HTTP
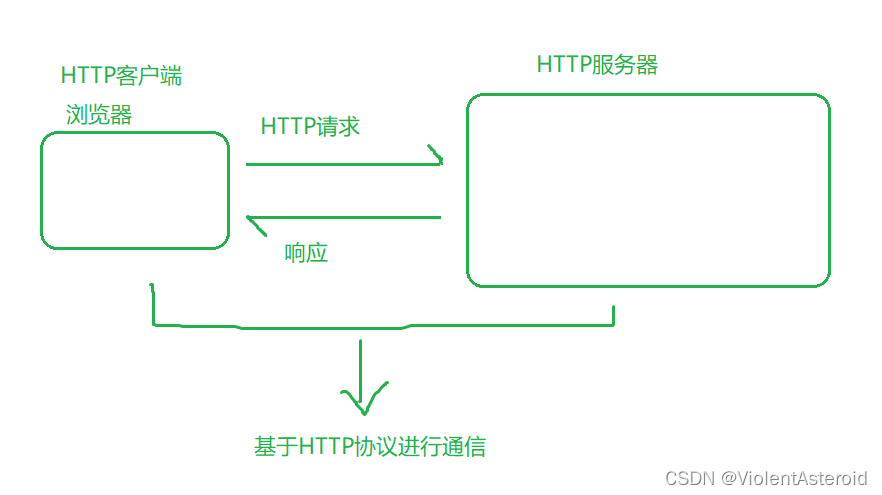
HTTP协议
是应用层使用最广泛的协议之一,从浏览器获取到网页,就是基于http
-
浏览器和服务器之间的交互桥梁
-
基于传输层的TCP协议来实现的,是一种无状态的应用层协议
-
为啥是无状态的呢
- 简化服务器端的处理逻辑:HTTP是无状态的,服务器不必保存客户端请求的状态,这样可以减少服务器存储空间的占用和处理复杂度,更容易扩展和管理系统
- 支持多个请求同时进行:HTTP请求和响应式独立的,浏览器可以同时发送多个请求,提高网络通信的效率
-
-
HTTP请求
-
首行
-
方法 + URL + 版本号

-
认识URL
-
URL的组成

-
最重要的四个部分
-
域名/IP
-
端口号
- HTTP默认端口号80
- HTTPS默认端口号443
-
带层次的路径
-
查询字符串(以键值对的方式来组织的)
-
-
举个例子
-
-
方法
-

-
GET请求
-
使用场景
- 在浏览器地址直接输入url
- 点击收藏夹
- html里的link、script、img、a…
- 通过js来构造get(form标签)
-
举个例子
-
-
POST请求
-
使用场景
- 典型的就是登录操作,登录跳转的时候会设计POST
- 传文件
-
-
GET 和 POST 的区别
-
GET和POST本质没有区别,大部分场景下能够互相替代,但是在适用情况下是有差异的
-
传参方式不同
- GET是习惯使用query string
- POST是习惯使用body正文传参
-
语义差别(使用场景上的不同)
- GET一般用于从服务器获取数据
- POST一般用于给服务器提交数据
-
幂等
- GET请求一般是获取数据,设置为幂等的,每次请求的数据是一样的
- POST提交数据,每次提交的数据不同,所以是不幂等的
-
缓存方面
- GET可以缓存
- POST一般不能缓存
-
长度限制
- GET请求一般有长度限制
- POST请求一般没有长度限制
-
-
-
-
-
-
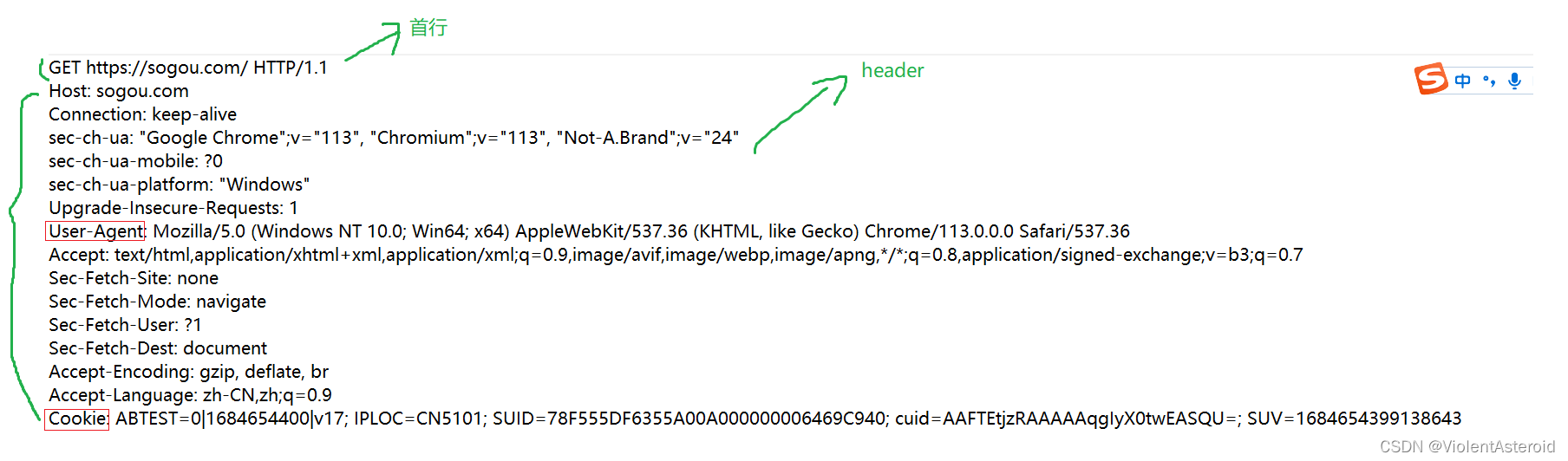
请求头(header)
-
构成

-
Host
- 描述了服务器所在的端口,用来描述最终访问的目标。这个内容大概率和URL中是一样的,也有一定情况是不同的
-
Content-Length
- GET请求中没有这两个字段,POST中一定有
- body的数据长度
-
Content-Type
- body的数据格式
-
User-Agent(UA)
- 描述了浏览器和操作系统的版本
- 主要分为PC和移动端
-
Referer
- 当前页面的来源
- 如果直接通过地址栏输入地址、直接点击收藏夹,就没有referer
- 用于

-
Cookie
-
本质上是浏览器给网址提供的 本地存储数据的机制
- 网页是默认不允许访问计算机的硬盘的(为了保证安全,浏览器对于访问硬盘作出了明确的限制),但是我们有这个需求,所以就引入了cookie
- 通过键值对的方式组织数据
-
cookie从哪来
- 从服务器来,服务器来决定,浏览器的cookie要存什么
- 浏览器通过HTTP响应报头部分(set-cookie字段)来知道自己要理解和存储的,下一次请求时就带上这个cookie
-
cookie在哪存
- 可以认为存于浏览器,也可以认为存在硬盘中
- cookie在存的时候,是按照浏览器+域名细分的
- cookie的内容不仅有键值对,还有过期时间,越敏感的网站,过期时间越短
-
cookie要到哪去
- 回到服务器里去
- 客户端会通过cookie保存当前用户使用的中间状态,当客户端访问服务器的时候,就自动把cookie内容带入请求中,服务器就知道客户端什么样子
- cookie就像是服务器在客户端的寄存处一样,用于服务器记录客户端的状态
-
cookie的工作原理
-
-
session
-
Session是什么
