPU实施产生的数据等会导致性能大幅降低。
GPU在各种对性能有需求的场景下的使用是未来的发展趋势。在基于LSM-tree数据库的优化上也有很多潜在的方向。例如利用DMA对于LUDA的改进,encoding过程和decoding过程摆脱对于内存的依赖;在compaction过程的encoding中加一些计算密集型任务,对每个数据块中数据特性进行预计算,方便后续查询时的快速获取;GPU的使用给很多之前被有缺陷的数据库架构设计也带来了一些新的可能,例如Wisckey[3]提出KV分离的设计思路,可以大大减少合并过程中的写放大,但是会带来范围查询性能下降,并且GC过程中存在大量点查的问题,但是合并和GC都是不在数据库查询相应路径上的,GPU可以作为专门的合并或者GC单元。
参考文献
[1] LUDA: Boost LSM- Key Value Store Compactions with GPUs, arXiv Peng Xu et.al
[2] OurRocks: Offloading Disk Scan Directly to GPU in Write-Optimized Database System,Won Gi Choi, IEEE TRANSACTIONS ON COMPUTERS, 2021
[3] WiscKey: Separating Keys from Values in SSD-conscious Storage, Lanyue Lu et.al , FAST 2016


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
实验室开源产品图数据库gStore:
gStore官网:http://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore