hex文件里面只有00,01,04三种码。那么我们在解析的时候只需要对这三种不同状态的进行不同的解析即可。
hex文件格式的解析,可阅读:HEX文件格式详解
首先创建一个Block的结构体,根据经验我们知道,一个数据块有:开始的地址,数据的长度,以及数据Buffer。三个结果。而一个hex文件里面可能有多个数据块,因此我们接下来声明了5个数据块。这个需要根据变量进行调整。然后根据hex文件初始化数据块的个数。再声明变量 HexBlockTotalNumber 为数据块的总数。
/*@!Encoding:936*/
variables
{
struct Block {
dword BlockStartAddr; //数据开始的地址
dword BlockDataLength; //数据的长度
byte dataBuffer[0x020FFFF]; //数据区域(单块数据的Buffer,如果hex文件很大,则需要把参数调大)
};
struct Block hexfile[5]; //创建5个数据块(主要根据HEX文件进行调整,hex有几个数据块就需要设置几个)
int HexBlockTotalNumber = 0; //数据块总数
dword t1; //计算解析所用的时间
}
/*********************************************************************************
*Function: //char2byte
* Description: //把单个字符转换为Byte的函数
*Input: //ch:ASCII编码字符,取值为0到F
*Return: //val,为byte类型
**********************************************************************************/
byte char2byte(char ch)
{
byte val;
val = 0;
if ( ch >= '0' && ch <= '9')
{
val = ch - '0';
}
if ( ch >= 'a' && ch <= 'f')
{
val = (ch - 'a') + 10;
}
if ( ch >= 'A' && ch <= 'F')
{
val = (ch - 'A') + 10;
}
return val;
}
/*********************************************************************************
*Function: //Read_hexFile
* Description: //解码HEX文件,只支持0x00,0x04,0x01类型
*Input: //Filename:需要解码的文件名
*Output: //hexfile
*Return: //void
**********************************************************************************/
//读取HEXFILE
void Read_hexFile(char Filename[])
{
long file_handle;
char RowData[128]; //逐行读取,每行数据缓存,当每行数据大于128时,需要将其调整
dword i;
dword RowDataByte; //单块数据块字节数
qword OffsetAddress; //扩展线性地址
qword ReAddr; //上一数据行起始地址
dword Len; //HEX每行有效数据字节数
dword ReLen; //HEX前一次数据长度
dword Addr; //HEX每行起始地址
dword Type; //HEX每行类型,有00,01,04四种类型
RowDataByte = 0;i = 0;Len = 0;ReLen = 0;Addr=0;Type = 0;ReAddr = 0;
file_handle = OpenFileRead(Filename,0);
HexBlockTotalNumber = 0;
if(file_handle!=0)
{ // Read all lines
while ( fileGetStringSZ(RowData,elcount(RowData),file_handle)!=0 ){
//判断首字符是否为:号
if(RowData[0] == ':'){
Len = (char2byte(RowData[1])*0x10+char2byte(RowData[2]));