- 除了将用户信息通过cookie存储在用户浏览器中,也可以利用session存储在服务器端,存储在服务器端的信息更加安全。 session可以存储在服务器上的文件、数据库或者内存中。可以将session存储在Redis这种内存型数据库中,效率会更高
-
Session工作原理
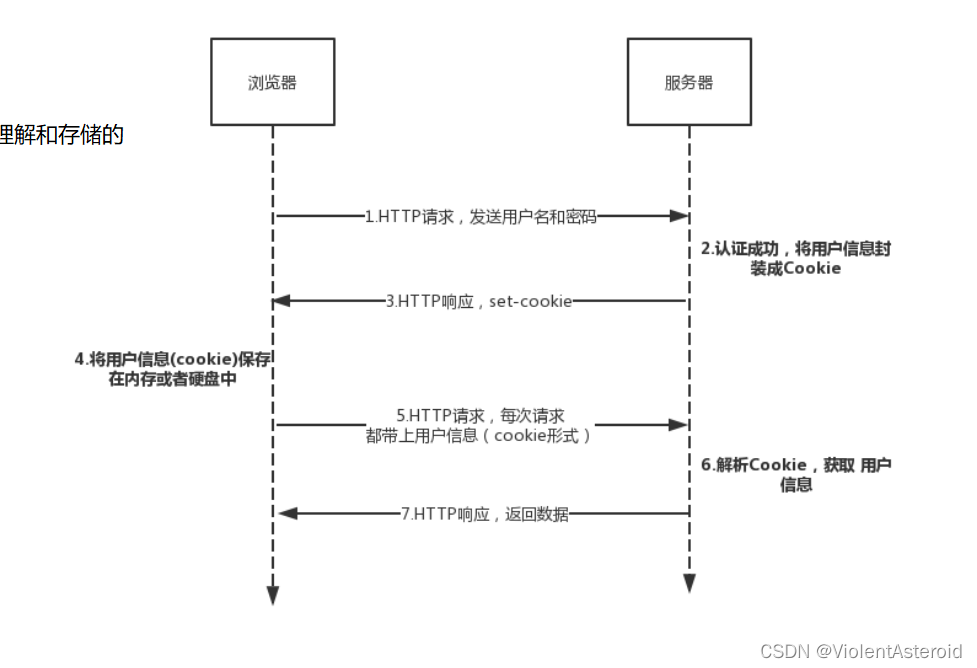
- 客户端登录完成之后,服务器会创建对应的 session,session 创建完之后,会把 session 的 id 发送给客户端,客户端再存储到浏览器中。这样客户端每次访问服务器时,都会带着 sessionid,服务器拿到 sessionid 之后,在内存找到与之对应的 session 这样就可以正常工作了
-
使用session维护用户登录状态过程
-
用户进行登录时,提交包含用户名和密码的表单,放入HTTP请求报文中
-
服务器验证该用户名和密码,如果正确则把用户信息存储在Redis中,它在Redis中的key称为SessionID
- SessionID的安全性问题,不能让它被恶意攻击者轻易获取,那么就不能产生一个容易被猜到的SessionID值。此外,还需要经常重新生成SessionID。在安全性要求高的场景,eg转账,除了使用Session管理用户状态,还要对用户进行重复验证,eg重新输入密码、短信验证码等方式
-
服务器返回的响应报文的Set-Cookie首部字段包含了SessionID,客户端收到响应报文之后将该Cookie值存入浏览器中
-
客户端之后对同一个服务器进行请求时会包含该Cookie值,服务器收到之后提取出Session ID,从Redis中取出用户信息,继续之前的业务操作
-
-
如果客户端禁用了cookie,那么session还能用吗
- 可以,Session的作用是在服务端来保持状态,通过sessionid来进行确认身份,但sessionid一般是通过Cookie来进行传递的。如果Cooike被禁用了,可以通过在URL中传递sessionid
-
-
cookie和session的区别
-
