1.程序运行为什么需要内存
1.计算机程序运行的目的
计算机为什么需要编程?
程序的目的是为了去运行,程序运行是为了得到一定的结果。计算机就是用来计算的,所有计算机程序其实都是在做计算。计算就是在计算数据,所以计算机程序中很重要的部分就是数据。
计算机程序=代码+数据

2.计算机程序运行过程
程序是由很多个函数组成的,程序的本质就是函数,函数的本质是加工数据的动作。
3.冯诺依曼结构和哈佛结构
冯诺依曼结构:数据和程序放在一起
哈佛结构:数据和代码分开存放
什么是代码:函数
什么是数据:全局变量,局部变量
冯诺依曼结构:在S5PV210中运行的linux系统上,运行应用程序时,这时候所有的应用程序的代码和数据都在DRAM。
哈佛结构:在单片机中,我们把程序代码烧写Flash(NorFlash)中,然后程序在Flash中原地运行,程序中所涉及到的数据(全局变量,局部变量)不能放在Flash中,必须放在RAM(SRAM)中。
4.动态内存DRAM和静态内存SRAM
SRAM和DRAM区别-CSDN博客
5.总结:为什么需要内存
内存是用来存储可变数据的,数据在程序中表现为全局变量,局部变量灯(在gcc中,其实常量也是存储在内存中)(大部分单片机中,常量是存储在flash中,也就是在代码段),对我们写程序来说非常重要。
6.深入思考:如何管理内存
对于计算机来说,内存容量越大则可能性越大,所以大家都希望自己的电脑内存更大。我们写程序时如何管理内存就成了很大的问题。如果管理不善,可能会造成程序运行消耗过多的内存,这样迟早内存都被你这个程序吃光了,当没有内存可用时程序就会崩溃。所以内存对程序来说是一种资源,所以管理内存对程序来说是一个重要技术和话题。
先从操作系统角度讲:操作系统掌握所有的硬件内存,因为内存很大,所以操作系统把内存分成1个1个的页面(其实就是一块,一般是4KB),然后以页面为单位来管理。页面内用更细小的方式来以字节为单位管理。操作系统内存管理的原理非常麻烦、非常复杂、非常不人性化。那么对我们这些使用操作系统的人来说,其实不需要了解这些细节。操作系统给我们提供了内存管理的一些接口,我们只需要用API即可管理内存。
譬如在C语言中使用malloc free这些接口来管理内存。
没有操作系统时:在没有操作系统(其实就是裸机程序)中,程序需要直接操作内存,编程者需要自己计算内存的使用和安排。如果编程者不小心把内存用错了,错误结果需要自己承担。
再从语言角度来讲:不同的语言提供了不同的操作内存的接口。
譬如汇编:根本没有任何内存管理,内存管理全靠程序员自己,汇编中操作内存时直接使用内存地址(譬如0xd0020010),非常麻烦;
譬如C语言:C语言中编译器帮我们管理直接内存地址,我们都是通过编译器提供的变量名等来访问内存的,操作系统下如果需要大块内存,可以通过API(malloc free)来访问系统内存。裸机程序中需要大块的内存需要自己来定义数组等来解决。
譬如C++语言:C++语言对内存的使用进一步封装。我们可以用new来创建对象(其实就是为对象分配内存),然后使用完了用delete来删除对象(其实就是释放内存)。所以C++语言对内存的管理比C要高级一些,容易一些。但是C++中内存的管理还是靠程序员自己来做。如果程序员new了一个对象,但是用完了忘记delete就会造成这个对象占用的内存不能释放,这就是内存泄漏。
Java/C#等语言:这些语言不直接操作内存,而是通过虚拟机来操作内存。这样虚拟机作为我们程序员的代理,来帮我们处理内存的释放工作。如果我的程序申请了内存,使用完成后忘记释放,则虚拟机会帮我释放掉这些内存。听起来似乎C# java等语言比C/C++有优势,但是其实他这个虚拟机回收内存是需要付出一定代价的,所以说语言没有好坏,只有适应不适应。当我们程序对性能非常在乎的时候(譬如操作系统内核)就会用C/C++语言;当我们对开发程序的速度非常在乎的时候,就会用Java/C#等语言。
二、位,字节,半字节,字的概念和内存位宽
内存单元的大小单位有4个:位(1bit) 字节(8bit) 半字(一般是16bit) 字(一般是32bit)
