引言
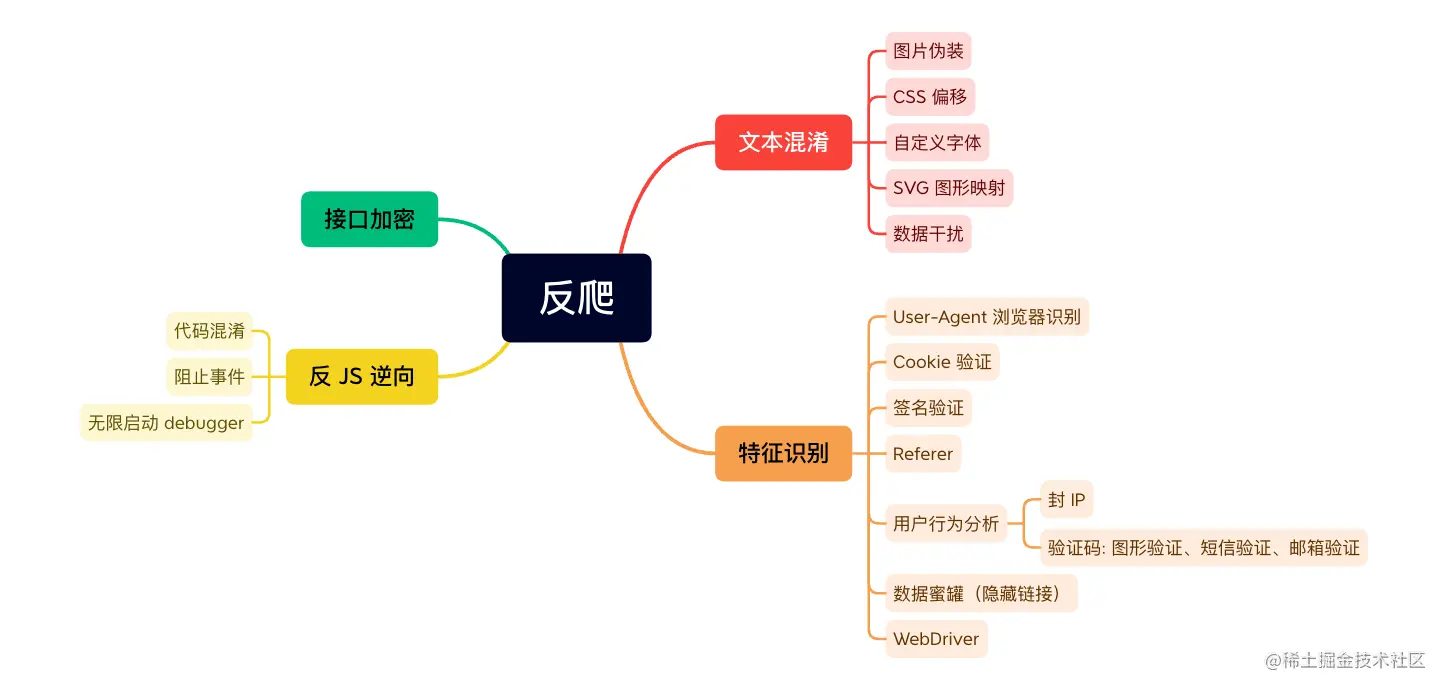
随着互联网的飞速发展, 爬虫技术不断演进, 为数据获取和信息处理提供了强大支持。然而, 滥用爬虫和恶意爬取数据的行为日益增多, 引发了反爬虫技术的兴起。在这场看似永无止境的 技术较量 中, 爬虫与反爬虫技术相互博弈、角力。本文将简单过下目前已知的几种反爬策略, 旨在扩展知识! 万一日后能够用上呢!!
一、图⽚伪装
1.1 原理
将价格、数量、手机号等一系列敏感信息, 通过图片的方式进行伪装, 然后图片和文字再混合一起进行展示, 这种方式既不影响用户的正常阅读, 又可以限制爬虫程序直接获取到这些敏感内容
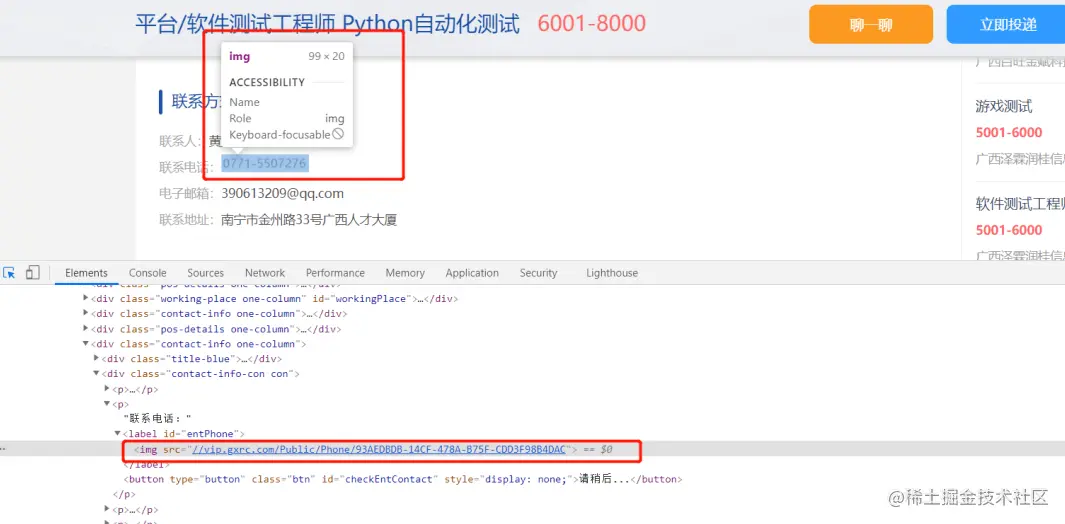
1.2 破解方式
该反爬手段是直接用图片替换了原来的内容, 所以爬虫程序是无法直接获取内容的, 唯一的破解手段就是将图片下载下来, 然后使用 OCR(文字识别) 技术对图片内容进行一个识别
二、CSS 偏移
2.1 原理
在 HTML 中将要展示的内容打乱, 然后利用 CSS 将乱序的文字排版成人类能够正常阅读