为啥要有cookie和session
-
HTTP是无状态的,请求和响应都是独立的,一次会话中的多次请求时无感知的,如何解决这个问题呢?这就需要借助会话持久技术,常见的就是cookie和session
- eg,用户进行登录操作的时候,切换到其他页面,服务器无法判断是哪个用户登录的,每次进行页面跳转的时候,都需要重新登录
-
-
存储位置不同
- cookie存储在客户端
- session存放在服务端,session存储的数据比较安全
-
存储的数据类型不同
- 两者都是key-value的结构,cookie的value只能是字符串类型
- session可以存储任意数据
-
存储的数据大小限制不同
- cookie大小受浏览器限制,很多是4k的大小
- session理论上受当前内存的限制
-
生命周期的控制
- cookie的有效期可以设置较长时间
- session的有效期比较短
-
-
-
-
空行
- 表示header的结束标记
-
正文(body)
-
如果是GET请求,一般没有body
-
如果是POST请求,一般有body
-
body的数据格式
-
根据请求头中的Content-Type字段来知道以何种方式解码
-
application/x-www-form-urlencoded
- 原生form表单,不设置Content-Type属性的话,就默认以这种方式进行传输
-
multipart/form-data
- 使用表单上传文件的时候,必须让表单的Content-Type 等于 multipart/form-data
- 支持传输多种文件格式
-
application/json
- 用得比较多,json字符串,支持格式化数据
-
text/xml
- 一般用来传输xml格式的文件,这种数据格式
-
-

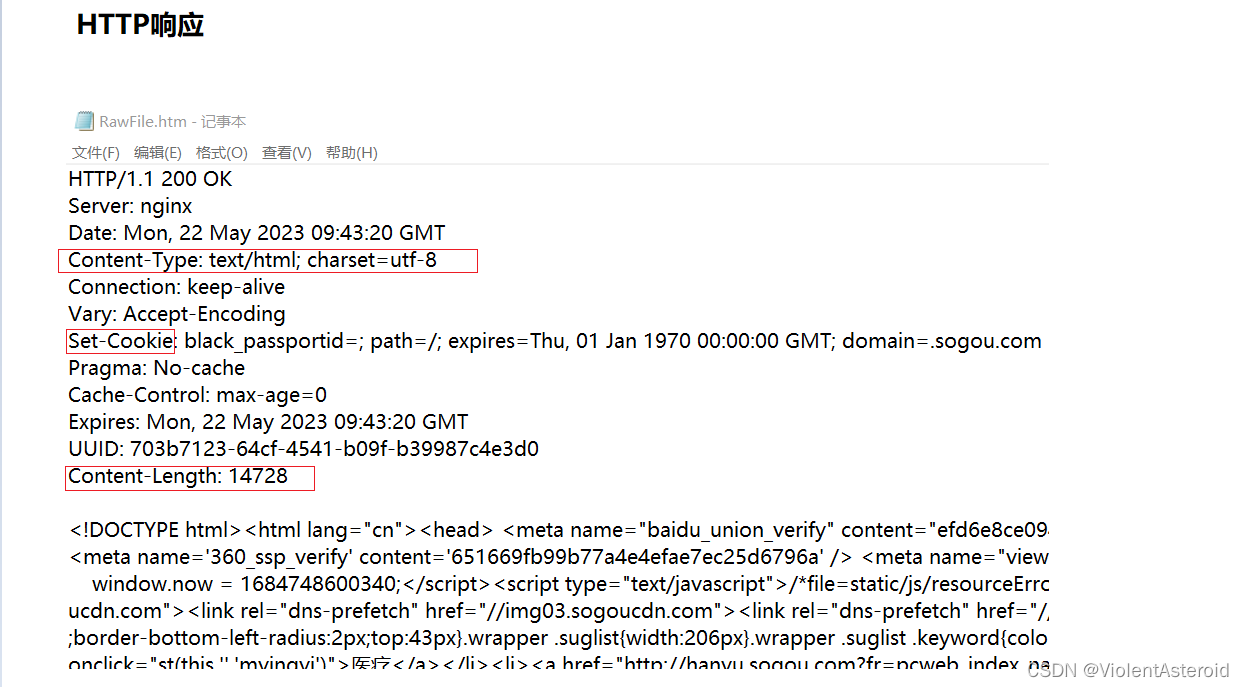
HTTP响应
-
例如
-
首行
-
版本号+状态码+描述码

-