Addr = char2byte(RowData[3])*0x1000+char2byte(RowData[4])*0x100+char2byte(RowData[5])*0x10+char2byte(RowData[6]);
Addr |= (OffsetAddress << 16);
Type = char2byte(RowData[7])*0x10+char2byte(RowData[8]);
//以下为打印解析的过程,打印解析时候的变量
//write("RowData:%s,HexBlockTotalNumber:%d,ReLen:%X,ReAddr:%X,Addr:%X,RowDataByte:%X",RowData,HexBlockTotalNumber,ReLen,ReAddr,Addr,RowDataByte);
switch(Type){
case 0x00: //数据
if (Addr > (ReLen + ReAddr)){ //判断为新数据块
if(RowDataByte == 0) //是否为首行数据字节数
{
hexfile[HexBlockTotalNumber].BlockStartAddr = Addr; //记录新数据块的起始地址
}
else //不是首行
{
hexfile[HexBlockTotalNumber].BlockDataLength = RowDataByte; //数据长度
RowDataByte = 0; //重新开始计数
HexBlockTotalNumber++;
hexfile[HexBlockTotalNumber].BlockStartAddr = Addr; //记录新数据块的起始地址
}
}
for(i = 0; i< Len ; i++)
{
//储存buffer,注意没有对crc进行校验。
hexfile[HexBlockTotalNumber].dataBuffer[RowDataByte++]=(char2byte(RowData[2*i+9])*0x10+char2byte(RowData[2*i+10]));
}
ReAddr = Addr; //保存当前地址,下一次使用
ReLen = Len; //保存当前长度,下一次使用
break;
case 0x04: //扩展线性地址记录
OffsetAddress = char2byte(RowData[9])*0x1000+char2byte(RowData[10])*0x100+char2byte(RowData[11])*0x10+char2byte(RowData[12]); //偏移地址
break;
case 0x01: //地址,结束
hexfile[HexBlockTotalNumber].BlockDataLength = RowDataByte; //数据长度
HexBlockTotalNumber++;
break;
}
}
}
write("Hex文件读取成功, 数据分块:%d",HexBlockTotalNumber);
for(i = 0; i < HexBlockTotalNumber; i++)
{
write("数据块:%d, 起始地址:0x%X, 结束地址:0x%X, 数据长度:%6d字节\r\n", i+1, hexfile[i].BlockStartAddr, hexfile[i].BlockStartAddr + hexfile[i].BlockDataLength - 1, hexfile[i].BlockDataLength);
}
fileClose(file_handle);
}
else{
write("OpenFileRead,error occurs");
}
}
on key 'f'
{
t1 = timeNow();
Read_hexFile(".//test.hex");
write("解析耗时:%f",t1-timeNow());
write("数据块:1");
write(0);
write("数据块:2");
write(1);
}
write (byte blockNum)
{
int i;
for (i=0; i<16; i++) write("dataBuffer[%d]:0x%2X",i,hexfile[blockNum].dataBuffer[i]);
}
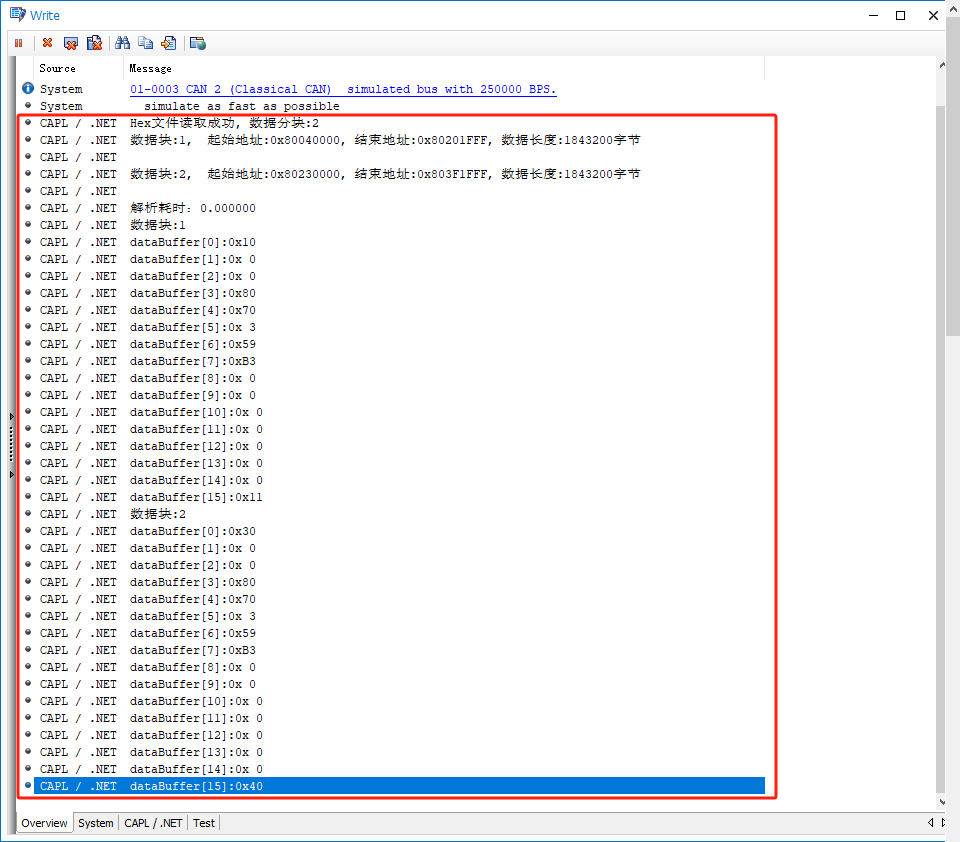
text.hex用Hexview打开的结果,我们读取圈中部分的数据:


运行结果:
参考:
CANOE CAPL编程 HEX文件读取
https://blog.csdn.net/zengqz123/article/details/106550213