1.什么是内存?(硬件和逻辑两个角度)
1.硬件角度

内存实际上是电脑的一种配件(一般叫内存条)。根据不同的硬件实现原理还可以把内存分为SRAM和DRAM
2.逻辑角度
内存可以随机访问(随机访问的意思是只要给一个地址,就可以访问这个内存地址),并且可以读写(当然逻辑上也可以限制其为只读只写);内存在编程中天然是用来存放变量的(随机性)。就是因为有了内存,所以c语言才能定义变量。
2.内存的编程模型
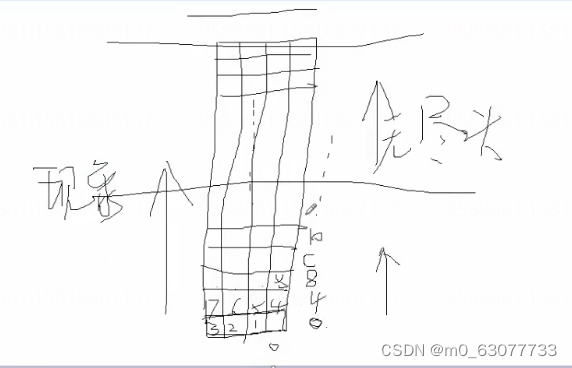
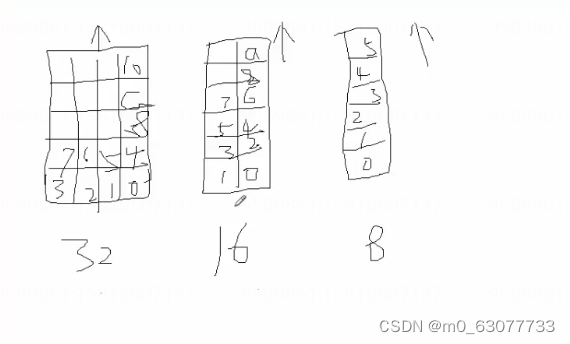
从逻辑角度来讲,内存实际上是由无限多个内存单元格组成的,每一个单元格有一个固定的地址叫内存地址,这个内存地址和这个内存单元格唯一对应且永久绑定。
以大楼来类比内存是最合适的。逻辑上的内存就好象是一栋无限大的大楼,内存的单元格就好象大楼中的一个个小房间。每个内存单元格的地址就好象每个小房间的房间号。内存中存储的内容就好象住在房间中的人一样。
逻辑上来说,内存可以有无限大(因为数学上编号永远可以增加,无尽头)。但是现实中实际的内存大小是有限制的,譬如32位的系统(32位系统指的是32位数据线,但是一般地址线也是32位,这个地址线32位决定了内存地址只能有32位二进制,所以逻辑上的大小为2的32次方)内存限制就为4G。实际上32位的系统中可用的内存是小于等于4G的(譬如我32位CPU装32位windows,但实际电脑只有512M内存)
3.内存位宽
从硬件角度讲
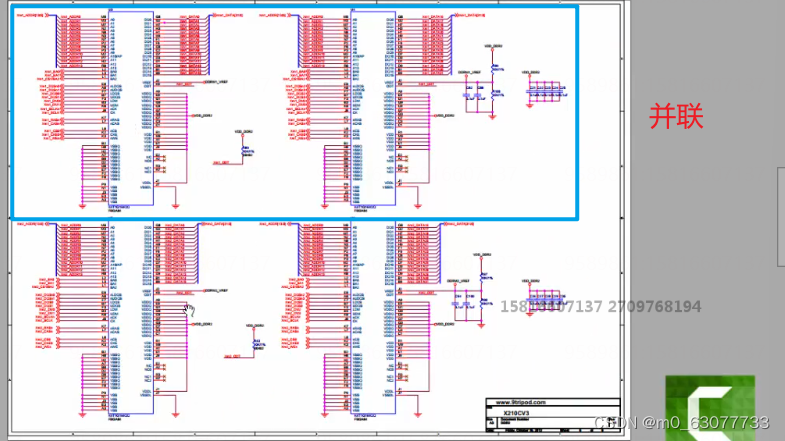
硬件内存的实现本身是有宽度的,也就是说有些内存条就是8位的,而有些就是16位的。那么需要强调的是内存芯片之间是可以并联的,通过并联后即使8位的内存芯片也可以做出来16位或32位的硬件内存。
从逻辑角度讲
内存位宽在逻辑上是任意的,甚至逻辑上存在内存位宽是24位的内存(但是实际上这种硬件是买不到的,也没有实际意义)。从逻辑角度来讲不管内存位宽是多少,我就直接操作即可,对我的操作不构成影响。但是因为你的操作不是纯逻辑而是需要硬件去执行的,所以不能为所欲为,所以我们实际的很多操作都是受限于硬件的特性的。譬如24位的内存逻辑上和32位的内存没有任何区别,但实际硬件都是32位的,都要按照32位硬件的特性和限制来干活。
4.位和字节
位:1bit
字节:8bit
在所有的计算机、所有的机器中(不管是32位系统还是16位系统还是以后的64位系统),位永远都是1bit,字节永远都是8bit。
5.字和半字
字:一般为32bit
半字:一般为16bit
历史上曾经出现过16位系统、32位系统、64位系统三种,而且操作系统还有windows、linux、iOS等很多,所以很多的概念在历史上曾经被混乱的定义过。
建议大家对字、半字、双字这些概念不要详细区分,只要知道这些单位具体有多少位是依赖于平台的。实际工作中在每种平台上先去搞清楚这个平台的定义(字是多少位,半字永远是字的一半,双字永远是字的2倍大小)。
编程时一般根本用不到字这个概念,那我们区分这个概念主要是因为有些文档中会用到这些概念,如果不加区别可能会造成你对程序的误解。
在linux+ARM这个软硬件平台上(我们嵌入式核心课的所有课程中),字是32位的。
三、内存编址和寻址,内存对齐
1.内存编址方法
内存在逻辑上就是一个一个的格子,这些格子可以用来装东西(里面装的东西就是内存中存储的数),每个格子有一个编号,这个编号就是内存地址,这个内存地址(一个数字)和这个格子的空间(实质是一个空间)是一一对应且永久绑定的。这就是内存的编址方法。
在程序运行时,计算机中CPU实际只认识内存地址,而不关心这个地址所代表的空间在哪里,怎么分布这些实体问题。因为硬件设计保证了按照这个地址就一定能找到这个格子,所以说内存单元的2个概念:地址和空间是内存单元的两个方面。
2.关键:内存编址是以字节为单位的