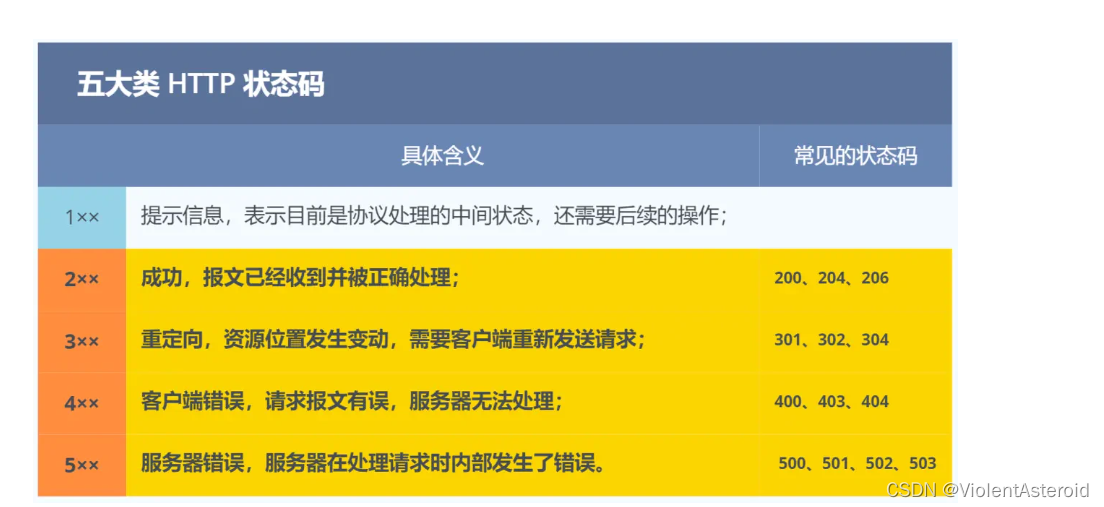
HTTP的状态码
-
200 OK
- 成功
-
404 NotFound
- 访问资源不存在,在服务器中没找到
-
403 Forbidden
- 拒绝访问,没有权限
-
302 Found
- 3xx都是表示重定向
- 重定向,类似呼叫转移
- 这样的响应报文会在header里带个location属性,通过这个属性描述要跳转到哪个新地址
-
500 Internal Server Error
- 服务器内部错误(服务器代码抛异常了)
-
504 Gateway timeout
- 请求超时(响应时间太久,浏览器等不及了)
-

-
-
-
-
header响应头
-
空行
- 表示header的结束标志
-
body
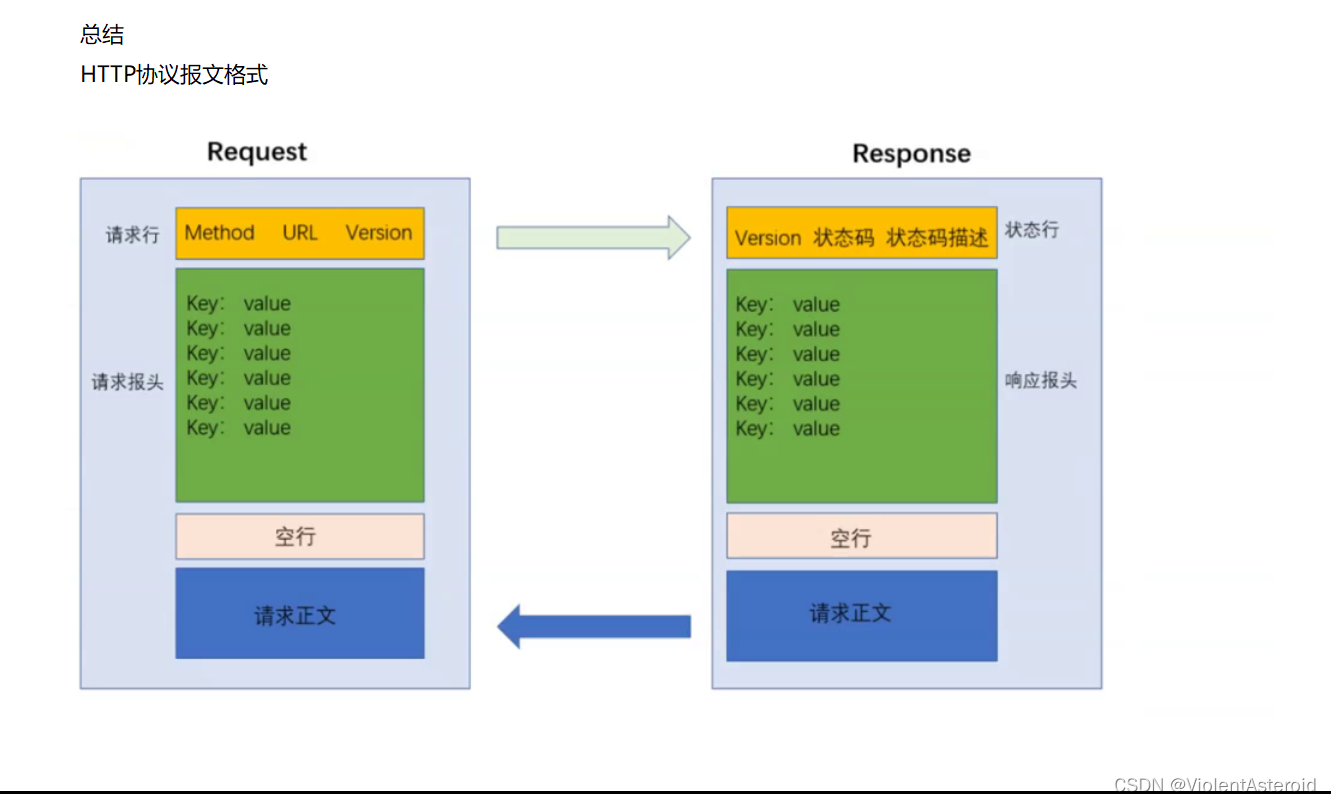
HTTP报文格式
如何构造HTTP请求
对于GET
-
地址栏直接输入
-
点击收藏夹
-
html中的link script img a标签
-
form标签
-
只能构造GET、POST,无法构造PUT、DELETE、OPTIONS等请求
-
GET请求

-
POST请求
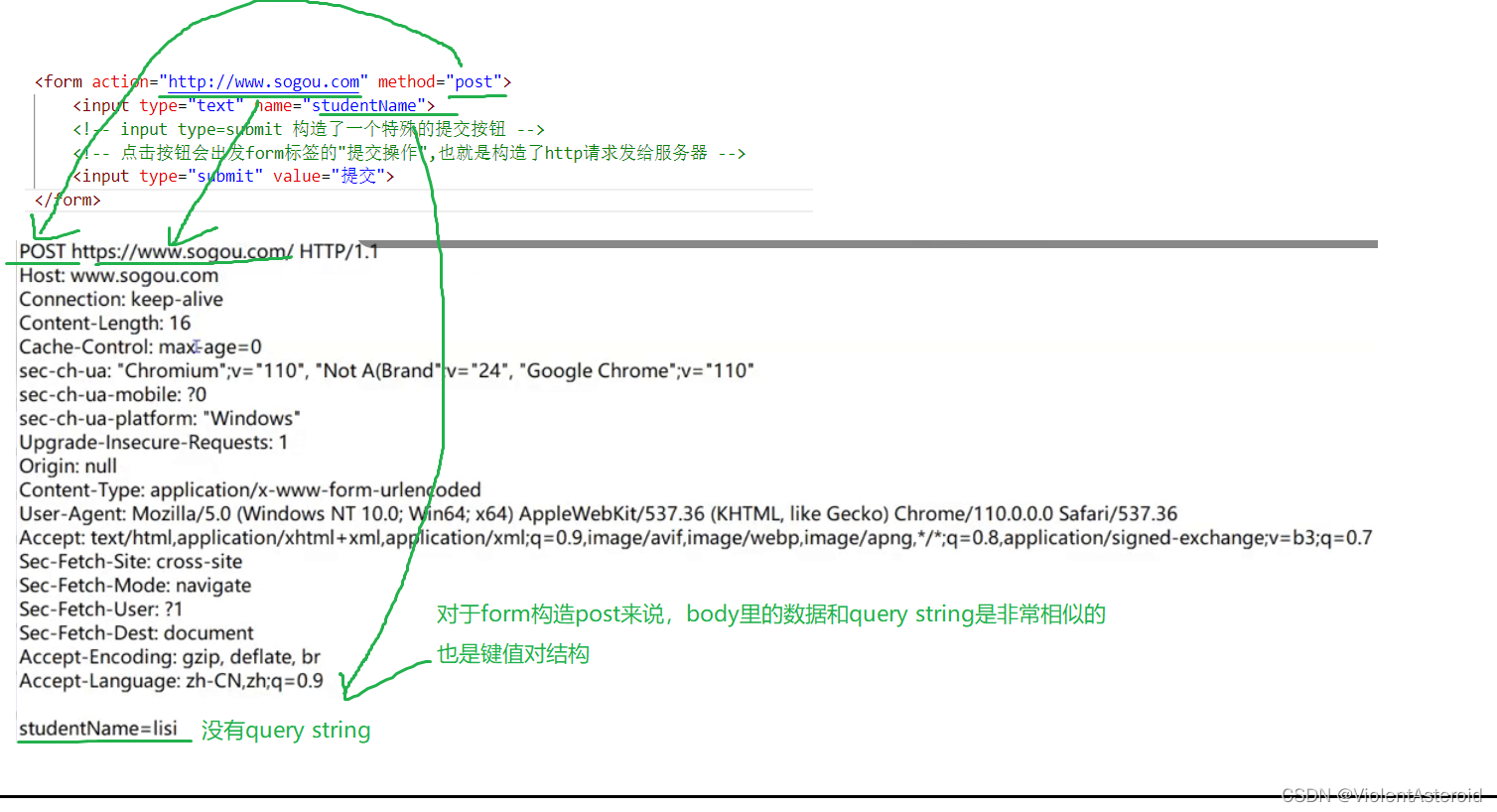
-
-
Ajax构造http请求
-
浏览器提供的一种通过js构造http请求的方式
-
html中,通过Ajax发起http请求后,不必等待服务器响应,就可以继续往下执行,等服务器响应回来,再由浏览器通知到我们的代码中
-
代码中如何使用Ajax
-
js原生提供Ajax的api,但是很难用
-
jQuery提供的api,针对原生api的封装,简单很多
-
是一个特殊的全局对象,
j
Q
u
e
r
y
的
a
p
i
都是以
是一个特殊的全局对象,jQuery的api都是以
是一个特殊的全局对象,jQuery的api都是以的方式引出的,只有一个参数,是一个js对象

-
是一个特殊的全局对象,
j
