一. 介绍
1.1 为什么要引入Adapter
在存在许多下游任务的情况下,微调的参数效率很低:每个任务都需要一个全新的模型。作为替代方案,我们建议使用适配器模块进行传输。
1.2 论文目标
目标是建立一个在所有这些方面都表现良好的系统,但不需要为每个新任务训练一个全新的模型
1.3 论文贡献
设计一个有效的适配器模块及其与基础模型的集成。我们提出了一个简单而有效的瓶颈架构。
二. NLP的适配器调优
2.1 瓶颈设计

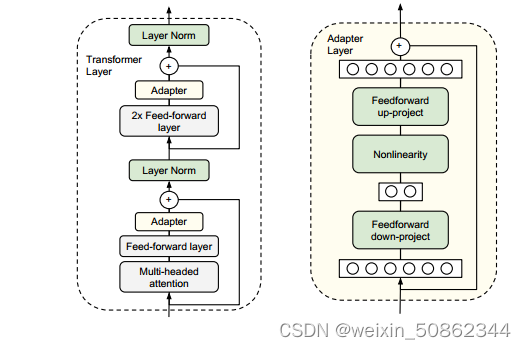
上图显示了我们的适配器体系结构,以及它在Transformer的应用。Transformer的每一层都包含两个主要子层:注意层和前馈层。左图:将适配器模块两次添加到每个Transformer层,在多头注意之后的投影和两个前馈层之后。右图:适配器由瓶颈组成,瓶颈包含与原始模型中的注意力和前馈层相关的几个参数。适配器还包含一个跳过连接。在适配器调优期间,绿色层在下游数据上进行训练,这包括适配器、层归一化参数和最终分类层。
为了限制参数的数量,提出了一个瓶颈架构。适配器首先将原始的d维特征投影到较小的维度m中,使用非线性,然后投影回d维。每层添加的参数总数(包括偏差)为2md + d + m。通过设置m 远小于 d,我们限制了每个任务添加的参数数量
2.2 实验结论
- 虽然每个适配器对整体网络的影响很小,但整体效果很大。

- 较低层上的适配器比较高层上的适配器影响较小。
- 在两个数据集上,适配器的性能对于低于10−2的标准差是鲁棒的。但是,当初始化太大时,性能会下降,对CoLA的影响更大。
- 跨适配器大小的模型质量是稳定的,并且在所有任务中使用固定的适配器大小可以对性能造成很小的损害。
- 以下扩展未能显著提升性能(i)向适配器添加批处理/层规范化,(ii)增加每个适配器的层数,(iii)不同的激活函数,例如tanh, (iv)仅在注意层内插入适配器,(v)与主层并行添加适配器,并可能使用乘法交互。
三.实验
代码参考:adapter-hub/adapter-transformers: Huggingface Transformers + Adapters = ❤️ (github.com)
以构建Bert模型为例,模型基本继承,包含关系如下图所示

3.1 增加adapter
通过add_adapter调用模型父类ModelAdaptersMixin的add_adapter方法实现增加adapter
model.add_adapter(adapter_name, config=adapter_config)即
def add_adapter(self, adapter_name: str, config=None, overwrite_ok: bool = False, set_active: bool = False):
config = AdapterConfigBase.load(config) # ensure config is ok and up-to-date
# In case adapter already exists and we allow overwriting, explicitly delete the existing one first
if overwrite_ok and adapter_name in self.config.adapters:
self.delete_adapter(adapter_name)
#-----------------------------------------------------
#将配置文件添加到config文件中
self.config.adapters.add(adapter_name, config=config)
try:
#初始化模型模块同时初始化权重
self._add_adapter_weights(adapter_name)
#-----------------------------------------------------
except ValueError as ex:
self.delete_adapter(adapter_name)
raise ex
if set_active:
self.set_active_adapters(adapter_name)3.1.1 _add_adapter_weights函数
def _add_adapter_weights(self, adapter_name: str):
#对模型中的每一层添加adapter层
self.apply_to_adapter_layers(lambda i, layer: layer.add_adapter(adapter_name, i))
# PHM Layer
adapter_config = self.config.adapters.match(adapter_name, AdapterConfig, location_key="phm_layer")
if adapter_config:
adapter_module = list(self.get_adapter(adapter_name)[0].values())[0]
# if multiple adapters with same location key exist they are returned as a modulelist
if isinstance(adapter_module, nn.ModuleList):
adapter_module = adapter_module[0]
if adapter_config["shared_phm_rule"] or adapter_config["shared_W_phm"]:
if self.config.model_type in SUBMODEL_NAMES:
hidden_sizes = [
getattr(self.config, key).hidden_size for key in SUBMODEL_NAMES[self.config.model_type]
]
if all(hidden_sizes[0] == h for h in hidden_sizes):
self.base_model.shared_parameters[adapter_name] = init_shared_parameters(
adapter_config, hidden_sizes[0], self.device
)
else:
raise ValueError(
"The model has different hidden sizes {}. Sharing comapcter weights is only possible if"
" the hidden_sizes match.".format(hidden_sizes)
)
else:
self.base_model.shared_parameters[adapter_name] = init_shared_parameters(
adapter_config, self.config.hidden_size, self.device
)
# Prefix Tuning
for module in self.modules():
if isinstance(module, PrefixTuningPool):
module.confirm_prefix(adapter_name)
if isinstance(self, InvertibleAdaptersMixin) or isinstance(self, InvertibleAdaptersWrapperMixin):
self.add_invertible_adapter(adapter_name)在AdapterLayer类中的add_adapter函数,往每一层中添加了Adapter或者是ParallelAdapter
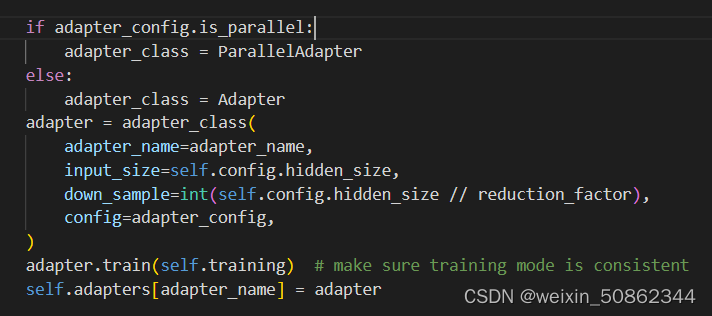
以Adapter类为例,在初始化函数中我们可以看到Adapter实际上就是一个线性层下采样到映射维度,在投影到原先模型的维度,即下图