我随便给一个数字(譬如说7),然后说这个数字是一个内存地址,然后问你这个内存地址对应的空间多大?这个大小是固定式,就是一个字节(8bit)。【不管数字是多少,都是8bit】
如果把内存比喻位一栋大楼,那么这个楼里面的一个一个房间就是一个一个内存格子,这个格子的大小是固定的8bit,就好象这个大楼里面所有的房间户型是一样的。
3.内存和数据类型的关系
C语言中的基本数据类型有:char short int long float double
int 整形(整数类型,这个整就体现在它和CPU本身的数据位宽是一样的)譬如32位的CPU,整形就是32位,int就是32位。
数据类型和内存的关系就在于:
数据类型是用来定义变量的,而这些变量需要存储、运算在内存中。所以数据类型必须和内存相匹配才能获得最好的性能,否则可能不工作或者效率低下。
在32位系统中定义变量最好用int,因为这样效率高。原因就在于32位的系统本身配合内存等也是32位,这样的硬件配置天生适合定义32位的int类型变量,效率最高。也能定义8位的char类型变量或者16位的short类型变量,但是实际上访问效率不高。
在很多32位环境下,我们实际定义bool类型变量(实际只需要1个bit就够了)都是用int来实现bool的。也就是说我们定义一个bool b1;时,编译器实际帮我们分配了32位的内存来存储这个bool变量b1。编译器这么做实际上浪费了31位的内存,但是好处是效率高。
问题:实际编程时要以省内存为大还是要以运行效率为重?答案是不定的,看具体情况。很多年前内存很贵机器上内存都很少,那时候写代码以省内存为主。现在随着半导体技术的发展内存变得很便宜了,现在的机器都是高配,不在乎省一点内存,而效率和用户体验变成了关键。所以现在写程序大部分都是以效率为重。
4.内存对齐
我们在C中int a;定义一个int类型变量,在内存中就必须分配4个字节来存储这个a。有这么2种不同内存分配思路和策略:
第一种:0 1 2 3 对齐访问
第二种:1 2 3 4 或者 2 3 4 5 或者 3 4 5 6 非对齐访问
内存的对齐访问不是逻辑的问题,是硬件的问题。从硬件角度来说,32位的内存它 0 1 2 3四个单元本身逻辑上就有相关性,这4个字节组合起来当作一个int硬件上就是合适的,效率就高。
对齐访问很配合硬件,所以效率很高;非对齐访问因为和硬件本身不搭配,所以效率不高。(因为兼容性的问题,一般硬件也都提供非对齐访问,但是效率要低很多。)
四、c语言如何操作内存
1.C语言对内存地址的封装(用变量名来访问内存、数据类型的含义、函数名的含义)
1.用变量名来访问内存
譬如在C语言中 int a; a = 5; a += 4; // a == 9;
int a; // 编译器帮我们申请了1个int类型的内存格子(长度是4字节,地址是确定的,但是只有编译器知道,我们是不知道的,也不需要知道。),并且把符号a和这个格子绑定。
a = 5; // 编译器发现我们要给a赋值,就会把这个值5丢到符号a绑定的那个内存格子中。
a += 4; // 编译器发现我们要给a加值,a += 4 等效于 a = a + 4;编译器会先把a原来的值读出来,然后给这个值加4,再把加之后的和写入a里面去。2.数据类型的含义
C语言中数据类型的本质含义是:表示一个内存格子的长度和解析方法。
之前讲过一个很重要的概念:内存单元格子的编址单位是字节。
a.数据类型决定长度的含义
我们一个内存地址(0x30000000),本来这个地址只代表1个字节的长度,但是实际上我们可以通过给他一个类型(int),让他有了长度(4)【因为一个内存是1字节】,这样这个代表内存地址的数字(0x30000000)就能表示从这个数字(0x30000000)开头的连续的n(4)个字节的内存格子了(0x30000000 + 0x30000001 + 0x30000002 + 0x30000003)。
b.数据类型决定解析方法的含义