Q
u
e
r
y
的
a
p
i
都是以
是一个特殊的全局对象,jQuery的api都是以
是一个特殊的全局对象,jQuery的api都是以的方式引出的,只有一个参数,是一个js对象
-
-
跟form比起来,Ajax的优点
- 支持PUT、DELETE方法
- Ajax发送的请求可以灵活设置header
- Ajax发送的请求的body也可以灵活设置
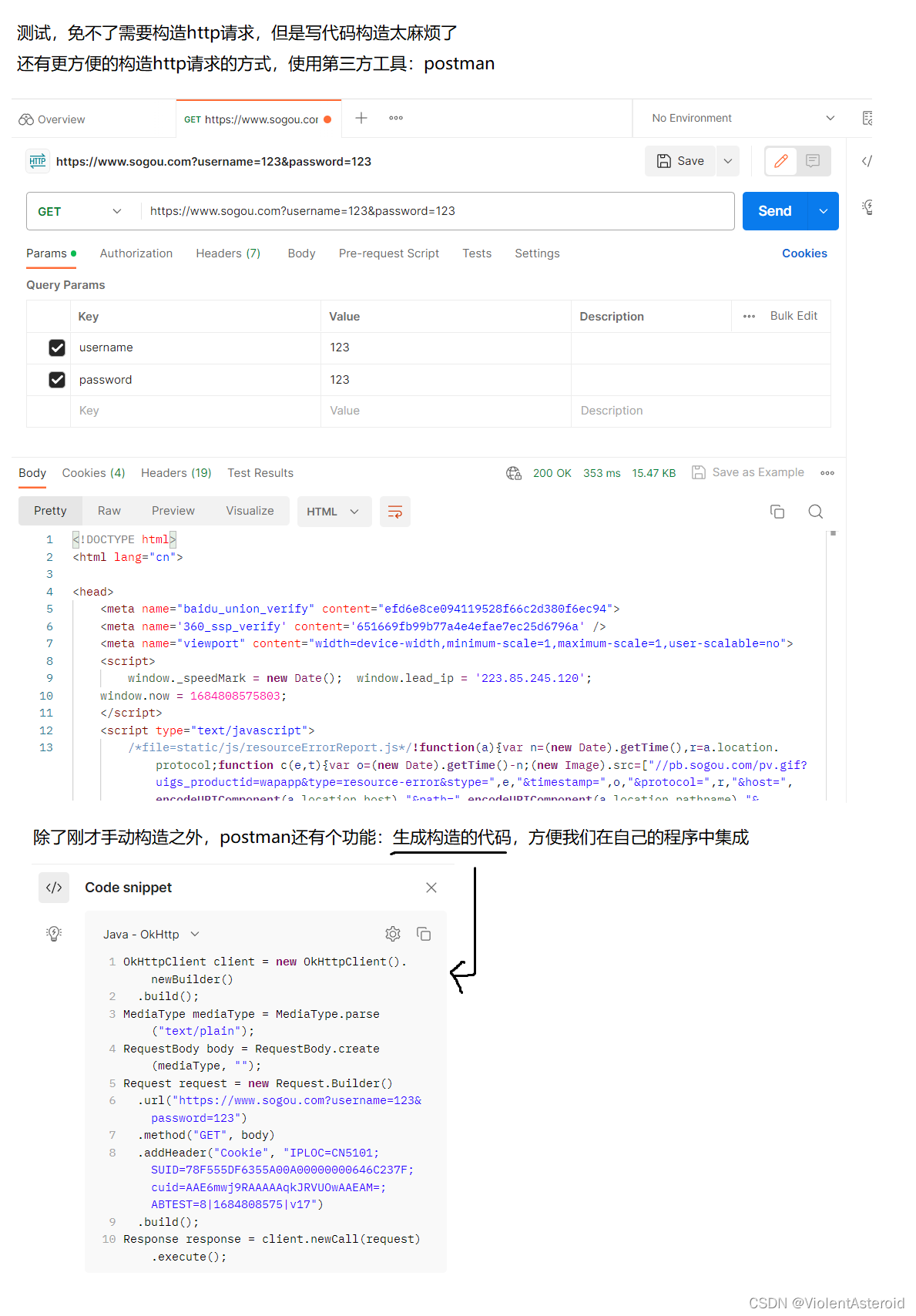
使用postman构造请求
HTTP和HTTPS
区别
-
两者默认端口不同
- HTTP:80
- HTTPS:443
-
URL前缀不同
- HTTP 的 URL 前缀是 http://
- HTTPS 的 URL 前缀是 https://
-
安全性和资源消耗
- HTTP 协议运行在 TCP 之上,所有传输的内容都是明文,客户端和服务器端都无法验证对方的身份。HTTPS 是运行在 SSL/TLS 之上的 HTTP 协议,SSL/TLS 运行在 TCP 之上。所有传输的内容都经过加密,加密采用对称加密,但对称加密的密钥用服务器方的证书进行了非对称加密。
- HTTP 安全性没有 HTTPS 高,但是 HTTPS 比 HTTP 耗费更多服务器资源
HTTPS加密
-
为什么需要加密
- 因为http的内容是明文传输的,明文数据会经过中间代理服务器、路由器、WiFi热点、通信服务运营商等多个物理节点,如果信息再传输过程中被劫持,传输的内容就完全暴露了。劫持者还可以篡改传输的信息不被双方察觉,这就是中间人攻击,所以我们需要对信息进行加密,最常用的就是对称加密
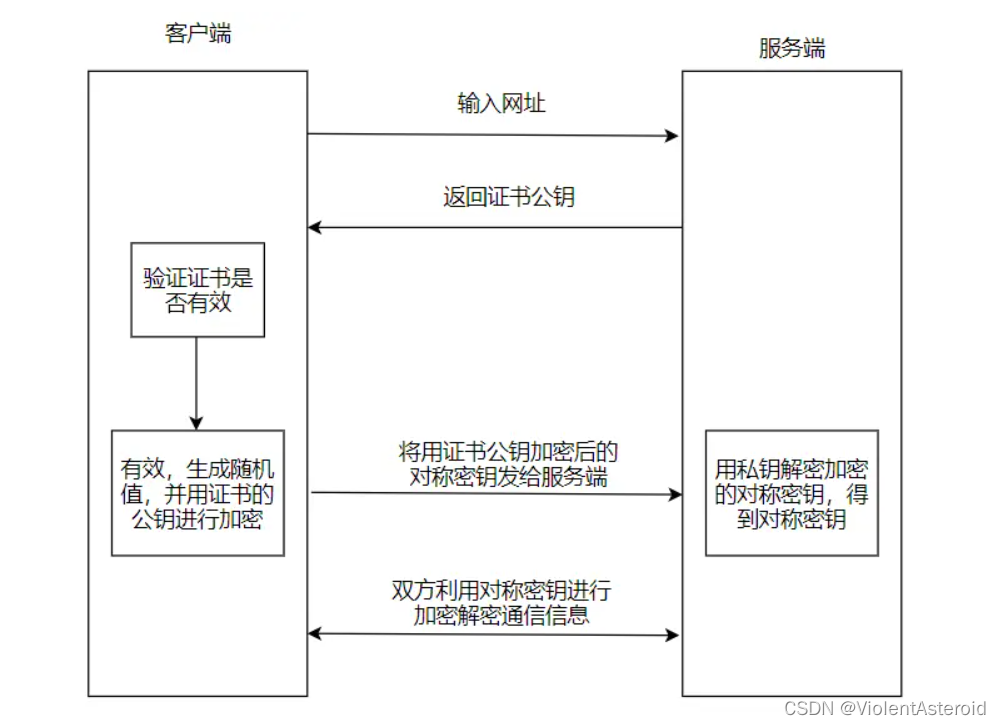
- 加密流程
-
对称加密
- 一个密钥,可以加密一段信息,也可以对加密后的信息进行解密,这就是对称加密
- 但是对称加密怎么才能保证密钥只被传输双方知晓,同时不被别人知道呢?如果传输过程密钥被别人劫持到手,他就可以用密钥解开传输的任何内容了。如果浏览器预存了网站A的密钥,就可以确保不会有人知道密钥了,但是浏览器显然不能预存所有网站的密钥。所以我们就需要非对称加密
