R语言中 fread 怎么用?
今天分享的笔记内容是数据读取神器fread,速度嘎嘎快。在R语言中,fread函数是data.table包中的一个功能强大的数据读取函数,可以用于快速读取大型数据文件,它比基本的read.table和read.csv函数更快,尤其在处理大型数据集时效果更为明显。
使用方法
首先,确保已经安装了data.table包。如果尚未安装,可以使用以下命令安装:
install.packages("data.table")
然后,加载data.table包:
library(data.table)
接下来,使用fread函数来读取数据文件。假设你有一个名为data.csv的CSV文件,可以使用如下命令:
data <- fread("data.csv")
如果你的数据文件采用了其他的分隔符,比如制表符或空格,你可以使用sep参数指定分隔符。
例如,对于制表符分隔的文件,可以使用如下命令:
data <- fread("data.tsv", sep = "\t")
以上就是最常用的使用方法,特别适合大文件读取,亲测100MB的文件读取时一秒左右就完成了,可以用来替换原来的read.table和read.csv函数。
使用技巧
fread函数的作用是将不同类型的输入数据高效地读取到R数据表中,它具有多个选项和配置,使用户能够无缝处理各种文件格式和数据结构。
接下来看一下fread函数的一些关键参数及其在数据处理中的作用。
fread函数的关键参数
input:该参数接受单个字符字符串,确定输入数据的来源。它可以是文件、文本数据或shell命令。
file:用户可以指定要读取的文件的名称或路径。该函数支持各种文件格式,包括具有.gz和.bz2等扩展名的压缩文件。
text:如果数据以字符向量的形式存在,用户可以直接将文本数据输入函数进行处理。
cmd:该参数允许用户在读取数据之前使用shell命令对文件进行预处理。
sep:列之间的分隔符,默认设置为"auto"。用户可以明确指定分隔符,也可以让函数根据数据自动确定适当的分隔符。
sep2:类似于sep,该参数表示列之间的次要分隔符,这个参数一般不怎么用。
dec:文件中表示小数点的字符。
nrows:要从输入中读取的行数。
header:逻辑值或整数,指定文件是否包含标题以及其位置。
na.strings:一个字符字符串,表示数据中缺失值的表示方式。
stringsAsFactors:一个逻辑值,指示是否应将字符列转换为因子。
verbose:一个逻辑值,确定函数在读取过程中是否应显示详细输出。
高级配置
fread函数提供高级配置,如数据类型规范(colClasses)、列选择(select)和编码设置(encoding)。它还支持多线程读取(nThread),以提高多核系统的性能。
为了确保准确的数据处理,使用函数时应注意数据格式、编码和分隔符设置。
在实际使用中,应根据数据文件的特点选择合适的参数配置。对于大型数据集,应注意文件格式、编码方式和数据分隔符的设置,以确保准确读取和处理数据。
使用nrows参数可以控制读取的行数,避免读取整个大文件造成资源浪费。 同时,注意使用header参数来指定文件是否包含标题行,以便正确解析数据的列名。
为什么fread速度更快?
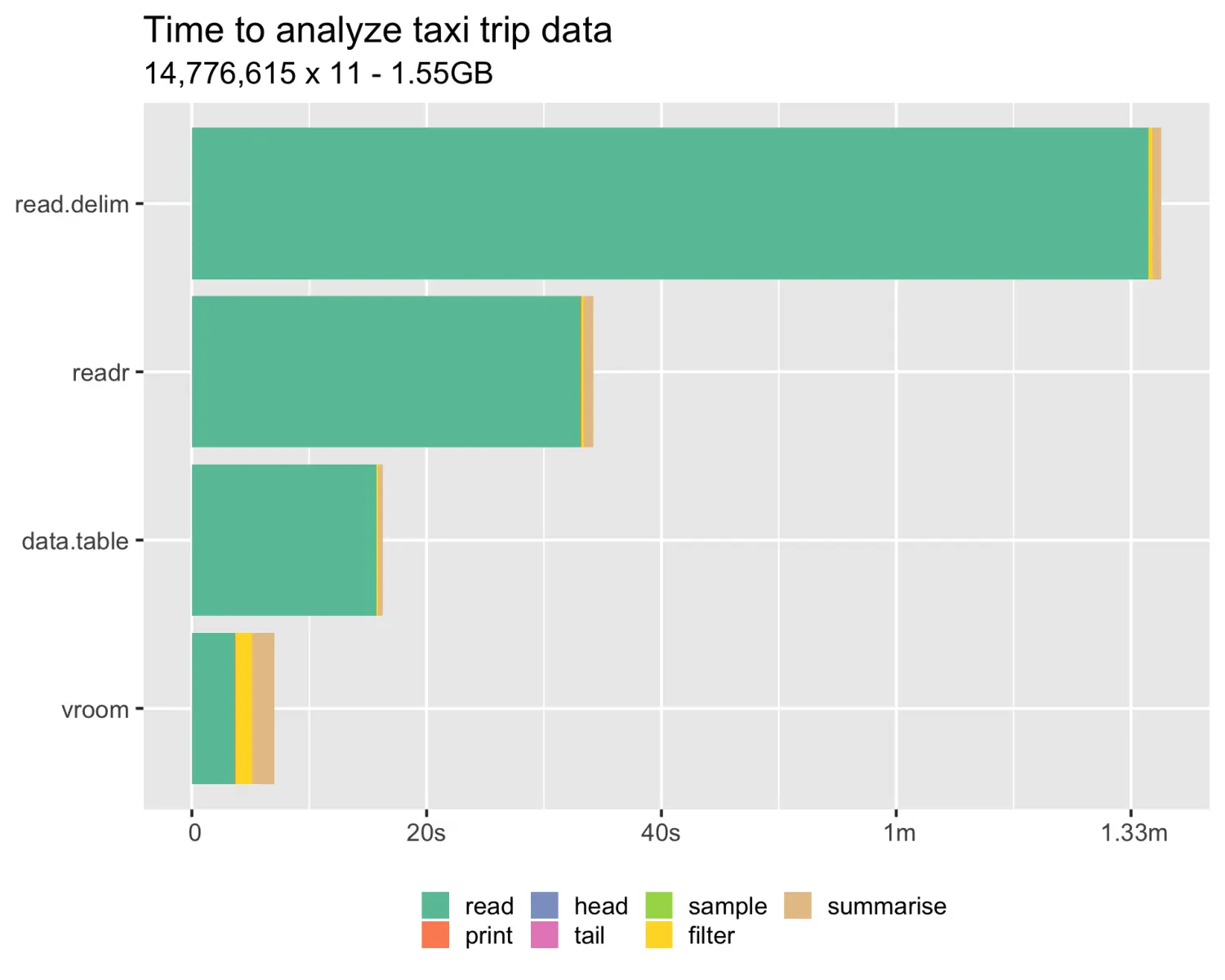
彩蛋:其实还有vroom这个包,读写速度也挺快的,非常适合机器学习等大数据样品集读取,功能很强大!
# read.table()
start = Sys.time()
Tx = read.table(fileIn, sep = "\t", header = FALSE, stringsAsFactors = FALSE)
end = Sys.time()
> end - start
Time difference of 29.71594 secs
# fread()
start = Sys.time()
> Tx = fread(fileIn, sep = "\t", header = FALSE, stringsAsFactors = FALSE)
|--------------------------------------------------|
|==================================================|
end = Sys.time()
> end - start
Time difference of 3.99352 secs
希望本文能够帮助您深入了解fread函数的使用,并在实际应用中灵活运用,从而提高数据处理的效率和准确性。
本文由 mdnice 多平台发布