:譬如我有一个内存地址(0x30000000),我们可以通过给这个内存地址不同的类型来指定这个内存单元格子中二进制数的解析方法。譬如我 (int)0x30000000,含义就是(0x30000000 + 0x30000001 + 0x30000002 + 0x30000003)这4个字节连起来共同存储的是一个int型数据;那么我(float)0x30000000,含义就是(0x30000000 + 0x30000001 + 0x30000002 + 0x30000003)这4个字节连起来共同存储的是一个float型数据;【只是看法变了,但是里面的值并没有改变】
3.函数名的含义
C语言中,函数就是一段代码的封装。函数名的实质就是这一段代码的首地址。所以说函数名的本质也是一个内存地址。
2.用指针来间接访问内存
关于类型(不管是普通变量类型int float等,还是指针类型int * float *等),只要记住:
类型只是对后面数字或者符号(代表的是内存地址)所表征的内存的一种长度规定和解析方法规定而已。
C语言中的指针,全名叫指针变量,指针变量其实很普通变量没有任何区别。譬如int a和int *p其实没有任何区别,a和p都代表一个内存地址(譬如是0x20000000),但是这个内存地址(0x20000000)的长度和解析方法不同。a是int型所以a的长度是4字节,解析方法是按照int的规定来的;p是int *类型,所以长度是4字节,解析方法是int *的规定来的(0x20000000开头的连续4字节中存储了1个地址,这个地址所代表的内存单元中存放的是一个int类型的数)。
3.用数组来管理内存
数组管理内存和变量其实没有本质区别,只是符号的解析方法不同。(普通变量、数组、指针变量其实都没有本质差别,都是对内存地址的解析,只是解析方法不一样)。
int a; // 编译器分配4字节长度给a,并且把首地址和符号a绑定起来。
int b[10]; // 编译器分配40个字节长度给b,并且把首元素首地址和符号b绑定起来。数组中第一个元素(a[0])就称为首元素;每一个元素类型都是int,所以长度都是4,其中第一个字节的地址就称为首地址;首元素a[0]的首地址就称为首元素首地址。
五、内存管理之结构体
1.数组的优势和缺陷
优势:数组比较简单,访问用下标,可以随机访问。
缺陷:1 数组中所有元素类型必须相同;2 数组大小必须定义时给出,而且一旦确定不能再改。
2.结构体隆重登场
结构体发明出来就是为了解决数组的第一个缺陷:数组中所有元素类型必须相同
我们要管理3个学生的年龄(int类型),怎么办?
第一种解法:用数组 int ages[3];
第二种解法:用结构体
struct ages
{
int age1;
int age2;
int age3;
};
struct ages age;
分析总结:在这个示例中,数组要比结构体好。但是不能得出结论说数组就比结构体好,在包中元素类型不同时就只能用结构体而不能用数组了。
struct people
{
int age; // 人的年龄
char name[20]; // 人的姓名
int height; // 人的身高
};
因为people的各个元素类型不完全相同,所以必须用结构体,没法用数组。
3.结构体内嵌指针实现面向对象
面向过程与面向对象。
总的来说:C语言是面向过程的,但是C语言写出的linux系统是面向对象的。
非面向对象的语言,不一定不能实现面向对象的代码。只是说用面向对象的语言来实现面向对象要更加简单一些、直观一些、无脑一些。
用C++、Java等面向对象的语言来实现面向对象简单一些,因为语言本身帮我们做了很多事情;但是用C来实现面向对象很麻烦,看起来也不容易理解,这就是为什么大多数人学过C语言却看不懂linux内核代码的原因。
struct s
{
int age; // 普通变量
void (*pFunc)(void); // 函数指针,指向 void func(void)这类的函数
};
使用这样的结构体就可以实现面向对象。
这样包含了函数指针的结构体就类似于面向对象中的class,结构体中的变量类似于class中的成员变量,结构体中的函数指针类似于class中的成员方法。