-
非对称加密
-
两把密钥:公钥和私钥,用公钥加密的内容只有私钥能解开,同时用私钥加密的内容只有公钥能解开
-
只能保证单方向传输的安全性:服务器先把公钥以明文传输给浏览器,之后浏览器向服务器传数据前先用这个公钥加密好再传,然后服务器私钥解密。但是服务器到浏览器这个明文传输的阶段,公钥被中间人劫持了怎么办?他也能用公钥解密服务器传来的信息了,只能保证浏览器到服务器传输数据的安全性
-
两组密钥
- 服务器拥有公钥A和私钥A,浏览器拥有公钥B和私钥B
- 浏览器把公钥B明文传输给服务器,服务器将公钥A明文传输给浏览器
- 浏览器向服务器传输的内容用公钥A加密,服务器使用私钥A解密。服务器向浏览器传输的内容用公钥B加密,浏览器使用私钥B解密
-
这样做的确可以,但是非对称加密算法非常耗时,对称加密快很多
-
-
非对称加密+对称加密
- 网站服务器拥有非对称加密的公钥A,私钥A
- 浏览器向服务器请求,服务器把公钥A明文传输给浏览器
- 浏览器随机生成一个用于对称加密的密钥X,并且使用公钥A加密传给服务器
- 服务器拿到私钥A解密得到密钥X,这样双方都有密钥X,且别人都无法知道它,之后的数据都通过密钥X加密解密
-
数字证书
-
其实非对称加密+对称加密还是会遭到中间人攻击
- 中间人把公钥A劫持,保存下来,并且将公钥A替换为自己伪造的公钥B
- 浏览器生成一个用于对称加密的密钥X,用公钥B加密后传给服务器
- 中间人劫持到后用私钥B解密得到密钥X,再用公钥A加密后传输给服务器
- 服务器拿到后用私钥A解密得到密钥X
-
数字证书
-
根本原因是浏览器无法确认收到的公钥是不是服务器自己的,如何证明浏览器收到的公钥是网站服务器的呢?CA机构颁发“身份证”:数字证书
-
网站在使用HTTPS前,需要向CA机构申领一份数字证书,其中包含持有者信息、公钥信息等
-
如何防止数字证书被篡改?
