1.关于volatile:
对于文章中这个函数,
__global__ void reduceUnrollWarps8 (int *g_idata, int *g_odata, unsigned int n)
{
// set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x * 8 + threadIdx.x;
// convert global data pointer to the local pointer of this block
int *idata = g_idata + blockIdx.x * blockDim.x * 8;
// unrolling 8
if (idx + 7 * blockDim.x < n)
{
int a1 = g_idata[idx];
int a2 = g_idata[idx + blockDim.x];
int a3 = g_idata[idx + 2 * blockDim.x];
int a4 = g_idata[idx + 3 * blockDim.x];
int b1 = g_idata[idx + 4 * blockDim.x];
int b2 = g_idata[idx + 5 * blockDim.x];
int b3 = g_idata[idx + 6 * blockDim.x];
int b4 = g_idata[idx + 7 * blockDim.x];
g_idata[idx] = a1 + a2 + a3 + a4 + b1 + b2 + b3 + b4;
}
__syncthreads();
// in-place reduction in global memory
for (int stride = blockDim.x / 2; stride > 32; stride >>= 1)
{
if (tid < stride)
{
idata[tid] += idata[tid + stride];
}
// synchronize within threadblock
__syncthreads();
}
// unrolling warp
if (tid < 32)
{
volatile int *vmem = idata;
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
vmem[tid] += vmem[tid + 8];
vmem[tid] += vmem[tid + 4];
vmem[tid] += vmem[tid + 2];
vmem[tid] += vmem[tid + 1];
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = idata[0];
}在 //unrolling wrap 之前的for循环完成后,只剩下idata[0] 到 idata[63](共64个元素)的数据还没有进行加和。
之前的疑问是 最后的if语句块内为什么会完成这个操作而不出问题:
因为一个线程束内的线程会进行同步,所以if里的语句是,所有线程执行第一条语句,都执行完了,再执行第二条语句。
然后关于volitale ,大家都说是禁止编译器优化,我的理解是:
如果没有volatile,各个线程写寄存器的时候是有同步的,从寄存器写到共享内存是没有同步的。(不过在我这里,去掉volatile结果也是对的。。。)
2.关于延迟隐藏
目前个人理解就是让一个线程尽可能多做事。
3.关于如何获得最大线程束
参考:【精选】CUDA编程:笔记2_线程束_longlongqin的博客-CSDN博客
little法则给出了下面的计算公式"所需线程束 = 延迟 × 吞吐量
带宽:一般指的是理论峰值,最大每个时钟周期能执行多少个指令;
吞吐量:是指实际操作过程中每分钟处理多少个指令。
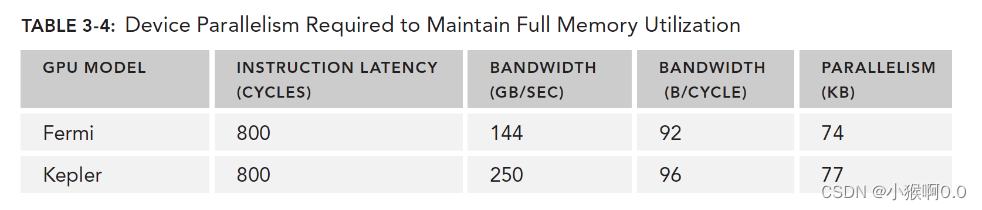
每次想到还是看书吧。
一个WRAP访存周期是T,刚好是Wrap处理指令时间周期t的K倍,只需要K个wrap就能隐藏访存带来的延迟。
得到最大线程束数量还要减少分支
4.选择合适的网格和块:
有个工具包(同学说不能使了,但是应该也提供了别的方法)。
4.什么是事务内存
参考:初识事务内存(Transactional Memory) - 知乎
个人理解:比u锁更好的具有原子性的互斥手段。
5.在GPU上只有内存加载操作可以被缓存,内存存储操作不能被缓存。
内存加载操作:从全局内存或其他内存读数据加载到寄存器或缓存中。
内存存储操作:将数据从寄存器或缓存写入到内存
线程加载数据时,如果缓存中有数据,可以直接从缓存中加载。而存储操作通常不能被缓存,因为要保证数据的一致性,必须及时更新内存中的数据,而不能依赖于缓存。
6.对于固定内存和零拷贝内存
当传输大数据时,使用固定内存:cudaError_t cudaMallocHost(void **devPtr, size_t count);
cudaError_t cudaFreeHost(void *ptr);
如果想要共享主机和设备端的少量数据,使用零拷贝内存:
cudaErroer_t cudaHostAlloc(void **pHost, size_t count, unsigned int flags);
cudaFreeHost()
使用下列函数获取映射到固定内存的设备指针:
cudaError_t cudaHostGetDevicePointer(void **pDevice, void *pHost, unsigned int flags);
// part 2: using zerocopy memory for array A and B
// allocate zerocpy memory
CHECK(cudaHostAlloc((void **)&h_A, nBytes, cudaHostAllocMapped));
CHECK(cudaHostAlloc((void **)&h_B, nBytes, cudaHostAllocMapped));
// initialize data at host side
initialData(h_A, nElem);
initialData(h_B, nElem);
memset(hostRef, 0, nBytes);
memset(gpuRef, 0, nBytes);
// pass the pointer to device
CHECK(cudaHostGetDevicePointer((void **)&d_A, (void *)h_A, 0));
CHECK(cudaHostGetDevicePointer((void **)&d_B, (void *)h_B, 0));
// add at host side for result checks
sumArraysOnHost(h_A, h_B, hostRef, nElem);
// execute kernel with zero copy memory
sumArraysZeroCopy<<<grid, block>>>(d_A, d_B, d_C, nElem);
// copy kernel result back to host side
CHECK(cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost));
// check device results
checkResult(hostRef, gpuRef, nElem);
// free memory
CHECK(cudaFree(d_C));
CHECK(cudaFreeHost(h_A));
CHECK(cudaFreeHost(h_B));有了虚拟内存寻址(UVA)后,由cudaHostAlloc()分配的固定主机内存具有相同的主机和设备指针,可以将返回的指针直接传递给核函数:
cudaHostAlloc((void **)&h_A, nBytes, cudaHostAllocMapped);
cudaHostAlloc((void **)&h_B, nBytes, cudaHostAllocMapped);
initialData(h_A, nElem);
initialData(h_B, nElem);
sumArrayZeroCopy<<<grid, block>>>(h_A, h_B, d_C, nElem);