-
数字签名
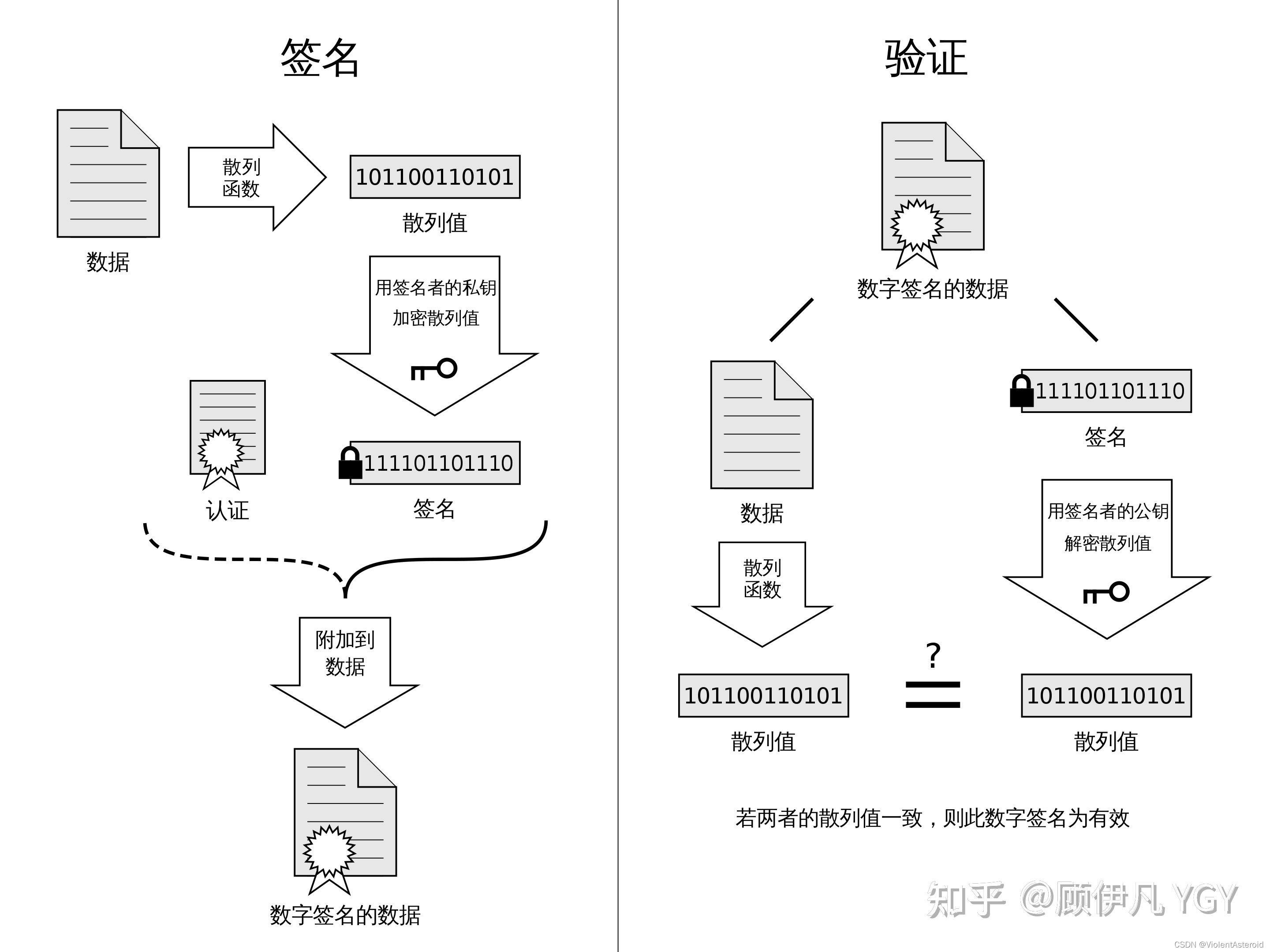
-
制作过程
- CA机构拥有非对称加密的私钥和公钥
- CA机构对证书明文数据T进行hash
- 对hash后的值用私钥加密,得到数字签名S
-
验证过程
- 拿到证书,得到明文T,签名S
- 拿CA机构的公钥对S解密,得到S(是浏览器信任的机构,浏览器保留它的公钥)
- 用证书指明的hash算法对明文T进行hash得到T
- 对比T和S的值,如果相等则证书可信
-
为什么制作签名的时候要hash一次
- 非对称加密效率差,证书信息长,比较耗时。而hash后得到的是固定长度的信息,这样解密就快很多
-
-
中间人有可能篡改吗?
- 假如中间人篡改了原文,但是它没有CA机构的私钥,无法得到加密后的签名,就无法篡改签名,此时T和解密后S的值不同,就说明被篡改了,证书不可信
-
中间人有可能把证书掉包吗
- 证书包含网站A的信息,包括域名,浏览器把证书的域名和请求 的域名对比一下,就知道有没有掉包了
-
-
-
常见的加密算法
-
对称加密
- DES
- AES
-
非对称加密
- RSA
- DSA
- ECC
HTTP的长、短连接
HTTP协议和TCP/ID协议的关系
- HTTP的长连接和短连接本质上是TCP的长连接和短连接
- HTTP属于应用层协议,在传输层使用TCP协议,在网络层使用IP协议
- IP协议主要解决网络路由和寻址问题,TCP协议主要解决如何在IP层之上可靠地传输数据包,使得网络上接收端收到发送端所发出的所有包,并且顺序和发送顺序一致
如何理解HTTP协议是无状态的
- 这里的无状态,指的是协议对于事务处理没有记忆能力,服务器不知道客户端是什么状态
- HTTP是一个无状态的面向连接的协议,无状态不代表HTTP不能保持TCP连接
什么是长短连接
-
HTTP/1.0默认使用短连接
- 短连接:三次握手建立连接,一次收发数据之后就进行四次挥手
-
HTTP/1.1起,默认使用长连接
- 长连接:一次连接可以收发多条数据,只有超过一定的时间不再发送数据 才会断开连接
- 使用长连接的HTTP协议,会在响应头加入:Connection:keep-alive
HTTP1.0 1.1 2.0的主要区别